
深入理解SVM,詳解SMO演算法
阿新 • • 發佈:2020-09-22
今天是**機器學習專題**第35篇文章,我們繼續SVM模型的原理,今天我們來講解的是SMO演算法。
## 公式回顧
在之前的文章當中我們對硬間隔以及軟間隔問題都進行了分析和公式推導,我們發現軟間隔和硬間隔的形式非常接近,只有少數幾個引數不同。所以我們著重來看看軟間隔的處理。
通過拉格朗日乘子法以及對原問題的對偶問題進行求解,我們得到了二次規劃:
$$\begin{align*}
&\min_{\alpha}\frac{1}{2} \sum_{i=1}^m \sum_{j=1}^m \alpha_i \alpha_j y_iy_jx_i^Tx_j -\sum_{i=1}^m\alpha_i \tag{1} \\
& \begin{array}{r@{\quad}r@{}l@{\quad}l}
s.t.& \sum_{i=1}^m \alpha_i y_i = 0 \\
& 0 \le \alpha_i \le C,&i=1,2,3\ldots,m\\
\end{array}
\end{align*}$$
它應該滿足的KTT條件如下:
$$\left\{\begin{align*}
\alpha_i \ge 0, \beta_i \ge 0\\
y_i(\omega^T x_i + b) - 1 + \xi_i \ge 0\\\alpha_i(y_i(\omega^Tx_i + b) - 1 + \xi_i)=0\\\xi_i \ge0, \beta_i \xi_i = 0 \end{align*}\right.$$
也就是說我們要在這些條件下去求解(1)式的極值,在這個約束的情況下,雖然我們已經把式子化簡成了只有一種引數$\alpha$,但這個極值又應該怎麼求呢?為了解決這個問題,我們需要引入一個新的演算法,也是今天的文章的主要介紹的內容——**SMO演算法**。
## SMO演算法簡介
SMO的全寫是Sequential Minimal Optimization,翻譯過來是序列最小優化演算法。演算法的核心思想是由於我們需要尋找的是一系列的$\alpha$值使得(1)取極值,但問題是**這一系列的值我們很難同時優化**。所以SMO演算法想出了一個非常天才的辦法,把這一系列的$\alpha$中的兩個看成是變數,其它的全部固定看成是常數。
這裡有一個問題是為什麼我們要選擇兩個$\alpha$看成是變數而不選一個呢?選一個不是更加簡單嗎?因為我們的約束條件當中有一條是$\sum y_i\alpha_i=0$,所以如果我們只選擇一個$\alpha$進行調整的話,那麼顯然**會破壞這個約束**。所以我們選擇兩個,其中一個變化,另外一個也隨著變化,這樣就可以保證不會破壞約束條件了。
為了方便敘述,我們預設選擇的兩個$\alpha$分別是$\alpha_1, \alpha_2$。另外由於我們涉及$x_i^Tx_j$的操作,我們令$K_{ij}=x_i^Tx_j$。這樣上面的(1)式可以寫成:
$$\begin{align*}
&\min_{\alpha1,\alpha_2}\frac{1}{2}K_{11}\alpha_1^2 + \frac{1}{2}K_{22}\alpha_2^2 + y_1y_2\alpha_1\alpha_2 - (\alpha_1 + \alpha_2) + y_1\alpha_1\sum_{i=3}^my_i\alpha_iK_{i1} + y_2\alpha_2\sum_{i=3}^my_i\alpha_iK_{i, 2} + Constant \tag{2} \\
& \begin{array}{r@{\quad}r@{}l@{\quad}l}
s.t.& \alpha_1y_1 + \alpha_2y_2 = -\sum_{i=3}^m y_i\alpha_i \\
& 0 \le \alpha_i \le C,&i=1,2,3\ldots,m\\
\end{array}
\end{align*}$$
其中由於$y_1 = \pm 1$,所以$y_i^2 = 1$,上面的Constant表示除了$\alpha_1, \alpha_2$以外的常數項。我們假設$\alpha_1y_1 + \alpha_2y_2 = k$,其中$\alpha_1, \alpha_2 \in [0, C]$,由於$y_i$只有兩個選項1或者-1,所以我們可以分情況討論。
## 分情況討論
首先我們討論$y_1$和$y_2$不同號時,無非兩種,第一種情況是$\alpha_1 - \alpha_2 = k$,也就是$\alpha_2 = \alpha_1 - k$,我們假設此時k > 0,第二種情況是$\alpha_2 = \alpha_1 + k$,我們假設此時k < 0。我們很容易發現對於第一種情況,如果 k < 0,其實就是第二種情況,同樣對於第二種情況,如果k > 0其實就是第一種情況。這變成了一個**線性規劃問題**,我們把圖畫出來就非常清晰了。

針對第一種情況,我們可以看出來$\alpha_2$的範圍是$(0, C - \alpha_2 + \alpha_1)$,第二種情況的範圍是$(\alpha_2 - \alpha_1, C)$。這裡我們把k又表示回了$\alpha_1,\alpha_2$,由於我們要通過迭代的方法來優化$\alpha_1,\alpha_2$的取值,所以我們令上一輪的$\alpha_1, \alpha_2$分別是$\alpha_{1o}, \alpha_{2o}$。這裡的o指的是old的意思,我們把剛才求到的結論綜合一下,就可以得到$\alpha_2$下一輪的下界L是$\max(0, \alpha_{2o} - \alpha_{1o})$,上界H是$\min(C+\alpha_{2o} - \alpha_{1o}, C)$。
同理,我們畫出$\alpha_1, \alpha_2$同號時的情況,也有k > 0 和 k < 0兩種。
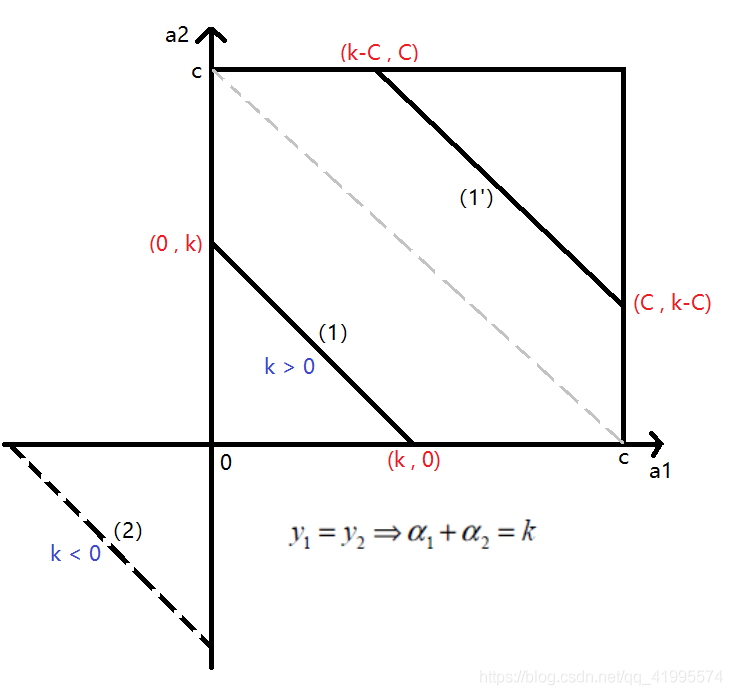
第一種情況是$y_1 = y_2 = 1$,這時$\alpha_1 + \alpha_2 = k$,此時 k > 0,對應的$\alpha_2$的取值是$(0, \alpha_{1o} + \alpha_{2o})$。當k > C的時候,這時候也就是右上角1'的情況,此時過了中間的虛線,$\alpha_2$的範圍是$(\alpha_{1o} + \alpha_{2o} - C, C)$。
第二種情況是$y_1 = y_2 = -1$,此時$\alpha_1 + \alpha_2 = k$,此時k < 0,由於這個時候是不符合約束條件$0\le \alpha_1, \alpha_2 \le C$的,所以此時沒有解。這兩種情況綜合一下,可以得到下界L是$\max(0, \alpha_{1o} + \alpha_{2o} - C)$,上屆H是$\min(\alpha_{1o} + \alpha{2o}, C)$。
我們假設我們通過迭代之後得到的下一輪$\alpha_2$是$\alpha_{2new, unc}$,這裡的**unc是未經過約束的意思**。那麼我們加上剛才的約束,可以得到:
$$\begin{equation} \alpha_{2new}=\left\{ \begin{aligned} & H &\quad \alpha_{2new, unc} > H \\ & \alpha_{2new, unc} \quad &L \le \alpha_{2new, unc} \le H \\ & L &\quad \alpha_{2new, unc} < L \end{aligned} \right. \end{equation}$$
這裡的$\alpha_{2new,unc}$是我們利用求導得到取極值時的$\alpha_2$,但問題是由於存在約束,這個值並不一定能取到。所以上述的一系列操作就是為了探討約束存在下我們能夠取到的極值情況。如果看不懂推導過程也沒有關係,至少這個結論需要搞明白。
## 代入消元
我們現在已經得到了下一輪迭代之後得到的新的$\alpha_2$的取值範圍,接下來要做的就是像梯度下降一樣,求解出使得損失函式最小的$\alpha_1$和$\alpha_2$的值,由於$\alpha_1 + \alpha_2$的值已經確定,所以我們求解出其中一個即可。
我們令$\alpha_1y_1 + \alpha_2y_2 = \xi$,那麼我們可以代入得到$\alpha_1 = y_1(\xi - \alpha_2y_2)$
我們把這個式子代入原式,得到的式子當中可以消去$\alpha_1$,這樣我們得到的就是**只包含$\alpha_2$的式子**。我們可以把它看成是一個關於$\alpha_2$的函式,為了進一步簡化,我們令$v_i = \sum_{j=3}^my_j \alpha_j K{i, j} , E_i = f(x_i ) - y_i = \sum_{j=1}^m \alpha_jy_jK_{i, j} + b - y_i$
這裡的$E_i$表示的是第i個樣本真實值與預測值之間的差,我們把上面兩個式子代入原式,化簡可以得到:
$$f(\alpha_2) = \frac12 K_{11}(\xi - \alpha_2y_2) + \frac12K_{22}\alpha_2^2 + y_2K_{12}(\xi- \alpha_2y_2)\alpha_2 - (\xi - \alpha_2y_2)y_1 - \alpha_2 + (\xi - \alpha_2y_2)v_1 + y_2\alpha_2v_2$$
接下來就是對這個式子進行**求導求極值**,就是高中數學的內容了。
$$\frac {\partial W}{\partial\alpha_2}=K_{11}\alpha_2 + K_{22}\alpha_2 - 2K_{12}\alpha_2 - K{11}\xi y_2+K{12}\xi y_2 + y_1y_2 -1 - v_1y_2 + y_2v_2 = 0$$
我們求解這個式子,最終可以得到:
$$\alpha_{2new, unc} = \alpha_{2o} + \frac{y_2(E_1 - E_2)}{K_{11}+K_{22} - 2 K_{12}}$$
我們根據這個式子就可以求出$\alpha_2$下一輪迭代之後的值,求出值之後,我們在和約束的上下界比較一下,就可以得到在滿足約束的情況下可以取到的最好的值。最後,我們把$\alpha_2$代入式子求解一下$\alpha_1$。這樣我們就**同時優化了一對$\alpha$引數**,SMO演算法其實就是**重複使用上面的優化方法不停地選擇兩個引數進行優化**,直到達到迭代次數,或者是不能再帶來新的提升為止。
整個演算法的邏輯其實是不難理解的,但是中間公式的推導過程實在是多了一些。這也是我把SVM模型放到機器學習專題最後來講解的原因,在下一篇文章當中,我們將會為大家帶來SVM模型核函式的相關內容,結束之後我們機器學習專題就將迎來尾聲了,再之後我們將會開始深度學習的專題,敬請期待吧。
今天的文章到這裡就結束了,如果喜歡本文的話,請來一波**素質三連**,給我一點支援吧(**關注、轉發、點贊**)。
[原文連結,求個關注](https://mp.weixin.qq.com/s?__biz=MzUyMTM5OTM2NA==&mid=2247487331&idx=2&sn=ef5cbced48cf9321bb55ba542116efe2&chksm=f9daf248cead7b5ee8d14cc2bc95db890c74fdb6117398c817aa9acc338861960fea5d043fc0&token=55017786&lang=zh_CN#rd)
![](https://img2020.cnblogs.com/blog/1906483/202009/1906483-20200922110744882-18120882