
Apache Hudi與Apache Flink整合
阿新 • • 發佈:2020-10-13
> 感謝王祥虎@wangxianghu 投稿
Apache Hudi是由Uber開發並開源的資料湖框架,它於2019年1月進入Apache孵化器孵化,次年5月份順利畢業晉升為Apache頂級專案。是當前最為熱門的資料湖框架之一。
## 1. 為何要解耦
Hudi自誕生至今一直使用Spark作為其資料處理引擎。如果使用者想使用Hudi作為其資料湖框架,就必須在其平臺技術棧中引入Spark。放在幾年前,使用Spark作為大資料處理引擎可以說是很平常甚至是理所當然的事。因為Spark既可以進行批處理也可以使用微批模擬流,流批一體,一套引擎解決流、批問題。然而,近年來,隨著大資料技術的發展,同為大資料處理引擎的Flink逐漸進入人們的視野,並在計算引擎領域獲佔據了一定的市場,大資料處理引擎不再是一家獨大。在大資料技術社群、論壇等領地,Hudi是否支援使用flink計算引擎的的聲音開始逐漸出現,並日漸頻繁。所以使Hudi支援Flink引擎是個有價值的事情,而整合Flink引擎的前提是Hudi與Spark解耦。
同時,縱觀大資料領域成熟、活躍、有生命力的框架,無一不是設計優雅,能與其他框架相互融合,彼此借力,各專所長。因此將Hudi與Spark解耦,將其變成一個引擎無關的資料湖框架,無疑是給Hudi與其他元件的融合創造了更多的可能,使得Hudi能更好的融入大資料生態圈。
## 2. 解耦難點
Hudi內部使用Spark API像我們平時開發使用List一樣稀鬆平常。自從資料來源讀取資料,到最終寫出資料到表,無處不是使用Spark RDD作為主要資料結構,甚至連普通的工具類,都使用Spark API實現,可以說Hudi就是用Spark實現的一個通用資料湖框架,它與Spark的繫結可謂是深入骨髓。
此外,此次解耦後集成的首要引擎是Flink。而Flink與Spark在核心抽象上差異很大。Spark認為資料是有界的,其核心抽象是一個有限的資料集合。而Flink則認為資料的本質是流,其核心抽象DataStream中包含的是各種對資料的操作。同時,Hudi內部還存在多處同時操作多個RDD,以及將一個RDD的處理結果與另一個RDD聯合處理的情況,這種抽象上的區別以及實現時對於中間結果的複用,使得Hudi在解耦抽象上難以使用統一的API同時操作RDD和DataStream。
## 3. 解耦思路
理論上,Hudi使用Spark作為其計算引擎無非是為了使用Spark的分散式計算能力以及RDD豐富的運算元能力。拋開分散式計算能力外,Hudi更多是把 RDD作為一個數據結構抽象,而RDD本質上又是一個有界資料集,因此,把RDD換成List,在理論上完全可行(當然,可能會犧牲些效能)。為了儘可能保證Hudi Spark版本的效能和穩定性。我們可以保留將有界資料集作為基本操作單位的設定,Hudi主要操作API不變,將RDD抽取為一個泛型, Spark引擎實現仍舊使用RDD,其他引擎則根據實際情況使用List或者其他有界資料集。
解耦原則:
1)統一泛型。Spark API用到的`JavakRDD`,`JavaRDD`,`JavaRDD`統一使用泛型`I,K,O`代替;
2)去Spark化。抽象層所有API必須與Spark無關。涉及到具體操作難以在抽象層實現的,改寫為抽象方法,引入Spark子類實現。
例如:Hudi內部多處使用到了`JavaSparkContext#map()`方法,去Spark化,則需要將`JavaSparkContext`隱藏,針對該問題我們引入了`HoodieEngineContext#map()`方法,該方法會遮蔽`map`的具體實現細節,從而在抽象成實現去Spark化。
3)抽象層儘量減少改動,保證hudi原版功能和效能;
4)使用`HoodieEngineContext`抽象類替換`JavaSparkContext`,提供執行環境上下文。
## 4.Flink整合設計
Hudi的寫操作在本質上是批處理,`DeltaStreamer`的連續模式是通過迴圈進行批處理實現的。為使用統一API,Hudi整合flink時選擇攢一批資料後再進行處理,最後統一進行提交(這裡flink我們使用List來攢批資料)。
攢批操作最容易想到的是通過使用時間視窗來實現,然而,使用視窗,在某個視窗沒有資料流入時,將沒有輸出資料,Sink端難以判斷同一批資料是否已經處理完。因此我們使用flink的檢查點機制來攢批,每兩個barrier之間的資料為一個批次,當某個子任務中沒有資料時,mock結果資料湊數。這樣在Sink端,當每個子任務都有結果資料下發時即可認為一批資料已經處理完成,可以執行commit。
DAG如下:
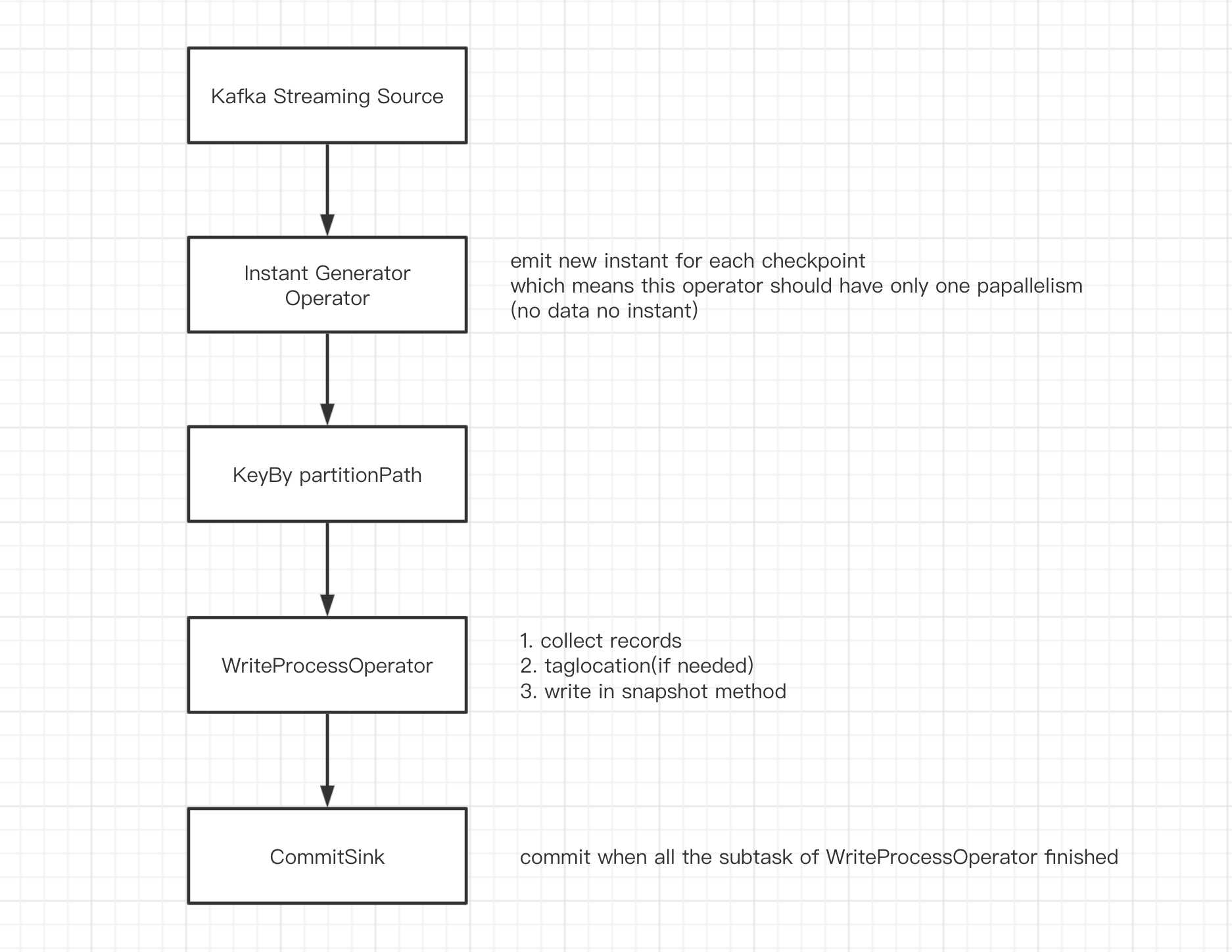
- source 接收kafka資料,轉換成`List`;
- InstantGeneratorOperator 生成全域性唯一的instant.當上一個instant未完成或者當前批次無資料時,不建立新的instant;
- KeyBy partitionPath 根據 `partitionPath`分割槽,避免多個子任務寫同一個分割槽;
- WriteProcessOperator 執行寫操作,噹噹前分割槽無資料時,向下遊傳送空的結果資料湊數;
- CommitSink 接收上游任務的計算結果,當收到 `parallelism`個結果時,認為上游子任務全部執行完成,執行commit.
注:
`InstantGeneratorOperator`和`WriteProcessOperator` 均為自定義的Flink運算元,`InstantGeneratorOperator`會在其內部阻塞檢查上一個instant的狀態,保證全域性只有一個inflight(或requested)狀態的instant.`WriteProcessOperator`是實際執行寫操作的地方,其寫操作在checkpoint時觸發。
## 5. 實現示例
### 1) HoodieTable
```
/**
* Abstract implementation of a HoodieTable.
*
* @param Sub type of HoodieRecordPayload
* @param Type of inputs
* @param Type of keys
* @param Type of outputs
*/
public abstract class HoodieTable implements Serializable {
protected final HoodieWriteConfig config;
protected final HoodieTableMetaClient metaClient;
protected final HoodieIndex index;
public abstract HoodieWriteMetadata upsert(HoodieEngineContext context, String instantTime,
I records);
public abstract HoodieWriteMetadata insert(HoodieEngineContext context, String instantTime,
I records);
public abstract HoodieWriteMetadata bulkInsert(HoodieEngineContext context, String instantTime,
I records, Option> bulkInsertPartitioner);
......
}
```
`HoodieTable` 是 hudi的核心抽象之一,其中定義了表支援的`insert`,`upsert`,`bulkInsert`等操作。以 `upsert` 為例,輸入資料由原先的 `JavaRDD inputRdds` 換成了 `I records`, 執行時 `JavaSparkContext jsc` 換成了 `HoodieEngineContext context`.
從類註釋可以看到 `T,I,K,O`分別代表了hudi操作的負載資料型別、輸入資料型別、主鍵型別以及輸出資料型別。這些泛型將貫穿整個抽象層。
### 2) HoodieEngineContext
```
/**
* Base class contains the context information needed by the engine at runtime. It will be extended by different
* engine implementation if needed.
*/
public abstract class HoodieEngineContext {
public abstract List map(List data, SerializableFunction func, int parallelism);
public abstract List flatMap(List data, SerializableFunction> func, int parallelism);
public abstract void foreach(List data, SerializableConsumer consumer, int parallelism);
......
}
```
`HoodieEngineContext` 扮演了 `JavaSparkContext` 的角色,它不僅能提供所有 `JavaSparkContext`能提供的資訊,還封裝了 `map`,`flatMap`,`foreach`等諸多方法,隱藏了`JavaSparkContext#map()`,`JavaSparkContext#flatMap()`,`JavaSparkContext#foreach()`等方法的具體實現。
以`map`方法為例,在Spark的實現類 `HoodieSparkEngineContext`中,`map`方法如下:
```
@Override
public List map(List data, SerializableFunction func, int parallelism) {
return javaSparkContext.parallelize(data, parallelism).map(func::apply).collect();
}
```
在操作List的引擎中其實現可以為(不同方法需注意執行緒安全問題,慎用`parallel()`):
```
@Override
public List map(List data, SerializableFunction func, int parallelism) {
return data.stream().parallel().map(func::apply).collect(Collectors.toList());
}
```
注:map函式中丟擲的異常,可以通過包裝`SerializableFunction func`解決.
這裡簡要介紹下 `SerializableFunction`:
```
@FunctionalInterface
public interface SerializableFunction extends Serializable {
O apply(I v1) throws Exception;
}
```
該方法實際上是 `java.util.function.Function` 的變種,與`java.util.function.Function` 不同的是 `SerializableFunction`可以序列化,可以拋異常。引入該函式是因為`JavaSparkContext#map()`函式能接收的入參必須可序列,同時在hudi的邏輯中,有多處需要拋異常,而在Lambda表示式中進行 `try catch` 程式碼會略顯臃腫,不太優雅。
## 6.現狀和後續計劃
### 6.1 工作時間軸
2020年4月,T3出行(楊華@vinoyang,王祥虎@wangxianghu)和阿里巴巴的同學(李少鋒@leesf)以及若干其他小夥伴一起設計、敲定了該解耦方案;
2020年4月,T3出行(王祥虎@wangxianghu)在內部完成了編碼實現,並進行了初步驗證,得出方案可行的結論;
2020年7月,T3出行(王祥虎@wangxianghu)將該設計實現和基於新抽象實現的Spark版本推向社群(HUDI-1089);
2020年9月26日,順豐科技基於T3內部分支修改完善的版本在 Apache Flink Meetup(深圳站)公開PR, 使其成為業界第一個在線上使用Flink將資料寫hudi的企業。
2020年10月2日,HUDI-1089 合併入hudi主分支,標誌著hudi-spark解耦完成。
### 6.2 後續計劃
1)推進hudi和flink整合
將flink與hudi的整合儘快推向社群,在初期,該特性可能只支援kafka資料來源。
2)效能優化
為保證hudi-spark版本的穩定性和效能,此次解耦沒有太多考慮flink版本可能存在的效能問題。
3)類flink-connector-hudi第三方包開發
將hudi-flink的繫結做成第三方包,使用者可以在flink應用中以編碼方式讀取任意資料來源,通過這個第三方包寫