
Java進階專題(十三) 從電商系統角度研究多執行緒(上)
阿新 • • 發佈:2020-09-07
## 前言
本章節主要分享下,多執行緒併發在電商系統下的應用。主要從以下幾個方面深入:執行緒相關的基礎理論和工具、多執行緒程式下的效能調優和電商場景下多執行緒的使用。
##多執行緒J·U·C
### 執行緒池
#### 概念
**回顧執行緒建立的方式**
- 繼承Thread
- 實現Runnable
- 使用FutureTask
**執行緒狀態**
NEW:剛剛建立,沒做任何操作
RUNNABLE:呼叫run,可以執行,但不代表一定在執行(RUNNING,READY)
WATING:使用了waite(),join()等方法
TIMED_WATING:使用了sleep(long),wait(long),join(long)等方法
BLOCKED:搶不到鎖
TERMINATED:終止
**執行緒池基本概念**
根據上面的狀態,普通執行緒執行完,就會進入TERMINA TED銷燬掉,而執行緒池就是建立一個緩衝池存放執行緒,執行結束以後,該執行緒並不會死亡,而是再次返回執行緒池中成為空閒狀態,等候下次任務來臨,這使得執行緒池比手動建立執行緒有著更多的優勢:
- 降低系統資源消耗,通過重用已存在的執行緒,降低執行緒建立和銷燬造成的消耗;
- 提高系統響應速度,當有任務到達時,通過複用已存在的執行緒,無需等待新執行緒的建立便能立即執行;
- 方便執行緒併發數的管控。因為執行緒若是無限制的建立,可能會導致記憶體佔用過多而產生OOM
- 節省cpu切換執行緒的時間成本(需要保持當前執行執行緒的現場,並恢復要執行執行緒的現場)。
- 提供更強大的功能,延時定時執行緒池。*(Timer vs ScheduledThreadPoolExecutor)*
**常用執行緒池類結構**
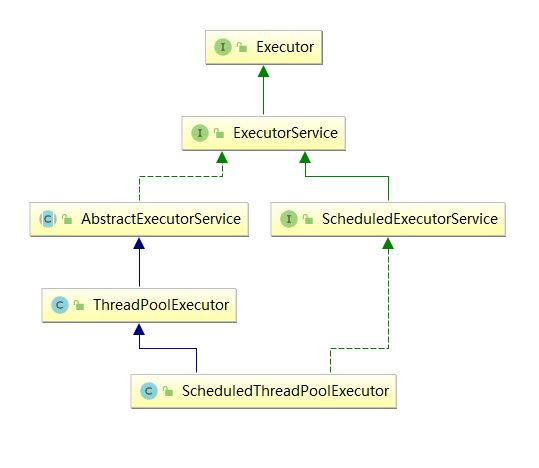
說明:
- 最常用的是ThreadPoolExecutor
- 排程用的ScheduledThreadPoolExecutor
- Executors是工具類,協助建立執行緒池
#### 工作機制
線上程池的程式設計模式下,任務是提交給整個執行緒池,而不是直接提交給某個執行緒,執行緒池在拿到任務後,就在內部尋找是否有空閒的執行緒,如果有,則將任務交給某個空閒的執行緒。一個執行緒同時只能執行一個任務,但可以同時向一個執行緒池提交多個任務。
**執行緒池狀態**
- RUNNING:初始化狀態是RUNNING。執行緒池被一旦被建立,就處於RUNNING狀態,並且執行緒池中的任務數為0。RUNNING狀態下,能夠接收新任務,以及對已新增的任務進行處理。
- SHUTDOWN:SHUTDOWN狀態時,不接收新任務,但能處理已新增的任務。呼叫執行緒池的shutdown()介面時,執行緒池由RUNNING -> SHUTDOWN。
```java
//shutdown後不接受新任務,但是task1,仍然可以執行完成
ExecutorService poolExecutor = Executors.newFixedThreadPool(5);
poolExecutor.execute(new Runnable() {
public void run() {
try {
Thread.sleep(1000);
System.out.println("finish task 1");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
poolExecutor.shutdown();
poolExecutor.execute(new Runnable() {
public void run() {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
System.out.println("ok");
```
- STOP:不接收新任務,不處理已新增的任務,並且會中斷正在處理的任務。呼叫執行緒池的shutdownNow()介面時,執行緒池由(RUNNING 或SHUTDOWN ) -> STOP
```java
//改為shutdownNow後,任務立馬終止,sleep被打斷,新任務無法提交,task1停止
poolExecutor.shutdownNow();
```
- TIDYING:所有的任務已終止,ctl記錄的”任務數量”為0,執行緒池會變為TIDYING。執行緒池變為TIDYING狀態時,會執行鉤子函式terminated(),可以通過過載terminated()函式來實現自定義行為
```java
//自定義類,重寫terminated方法
public class MyExecutorService extends ThreadPoolExecutor {
public MyExecutorService(int corePoolSize, int maximumPoolSize, long
keepAliveTime, TimeUnit unit, BlockingQueue workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit,
workQueue);
}
@Override
protected void terminated() {
super.terminated();
System.out.println("treminated");
}
//呼叫 shutdownNow, ternimated方法被呼叫列印
public static void main(String[] args) throws InterruptedException {
MyExecutorService service = new
MyExecutorService(1,2,10000,TimeUnit.SECONDS,new
LinkedBlockingQueue(5));
service.shutdownNow();
}
}
```
- TERMINA TED:執行緒池處在TIDYING狀態時,執行完terminated()之後,就會由TIDYING ->TERMINA TED
#### 結構說明

#### 任務提交流程
1. 新增任務,如果執行緒池中的執行緒數沒有達到coreSize,會建立執行緒執行任務
2. 當達到coreSize,把任務放workQueue中
3. 當queue滿了,未達maxsize建立心執行緒
4. 執行緒數也達到maxsize,再新增任務會執行reject策略
5. 任務執行完畢,超過keepactivetime,釋放超時的非核心執行緒,最終恢復到coresize大小
#### 原始碼剖析
execute方法
```java
//任務提交階段
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
//判斷當前workers中的執行緒數量有沒有超過核心執行緒數
if (workerCountOf(c) < corePoolSize) {
//如果沒有則建立核心執行緒數(引數true指的就是核心執行緒)
if (addWorker(command, true))
return;
c = ctl.get();
}
//如果超過核心執行緒數了 先校驗執行緒池是否正常執行後向阻塞佇列workQueue末尾新增任務
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
//再次檢查執行緒池執行狀態,若不在執行則移除該任務並且執行拒絕策略
if (! isRunning(recheck) && remove(command))
reject(command);
//若果沒有執行緒在執行
else if (workerCountOf(recheck) == 0)
//則建立一個空的worker 該worker從佇列中獲取任務執行
addWorker(null, false);
}
//否則直接新增非核心執行緒執行任務 若非核心執行緒也新增失敗 則執行拒絕策略
else if (!addWorker(command, false))
reject(command);
}
```
執行緒建立:addWorker()方法
```java
//addWorker通過cas保證了併發安全性
private boolean addWorker(Runnable firstTask, boolean core) {
//第一部分 計數判斷,不符合返回false
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >