
記錄一次OCR程式開發的嘗試
阿新 • • 發佈:2020-09-14
# 記錄一次OCR程式開發的嘗試
最近工作中涉及到一部分文件和紙質文件的校驗工作,就想把紙質檔案拍下來,用文字來互相校驗。想到之前呼叫有道智雲介面做了文件翻譯。看了下OCR文字識別的API介面,有道提供了多種OCR識別的不同介面,有手寫體、印刷體、表格、整題識別、購物小票識別、身份證、名片等。乾脆這次就繼續用有道智雲介面做個小[demo](https://github.com/LemonQH/WordPicsOCRDemo),把這些功能都試了試,當練手,也當為以後的可能用到的功能做準備了。
### 呼叫API介面的準備工作
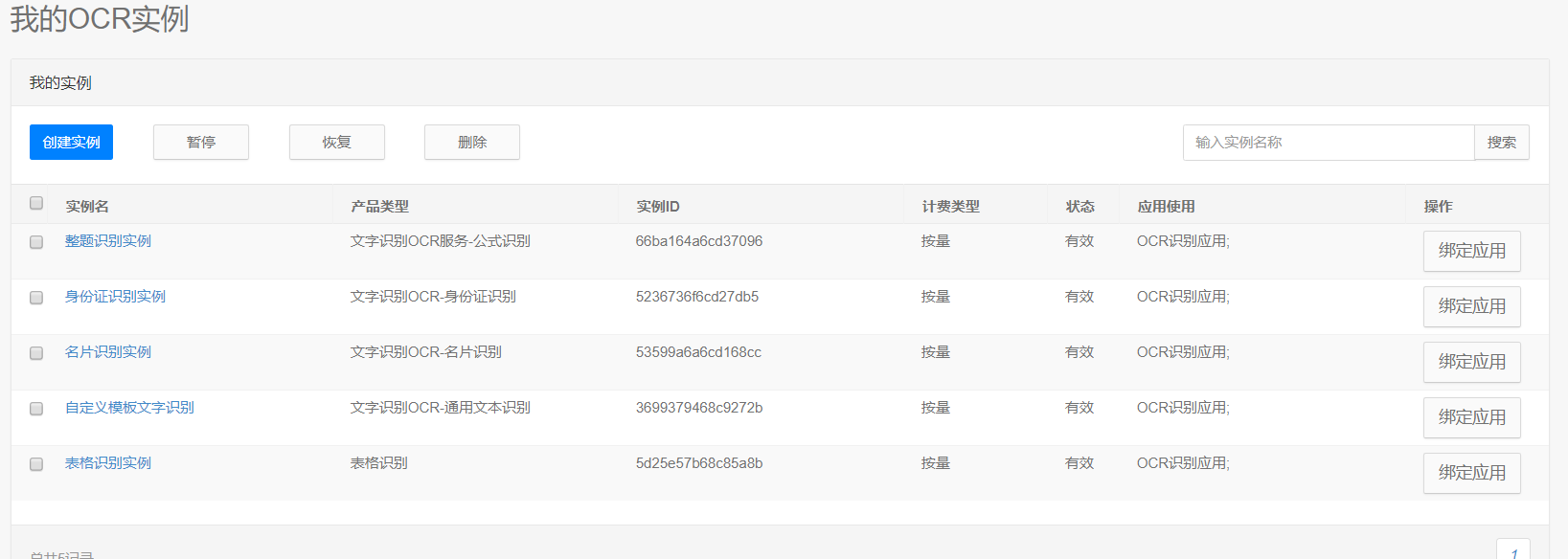
首先,是需要在有道智雲的個人頁面上建立例項、建立應用、繫結應用和例項,獲取到應用的id和金鑰。具體個人註冊的過程和應用建立過程詳見文章[分享一次批量檔案翻譯的開發過程](https://blog.csdn.net/qiedabeng8686/article/details/108416385)

### 開發過程詳細介紹
下面介紹具體的程式碼開發過程:
這次的demo使用python3開發,包括maindow.py,ocrprocesser.py,ocrtools.py三個檔案。介面部分,為了簡化開發過程,使用python自帶的tkinter庫,提供選擇待識別檔案和識別型別、展示識別結果的功能;ocrprocesser.py根據所選型別呼叫相應api介面,完成識別過程並返回結果;ocrtools.py封裝了經整理後的有道ocr 的各類api,實現了分類呼叫。
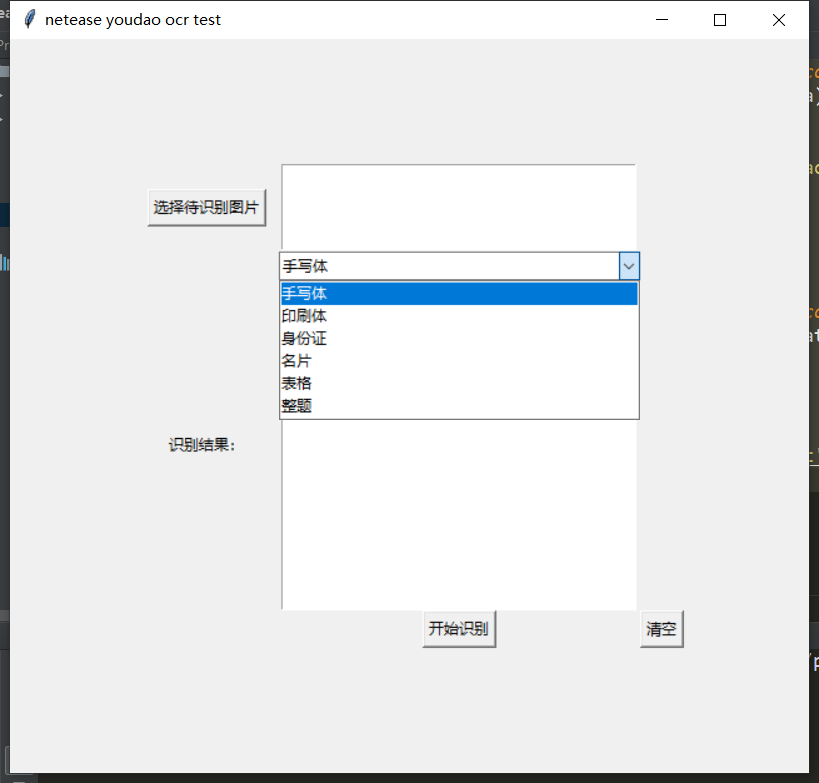
1. 介面部分:
介面部分程式碼如下,使用了tkinter的grid來排列元素。
```python
root=tk.Tk()
root.title("netease youdao ocr test")
frm = tk.Frame(root)
frm.grid(padx='50', pady='50')
btn_get_file = tk.Button(frm, text='選擇待識別圖片', command=get_files)
btn_get_file.grid(row=0, column=0, padx='10', pady='20')
text1 = tk.Text(frm, width='40', height='5')
text1.grid(row=0, column=1)
combox=ttk.Combobox(frm,textvariable=tk.StringVar(),width=38)
combox["value"]=img_type_dict
combox.current(0)
combox.bind("<