
別隻會搜日誌了,求你懂點檢索原理吧
阿新 • • 發佈:2020-10-09
本篇主要內容如下:
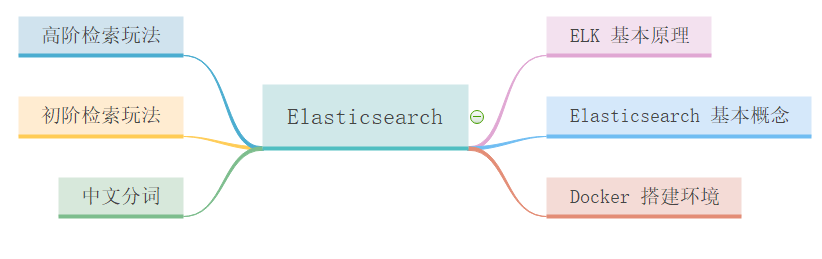
# 前言
專案中我們總是用 `Kibana` 介面來搜尋測試或生產環境下的日誌,來看下有沒有異常資訊。`Kibana` 就是 我們常說的 `ELK` 中的 `K`。
Kibana 介面如下圖所示:
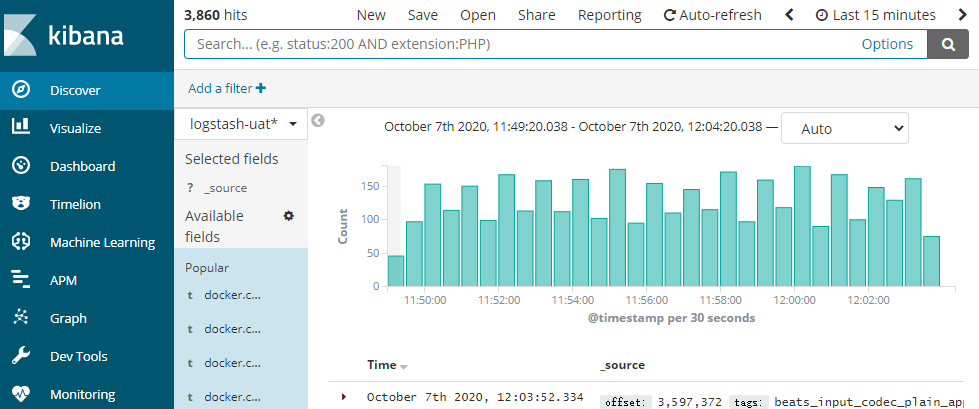
但這些日誌檢索原理是什麼呢?這裡就該我們的 Elasticsearch 搜尋引擎登場了。
**我會分為三篇來講解 Elasticsearch(簡稱ES)的原理、實戰及部署。**
- **上篇:** 講解 ES 的原理、中文分詞的配置。
- **中篇:** 實戰 ES 應用。
- **下篇:** ES 的叢集部署。
為什麼要分成三篇,因為每一篇都很長,而且側重點不一樣,所以分成三篇來講解。
# 一、Elasticsearch 簡介
## 1.1 什麼是 Elasticsearch?
Elasticsearch 是一個分散式的開源搜尋和分析引擎,適用於所有型別的資料,包括文字、數字、地理空間、結構化和非結構化資料。簡單來說只要涉及搜尋和分析相關的, ES 都可以做。
## 1.2 Elasticsearch 的用途?
Elasticsearch 在速度和可擴充套件性方面都表現出色,而且還能夠索引多種型別的內容,這意味著其可用於多種用例:
- 比如一個線上網上商店,您可以在其中允許客戶搜尋您出售的產品。在這種情況下,您可以使用Elasticsearch 儲存整個產品目錄和庫存,併為它們提供搜尋和自動完成建議。
- 比如收集日誌或交易資料,並且要分析和挖掘此資料以查詢趨勢,統計資訊,摘要或異常。在這種情況下,您可以使用 Logstash(Elasticsearch / Logstash / Kibana堆疊的一部分)來收集,聚合和解析資料,然後讓 Logstash 將這些資料提供給 Elasticsearch。資料放入 Elasticsearch 後,您可以執行搜尋和聚合以挖掘您感興趣的任何資訊。
## 1.3 Elasticsearch 的工作原理?
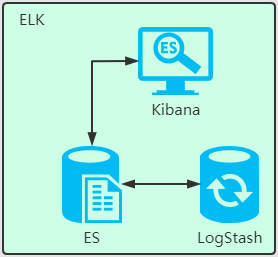
Elasticsearch 是在 Lucene 基礎上構建而成的。ES 在 Lucence 上做了很多增強。
Lucene 是apache軟體基金會 4 的 jakarta 專案組的一個子專案,是一個[開放原始碼](https://baike.baidu.com/item/開放原始碼/114160)的全文檢索引擎工具包,但它不是一個完整的全文檢索引擎,而是一個全文檢索引擎的架構,提供了完整的查詢引擎和索引引擎,部分[文字分析](https://baike.baidu.com/item/文字分析/11046544)引擎(英文與德文兩種西方語言)。Lucene的目的是為軟體開發人員提供一個簡單易用的工具包,以方便的在目標系統中實現全文檢索的功能,或者是以此為基礎建立起完整的全文檢索引擎。(來自百度百科)
**Elasticsearch 的原始資料從哪裡來?**
原始資料從多個來源 ( 包括日誌、系統指標和網路應用程式 ) 輸入到 Elasticsearch 中。
**Elasticsearch 的資料是怎麼採集的?**
資料採集指在 Elasticsearch 中進行索引之前解析、標準化並充實這些原始資料的過程。這些資料在 Elasticsearch 中索引完成之後,使用者便可針對他們的資料運行復雜的查詢,並使用聚合來檢索自身資料的複雜彙總。這裡用到了 Logstash,後面會介紹。
**怎麼視覺化檢視想要檢索的資料?**
這裡就要用到 Kibana 了,使用者可以基於自己的資料進行搜尋、檢視資料檢視等。
## 1.4 Elasticsearch 索引是什麼?
Elasticsearch 索引指相互關聯的文件集合。Elasticsearch 會以 JSON 文件的形式儲存資料。每個文件都會在一組鍵 ( 欄位或屬性的名稱 ) 和它們對應的值 ( 字串、數字、布林值、日期、數值組、地理位置或其他型別的資料 ) 之間建立聯絡。
Elasticsearch 使用的是一種名為倒排索引的資料結構,這一結構的設計可以允許十分快速地進行全文字搜尋。倒排索引會列出在所有文件中出現的每個特有詞彙,並且可以找到包含每個詞彙的全部文件。
在索引過程中,Elasticsearch 會儲存文件並構建倒排索引,這樣使用者便可以近實時地對文件資料進行搜尋。索引過程是在索引 API 中啟動的,通過此 API 您既可向特定索引中新增 JSON 文件,也可更改特定索引中的 JSON 文件。
## 1.5 Logstash 的用途是什麼?
Logstash 就是 `ELK` 中的 `L`。
Logstash 是 Elastic Stack 的核心產品之一,可用來對資料進行聚合和處理,並將資料傳送到 Elasticsearch。Logstash 是一個開源的伺服器端資料處理管道,允許您在將資料索引到 Elasticsearch 之前同時從多個來源採集資料,並對資料進行充實和轉換。
## 1.6 Kibana 的用途是什麼?
Kibana 是一款適用於 Elasticsearch 的資料視覺化和管理工具,可以提供實時的直方圖、線性圖等。
## 1.7 為什麼使用 Elasticsearch
- ES 很快,近實時的搜尋平臺。
- ES 具有分散式的本質特質。
- ES 包含一系列廣泛的功能,比如資料彙總和索引生命週期管理。
官方文件:https://www.elastic.co/cn/what-is/elasticsearch
# 二、ES 基本概念
## 2.1 Index ( 索引 )
動詞:相當於 Mysql 中的 insert
名詞:相當於 Mysql 中的 database
與 mysql 的對比
| 序號 | Mysql | Elasticsearch |
| ---- | -------------------------- | ------------------------- |
| 1 | Mysql 服務 | ES 叢集服務 |
| 2 | 資料庫 Database | 索引 Index |
| 3 | 表 Table | 型別 Type |
| 4 | 記錄 Records ( 一行行記錄 ) | 文件 Document ( JSON 格式 ) |
## 2.2 倒排索引
倒排索引(英語:Inverted index),也常被稱為反向索引、置入檔案或反向檔案,是一種索引方法,被用來儲存在全文搜尋下某個單詞在一個文件或者一組文件中的儲存位置的對映。它是文件檢索系統中最常用的資料結構。通過倒排索引,可以根據單詞快速獲取包含這個單詞的文件列表。
假如資料庫有如下電影記錄:
1-大話西遊
2-大話西遊外傳
3-解析大話西遊
4-西遊降魔外傳
5-夢幻西遊獨家解析
**分詞:將整句分拆為單詞**
| 序號 | 儲存到 ES 的詞 | 對應的電影記錄序號 |
| ---- | ------------ | ------------------ |
| A | 西遊 | 1,2, 3,4, 5 |
| B | 大話 | 1,2, 3 |
| C | 外傳 | 2,4, 5 |
| D | 解析 | 3,5 |
| E | 降魔 | 4 |
| F | 夢幻 | 5 |
| G | 獨家 | 5 |
**檢索:獨家大話西遊**
將 ` 獨家大話西遊 ` 解析拆分成 ` 獨家 `、` 大話 `、` 西遊 `
ES 中 A、B、G 記錄 都有這三個詞的其中一種, 所以 1,2, 3,4, 5 號記錄都有相關的詞被命中。
1 號記錄命中 2 次, A、B 中都有 ( 命中 `2` 次 ) ,而且 1 號記錄有 `2` 個詞,相關性得分:`2` 次/`2` 個詞=`1`
2 號記錄命中 2 個詞 A、B 中的都有 ( 命中 `2` 次 ) ,而且 2 號記錄有 `2` 個詞,相關性得分:`2` 次/`3` 個詞= `0.67`
3 號記錄命中 2 個詞 A、B 中的都有 ( 命中 `2` 次 ) ,而且 3 號記錄有 `2` 個詞,相關性得分:`2` 次/`3` 個詞= `0.67`
4 號記錄命中 2 個詞 A 中有 ( 命中 `1` 次 ) ,而且 4 號記錄有 `2` 個詞,相關性得分:`1` 次/`3` 個詞= `0.33`
5 號記錄命中 2 個詞 A 中有 ( 命中 `2` 次 ) ,而且 4 號記錄有 `4` 個詞,相關性得分:`2` 次/`4` 個詞= `0.5`
**所以檢索出來的記錄順序如下:**
1-大話西遊 ( 想關性得分:1 )
2-大話西遊外傳 ( 想關性得分:0.67 )
3-解析大話西遊 ( 想關性得分:0.67 )
5-夢幻西遊獨家解析 ( 想關性得分:0.5 )
4-西遊降魔 ( 想關性得分:0.33 )
# 三、Docker 搭建環境
## 3.1. 搭建 Elasticsearch 環境
搭建虛擬機器環境和安裝 docker 可以參照之前寫的文件:
- [01. 快速搭建 Linux 環境-運維必備](http://www.jayh.club/#/05.安裝部署篇/01.環境搭建篇)
- [02. 配置虛擬機器網路](http://www.jayh.club/#/05.安裝部署篇/02.配置虛擬機器網路)
- [03. 安裝 Docker](http://www.jayh.club/#/05.安裝部署篇/03.安裝docker)
### 1 ) 下載映象檔案
```sh
docker pull elasticsearch:7.4.2
```
### 2 ) 建立例項
- 1. 對映配置檔案
```sh
配置對映資料夾
mkdir -p /mydata/elasticsearch/config
配置對映資料夾
mkdir -p /mydata/elasticsearch/data
設定資料夾許可權任何使用者可讀可寫
chmod 777 /mydata/elasticsearch -R
配置 http.host
echo "http.host: 0.0.0.0" >> /mydata/elasticsearch/config/elasticsearch.yml
```
- 2. 啟動 elasticsearch 容器
``` sh
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type"="single-node" \
-e ES_JAVA_OPTS="-Xms64m -Xmx128m" \
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
```
- 3. 訪問 elasticsearch 服務
訪問:http://192.168.56.10:9200
返回的 reponse
``` json
{
"name" : "8448ec5f3312",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "xC72O3nKSjWavYZ-EPt9Gw",
"version" : {
"number" : "7.4.2",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "2f90bbf7b93631e52bafb59b3b049cb44ec25e96",
"build_date" : "2019-10-28T20:40:44.881551Z",
"build_snapshot" : false,
"lucene_version" : "8.2.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
```
訪問:http://192.168.56.10:9200/_cat 訪問節點資訊
``` sh
127.0.0.1 62 90 0 0.06 0.10 0.05 dilm * 8448ec5f3312
```
## 3.2. 搭建 Kibana 環境
``` sh
docker pull kibana:7.4.2
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://192.168.56.10:9200 -p 5601:5601 -d kibana:7.4.2
```
訪問 kibana: http://192.168.56.10:5601/
# 四、初階檢索玩法
## 4.1._cat 用法
``` sh
GET /_cat/nodes: 檢視所有節點
GET /_cat/health: 檢視 es 健康狀況
GET /_cat/master: 檢視主節點
GET /_cat/indices: 檢視所有索引
查詢彙總:
/_cat/allocation
/_cat/shards
/_cat/shards/{index}
/_cat/master
/_cat/nodes
/_cat/tasks
/_cat/indices
/_cat/indices/{index}
/_cat/segments
/_cat/segments/{index}
/_cat/count
/_cat/count/{index}
/_cat/recovery
/_cat/recovery/{index}
/_cat/health
/_cat/pending_tasks
/_cat/aliases
/_cat/aliases/{alias}
/_cat/thread_pool
/_cat/thread_pool/{thread_pools}
/_cat/plugins
/_cat/fielddata
/_cat/fielddata/{fields}
/_cat/nodeattrs
/_cat/repositories
/_cat/snapshots/{repository}
/_cat/templates
```
## 4.2. 索引一個文件 ( 儲存 )
例子:在 `customer` 索引下的 `external` 型別下儲存標識為 `1` 的資料。
- 使用 Kibana 的 Dev Tools 來建立
``` sh
PUT member/external/1
{
"name":"jay huang"
}
```
Reponse:
``` json
{
"_index": "member", //在哪個索引
"_type": "external",//在那個型別
"_id": "2",//記錄 id
"_version": 7,//版本號
"result": "updated",//操作型別
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 9,
"_primary_term": 1
}
```
- 也可以通過 Postman 工具傳送請求來建立記錄。
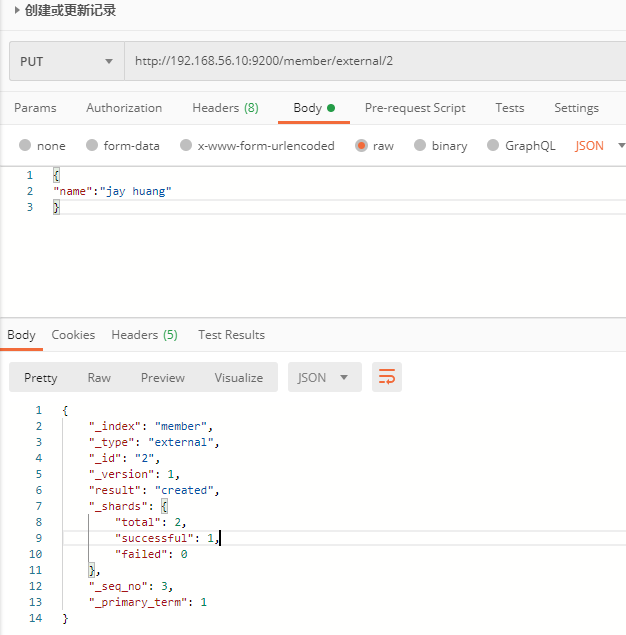
注意:
PUT 和 POST 都可以建立記錄。
POST:如果不指定 id,自動生成 id。如果指定 id,則修改這條記錄,並新增版本號。
PUT:必須指定 id,如果沒有這條記錄,則新增,如果有,則更新。
## 4.3 查詢文件
``` json
請求:http://192.168.56.10:9200/member/external/2
Reposne:
{
"_index": "member", //在哪個索引
"_type": "external", //在那個型別
"_id": "2", //記錄 id
"_version": 7, //版本號
"_seq_no": 9, //併發控制欄位,每次更新就會+1,用來做樂觀鎖
"_primary_term": 1, //同上,主分片重新分配,如重啟,就會變化
"found": true,
"_source": { //真正的內容
"name": "jay huang"
}
}
```
_seq_no 用作樂觀鎖
每次更新完資料後,_seq_no 就會+1,所以可以用作併發控制。
當更新記錄時,如果_seq_no 與預設的值不一致,則表示記錄已經被至少更新了一次,不允許本次更新。
用法如下:
``` json
請求更新記錄 2: http://192.168.56.10:9200/member/external/2?if_seq_no=9&&if_primary_term=1
返回結果:
{
"_index": "member",
"_type": "external",
"_id": "2",
"_version": 9,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 11,
"_primary_term": 1
}
```
_seq_no 等於 10,且_primary_term=1 時更新資料,執行一次請求後,再執行上面的請求則會報錯:版本衝突
``` json
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[2]: version conflict, required seqNo [10], primary term [1]. current document has seqNo [11] and primary term [1]",
"index_uuid": "CX6uwPBKRByWpuym9rMuxQ",
"shard": "0",
"index": "member"
}
],
"type": "version_conflict_engine_exception",
"reason": "[2]: version conflict, required seqNo [10], primary term [1]. current document has seqNo [11] and primary term [1]",
"index_uuid": "CX6uwPBKRByWpuym9rMuxQ",
"shard": "0",
"index": "member"
},
"status": 409
}
```
## 4.4 更新文件
- 用法
POST 帶 `_update` 的更新操作,如果原資料沒有變化,則 repsonse 中的 result 返回 noop ( 沒有任何操作 ) ,version 也不會變化。
請求體中需要用 `doc` 將請求資料包裝起來。
```
POST 請求:http://192.168.56.10:9200/member/external/2/_update
{
"doc":{
"name":"jay huang"
}
}
響應:
{
"_index": "member",
"_type": "external",
"_id": "2",
"_version": 12,
"result": "noop",
"_shards": {
"total": 0,
"successful": 0,
"failed": 0
},
"_seq_no": 14,
"_primary_term": 1
}
```
使用場景:對於大併發更新,建議不帶 `_update`。對於大併發查詢,少量更新的場景,可以帶_update,進行對比更新。
- 更新時增加屬性
請求體中增加 `age` 屬性
``` json
http://192.168.56.10:9200/member/external/2/_update
request:
{
"doc":{
"name":"jay huang",
"age": 18
}
}
response:
{
"_index": "member",
"_type": "external",
"_id": "2",
"_version": 13,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 15,
"_primary_term": 1
}
```
## 4.5 刪除文件和索引
- 刪除文件
``` json
DELETE 請求:http://192.168.56.10:9200/member/external/2
response:
{
"_index": "member",
"_type": "external",
"_id": "2",
"_version": 2,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
```
- 刪除索引
``` json
DELETE 請求:http://192.168.56.10:9200/member
repsonse:
{
"acknowledged": true
}
```
- 沒有刪除型別的功能
## 4.6 批量匯入資料
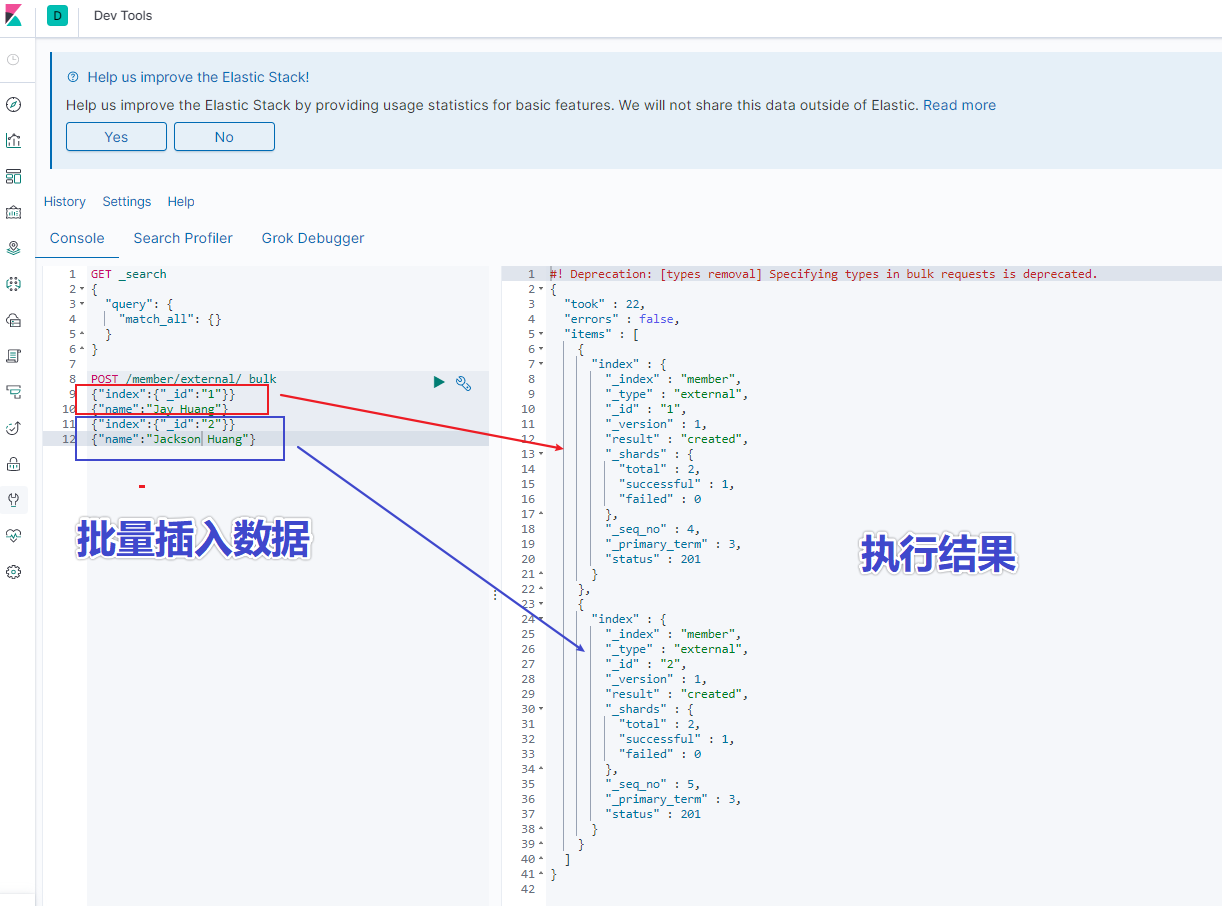
使用 kinaba 的 dev tools 工具,輸入以下語句
``` json
POST /member/external/_bulk
{"index":{"_id":"1"}}
{"name":"Jay Huang"}
{"index":{"_id":"2"}}
{"name":"Jackson Huang"}
```
執行結果如下圖所示:
- 拷貝官方樣本資料
``` http
https://raw.githubusercontent.com/elastic/elasticsearch/master/docs/src/test/resources/accounts.json
```

- 在 kibana 中執行指令碼
``` json
POST /bank/account/_bulk
{"index":{"_id":"1"}}
{"account_number":1,"balance":39225,"firstname":"Amber","lastname":"Duke","age":32,"gender":"M","address":"880 Holmes Lane","employer":"Pyrami","email":"[email protected]","city":"Brogan","state":"IL"}
{"index":{"_id":"6"}}
......
```
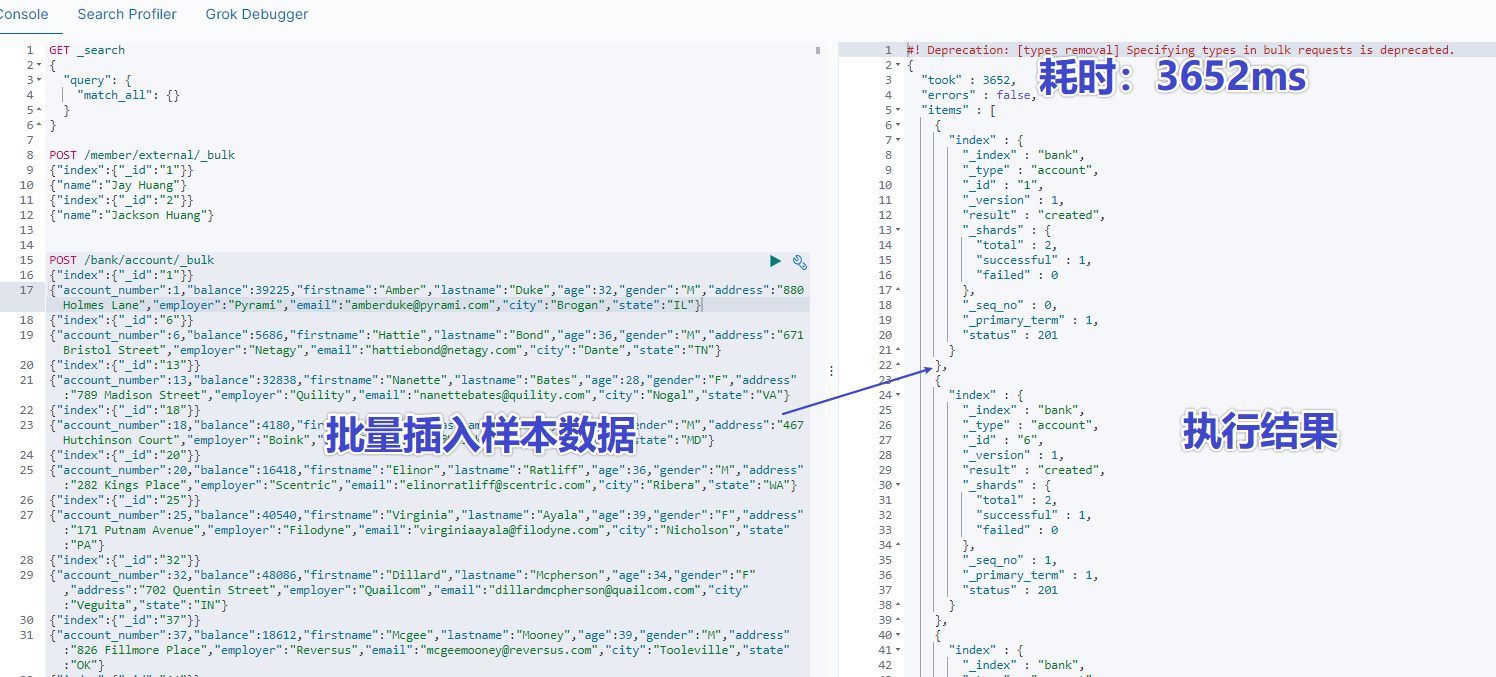
- 檢視所有索引
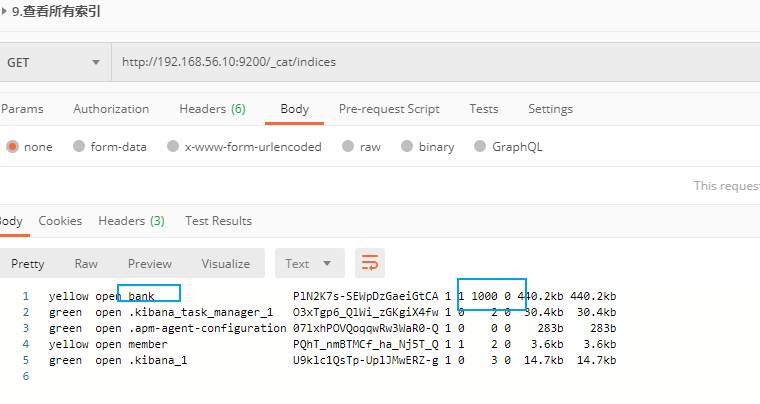
可以從返回結果中看到 bank 索引有 1000 條資料,佔用了 440.2kb 儲存空間。
# 五、高階檢索玩法
## 5.1 兩種查詢方式
### 5.1.1 URL 後接引數
``` json
GET bank/_search?q=*&sort=account_number: asc
```
```/_search?q=*&sort=account_number: asc`
查詢出所有資料,共 1000 條資料,耗時 1ms,只展示 10 條資料 ( ES 分頁 )
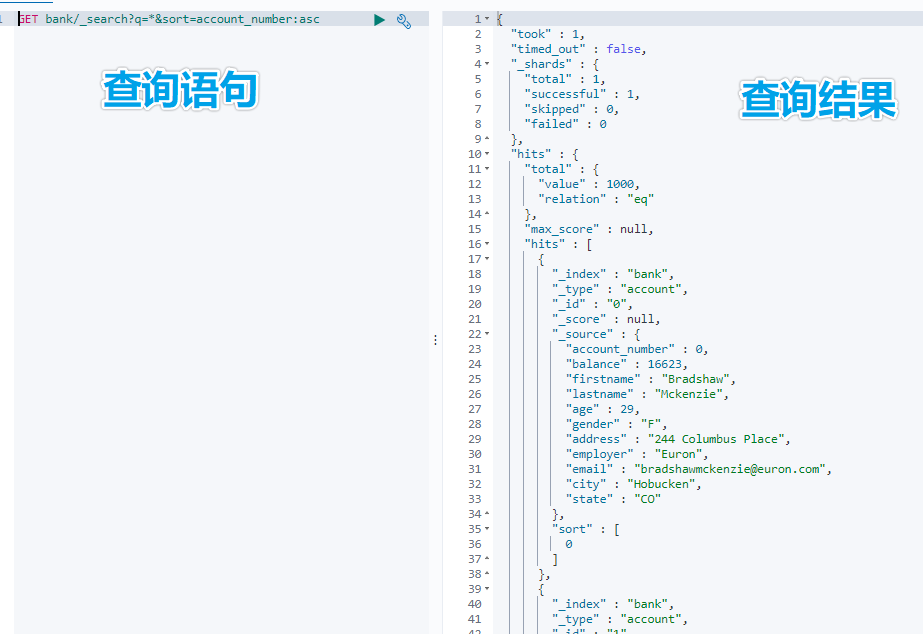
屬性值說明:
``` javascript
took – ES 執行搜尋的時間 ( 毫秒 )
timed_out – ES 是否超時
_shards – 有多少個分片被搜尋了,以及統計了成功/失敗/跳過的搜尋的分片
max_score – 最高得分
hits.total.value - 命中多少條記錄
hits.sort - 結果的排序 key 鍵,沒有則按 score 排序
hits._score - 相關性得分
參考文件:
https://www.elastic.co/guide/en/elasticsearch/reference/current/getting-started-search.html
```
### 5.1.2 URL 加請求體進行檢索 ( QueryDSL )
請求體中寫查詢條件
語法:
```json
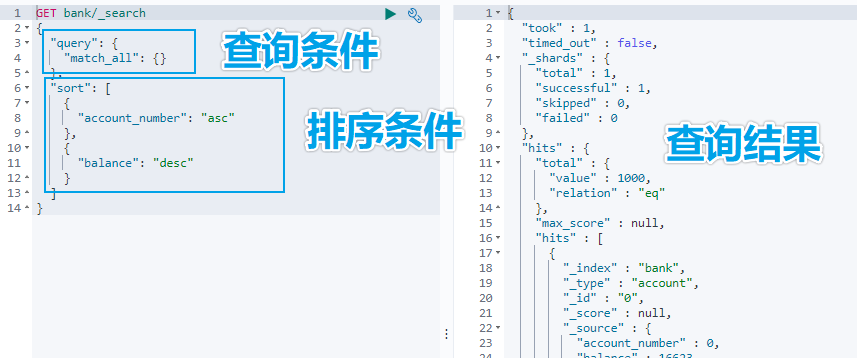
GET bank/_search
{
"query":{"match_all": {}},
"sort": [
{"account_number": "asc" }
]
}
```
示例:查詢出所有,先按照 accout_number 升序排序,再按照 balance 降序排序
## 5.2 詳解 QueryDSL 查詢
> DSL: Domain Specific Language
### 5.2.1 全部匹配 match_all
示例:查詢所有記錄,按照 balance 降序排序,只返回第 11 條記錄到第 20 條記錄,只顯示 balance 和 firstname 欄位。
``` json
GET bank/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"balance": {
"order": "desc"
}
}
],
"from": 10,
"size": 10,
"_source": ["balance", "firstname"]
}
```
### 5.2.2 匹配查詢 match
- 基本型別 ( 非字串 ) ,精確匹配
``` json
GET bank/_search
{
"query": {
"match": {"account_number": "30"}
}
}
```
- 字串,全文檢索
``` json
GET bank/_search
{
"query": {
"match": {
"address": "mill road"
}
}
}
```
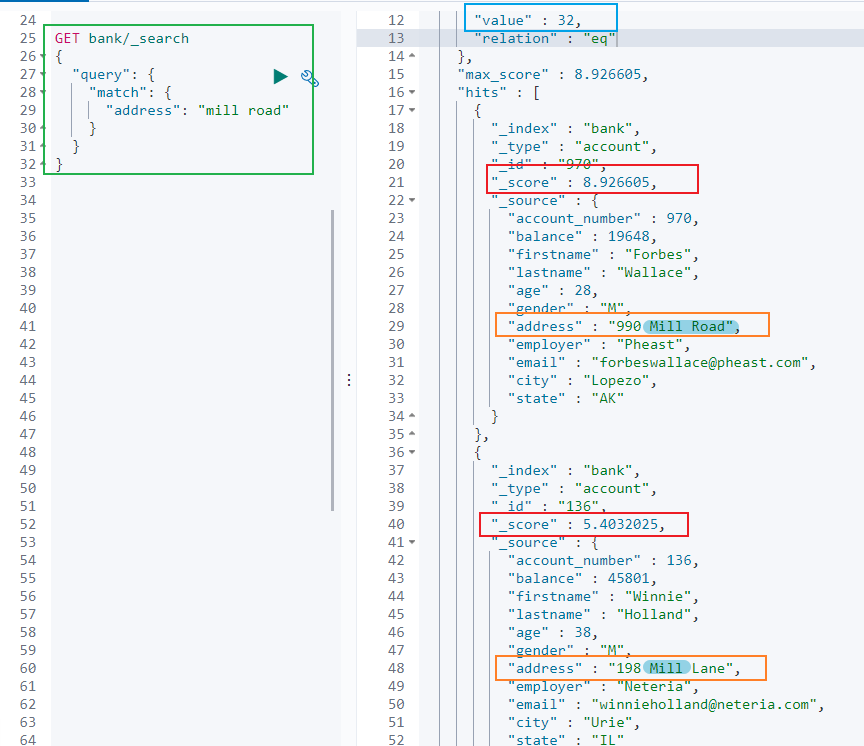
> 全文檢索按照評分進行排序,會對檢索條件進行分詞匹配。
>
> 查詢 `address` 中包含 `mill` 或者 `road` 或者 `mill road` 的所有記錄,並給出相關性得分。
查到了 32 條記錄,最高的一條記錄是 Address = "990 Mill Road",得分:8.926605. Address="198 Mill Lane" 評分 5.4032025,只匹配到了 Mill 單詞。
### 5.2.3 短語匹配 match_phase
將需要匹配的值當成一個整體單詞 ( 不分詞 ) 進行檢索
``` json
GET bank/_search
{
"query": {
"match_phrase": {
"address": "mill road"
}
}
}
```
> 查出 address 中包含 `mill road` 的所有記錄,並給出相關性得分
### 5.2.4 多欄位匹配 multi_match
``` json
GET bank/_search
{
"query": {
"multi_match": {
"query": "mill land",
"fields": [
"state",
"address"
]
}
}
}
```
> multi_match 中的 query 也會進行分詞。
>
> 查詢 `state` 包含 `mill` 或 `land` 或者 `address` 包含 `mill` 或 `land` 的記錄。
### 5.2.5 複合查詢 bool
> 複合語句可以合併任何其他查詢語句,包括複合語句。複合語句之間可以相互巢狀,可以表達複雜的邏輯。
搭配使用 must,must_not,should
must: 必須達到 must 指定的條件。 ( 影響相關性得分 )
must_not: 必須不滿足 must_not 的條件。 ( 不影響相關性得分 )
should: 如果滿足 should 條件,則可以提高得分。如果不滿足,也可以查詢出記錄。 ( 影響相關性得分 )
示例:查詢出地址包含 mill,且性別為 M,年齡不等於 28 的記錄,且優先展示 firstname 包含 Winnie 的記錄。
``` json
GET bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"address": "mill"
}
},
{
"match": {
"gender": "M"
}
}
],
"must_not": [
{
"match": {
"age": "28"
}
}
],
"should": [
{
"match": {
"firstname": "Winnie"
}
}
]
}
}
}
```
### 5.2.6 filter 過濾
> 不影響相關性得分,查詢出滿足 filter 條件的記錄。
>
> 在 bool 中使用。
``` json
GET bank/_search
{
"query": {
"bool": {
"filter": [
{
"range": {
"age": {
"gte":18,
"lte":40
}
}
}
]
}
}
}
```
### 5.2.7 term 查詢
> 匹配某個屬性的值。
>
> 全文檢索欄位用 match,其他非 text 欄位匹配用 term
>
> keyword:文字精確匹配 ( 全部匹配 )
>
> match_phase:文字短語匹配
``` json
非 text 欄位精確匹配
GET bank/_search
{
"query": {
"term": {
"age": "20"
}
}
}
```
### 5.2.8 aggregations 聚合
> 聚合:從資料中分組和提取資料。類似於 SQL GROUP BY 和 SQL 聚合函式。
>
> Elasticsearch 可以將命中結果和多個聚合結果同時返回。
聚合語法:
``` json
"aggregations" : {
"<聚合名稱 1>" : {
"<聚合型別>" : {
<聚合體內容>
}
[,"元資料" : { [] }]?
[,"aggregations" : { []+ }]?
}
[,"聚合名稱 2>" : { ... }]*
}
```
- 示例 1:搜尋 address 中包含 big 的所有人的年齡分佈 ( 前 10 條 ) 以及平均年齡,以及平均薪資
``` json
GET bank/_search
{
"query": {
"match": {
"address": "mill"
}
},
"aggs": {
"ageAggr": {
"terms": {
"field": "age",
"size": 10
}
},
"ageAvg": {
"avg": {
"field": "age"
}
},
"balanceAvg": {
"avg": {
"field": "balance"
}
}
}
}
```
檢索結果如下所示:
hits 記錄返回了,三種聚合結果也返回了,平均年齡 34 隨,平均薪資 25208.0,品駿年齡分佈:38 歲的有 2 個,28 歲的有一個,32 歲的有一個
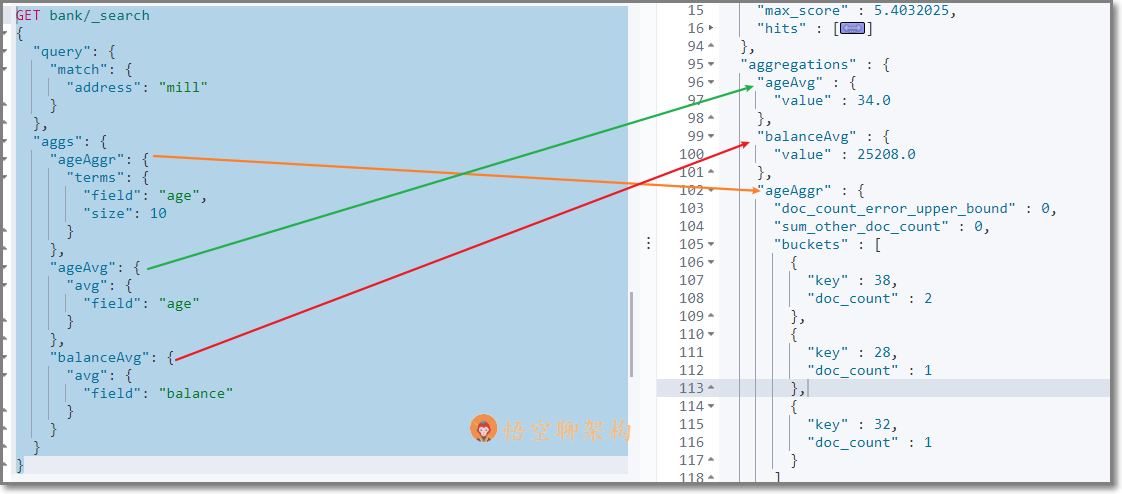
如果不想返回 hits 結果,可以在最後面設定 size:0
``` json
GET bank/_search
{
"query": {
"match": {
"address": "mill"
}
},
"aggs": {
"ageAggr": {
"terms": {
"field": "age",
"size": 10
}
}
},
"size": 0
}
```
- 示例 2:按照年齡聚合,並且查詢這些年齡段的平均薪資
從結果可以看到 31 歲的有 61 個,平均薪資 28312.9,其他年齡的聚合結果類似。
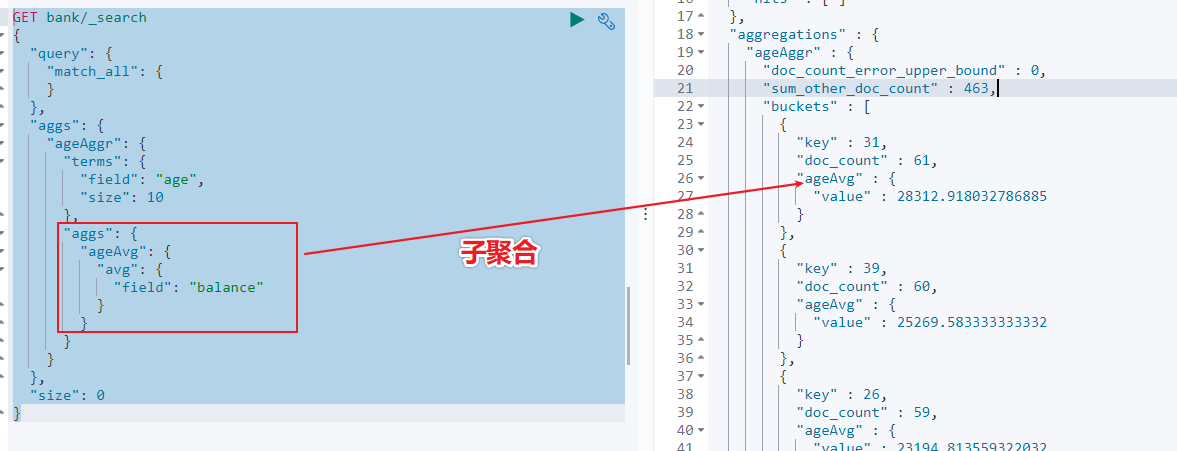
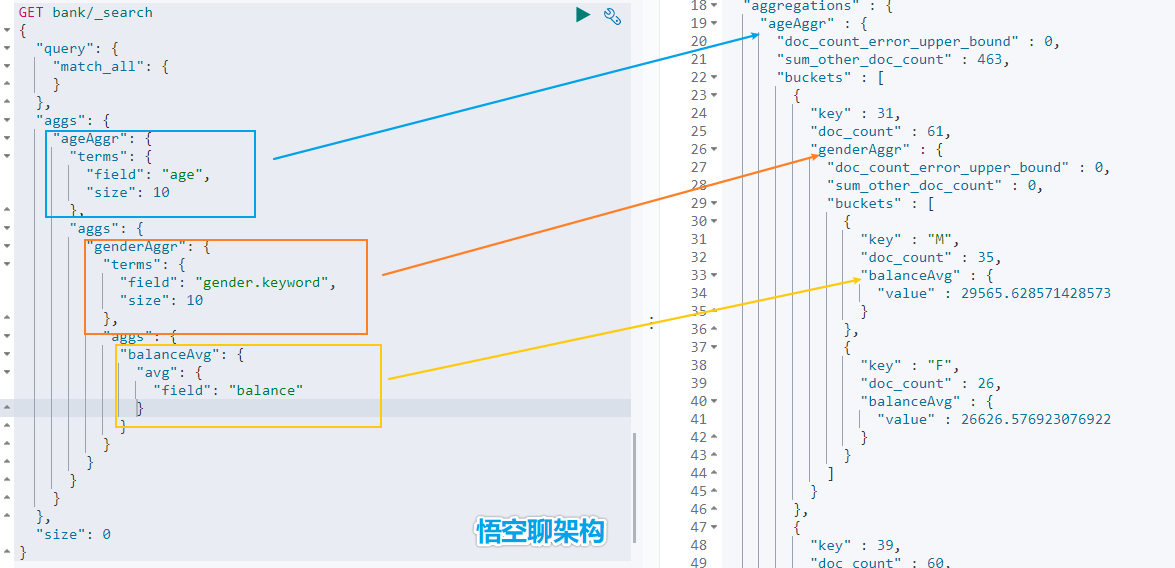
- 示例 3:按照年齡分組,然後將分組後的結果按照性別分組,然後查詢出這些分組後的平均薪資
``` json
GET bank/_search
{
"query": {
"match_all": {
}
},
"aggs": {
"ageAggr": {
"terms": {
"field": "age",
"size": 10
},
"aggs": {
"genderAggr": {
"terms": {
"field": "gender.keyword",
"size": 10
},
"aggs": {
"balanceAvg": {
"avg": {
"field": "balance"
}
}
}
}
}
}
},
"size": 0
}
```
從結果可以看到 31 歲的有 61 個。其中性別為 `M` 的 35 個,平均薪資 29565.6,性別為 `F` 的 26 個,平均薪資 26626.6。其他年齡的聚合結果類似。
### 5.2.9 Mapping 對映
> Mapping 是用來定義一個文件 ( document ) ,以及它所包含的屬性 ( field ) 是如何儲存和索引的。
- 定義哪些字串屬性應該被看做全文字屬性 ( full text fields )
- 定義哪些屬性包含數字,日期或地理位置
- 定義文件中的所有屬性是否都能被索引 ( _all 配置 )
- 日期的格式
- 自定義對映規則來執行動態新增屬性
Elasticsearch7 去掉 tpye 概念:
關係型資料庫中兩個資料庫表示是獨立的,即使他們裡面有相同名稱的列也不影響使用,但 ES 中不是這樣的。elasticsearch 是基於 Lucence 開發的搜尋引擎,而 ES 中不同 type 下名稱相同的 field 最終在 Lucence 中的處理方式是一樣的。
為了區分不同 type 下的同一名稱的欄位,Lucence 需要處理衝突,導致檢索效率下降
ES7.x 版本:URL 中的 type 引數為可選。
ES8.x 版本:不支援 URL 中的 type 引數
所有型別可以參考文件:https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-types.html
- 查詢索引的對映
如查詢 my-index 索引的對映
``` json
GET /my-index/_mapping
返回結果:
{
"my-index" : {
"mappings" : {
"properties" : {
"age" : {
"type" : "integer"
},
"email" : {
"type" : "keyword"
},
"employee-id" : {
"type" : "keyword",
"index" : false
},
"name" : {
"type" : "text"
}
}
}
}
}
```
- 建立索引並指定對映
如建立 my-index 索引,有三個欄位 age,email,name,指定型別為 interge, keyword, text
``` json
PUT /my-index
{
"mappings": {
"properties": {
"age": { "type": "integer" },
"email": { "type": "keyword" },
"name": { "type": "text" }
}
}
返回結果:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "my-index"
}
```
- 新增新的欄位對映
如在 my-index 索引裡面新增 employ-id 欄位,指定型別為 keyword
``` json
PUT /my-index/_mapping
{
"properties": {
"employee-id": {
"type": "keyword",
"index": false
}
}
}
```
- 更新對映
> 我們不能更新已經存在的對映欄位,必須建立新的索引進行資料遷移。
- 資料遷移
``` json
POST _reindex
{
"source": {
"index": "twitter"
},
"dest": {
"index": "new_twitter"
}
}
```
# 六、中文分詞
ES 內建了很多種分詞器,但是對中文分詞不友好,所以我們需要藉助第三方中文分詞工具包。
## 6.1 ES 中的分詞的原理
### 6.1.1 ES 的分詞器概念
ES 的一個分詞器 ( tokenizer ) 接收一個字元流,將其分割為獨立的詞元 ( tokens ) ,然後輸出詞元流。
ES 提供了很多內建的分詞器,可以用來構建自定義分詞器 ( custom ananlyzers )
### 6.1.2 標準分詞器原理
比如 stadard tokenizer 標準分詞器,遇到空格進行分詞。該分詞器還負責記錄各個詞條 ( term ) 的順序或 position 位置 ( 用於 phrase 短語和 word proximity 詞近鄰查詢 ) 。每個單詞的字元偏移量 ( 用於高亮顯示搜尋的內容 ) 。
### 6.1.3 英文和標點符號分詞示例
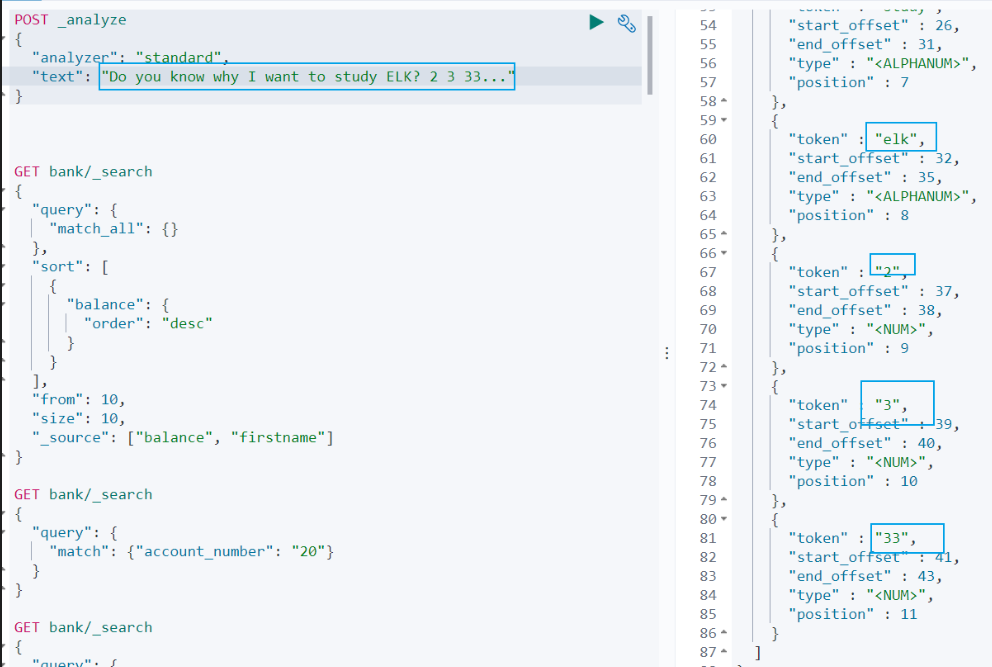
查詢示例如下:
``` json
POST _analyze
{
"analyzer": "standard",
"text": "Do you know why I want to study ELK? 2 3 33..."
}
```
查詢結果:
``` sh
do, you, know, why, i, want, to, study, elk, 2,3,33
```
從查詢結果可以看到:
(1)標點符號沒有分詞。
(2)數字會進行分詞。
### 6.1.4 中文分詞示例
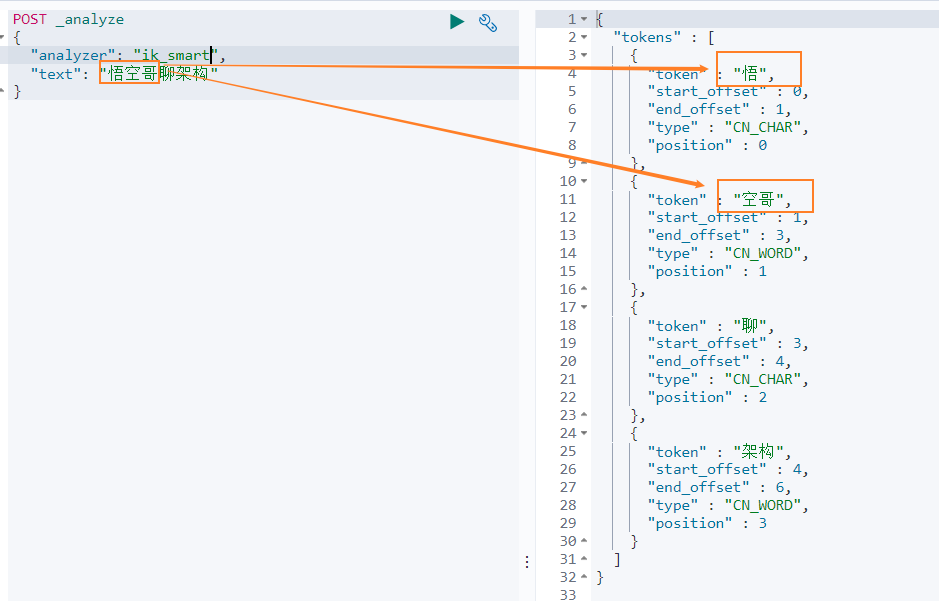
但是這種分詞器對中文的分詞支援不友好,會將詞語分詞為單獨的漢字。比如下面的示例會將 ` 悟空聊架構 ` 分詞為 ` 悟 `,` 空 `,` 聊 `,` 架 `,` 構 `,期望分詞為 ` 悟空 `,` 聊 `,` 架構 `。
``` json
POST _analyze
{
"analyzer": "standard",
"text": "悟空聊架構"
}
```
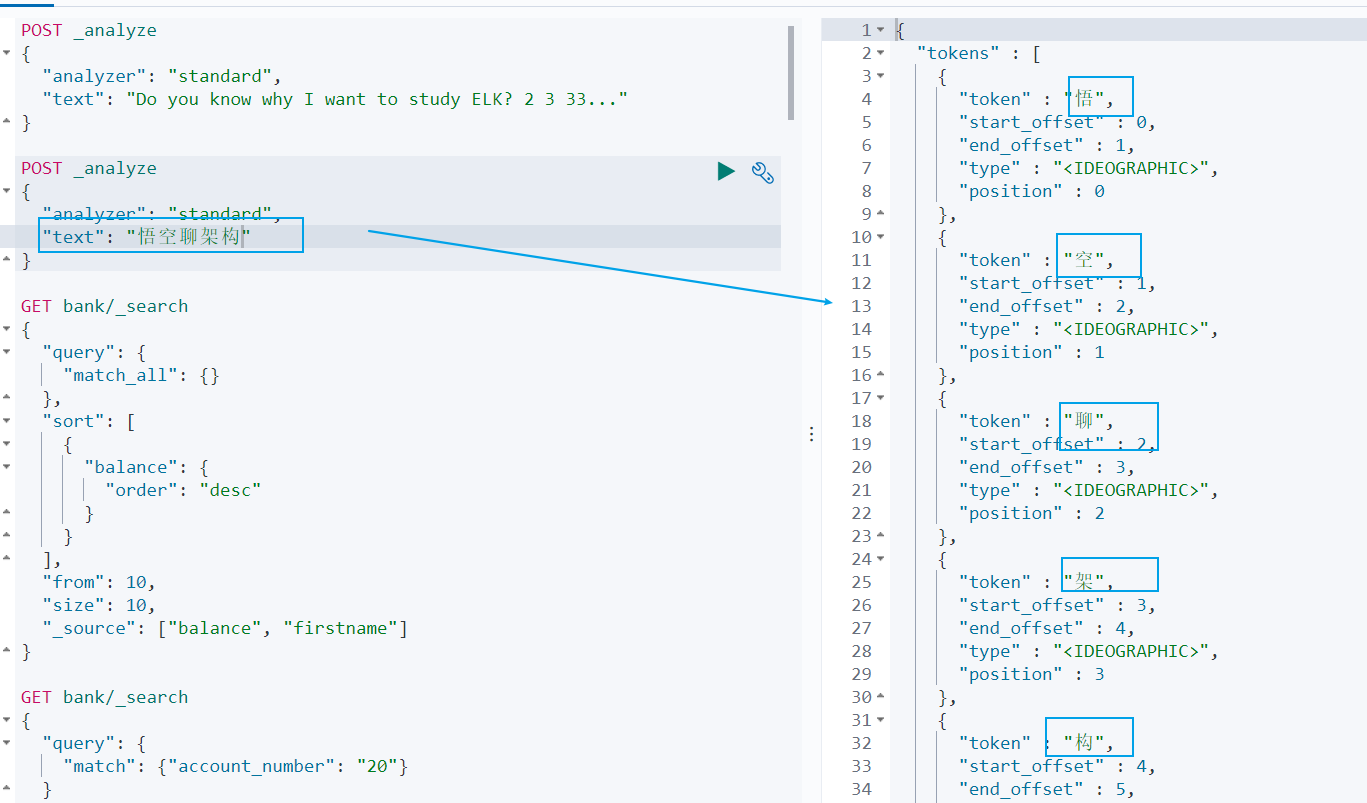
我們可以安裝 ik 分詞器來更加友好的支援中文分詞。
## 6.2 安裝 ik 分詞器
### 6.2.1 ik 分詞器地址
ik 分詞器地址:
``` js
https://github.com/medcl/elasticsearch-analysis-ik/releases
```
先檢查 ES 版本,我安裝的版本是 `7.4.2`,所以我們安裝 ik 分詞器的版本也選擇 7.4.2
``` json
http://192.168.56.10:9200/
{
"name" : "8448ec5f3312",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "xC72O3nKSjWavYZ-EPt9Gw",
"version" : {
"number" : "7.4.2",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "2f90bbf7b93631e52bafb59b3b049cb44ec25e96",
"build_date" : "2019-10-28T20:40:44.881551Z",
"build_snapshot" : false,
"lucene_version" : "8.2.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
```
### 6.2.2 安裝 ik 分詞器的方式
#### 6.2.2.1 方式一:容器內安裝 ik 分詞器
- 進入 es 容器內部 plugins 目錄
``` sh
docker exec -it <容器 id> /bin/bash
```
- 獲取 ik 分詞器壓縮包
``` sh
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.2/elasticsearch-analysis-ik-7.4.2.zip
```
- 解壓縮 ik 壓縮包
``` sh
unzip 壓縮包
```
- 刪除下載的壓縮包
``` sh
rm -rf *.zip
```
#### 6.2.2.2 方式二:對映檔案安裝 ik 分詞器
進入到對映資料夾
```sh
cd /mydata/elasticsearch/plugins
```
下載安裝包
```sh
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.2/elasticsearch-analysis-ik-7.4.2.zip
```
- 解壓縮 ik 壓縮包
``` sh
unzip 壓縮包
```
- 刪除下載的壓縮包
``` sh
rm -rf *.zip
```
#### 6.2.2.3 方式三:Xftp 上傳壓縮包到對映目錄
先用 XShell 工具連線虛擬機器 ( 操作步驟可以參考之前寫的文章 [02. 快速搭建 Linux 環境-運維必備] ( http://www.jayh.club/#/05. 安裝部署篇/01. 環境搭建篇 )) ,然後用 Xftp 將下載好的安裝包複製到虛擬機器。
## 6.3 解壓 ik 分詞器到容器中
- 如果沒有安裝 unzip 解壓工具,則安裝 unzip 解壓工具。
```sh
apt install unzip
```
- 解壓 ik 分詞器到當前目錄的 ik 資料夾下。
命令格式:unzip
例項:
``` sh
unzip ELK-IKv7.4.2.zip -d ./ik
```

- 修改資料夾許可權為可讀可寫。
``` sh
chmod -R 777 ik/
```
- 刪除 ik 分詞器壓縮包
``` sh
rm ELK-IKv7.4.2.zip
```
## 6.4 檢查 ik 分詞器安裝
- 進入到容器中
``` sh
docker exec -it <容器 id> /bin/bash
```
- 檢視 Elasticsearch 的外掛
``` sh
elasticsearch-plugin list
```
結果如下,說明 ik 分詞器安裝好了。是不是很簡單。
``` sh
ik
```

然後退出 Elasticsearch 容器,並重啟 Elasticsearch 容器
``` sh
exit
docker restart elasticsearch
```
## 6.5 使用 ik 中文分詞器
ik 分詞器有兩種模式
- 智慧分詞模式 ( ik_smart )
- 最大組合分詞模式 ( ik_max_word )
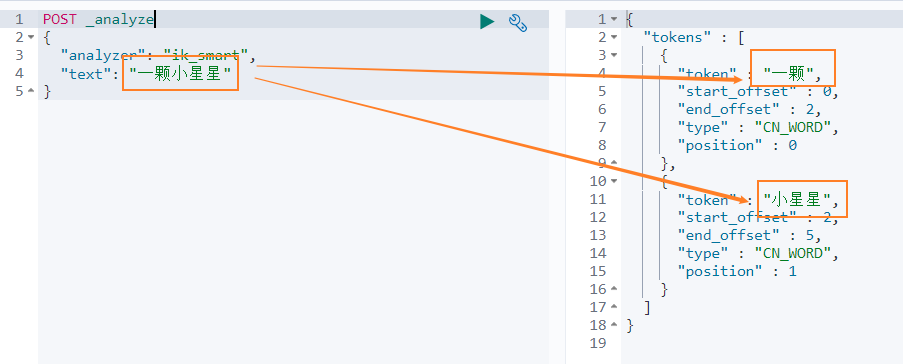
我們先看下 ` 智慧分詞 ` 模式的效果。比如對於 ` 一顆小星星 ` 進行中文分詞,得到的兩個詞語:` 一顆 `、` 小星星 `
我們在 Dev Tools Console 輸入如下查詢
``` json
POST _analyze
{
"analyzer": "ik_smart",
"text": "一顆小星星"
}
```
得到如下結果,被分詞為 一顆和小星星。
再來看下 ` 最大組合分詞模式 `。輸入如下查詢語句。
``` json
POST _analyze
{
"analyzer": "ik_max_word",
"text": "一顆小星星"
}
```
` 一顆小星星 ` 被分成了 6 個詞語:一顆、一、顆、小星星、小星、星星。
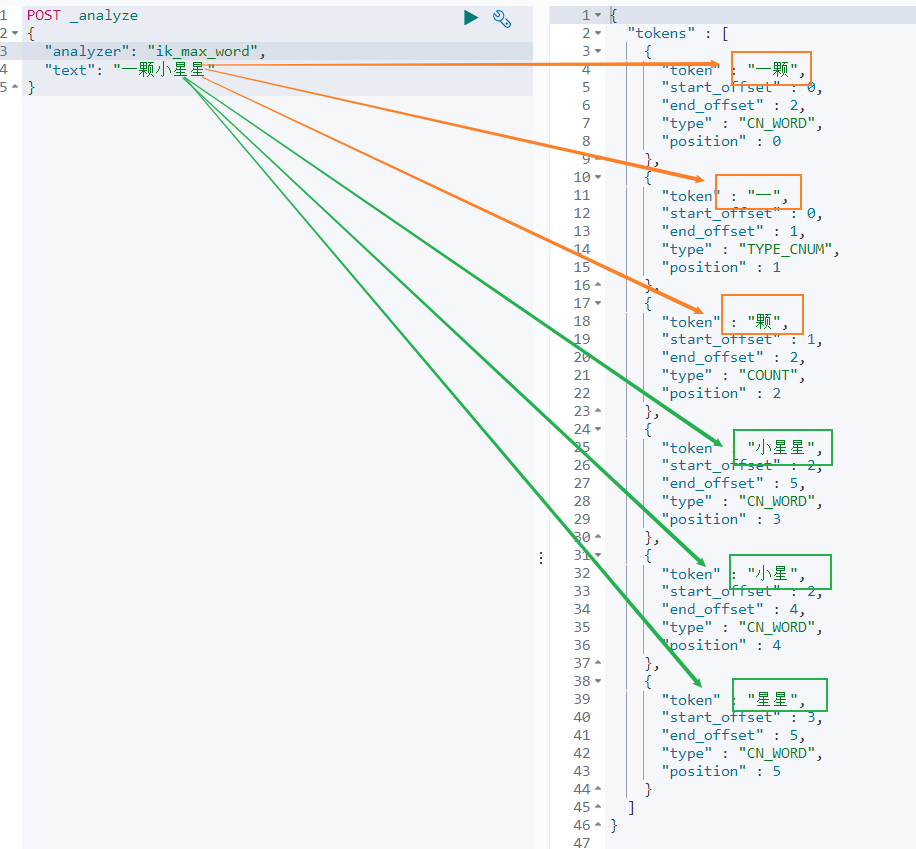
我們再來看下另外一箇中文分詞。比如搜尋悟空哥聊架構,期望結果:悟空哥、聊、架構三個詞語。
實際結果:悟、空哥、聊、架構四個詞語。ik 分詞器將悟空哥分詞了,認為 ` 空哥 ` 是一個詞語。所以需要讓 ik 分詞器知道 ` 悟空哥 ` 是一個詞語,不需要拆分。那怎麼辦做呢?
## 6.5 自定義分詞詞庫
### 6.5.1 自定義詞庫的方案
- 方案
新建一個詞庫檔案,然後在 ik 分詞器的配置檔案中指定分詞詞庫檔案的路徑。可以指定本地路徑,也可以指定遠端伺服器檔案路徑。這裡我們使用遠端伺服器檔案的方案,因為這種方案可以支援熱更新 ( 更新伺服器檔案,ik 分詞詞庫也會重新載入 ) 。
- 修改配置檔案
ik 分詞器的配置檔案在容器中的路徑:
``` sh
/usr/share/elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml。
```
修改這個檔案可以通過修改對映檔案,檔案路徑:
``` sh
/mydata/elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml
```
編輯配置檔案:
``` sh
vim /mydata/elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml
```
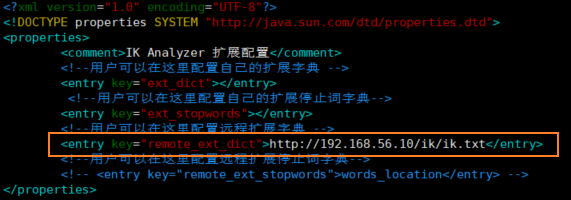
配置檔案內容如下所示:
``` xml
IK Analyzer 擴充套件配置
custom/mydict.dic;custom/single_word_low_freq.dic
custom/ext_stopword.dic
location
http://xxx.com/xxx.dic
```
修改配置 `remote_ext_dict` 的屬性值,指定一個 遠端網站檔案的路徑,比如 http://www.xxx.com/ikwords.text。
這裡我們可以自己搭建一套 nginx 環境,然後把 ikwords.text 放到 nginx 根目錄。
### 6.5.2 搭建 nginx 環境
方案:首先獲取 nginx 映象,然後啟動一個 nginx 容器,然後將 nginx 的配置檔案拷貝到根目錄,再刪除原 nginx 容器,再用對映資料夾的方式來重新啟動 nginx 容器。
- 通過 docker 容器安裝 nginx 環境。
``` sh
docker run -p 80:80 --name nginx -d nginx:1.10
```
- 拷貝 nginx 容器的配置檔案到 mydata 目錄的 conf 資料夾
``` sh
cd /mydata
docker container cp nginx:/etc/nginx ./conf
```
- mydata 目錄 裡面建立 nginx 目錄
``` sh
mkdir nginx
```
- 移動 conf 資料夾到 nginx 對映資料夾
``` sh
mv conf nginx/
```
- 終止並刪除原 nginx 容器
``` sh
docker stop nginx
docker rm <容器 id>
```
- 啟動新的容器
```sh
docker run -p 80:80 --name nginx \
-v /mydata/nginx/html:/usr/share/nginx/html \
-v /mydata/nginx/logs:/var/log/nginx \
-v /mydata/nginx/conf:/etc/nginx \
-d nginx:1.10
```
- 訪問 nginx 服務
``` sh
192.168.56.10
```
報 403 Forbidden, nginx/1.10.3 則表示 nginx 服務正常啟動。403 異常的原因是 nginx 服務下沒有檔案。
- nginx 目錄新建一個 html 檔案
``` sh
cd /mydata/nginx/html
vim index.html
hello passjava
```
- 再次訪問 nginx 服務
瀏覽器列印 hello passjava。說明訪問 nginx 服務的頁面沒有問題。
- 建立 ik 分詞詞庫檔案
``` sh
cd /mydata/nginx/html
mkdir ik
cd ik
vim ik.txt
```
填寫 ` 悟空哥 `,並儲存檔案。
- 訪問詞庫檔案
``` sh
http://192.168.56.10/ik/ik.txt
```
瀏覽器會輸出一串亂碼,可以先忽略亂碼問題。說明詞庫檔案可以訪問到。
- 修改 ik 分詞器配置
```sh
cd /mydata/elasticsearch/plugins/ik/config
vim IKAnalyzer.cfg.xml
```
- 重啟 elasticsearch 容器並設定每次重啟機器後都啟動 elasticsearch 容器。
``` sh
docker restart elasticsearch
docker update elasticsearch --restart=always
```
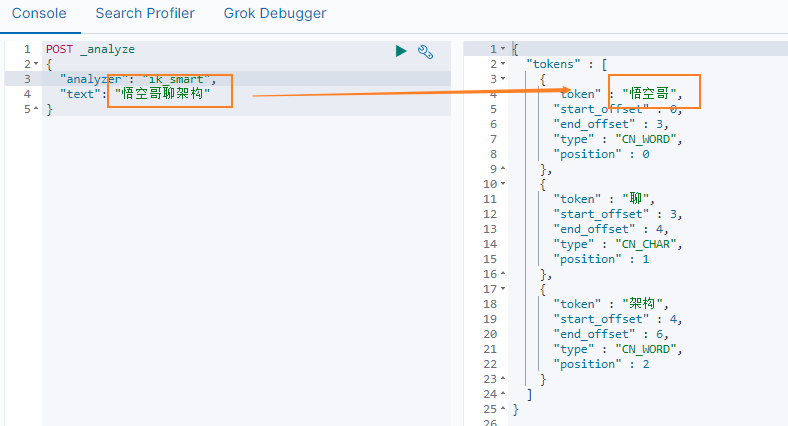
- 再次查詢分詞結果
可以看到 ` 悟空哥聊架構 ` 被拆分為 ` 悟空哥 `、` 聊 `、` 架構 ` 三個詞語,說明自定義詞庫中的 ` 悟空哥 ` 有作用。
# 七、寫在最後
中篇和下篇繼續肝,加油衝呀!
- 中篇: 實戰 ES 應用。
- 下篇: ES 的叢集部署。
- END -
> 你好,我是`悟空哥`,**「7年專案開發經驗,全棧工程師,開發組長,超喜歡圖解程式設計底層原理」**。
我還`手寫了 2 個小程式`,`Java 刷題小程式`,`PMP 刷題小程式`,點選我的公眾號選單開啟!
另外有 111 本架構師資料以及 1000 道 Java 面試題,都整理成了PDF。
可以關注公眾號 **「悟空聊架構」** 回覆 `悟空` 領取優質資料。
**「轉發->在看->點贊->收藏->評論!!!」** 是對我最大的支援!
**《Java併發必知必會》系列:**
[1.反制面試官 | 14張原理圖 | 再也不怕被問 volatile!](https://www.cnblogs.com/jackson0714/p/java_volatile.html)
[2.程式設計師深夜慘遭老婆鄙視,原因竟是CAS原理太簡單?](https://www.cnblogs.com/jackson0714/p/CAS.html)
[3.用積木講解ABA原理 | 老婆居然又聽懂了!](https://www.cnblogs.com/jackson0714/p/ABA.html)
[4.全網最細 | 21張圖帶你領略集合的執行緒不安全](https://www.cnblogs.com/jackson0714/p/thread_safe_collections.html)
[5.5000字 | 24張圖帶你徹底理解Java中的21種鎖](https://www.cnblogs.com/jackson0714/p/lock.html)
[6.乾貨 | 一口氣說出18種佇列(Queue),面試穩了](https://www.cnblogs.com/jackson0714/p/queue.html)

我是悟空哥,努力變強,變身超級賽亞人!我們下期