
虛擬機器系列 | 執行引擎和垃圾回收
阿新 • • 發佈:2020-09-25
本文原始碼:[GitHub·點這裡](https://github.com/cicadasmile/java-base-parent) || [GitEE·點這裡](https://gitee.com/cicadasmile/java-base-parent)
# 一、執行引擎
應用程式經過編譯,轉換為位元組碼檔案,位元組碼載入到記憶體空間並不能直接在作業系統上執行,執行引擎作為Java虛擬機器核心的組成部分,作用就是將位元組碼指令解釋/編譯為對應系統平臺上的本地機器指令。
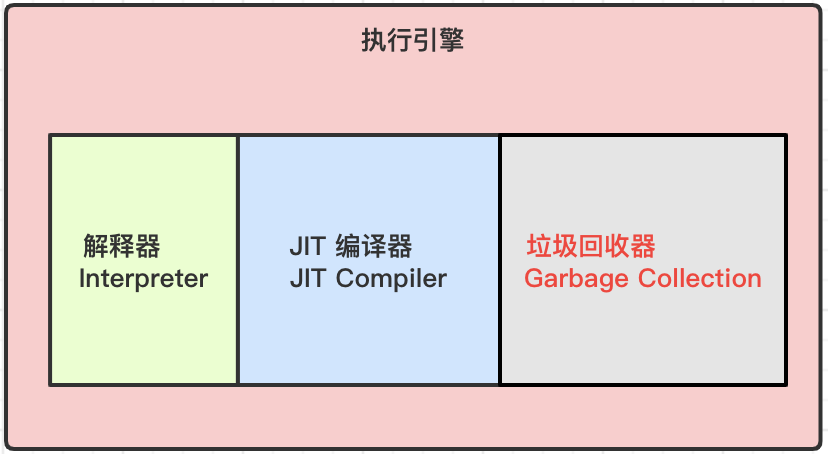
**直譯器**:虛擬機器啟動時會根據預定義對位元組碼採用逐行解釋的方式執行,將每條位元組碼檔案中的內容解釋為對應系統平臺的本地機器指令執行;
**JIT編譯器**:虛擬機器將原始碼編譯成本地機器平臺相關的機器語言,並且尋找熱點高頻執行的程式碼將其放入元空間中,即元空間中存放的JIT快取程式碼;
**垃圾回收**:對於沒有任何引用的物件標記為垃圾,會被回收釋放記憶體空間。
# 二、垃圾物件標記
## 1、引用計數法
每個物件儲存一個整型引用計數器,用來記錄物件被引用的次數,當該物件被一個物件引用時,計數器加1,當失去一個引用時,計數器減1;引用計數演算法就是通過判斷物件的引用數量來決定物件是否可以被當做垃圾物件回收掉。
雖然引用計數法效率高,但是當兩個物件互相引用時會導致這兩個物件一直不會被回收,這是一個致命的缺陷。所以JVM並沒有採用該標記演算法。
## 2、可達性分析演算法
可達性分析演算法是基於物件到根物件的引用鏈是否可達來判斷物件是否可以被回收;
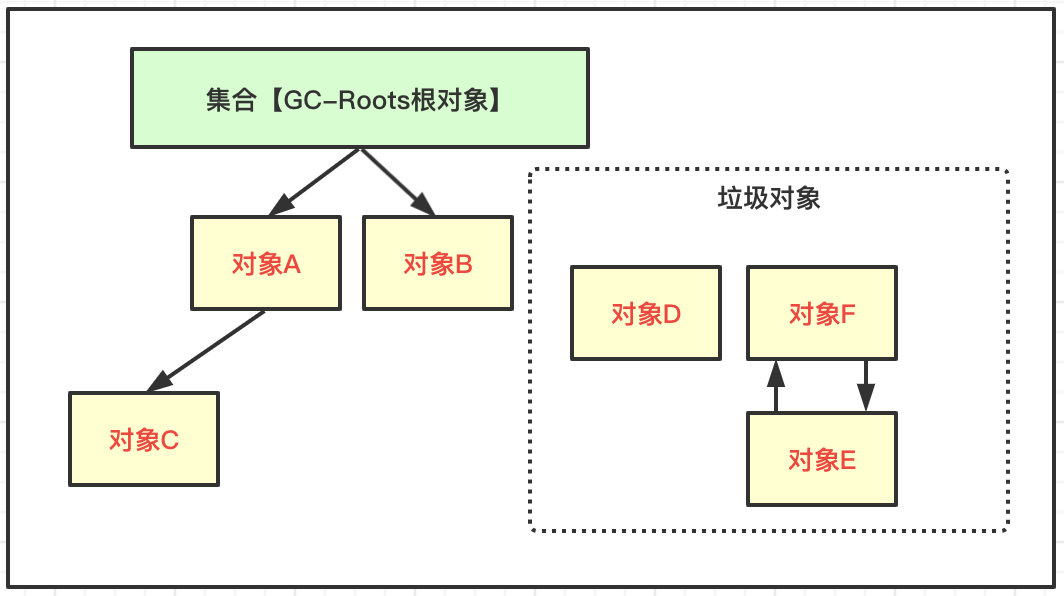
執行程式把所有的引用關係鏈看作一張圖,通過GC-Roots根物件物件集合作為起始點,從每個根節點向下不斷搜尋被根物件集合所連線的物件是否可達,搜尋路徑稱為引用鏈(Reference-Chain),如果物件到GC-Roots沒有任何引用鏈存在,則說明此物件是不可用的,
- 虛擬機器棧中引用的物件;
- 元空間中類靜態屬性引用的物件;
- 元空間中常量引用的物件;
- 本地方法棧中Native方法引用的物件;
相對於引用計數法演算法,可達性分析演算法則避免了迴圈引用導致的問題,同樣具備執行高效的特點,也是JVM採用的標記演算法。
# 三、垃圾回收機制
## 1、標記清除演算法
標記-清除演算法分為標記和清除兩個階段:
標記階段:從根物件集合進行掃描,對存活的物件物件標記;清除階段:再次掃描發現未被標記的物件並進行回收;
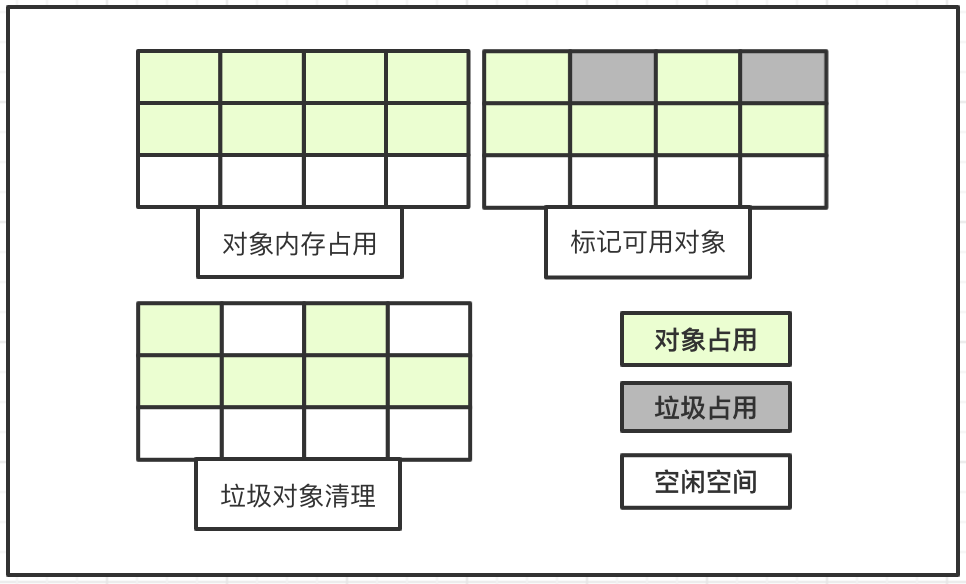
該演算法效率不高,進行垃圾回收需要暫停應用程式,同時會產生大量記憶體碎片,後續程式執行過程中分配記憶體佔用較大的物件時,會有連續記憶體不夠情況,容易觸發再一次垃圾收集動作。
## 2、標記整理演算法
標記整理演算法的標記過程類似標記清除演算法,第一階段:標記出垃圾物件;第二階段:讓所有存活的物件都向記憶體區一端移動;第三階段:直接清理掉邊界端以外的記憶體,類似於磁碟整理的過程;

該垃圾回收演算法效率不高,物件移動過程需要暫停應用程式,適用於物件存活率高的場景(老年代)。
## 3、複製演算法
複製演算法將記憶體按容量劃分為大小相等的兩塊,每次只使用其中的一塊,當使用的這塊的記憶體用完,就將還存活著的物件複製到另外一塊空閒記憶體上,然後使用過的記憶體空間一次清理。
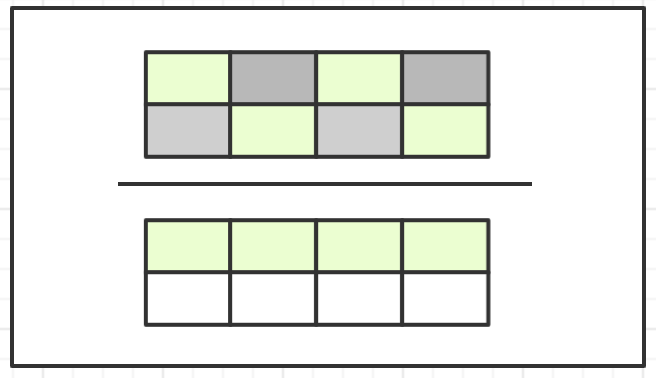
該演算法實現簡單,執行效率高,但是記憶體空間嚴重浪費,適用於物件存活率低的場景,比如新生代。
## 4、分代收集演算法
當前市場上幾乎所有的虛擬機器都採用該回收演算法,分代收集演算法根據年輕代和老年代的各自特點採用不同的演算法機制,不同記憶體區域中物件生命週期也不同,因此對堆記憶體不同區域採用不同的回收策略可以提高垃圾回收執行效率。通常情況新生代物件存活率低,回收頻繁,就採用複製演算法;老年代存物件生命週期長,活率高,就用標記清除演算法或者標記整理演算法。
Java堆記憶體一般可以分為新生代、老年代和永久代三個模組,如下圖所示:
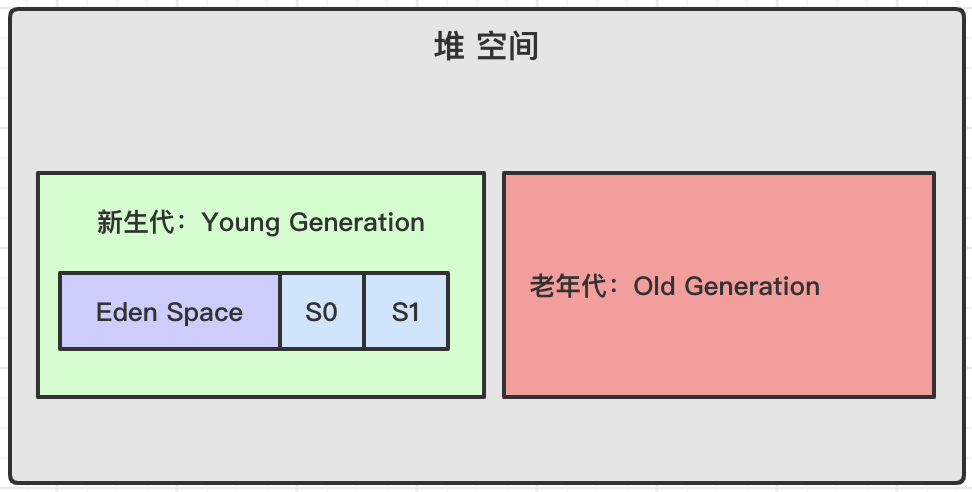
**新生代**
通常情況下,新建立的物件例項首先都是放在新生代空間中,所以追求快速的回收掉垃圾物件,一般情況下,新生代記憶體按照8:1:1的比例分為一個eden區和兩個survivor(survivor0,survivor1)區,物件例項大部分在Eden區中生成;
垃圾回收時先把eden區存活物件複製到S0區,然後清空eden區,當S0區也滿時,再將eden區和S0區存活物件複製到S1區,然後清空eden和S0區,之後交換S0區和S1區的角色,當S1區無法存放eden區和S0區的存活物件時,就將存活物件直接存移到老年代區,當老年代區也滿了,觸發一次FullGC,即新生代、老年代都進行回收。
**老年代**
老年代區存放一些生命週期較長的物件,物件例項在新生代中經歷了多次垃圾回收仍然存活的物件,會被移動到老年代區中。
# 四、原始碼地址
```
GitHub·地址
https://github.com/cicadasmile/java-base-parent
GitEE·地址
https://gitee.com/cicadasmile/java-base-parent
```
**推薦閱讀:程式設計體系整理**
|序號|專案名稱|GitHub地址|GitEE地址|推薦指數|
|:---|:---|:---|:---|:---|
|01|Java描述設計模式,演算法,資料結構|[GitHub·點這裡](https://github.com/cicadasmile/model-arithmetic-parent)|[GitEE·點這裡](https://gitee.com/cicadasmile/model-arithmetic-parent)|☆☆☆☆☆|
|02|Java基礎、併發、面向物件、Web開發|[GitHub·點這裡](https://github.com/cicadasmile/java-base-parent)|[GitEE·點這裡](https://gitee.com/cicadasmile/java-base-parent)|☆☆☆☆|
|03|SpringCloud微服務基礎元件案例詳解|[GitHub·點這裡](https://github.com/cicadasmile/spring-cloud-base)|[GitEE·點這裡](https://gitee.com/cicadasmile/spring-cloud-base)|☆☆☆|
|04|SpringCloud微服務架構實戰綜合案例|[GitHub·點這裡](https://github.com/cicadasmile/husky-spring-cloud)|[GitEE·點這裡](https://gitee.com/cicadasmile/husky-spring-cloud)|☆☆☆☆☆|
|05|SpringBoot框架基礎應用入門到進階|[GitHub·點這裡](https://github.com/cicadasmile/spring-boot-base)|[GitEE·點這裡](https://gitee.com/cicadasmile/spring-boot-base)|☆☆☆☆|
|06|SpringBoot框架整合開發常用中介軟體|[GitHub·點這裡](https://github.com/cicadasmile/middle-ware-parent)|[GitEE·點這裡](https://gitee.com/cicadasmile/middle-ware-parent)|☆☆☆☆☆|
|07|資料管理、分散式、架構設計基礎案例|[GitHub·點這裡](https://github.com/cicadasmile/data-manage-parent)|[GitEE·點這裡](https://gitee.com/cicadasmile/data-manage-parent)|☆☆☆☆☆|
|08|大資料系列、儲存、元件、計算等框架|[GitHub·點這裡](https://github.com/cicadasmile/big-data-parent)|[GitEE·點這裡](https://gitee.com/cicadasmile/big-data-parent)|☆☆☆☆☆