
定時任務與feign超時的糾葛,該咋優化?
阿新 • • 發佈:2020-09-22
# 1 背景
業務定時器應用半夜經常會觸發熔斷異常的告警郵件

根據郵件提示的類找到歸納以下表格
| 編號 | 報錯方法 | 介面所屬應用 | 所屬定時任務類 |
| -------- | -------- | -------- | -------- |
|A| VipTradeReportFeignService#getShopTradeReportByDate| pinka-mod-stats | ShopOrderSturctureTask |
|B|VipMemberStatsFeignService#statMemberRecord | pinka-mod-stats | MemberStatTask |
|C|VipPartnerWalletFeignService.handlePartnerWithdraw | pinka-mod-customer | PartnerWithdrawCheckTask |
|D|VipWeixinBabyActivityFeignService.getBabyActivityNoticePage | pinka-mod-weixin | VipWeixinBabyNoticeTask |
以上A~D都是在一個分散式定時器事件處理應用(pinka-mod-scheduler)中對外的feign微服務呼叫產生的,相當於4類任務,每類都會調1次或多次外部feign微服務介面,而其中的A~D介面發生了問題
其中A和B都是如下形式的異常
```
com.netflix.hystrix.exception.HystrixTimeoutException
at com.netflix.hystrix.AbstractCommand$HystrixObservableTimeoutOperator$1$1.run(AbstractCommand.java:1154)
at com.netflix.hystrix.strategy.concurrency.HystrixContextRunnable$1.call(HystrixContextRunnable.java:45)
at com.netflix.hystrix.strategy.concurrency.HystrixContextRunnable$1.call(HystrixContextRunnable.java:41)
...
```
而C和D都是如下形式的異常
```
feign.RetryableException: 10.13.32.111:56000 failed to respond executing POST http://pinka-mod-customer/vip/partner/wallet/handlePartnerWithdraw
at feign.FeignException.errorExecuting(FeignException.java:67)
at feign.SynchronousMethodHandler.executeAndDecode(SynchronousMethodHandler.java:104)
at feign.SynchronousMethodHandler.invoke(SynchronousMethodHandler.java:76)
at feign.hystrix.HystrixInvocationHandler$1.run(HystrixInvocationHandler.java:114)
...
Caused by: org.apache.http.NoHttpResponseException: 10.13.32.111:56000 failed to respond
at org.apache.http.impl.conn.DefaultHttpResponseParser.parseHead(DefaultHttpResponseParser.java:141)
at org.apache.http.impl.conn.DefaultHttpResponseParser.parseHead(DefaultHttpResponseParser.java:56)
at org.apache.http.impl.io.AbstractMessageParser.parse(AbstractMessageParser.java:259)
...
```
# 2 追查
## 2.1 HystrixTimeoutException超時異常
A與B的異常幾乎每天都發生,且提示很明顯,是Hystrix中設定了超時時間(目前為10s),並且執行超時導致的。為何會超時?去介面實現發現是有for迴圈場景的耗時邏輯
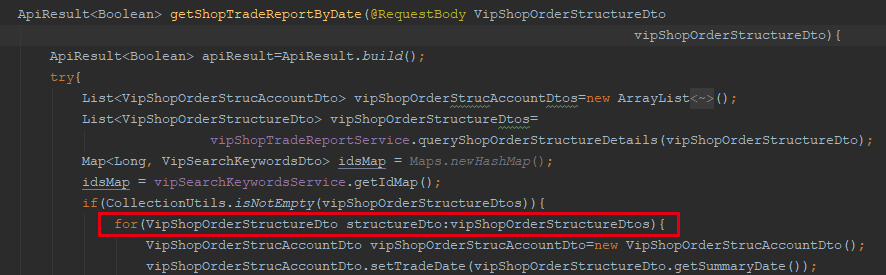
通過Kibana日誌系統查歷史執行耗時,也可以發現都基本>13s,所以這類異常基本確因

### 2.1.1 解決與思考
這其實是一個很典型場景,定時器任務執行並且處理邏輯是在另外一個微服務中,而處理邏輯屬於複雜耗時,怎麼辦?
A. 增加超時時間,這是個粗暴的思路,因為設長了可能導致更大的問題,因為超時本來就是為了fastfail,設20s那之後可能還會遇到要30s甚至更久的場景。所以這個方案不能用在所有呼叫的公共預設超時時間上;
但是可以考慮用在某些介面上,比如VipTradeReportFeignService#getShopTradeReportByDate介面評估正常耗時就是要15s以上,那就單獨為其設定。相關配置方式:
```
#預設公共超時
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds=10000
#單獨為某個feign介面設定超時
hystrix.command."FeignService#sayHello(String)".execution.isolation.thread.timeoutInMilliseconds=15000
```
B. 優化介面提供方的邏輯執行時間。比如上述VipTradeReportFeignService#getShopTradeReportByDate中的for迴圈,能否移到介面呼叫方,相當於介面提供方每次只執行for迴圈的1次操作。說白了就是確保介面返回要在超時時間內,這也符合微服務介面的設計原則。
C. 還有種思路是介面處理非同步化,即介面提供方立刻返回,自己再用非同步執行緒去處理最終邏輯。但是單純這樣會導致任務執行不可靠,即介面返回成功不代表真實一定執行成功了,如果此時介面提供方重啟或異常導致耗時的非同步邏輯執行一半就中斷了,反而無法利用分散式定時任務排程的機制去重試執行等。所以使用此思路時,介面立刻返回但不能立刻將任務也作為成功執行完畢,需要配合一些非同步通知機制,即介面提供方真實成功結束耗時操作,通知給介面呼叫方,介面呼叫方再將任務作為成功返回上報。
## 2.2 feign.RetryableException failed to respond executing 異常
這是C和D的異常,是隨機低頻告警。看字面意思是介面請求無響應,再結合郵件中的“熔斷”字眼就自然推測是介面提供應用的問題了(事後證明被“熔斷”字眼坑了)。所以去追查介面所屬應用pinka-mod-customer在告警前後的監控指標,發現tcp連線、CPU、記憶體、網路流量表現都沒什麼異常狀況。另外如果是熔斷,那此介面必然得是呼叫失敗多次呀,而每次定時任務對該介面呼叫卻只有一次。
這時候檢視介面提供方Controller層日誌,發現告警時刻確實提供方沒進入controller處理。

由此推測,提供方應用本身並無問題。而檢視呼叫方應用日誌和效能指標,在那個時刻也無異常情況,還在不斷向其他應用呼叫產生日誌。再結合這個異常日誌,推測原因是**由於呼叫方與提供方某次呼叫的網路閃斷導致的**(所以是隨機低頻)。
但為何會開啟“熔斷”,這個還無法解釋。此時去追查郵件告警的程式碼源頭,告警本質是通過重寫了openfeign官方的HystrixCommand建立邏輯中的getFallback方法實現的,即進入fallback邏輯就會發郵件
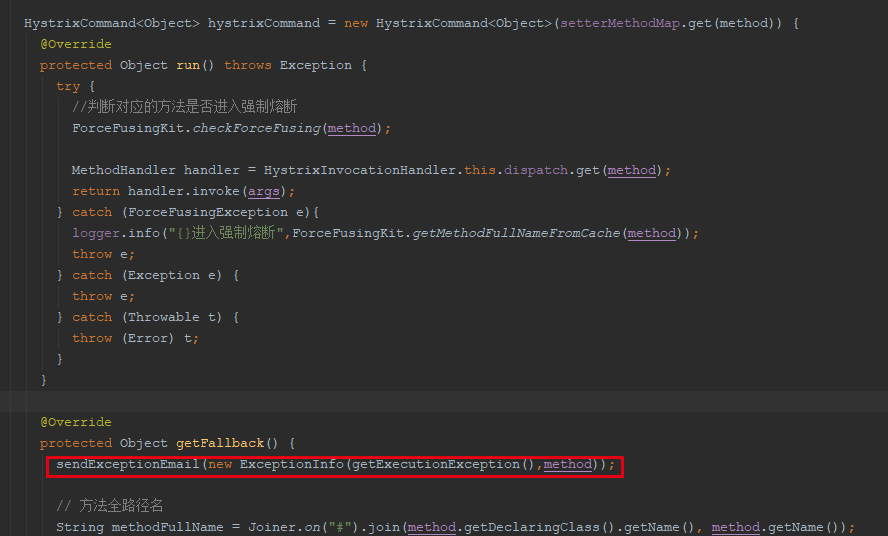
此時真相大白了,其實只是進了fallback降級,並不代表開啟熔斷,比如在HystrixCommand的run中丟擲異常會進fallback,run執行超時會進fallback,熔斷也會進fallback。即A~D這些異常,雖然郵件寫的是熔斷,但其實都沒開啟熔斷,而只是進了fallback降級!
所以feign.RetryableException failed to respond executing這個其實只是一次偶然的呼叫失敗進了fallback而已,並沒之前猜想的那麼複雜。
### 2.2.1 解決與思考
郵件告警邏輯自然是要修改,區分熔斷和降級。如果要判斷熔斷,可以用如下方法
```
protected Object getFallback() {
if (this.isCircuitBreakerOpen()) {
// 熔斷告警方式
sendExceptionEmail(...);
}else{
// 非熔斷降級告警,如果無需告警也可不寫
sendExceptionEmail(...);
}
....
}
```
“架構人生,迭代生命” ——深邃老夏,搜尋summer_deep微信公眾號可獲取更