
ConcurrentHashMap原始碼解析,多執行緒擴容
阿新 • • 發佈:2020-10-12
前面一篇已經介紹過了 HashMap 的原始碼:
[HashMap原始碼解析、jdk7和8之後的區別、相關問題分析](https://www.cnblogs.com/lifegoeson/p/13628737.html)
HashMap並不是執行緒安全的,他就一個普通的容器,沒有做相關的同步處理,因此執行緒不安全主要體現在:
* put、get 等等核心方法在多執行緒情況下,都會出現修改的覆蓋,資料不一致等等問題。比如多個執行緒 put 先後的問題,會導致結果覆蓋,如果一個 put 一個get,也可能會因為排程問題獲取到錯誤的結果;
* 多執行緒操作有讀有寫的時候,可能會出現一個典型異常:ConcurrentModificationException
* 另外擴容的時候,hashmap1.7 的實現還有可能出現死迴圈的問題。
關於執行緒安全的雜湊對映的選擇有三種:
* Hashtable;
* SynchronizedMap對HashMap包裝;
* ConcurrentHashMap
1. 其中,Hashtable 的效率比較低,因為他的每一個方法都是用了鎖,synchronized 修飾的; 2. 用 SynchronizedMap 對 HashMap 包裝的實質也是額外加入一個物件叫做 mutex,是一個 Object,然後給對應的方法上都加上 synchronized(mutex),當然比 Hashtable 是要好一些的,因為鎖物件粒度要小一些。Hashtable 採用的 synchronized 鎖上方法鎖定的是整個 this。 ConcurrentHashMap則是最好的選擇,這裡我們來看看他的原始碼原理。
# 一、ConcurrentHashMap 資料結構
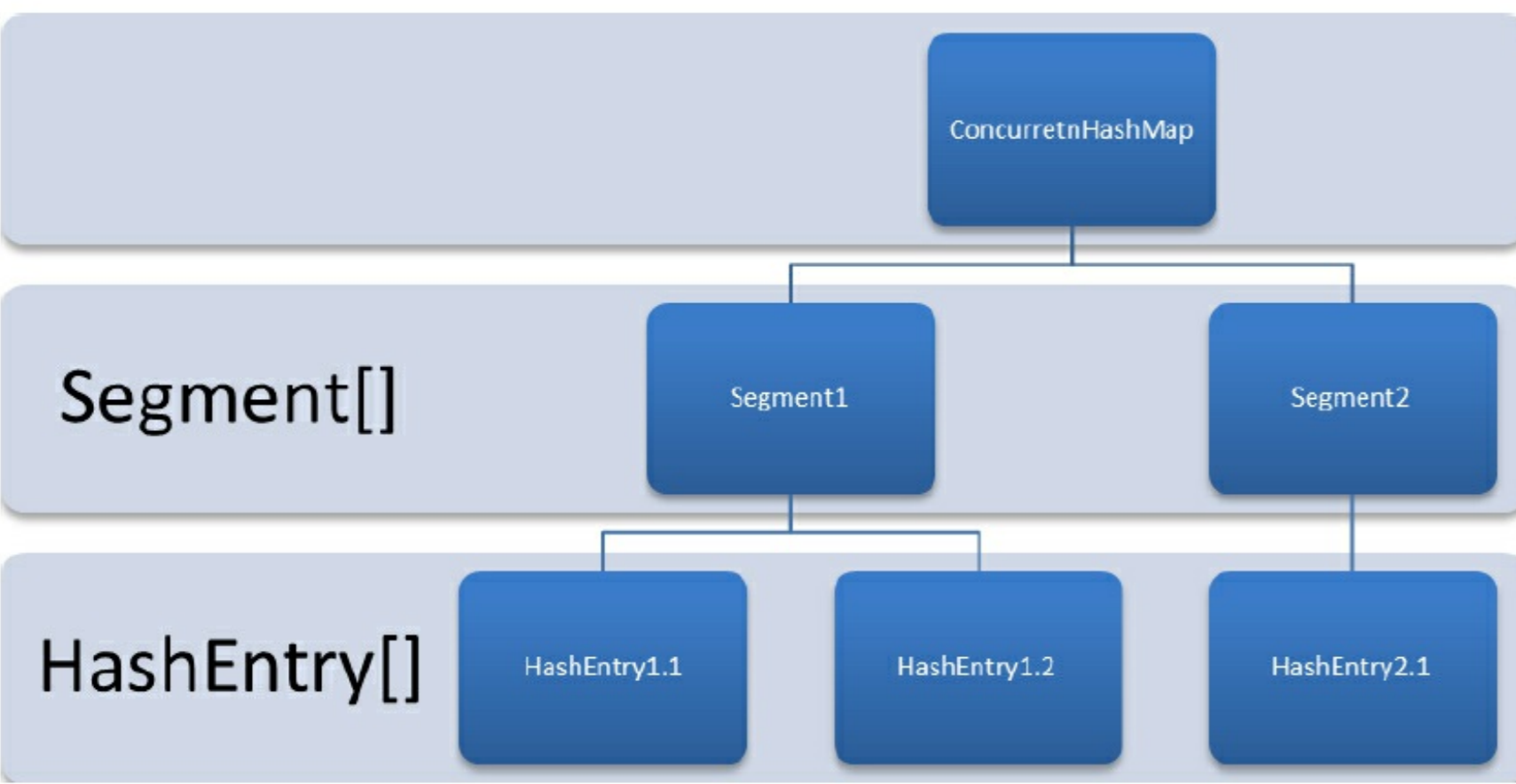

## 2.1 jdk7 的 put ,get ,擴容方法
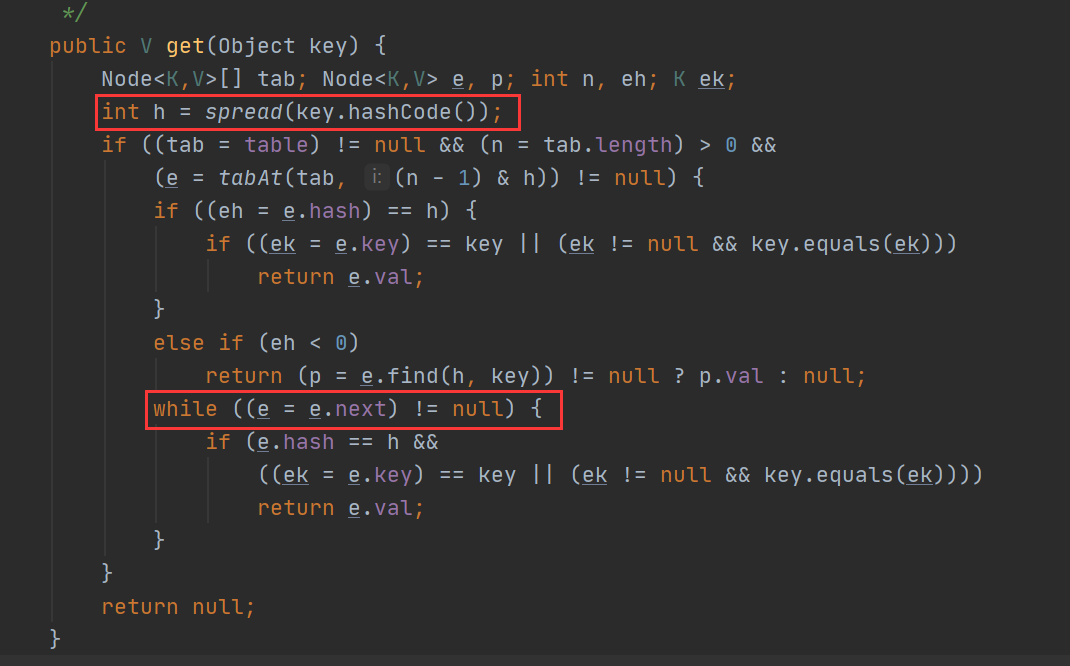
這裡沒有原始碼的截圖,但是過程是清晰的。 **put 方法(加鎖):** 1. 將當前 Segment 中的表通過 key 的雜湊碼定位到HashEntry。這一步會嘗試獲取鎖,如果獲取失敗肯定存在其他執行緒存在競爭,則利用 scanAndLockForPut() 方法去獲取鎖。 2. 遍歷該 HashEntry,如果不為空則判斷預定的 key 和當前遍歷的 key 是否替代,替代則覆蓋舊的值。 3. 不為空則需要新建一個 HashEntry 並加入到 Segment 中,同時會先判斷是否需要擴容。 4. 最後會解除在 1 中所獲取當前Segment的鎖。 可以看到,整體就是獲取鎖的中間進行 put 操作,put 操作的流程也和 HashMap 的 put 是類似的。 **get 方法(不加鎖)**: ConcurrentHashMap 的 get 操作跟 HashMap 類似,只是ConcurrentHashMap 第一次需要經過一次 hash 定位到 Segment 的位置,然後再 hash 定位到指定的 HashEntry,遍歷該 HashEntry 下的連結串列進行對比,成功就返回,不成功就返回 null。 並且 get 的過程呼叫的是 Unsafe 包的 getObjectVolatile 方法,因為具體的物件是 volatile 修飾的,不用加鎖,讀取也可以直接讀到最新的值。 **rehash 方法(加鎖)**: ConcurrentHashMap 的擴容方法和 HashMap 也是類似的,因為外部已經對 Segment 加鎖,內部的操作就是重新計算 hash 值,然後重新移動元素。 這裡可以看出來,因為有 Segment 的一個粒度縮小的優化,加上一個讀寫分離的普遍思想,jdk 7 實現的方法比較容易理解。 下來的 jdk 8 做出的優化非常多,因此幾個方法分開來講 ## 2.2 jdk 8 的初始化
構造方法和 HashMap 一樣,是不會初始化的,而是在第一次呼叫 put 方法之後才會進行初始化。構造方法呼叫的時候只是進行了一些引數的確定。 因此我們可以先看一下ConcurrentHashMap 裡面的比較重要的引數: ```java //最大容量 private static final int MAXIMUM_CAPACITY = 1 << 30; //預設初始化容量 private static final int DEFAULT_CAPACITY = 16; //負載因子 private static final float LOAD_FACTOR = 0.75f; //連結串列轉為紅黑樹的臨界值 static final int TREEIFY_THRESHOLD = 8; //紅黑樹轉為連結串列的臨界值 static final int UNTREEIFY_THRESHOLD = 6; //當容量大於64時,連結串列才會轉為紅黑樹,否則,即便連結串列長度大於8,也不會轉,而是會擴容 static final int MIN_TREEIFY_CAPACITY = 64; ``` 可以看到,以上的幾個屬性和 HashMap 一模一樣,除此之外,比較重要的一個引數就是: ```java private transient volatile int sizeCtl; ``` 在計算出陣列長度、也就是裝整個 Map 的那個 Node[] table 的長度之後,是賦值給 sizeCtl 這個元素的。 如果說使用無參構造,那麼初始化的時候,**sizeCtl** 會是 16,其他的情況會計算成為一個 2 的冪次方數,也和 HashMap 是一樣的。另外,**sizeCtl** 這個引數的值還有別的含義: * 負數代表正在進行初始化或擴容操作 * -1代表正在初始化 * -N 表示,這個高16位表示當前擴容的標誌,每次擴容都會生成一個不一樣的標誌,低16位表示參與擴容的執行緒數量 * 正數或 0,0 代表 hash 表那個陣列還沒有被初始化,正數表示達到這個值需要擴容(擴容閾值,其實就等於(容量 * 負載因子),也就是陣列長度*0.75)。 還有一部分基本是和擴容相關的屬性,第一眼看過去可能不能理解這些什麼時候會用,下面講到擴容方法的時候就會用到: ```java //擴容相關,每個執行緒負責最小桶個數 private static final int MIN_TRANSFER_STRIDE = 16; //擴容相關,為了計算sizeCtl private static int RESIZE_STAMP_BITS = 16; //最大輔助擴容執行緒數量 private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1; //擴容相關,為了計算sizeCtl private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS; //下面幾個是狀態值 //MOVED表示正在擴容 static final int MOVED = -1; // hash for forwarding nodes //-2表示紅黑樹標識 static final int TREEBIN = -2; // hash for roots of trees static final int RESERVED = -3; // hash for transient reservations //計算Hash值使用 static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash //可用CPU核數 static final int NCPU = Runtime.getRuntime().availableProcessors(); //用於記錄容器中插入的元素數量 private transient volatile long baseCount; ``` ## 2.3 jdk 8 的 put() 方法
和 jdk 8 的 HashMap 方法一樣,直接呼叫的是 putVal 方法去執行。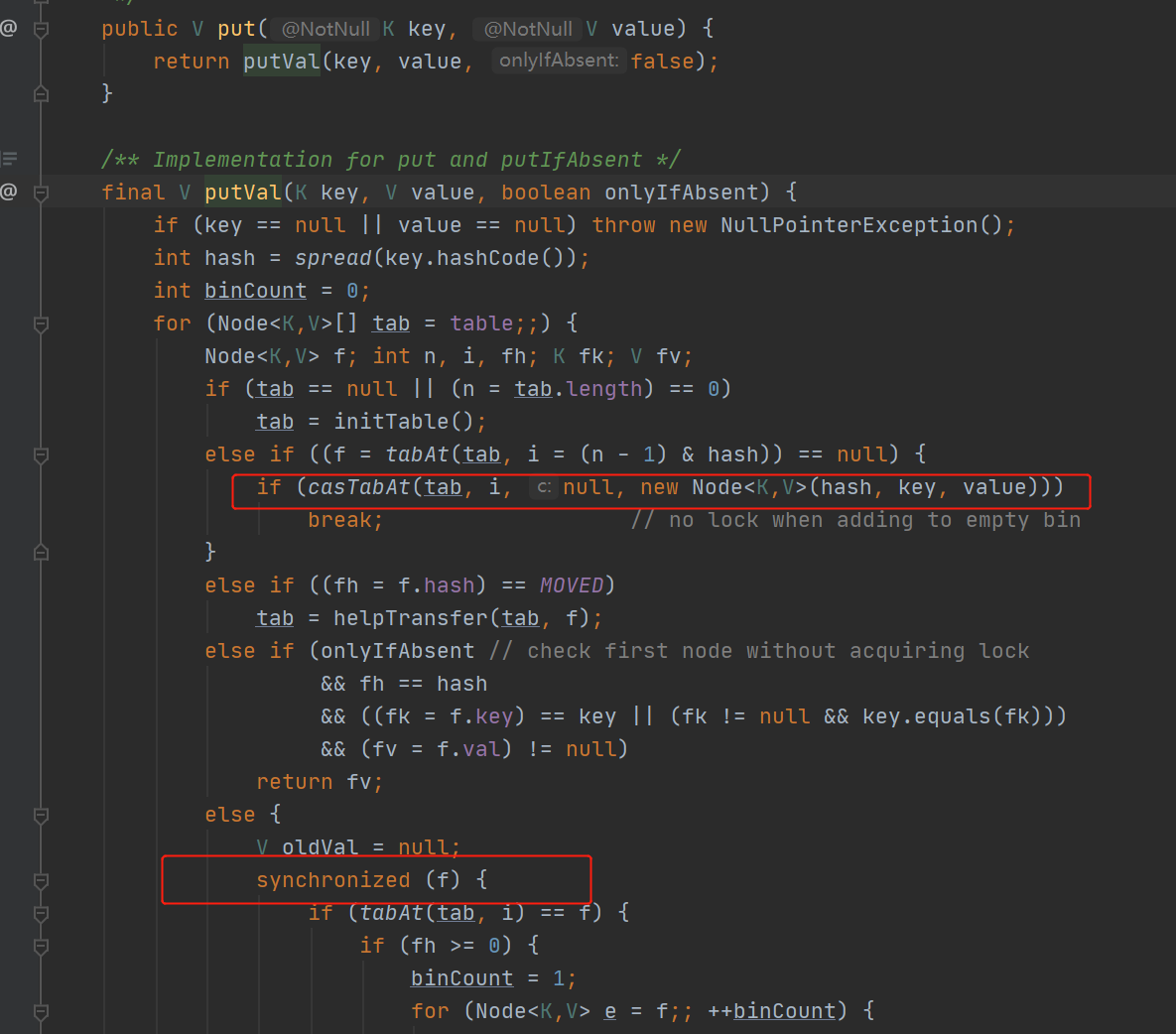
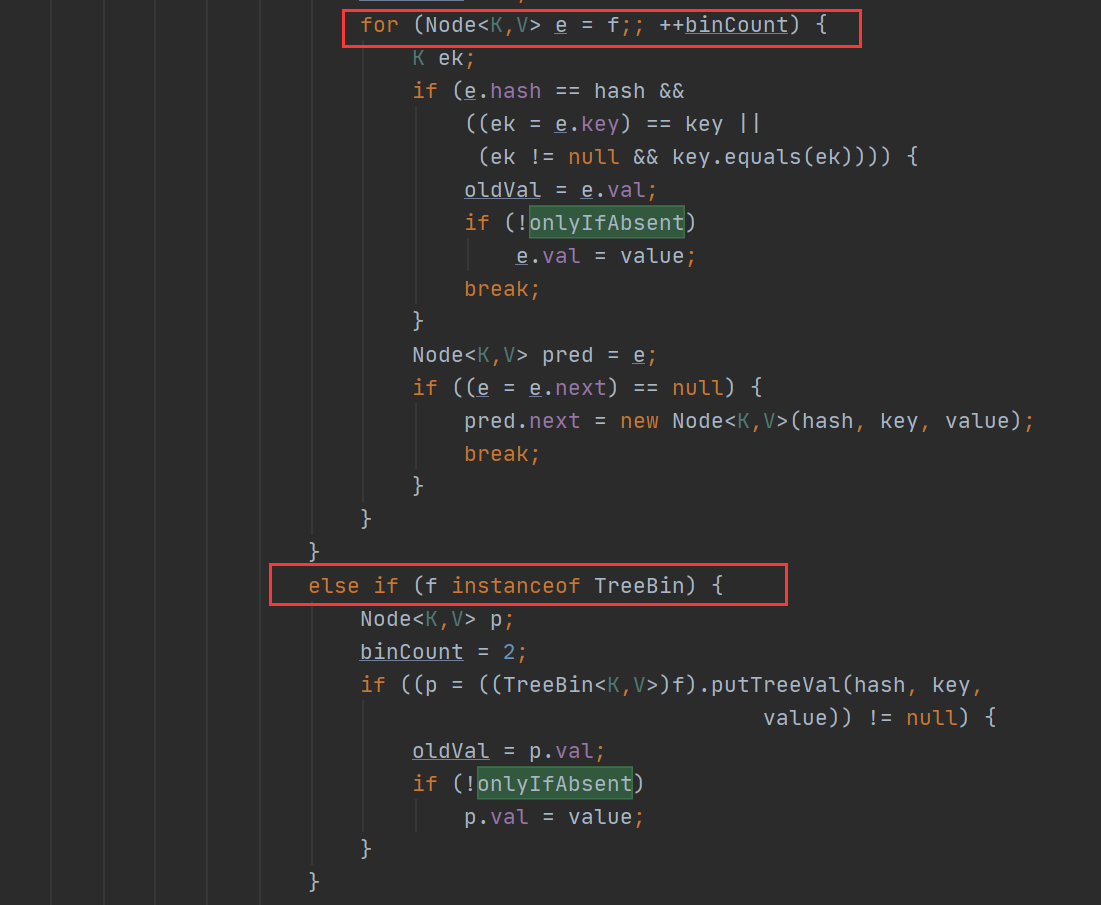
新增元素的相關操作之後,最後會呼叫 addCount 方法,也就是判斷是否需要擴容,在這裡面控制不同的策略。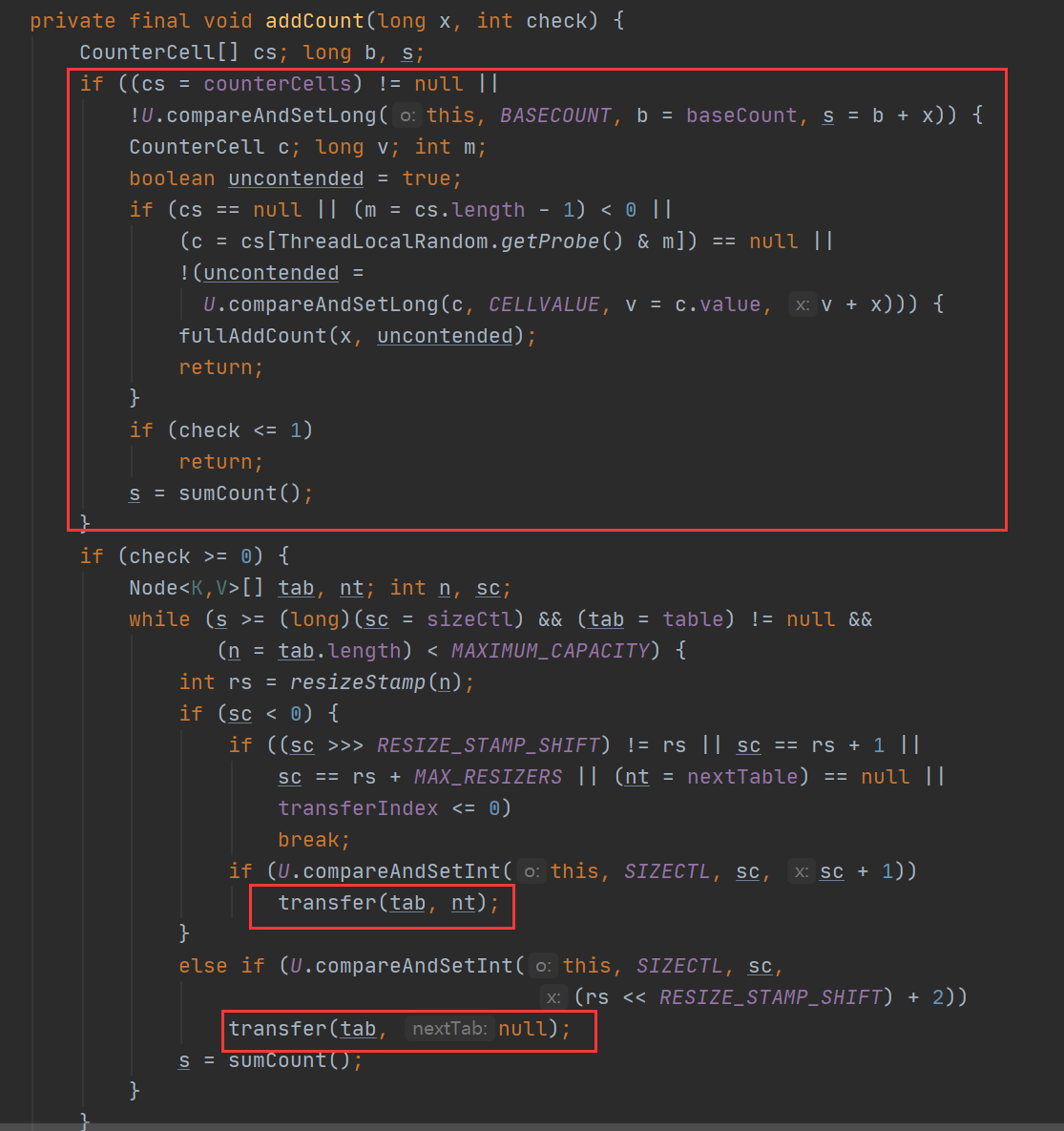
transfer 方法主要就是完成將擴容任務分配給多個執行緒去處理,根據了CPU核心數和集合 length 計算每個核一輪處理桶的個數。 然後每個執行緒處理的最小單位只能是一個數組的位置,這個時候擴容之後,和HashMap 一樣,其實只有原位置或者 原位置+陣列長度 的位置,因為仍然有可能多個執行緒操作之間發生雜湊衝突,就用到 synchronized。 原始碼很長,這裡的詳細註釋參考的是一個部落格: https://www.cnblogs.com/gunduzi/p/13651664.html ```java /** * Moves and/or copies the nodes in each bin to new table. See * above for explanation. * * transferIndex 表示轉移時的下標,初始為擴容前的 length。 * * 我們假設長度是 32 */ private final void transfer(Node[] tab, Node[] nextTab) {
int n = tab.length, stride;
// 將 length / 8 然後除以 CPU核心數。如果得到的結果小於 16,那麼就使用 16。
// 這裡的目的是讓每個 CPU 處理的桶一樣多,避免出現轉移任務不均勻的現象,如果桶較少的話,預設一個 CPU(一個執行緒)處理 16 個桶
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range 細分範圍 stridea:TODO
// 新的 table 尚未初始化
if (nextTab == null) { // initiating
try {
// 擴容 2 倍
Node[] nt = (Node[])new Node[n << 1];
// 更新
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
// 擴容失敗, sizeCtl 使用 int 最大值。
sizeCtl = Integer.MAX_VALUE;
return;// 結束
}
// 更新成員變數
nextTable = nextTab;
// 更新轉移下標,就是 老的 tab 的 length
transferIndex = n;
}
// 新 tab 的 length
int nextn = nextTab.length;
// 建立一個 fwd 節點,用於佔位。當別的執行緒發現這個槽位中是 fwd 型別的節點,則跳過這個節點。
ForwardingNode fwd = new ForwardingNode(nextTab);
// 首次推進為 true,如果等於 true,說明需要再次推進一個下標(i--),反之,如果是 false,那麼就不能推進下標,需要將當前的下標處理完畢才能繼續推進
boolean advance = true;
// 完成狀態,如果是 true,就結束此方法。
boolean finishing = false; // to ensure sweep before committing nextTab
// 死迴圈,i 表示下標,bound 表示當前執行緒可以處理的當前桶區間最小下標,死迴圈的作用是保證拷貝全部完成。
for (int i = 0, bound = 0;;) {
Node f; int fh;
// 如果當前執行緒可以向後推進;這個迴圈就是控制 i 遞減。同時,每個執行緒都會進入這裡取得自己需要轉移的桶的區間 //這個迴圈只是用來控制每個執行緒每輪最多copy的桶的個數,如果只有一個執行緒在擴容,也是可以完成的,只是分成多輪
while (advance) {
int nextIndex, nextBound;
// 對 i 減一,判斷是否大於等於 bound (正常情況下,如果大於 bound 不成立,說明該執行緒上次領取的任務已經完成了。那麼,需要在下面繼續領取任務)
// 如果對 i 減一大於等於 bound(還需要繼續做任務),或者完成了,修改推進狀態為 false,不能推進了。任務成功後修改推進狀態為 true。
// 通常,第一次進入迴圈,i-- 這個判斷會無法通過,從而走下面的 nextIndex 賦值操作(獲取最新的轉移下標)。其餘情況都是:如果可以推進, //將 i 減一,然後修改成不可推進。如果 i 對應的桶處理成功了,改成可以推進。
if (--i >= bound || finishing)
advance = false;// 這裡設定 false,是為了防止在沒有成功處理一個桶的情況下卻進行了推進
// 這裡的目的是:1. 當一個執行緒進入時,會選取最新的轉移下標。2. 當一個執行緒處理完自己的區間時,如果還有剩餘區間的沒有別的執行緒處理。再次獲取區間。
else if ((nextIndex = transferIndex) <= 0) {
// 如果小於等於0,說明沒有區間了 ,i 改成 -1,推進狀態變成 false,不再推進,表示,擴容結束了,當前執行緒可以退出了
// 這個 -1 會在下面的 if 塊裡判斷,從而進入完成狀態判斷
i = -1;
advance = false;// 這裡設定 false,是為了防止在沒有成功處理一個桶的情況下卻進行了推進
}// CAS 修改 transferIndex,即 length - 區間值,留下剩餘的區間值供後面的執行緒使用
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;// 這個值就是當前執行緒可以處理的最小當前區間最小下標
i = nextIndex - 1; // 初次對i 賦值,這個就是當前執行緒可以處理的當前區間的最大下標
advance = false; // 這裡設定 false,是為了防止在沒有成功處理一個桶的情況下卻進行了推進,這樣對導致漏掉某個桶。下面的 if (tabAt(tab, i) == f) 判斷會出現這樣的情況。
}
}
// 如果 i 小於0 (不在 tab 下標內,按照上面的判斷,領取最後一段區間的執行緒擴容結束)
// 如果 i >= tab.length(不知道為什麼這麼判斷)
// 如果 i + tab.length >= nextTable.length (不知道為什麼這麼判斷)
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
if (finishing) { // 如果完成了擴容
nextTable = null;// 刪除成員變數
table = nextTab;// 更新 table
sizeCtl = (n << 1) - (n >>> 1); // 更新閾值
return;// 結束方法。
}// 如果沒完成 //說明1
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {// 嘗試將 sc -1. 表示這個執行緒結束幫助擴容了,將 sc 的低 16 位減一。
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)// 如果 sc - 2 不等於識別符號左移 16 位。如果他們相等了,說明沒有執行緒在幫助他們擴容了。也就是說,擴容結束了。
return;// 不相等,說明沒結束,當前執行緒結束方法。
finishing = advance = true;// 如果相等,擴容結束了,更新 finising 變數
i = n; // 再次迴圈檢查一下整張表
}
}
else if ((f = tabAt(tab, i)) == null) // 獲取老 tab i 下標位置的變數,如果是 null,就使用 fwd 佔位。
advance = casTabAt(tab, i, null, fwd);// 如果成功寫入 fwd 佔位,再次推進一個下標
else if ((fh = f.hash) == MOVED)// 如果不是 null 且 hash 值是 MOVED。
advance = true; // already processed // 說明別的執行緒已經處理過了,再次推進一個下標
else {// 到這裡,說明這個位置有實際值了,且不是佔位符。對這個節點上鎖。為什麼上鎖,防止 putVal 的時候向連結串列插入資料
synchronized (f) {
// 判斷 i 下標處的桶節點是否和 f 相同
if (tabAt(tab, i) == f) {
Node ln, hn;// low, height 高位桶,低位桶
// 如果 f 的 hash 值大於 0 。TreeBin 的 hash 是 -2
if (fh >= 0) {
// 對老長度進行與運算(第一個運算元的的第n位於第二個運算元的第n位如果都是1,那麼結果的第n為也為1,否則為0)
// 由於 Map 的長度都是 2 的次方(000001000 這類的數字),那麼取於 length 只有 2 種結果,一種是 0,一種是1
// 如果是結果是0 ,Doug Lea 將其放在低位,反之放在高位,目的是將連結串列重新 hash,放到對應的位置上,讓新的取於演算法能夠擊中他。
int runBit = fh & n;
Node lastRun = f; // 尾節點,且和頭節點的 hash 值取於不相等
// 遍歷這個桶 //說明2
for (Node p = f.next; p != null; p = p.next) {
// 取於桶中每個節點的 hash 值
int b = p.hash & n;
// 如果節點的 hash 值和首節點的 hash 值取於結果不同
if (b != runBit) {
runBit = b; // 更新 runBit,用於下面判斷 lastRun 該賦值給 ln 還是 hn。
lastRun = p; // 這個 lastRun 保證後面的節點與自己的取於值相同,避免後面沒有必要的迴圈
}
}
if (runBit == 0) {// 如果最後更新的 runBit 是 0 ,設定低位節點
ln = lastRun;
hn = null;
}
else {
hn = lastRun; // 如果最後更新的 runBit 是 1, 設定高位節點
ln = null;
}// 再次迴圈,生成兩個連結串列,lastRun 作為停止條件,這樣就是避免無謂的迴圈(lastRun 後面都是相同的取於結果)
for (Node p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
// 如果與運算結果是 0,那麼就還在低位
if ((ph & n) == 0) // 如果是0 ,那麼建立低位節點
ln = new Node(ph, pk, pv, ln);
else // 1 則建立高位
hn = new Node(ph, pk, pv, hn);
}
// 其實這裡類似 hashMap
// 設定低位連結串列放在新連結串列的 i
setTabAt(nextTab, i, ln);
// 設定高位連結串列,在原有長度上加 n
setTabAt(nextTab, i + n, hn);
// 將舊的連結串列設定成佔位符
setTabAt(tab, i, fwd);
// 繼續向後推進
advance = true;
}// 如果是紅黑樹
else if (f instanceof TreeBin) {
TreeBin t = (TreeBin)f;
TreeNode lo = null, loTail = null;
TreeNode hi = null, hiTail = null;
int lc = 0, hc = 0;
// 遍歷
for (Node e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode p = new TreeNode
(h, e.key, e.val, null, null);
// 和連結串列相同的判斷,與運算 == 0 的放在低位
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
} // 不是 0 的放在高位
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
// 如果樹的節點數小於等於 6,那麼轉成連結串列,反之,建立一個新的樹
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin(hi) : t;
// 低位樹
setTabAt(nextTab, i, ln);
// 高位數
setTabAt(nextTab, i + n, hn);
// 舊的設定成佔位符
setTabAt(tab, i, fwd);
// 繼續向後推進
advance = true;
}
}
}
}
}
}
```
流程如下:
1. **根據作業系統的 CPU 核數和集合 length 計算每個核一輪處理桶的個數**,最小是16
2. 修改 transferIndex 標誌位,**每個執行緒領取完任務**就減去多少,比如初始大小是transferIndex = table.length = 64,每個執行緒領取的桶個數是16,第一個執行緒領取完任務後transferIndex = 48,也就是說第二個執行緒這時進來是從第 48 個桶開始處理,再減去16,依次類推,這就是**多執行緒協作處理**的原理
3. 領取完任務之後就開始處理,如果桶為空就設定為 ForwardingNode ,如果不為空就**加鎖拷貝**,只有這裡用到了 **synchronized** 關鍵字來加鎖,為了防止拷貝的過程有其他執行緒在put元素進來。拷貝完成之後也設定為 ForwardingNode節點。
4. 如果某個執行緒分配的桶處理完了之後,再去申請,發現 transferIndex = 0,這個時候就說明所有的桶都領取完了,但是別的執行緒領取任務之後有沒有處理完並不知道,該執行緒會**將 sizeCtl 的值減1**,然後判斷是不是所有執行緒都退出了,如果還有執行緒在處理,就退出
5. 直到最後一個執行緒處理完,發現 **sizeCtl = rs<< RESIZE_STAMP_SHIFT** 也就是識別符號左移 16 位,才會將舊陣列幹掉,用新陣列覆蓋,並且會重新設定 sizeCtl 為新陣列的擴容點。
以上過程總的來說分成兩個部分:
* **分配任務**:這部分其實很簡單,就是把一個大的陣列給切分,切分多個小份,然後每個執行緒處理其中每一小份,當然可能就只有1個或者幾個執行緒在擴容,那就一輪一輪的處理,一輪處理一份
* **處理任務**:複製部分主要有兩點,第一點就是加鎖,第二點就是處理完之後置為ForwardingNode來佔位標識這個位置被遷移過了。
## 2.7 jdk8 的協助擴容 helpTransfer()方法
如果說 put 的時候發現數組正在擴容,會執行 helpTransfer 方法,也就是這個執行緒來幫助進行擴容。

1. 其中,Hashtable 的效率比較低,因為他的每一個方法都是用了鎖,synchronized 修飾的; 2. 用 SynchronizedMap 對 HashMap 包裝的實質也是額外加入一個物件叫做 mutex,是一個 Object,然後給對應的方法上都加上 synchronized(mutex),當然比 Hashtable 是要好一些的,因為鎖物件粒度要小一些。Hashtable 採用的 synchronized 鎖上方法鎖定的是整個 this。 ConcurrentHashMap則是最好的選擇,這裡我們來看看他的原始碼原理。
# 一、ConcurrentHashMap 資料結構
## 2.1 jdk7 的 put ,get ,擴容方法
這裡沒有原始碼的截圖,但是過程是清晰的。 **put 方法(加鎖):** 1. 將當前 Segment 中的表通過 key 的雜湊碼定位到HashEntry。這一步會嘗試獲取鎖,如果獲取失敗肯定存在其他執行緒存在競爭,則利用 scanAndLockForPut() 方法去獲取鎖。 2. 遍歷該 HashEntry,如果不為空則判斷預定的 key 和當前遍歷的 key 是否替代,替代則覆蓋舊的值。 3. 不為空則需要新建一個 HashEntry 並加入到 Segment 中,同時會先判斷是否需要擴容。 4. 最後會解除在 1 中所獲取當前Segment的鎖。 可以看到,整體就是獲取鎖的中間進行 put 操作,put 操作的流程也和 HashMap 的 put 是類似的。 **get 方法(不加鎖)**: ConcurrentHashMap 的 get 操作跟 HashMap 類似,只是ConcurrentHashMap 第一次需要經過一次 hash 定位到 Segment 的位置,然後再 hash 定位到指定的 HashEntry,遍歷該 HashEntry 下的連結串列進行對比,成功就返回,不成功就返回 null。 並且 get 的過程呼叫的是 Unsafe 包的 getObjectVolatile 方法,因為具體的物件是 volatile 修飾的,不用加鎖,讀取也可以直接讀到最新的值。 **rehash 方法(加鎖)**: ConcurrentHashMap 的擴容方法和 HashMap 也是類似的,因為外部已經對 Segment 加鎖,內部的操作就是重新計算 hash 值,然後重新移動元素。 這裡可以看出來,因為有 Segment 的一個粒度縮小的優化,加上一個讀寫分離的普遍思想,jdk 7 實現的方法比較容易理解。 下來的 jdk 8 做出的優化非常多,因此幾個方法分開來講 ## 2.2 jdk 8 的初始化
構造方法和 HashMap 一樣,是不會初始化的,而是在第一次呼叫 put 方法之後才會進行初始化。構造方法呼叫的時候只是進行了一些引數的確定。 因此我們可以先看一下ConcurrentHashMap 裡面的比較重要的引數: ```java //最大容量 private static final int MAXIMUM_CAPACITY = 1 << 30; //預設初始化容量 private static final int DEFAULT_CAPACITY = 16; //負載因子 private static final float LOAD_FACTOR = 0.75f; //連結串列轉為紅黑樹的臨界值 static final int TREEIFY_THRESHOLD = 8; //紅黑樹轉為連結串列的臨界值 static final int UNTREEIFY_THRESHOLD = 6; //當容量大於64時,連結串列才會轉為紅黑樹,否則,即便連結串列長度大於8,也不會轉,而是會擴容 static final int MIN_TREEIFY_CAPACITY = 64; ``` 可以看到,以上的幾個屬性和 HashMap 一模一樣,除此之外,比較重要的一個引數就是: ```java private transient volatile int sizeCtl; ``` 在計算出陣列長度、也就是裝整個 Map 的那個 Node[] table 的長度之後,是賦值給 sizeCtl 這個元素的。 如果說使用無參構造,那麼初始化的時候,**sizeCtl** 會是 16,其他的情況會計算成為一個 2 的冪次方數,也和 HashMap 是一樣的。另外,**sizeCtl** 這個引數的值還有別的含義: * 負數代表正在進行初始化或擴容操作 * -1代表正在初始化 * -N 表示,這個高16位表示當前擴容的標誌,每次擴容都會生成一個不一樣的標誌,低16位表示參與擴容的執行緒數量 * 正數或 0,0 代表 hash 表那個陣列還沒有被初始化,正數表示達到這個值需要擴容(擴容閾值,其實就等於(容量 * 負載因子),也就是陣列長度*0.75)。 還有一部分基本是和擴容相關的屬性,第一眼看過去可能不能理解這些什麼時候會用,下面講到擴容方法的時候就會用到: ```java //擴容相關,每個執行緒負責最小桶個數 private static final int MIN_TRANSFER_STRIDE = 16; //擴容相關,為了計算sizeCtl private static int RESIZE_STAMP_BITS = 16; //最大輔助擴容執行緒數量 private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1; //擴容相關,為了計算sizeCtl private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS; //下面幾個是狀態值 //MOVED表示正在擴容 static final int MOVED = -1; // hash for forwarding nodes //-2表示紅黑樹標識 static final int TREEBIN = -2; // hash for roots of trees static final int RESERVED = -3; // hash for transient reservations //計算Hash值使用 static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash //可用CPU核數 static final int NCPU = Runtime.getRuntime().availableProcessors(); //用於記錄容器中插入的元素數量 private transient volatile long baseCount; ``` ## 2.3 jdk 8 的 put() 方法
和 jdk 8 的 HashMap 方法一樣,直接呼叫的是 putVal 方法去執行。
新增元素的相關操作之後,最後會呼叫 addCount 方法,也就是判斷是否需要擴容,在這裡面控制不同的策略。
transfer 方法主要就是完成將擴容任務分配給多個執行緒去處理,根據了CPU核心數和集合 length 計算每個核一輪處理桶的個數。 然後每個執行緒處理的最小單位只能是一個數組的位置,這個時候擴容之後,和HashMap 一樣,其實只有原位置或者 原位置+陣列長度 的位置,因為仍然有可能多個執行緒操作之間發生雜湊衝突,就用到 synchronized。 原始碼很長,這裡的詳細註釋參考的是一個部落格: https://www.cnblogs.com/gunduzi/p/13651664.html ```java /** * Moves and/or copies the nodes in each bin to new table. See * above for explanation. * * transferIndex 表示轉移時的下標,初始為擴容前的 length。 * * 我們假設長度是 32 */ private final void transfer(Node
如果說 put 的時候發現數組正在擴容,會執行 helpTransfer 方法,也就是這個執行緒來幫助進行擴容。