
華為雲專家講述知識圖譜構建流程及方法
摘要:隨著AI技術的發展和普及,當今社會已經進入了智慧化時代。與以往不同的是,在這一波浪潮中,企業不僅是向數字化轉型,更是向知識化轉型。那麼,如何助力企業破解智慧化知識挖掘和管理難題,實現知識化轉型?
華為雲自然語言處理技術專家鄭毅在《企業級知識計算平臺的技術解讀和案例實踐》分享中,講述了華為雲知識計算平臺及相關技術、知識圖譜構建流程及方法,以及知識計算行業案例。本文主要講述“知識圖譜構建流程及方法”,讓我們先睹為快。
一、 什麼是知識圖譜?
知識圖譜是由實體、關係和屬性組成的一種資料結構。以下圖為例,“劉德華“是一個人物型別的實體,“劉德華”有自己的身高、國籍等資訊,這些資訊便稱之為實體的屬性。
同樣,“無間道”是一個電影型別的實體。我們知道“劉德華”是“無間道”這部電影的主演,所以“劉德華”與“無間道”之間有“主演”關係。通過實體、關係、屬性,就能夠把我們人可以理解的知識有效地組織起來。知識圖譜的構建與應用涉及資料庫、自然語言處理(NLP)和語義網路等技術。
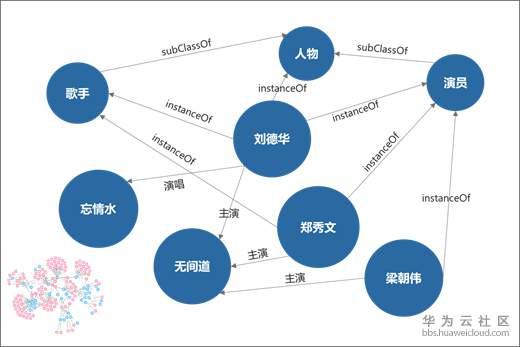
圖1 知識圖譜示例
通用知識圖譜or行業知識圖譜?
按照知識圖譜的用途,知識圖譜可分為通用知識圖譜和行業知識圖譜。通用知識圖譜側重構建常識性的知識,並用於搜尋引擎和推薦系統等。行業知識圖譜(也可稱企業知識圖譜)主要面向企業業務,通過構建不同行業、企業的知識圖譜,對企業內部提供知識化服務。華為雲知識圖譜服務可用於以上兩類知識圖譜的構建、管理和服務,更側重面向企業知識圖譜。
二、 如何構建知識圖譜?
知識圖譜構建主要分為自頂向下(top-down)與自底向上(bottom-up)兩種構建方式。自頂向下構建方式需要先定義好本體(Ontology或稱為Schema),再基於輸入資料完成資訊抽取到圖譜構建的過程。該方法更適用於專業知識方面圖譜的構建,比如企業知識圖譜,面向領域專業使用者使用。自底向上構建方式則是從開放的Open Linked Data中抽取置信度高的知識,或從非結構化文字中抽取知識,完成知識圖譜的構建。該方式更適用於常識性的知識,比如人名、機構名等通用知識圖譜的構建。本文側重介紹自頂向下構建方式的相關流程和技術,並用於構建企業知識圖譜。
目前業界暫無知識圖譜雲服務,也沒有統一標準的自頂向下構建流程。當前業界主流的知識圖譜構建方式是基於企業內部資料、公開資料,圖譜服務商以解決方案形式幫助客戶定製構建知識圖譜。這樣的方式無疑成本非常高並且效率很低,通常需要很長的週期才能完成。同時,企業沒有參與感,圖譜構建也可能存在很大偏差,難以用於實際業務中。
站在使用者角度,我們通過抽象知識圖譜構建流程及相關技術,推出華為雲知識圖譜雲服務(圖2),為不同行業、不同企業提供快速構建知識圖譜能力的平臺,賦能大中小型企業構建屬於自己的知識圖譜。

圖2 華為雲知識圖譜雲服務
華為雲知識圖譜雲服務提供流水線式圖譜構建能力,將圖譜構建抽象為如下基本流程:本體構建、資料來源配置、資訊抽取、知識對映以及知識融合。

圖3 知識圖譜構建基本流程
進一步通過將每一個流程模組抽象成外掛形式,並通過組合配置生成圖譜構建任務。面向不同的行業和領域,只需要修改外掛配置即可完成企業知識圖譜的構建。同時,基於流水線設計,知識圖譜雲服務可以在只修改資料來源的前提下完成知識圖譜的更新操作,非常適用於需要頻繁更新的知識圖譜。
2.1 如何構建知識圖譜的本體?
知識圖譜構建的第一步需要完成圖譜本體(Ontology)的設計和構建。本體是圖譜的模型,是對構成圖譜的資料的一種模式約束。對於企業知識圖譜的構建,一般是由垂直領域的行業專家和知識圖譜專家合作完成。
本體的構建和設計對於知識圖譜的構建至關重要。可以通過梳理領域知識、術語詞典、專家的人工經驗等作為本體構建的基礎,結合知識圖譜的應用場景來完善圖譜的構建,最終獲得實體類別、類別之間的關係、實體包含的屬性定義。華為雲知識圖譜雲服務提供圖形化本體設計工具,可以通過拖拽編輯靈活完成企業知識圖譜本體的構建。
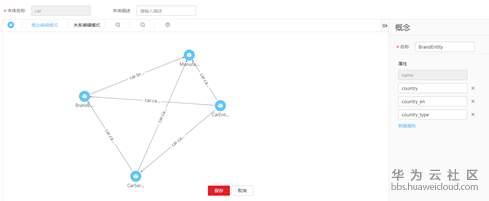
圖4 華為雲知識圖譜雲服務-本體設計介面
2.2 如何配置資料來源?需要做哪些準備
在配置資料來源之前,需要將不同型別、不同格式的資料進行初步的整理。比如:針對本地非電子化文件,需要先進行掃描電子化,結合OCR等技術將掃描件轉換成文字文件。再比如:針對本地電子化文件,需要將本地文件按文件型別、格式進行歸檔解析整理成規範的格式,或者針對網路資源,需要根據網站特點,開發相應的爬蟲,對資料進行爬取,並存儲到本地資料庫等等。還有一些第三方資源,需要獲取相應的資料訪問介面,並通過介面獲取相應資料。
整理好的資料上傳到華為雲OBS物件儲存服務後,知識圖譜雲服務就可以進行資料來源的配置,包括指定格式的針對結構化資料和非結構化文字的配置等。
2.3 什麼是資訊抽取?怎樣抽取?
資訊抽取的目的是根據不同的資料來源、不同的資料格式,完成實體、屬性、關係這種知識的抽取。這是知識圖譜構建流程中非常關鍵的一環,資訊抽取的質量決定了知識圖譜的質量。實體之間的關係以及實體的屬性值,都可以用三元組(主語、謂詞、賓語)來表示,所以資訊抽取又可以簡單叫做三元組抽取。
華為雲知識圖譜雲服務支援結構化Key-Value格式和非結構化文字的三元組抽取。針對結構化資料,可以通過配置預置函式的組合,完成欄位的處理。與之對應的,針對非結構化文字,雲服務提供演算法模型抽取能力,支援業界前沿的基於機器閱讀理解(Machine Reading Comprehension,MRC)的三元組抽取方法,通過使用多輪對話的思想進行三元組抽取,先抽取主語(Subject),然後根據抽取結果和候選謂詞對應的模板構造問句抽取賓語(Object),最終組成(主語,謂詞,賓語)三元組。該框架模型效果可以達到當前業界最好水平(state-of-the-art)。華為雲知識圖譜服務支援基於該演算法的模型訓練、預測以及管理功能,同時以外掛形式完成流水線中資訊抽取部分。
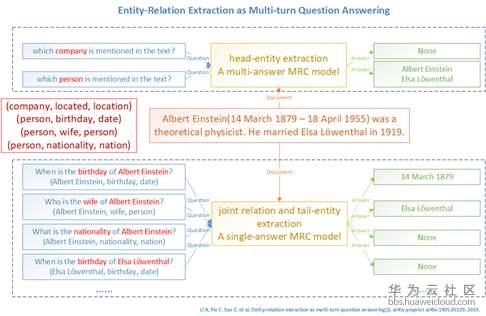
圖5 基於機器閱讀理解(MRC)的三元組抽取方法
資訊抽取中模型訓練推理功能是基於華為雲-ModelArts AI計算平臺完成的,該平臺提供高效的AI計算、模型訓練、推理及部署能力,同時為了方便訓練三元組抽取模型,額外提供三元組標註工具,使用者可以基於該工具快速獲得訓練資料,完成資訊抽取以及知識圖譜構建工作。
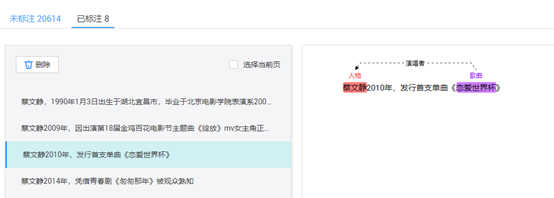
圖6 三元組標註工具示例
2.4 知識融合是如何完成的?
所謂知識融合,就是對多個數據源進行知識抽取後的大量三元組資料進行對齊合併。舉個例子:百度百科有明星劉德華,互動百科有明星劉德華,我們構建的知識圖譜不能有兩個明星劉德華吧?這時候就需要把他們識別出來放在一起,然後合併成一個實體,這就是實體的對齊以及知識的融合。
這其中關鍵的問題是怎樣高效的完成實體對齊,技術路線基本可以分為兩類:基於實體屬性相似度的框架、基於聯合表徵的深度學習框架。考慮到基於聯合表徵的深度學習框架依賴大量標註資料,並且模型與行業及資料強相關,無法提供很好的通用化能力,因此,華為雲知識圖譜服務當前支援基於實體屬性相似度的框架,可以通過定義相似度度量及組合,完成實體對齊以及知識融合。
除此之外,華為雲知識圖譜雲服務還提供圖譜視覺化服務,可以直觀地觀察分析實體及關係。
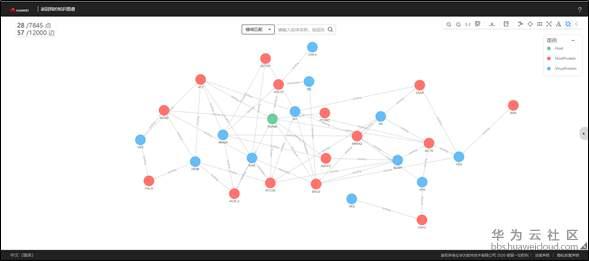
圖7 病毒蛋白知識圖譜視覺化示例
三、 知識圖譜需要怎樣的儲存方式?
經過知識圖譜構建,我們現在已經有了大量的三元組知識。那麼要怎樣來儲存這些三元組知識呢?
最直接的方式是使用表格式的儲存方式,如關係型資料表,三元組以三列資料或多列資料的形式儲存。這種方法在圖譜規模比較小的時候是可行的,但是如果圖譜規模變大了,是否依然可行呢?舉個例子,假使我們有了娛樂明星+電影這樣一個娛樂圖譜,其中包括了大量的明星人物、電影以及他們之間的關係。如果想查詢“劉德華和梁朝偉共同演過的電影中,年齡最大的導演是誰?“,就需要對關係型資料庫中知識圖譜結果表做2-3次自連線操作,如果三元組的數量是千萬、億、十億規模的話,顯而易見,這樣的查詢效率極低,基本不可行。
華為雲知識圖譜服務採用的是業界主流的圖資料庫方式儲存知識圖譜,直接把資料或知識圖譜以圖的形式儲存,可以非常高效地完成多跳關係、屬性的查詢。具體的,我們使用華為雲圖引擎服務,包括圖儲存、圖計算一體的架構設計,不僅可以提供高效的查詢效能,同時也可以提供多種預置的圖深度學習演算法,使用起來非常方便,歡迎大家前來試用。
圖8 華為雲圖引擎服務產品優勢
四、 華為雲知識計算案例介紹
中國石油基於華為雲知識計算服務的知識建模、油氣圖譜構建、圖譜儲存、自然語言處理、機器學習等能力構建了業界首個油氣知識計算平臺。以油氣勘探開發資料為基礎,通過知識計算技術的應用,為油氣勘探開發增儲上產、降本增效提供智慧輔助和決策。

圖9 油氣知識計算的價值和意義
華為知識計算解決方案提供豐富的知識應用,從解決企業痛點、提升企業效率、提供知識化服務的角度全面賦能企業,體現了知識計算在各行業中的智慧化價值,讓各行業的企業可以快速、低成本、高效率地管理,通過應用企業知識、實現知識化轉型,釋放知識化帶來的紅利,全面提升企業在智慧化時代的競爭力。
點選關注,第一時間瞭解華為雲新鮮技