
golang拾遺:為什麼我們需要泛型
阿新 • • 發佈:2020-10-17
從golang誕生起是否應該新增泛型支援就是一個熱度未曾消減的議題。泛型的支持者們認為沒有泛型的語言是不完整的,而泛型的反對者們則認為介面足以取代泛型,增加泛型只會徒增語言的複雜度。雙方各執己見,爭執不下,直到官方最終確定泛型是go2的發展路線中的重中之重。
今天我們就來看看為什麼我們需要泛型,沒有泛型時我們在做什麼,泛型會帶來哪些影響,泛型能拯救我們嗎?
void qsort(void *base, size_t nmemb, size_t size,
int (*compar)(const void *, const void *));
void *bsearch(const void *key, const void *base,
size_t nmemb, size_t size,
int (*compar)(const void *, const void *));
```
更普遍的,你可以用連結串列去實現佇列:
```c++
typedef struct node {
int val;
struct node *next;
} node_t;
void enqueue(node_t **head, int val) {
node_t *new_node = malloc(sizeof(node_t));
if (!new_node) return;
new_node->val = val;
new_node->next = *head;
*head = new_node;
}
```
原理同樣是將建立具體的資料的任務外包,只不過連結串列額外增加了一層node的包裝罷了。
那麼這麼做的好處和壞處是什麼呢?
好處是我們可以遵守DRY原則了,同時還能專注於佇列本身的實現。
壞處那就有點多了:
- 首先是型別擦除的同時沒有任何型別檢測的手段,因此型別安全無從保證,比如存進去的可以是`int`,取出來的時候你可以轉換成`char*`,程式不會給出任何警告,等你準備從這個`char*`裡取出某個位置上的字元的時候就會引發未定義行為,從而出現許許多多奇形怪狀的bug
- 只能存指標型別
- 如何確定佇列裡儲存資料的所有權?交給佇列管理會增加佇列實現的複雜性,不交給佇列管理就需要手動追蹤N個物件的生命週期,心智負擔很沉重,並且如果我們是存入的區域性變數的指標,那麼交給佇列管理就一定會導致free出現未定義行為,從程式碼層面我們是幾乎不能區分一個指標是不是真的指向了堆上的內容的
- 依舊不能避免書寫型別程式碼,首先使用資料時要從`void*`轉換為對應型別,其次我們需要書寫如qsort例子裡那樣的幫助函式。
### 動態型別語言的特例
在真正進入本節的主題之前,我想先介紹下什麼是動態型別,什麼是靜態型別。
所謂靜態型別,就是在編譯期能夠確定的變數、表示式的資料型別,換而言之,編譯期如果就能確定某個型別的記憶體佈局,那麼它就是靜態型別。舉個c語言的例子:
```c
int a = 0;
const char *str = "hello generic";
double values[] = {1., 2., 3.};
```
上述程式碼中`int`、`const char *`、`double[3]`都是靜態型別,其中`int`和`const char *`(指標型別不受底層型別的影響,大家有著相同的大小)標準中都給出了型別所需的最小記憶體大小,而陣列型別是帶有長度的,或者是在表示式和引數傳遞中退化(decay)為指標型別,因此編譯器在編譯這些程式碼的時候就能知道變數所需的記憶體大小,進而確定了其在記憶體中的佈局。當然靜態型別其中還有許多細節,這裡暫時不必深究。
回過來看動態型別就很好理解了,編譯期間無法確定某個變數、表示式的具體型別,這種型別就是動態的,例如下面的python程式碼:
```python
name = 'apocelipes'
name = 12345
```
name究竟是什麼型別的變數?不知道,因為name實際上可以賦值任意的資料,我們只能在執行時的某個點做型別檢測,然後斷言name是xxx型別的,然而過了這個時間點之後name還可以賦值一個完全不同型別的資料。
好了現在我們回到正題,可能你已經猜到了,我要說的特例是什麼。沒錯,因為動態型別語言實際上不關心資料的具體型別是什麼,所以即使沒有泛型你也可以寫出類似泛型的程式碼,而且通常它們工作得很好:
```python
class Queue:
def __init__(self):
self.data = []
def push(self, value):
self.data.append()
def pop(self):
self.data.pop()
def take(self, index):
return self.data[index]
```
我們既能放字串進`Queue`也能放整數和浮點數進去。然而這並不能稱之為泛型,使用泛型除了因為可以少寫重複的程式碼,更重要的一點是可以確保程式碼的型別安全,看如下例子,我們給Queue新增一個方法:
```python
def transform(self):
for i in range(len(self.data)):
self.data[i] = self.data[i].upper()
```
我們提供了一個方法,可以將佇列中的字串從小寫轉換為大寫。問題發生了,我們的佇列不僅可以接受字串,它還可以接受數字,這時候如果我們呼叫`transform`方法就會發生執行時異常:`AttributeError: 'int' object has no attribute 'upper'`。那麼怎麼避免問題呢?新增執行時的型別檢測就可以了,然而這樣做有兩個無法繞開的弊端:
- 寫出了型別相關的程式碼,和我們本意上想要實現型別無關的程式碼結構相沖突
- 限定了演算法只能由幾種資料型別使用,但事實上有無限多的型別可以實現upper方法,然而我們不能在型別檢查裡一一列舉他們,從而導致了我們的通用演算法變為了限定演算法。
## 動靜結合
沒有泛型的世界實在是充滿了煎熬,不是在違反DRY原則的邊緣反覆試探,就是冒著型別安全的風險激流勇進。有什麼能脫離苦海的辦法嗎?
作為一門靜態強型別語言,golang提供了一個不是太完美的答案——interface。
### 使用interface模擬泛型
interface可以接受任何滿足要求的型別的資料,並且具有執行時的型別檢查。雙保險很大程度上提升了程式碼的安全性。
一個典型的例子就是標準庫裡的containers:
```golang
package list // import "container/list"
Package list implements a doubly linked list.
To iterate over a list (where l is a *List):
for e := l.Front(); e != nil; e = e.Next() {
// do something with e.Value
}
type Element struct{ ... }
type List struct{ ... }
func New() *List
type Element struct {
// The value stored with this element.
Value interface{}
// Has unexported fields.
}
Element is an element of a linked list.
func (e *Element) Next() *Element
func (e *Element) Prev() *Element
type List struct {
// Has unexported fields.
}
List represents a doubly linked list. The zero value for List is an empty
list ready to use.
func New() *List
func (l *List) Back() *Element
func (l *List) Front() *Element
func (l *List) Init() *List
func (l *List) InsertAfter(v interface{}, mark *Element) *Element
func (l *List) InsertBefore(v interface{}, mark *Element) *Element
func (l *List) Len() int
func (l *List) MoveAfter(e, mark *Element)
func (l *List) MoveBefore(e, mark *Element)
func (l *List) MoveToBack(e *Element)
func (l *List) MoveToFront(e *Element)
func (l *List) PushBack(v interface{}) *Element
func (l *List) PushBackList(other *List)
...
```
這就是在上一大節中的方案2的型別安全強化版。介面的工作原理本文不會詳述。
但事情遠沒有結束,假設我們要對一個數組實現indexOf的通用演算法呢?你的第一反應大概是下面這段程式碼:
```golang
func IndexOfInterface(arr []interface{}, value interface{}) int {
for i, v := range arr {
if v == value {
return i
}
}
return -1
}
```
這裡你會接觸到interface的第一個坑。
### interface會進行嚴格的型別檢查
看看下面程式碼的輸出,你能解釋為什麼嗎?
```golang
func ExampleIndexOfInterface() {
arr := []interface{}{uint(1),uint(2),uint(3),uint(4),uint(5)}
fmt.Println(IndexOfInterface(arr, 5))
fmt.Println(IndexOfInterface(arr, uint(5)))
// Output:
// -1
// 4
}
```
會出現這種結果是因為interface的相等需要型別和值都相等,字面量5的值是int,所以沒有搜尋到相等的值。
想要避免這種情況也不難,建立一個`Comparable`介面即可:
```golang
type Comparator interface {
Compare(v interface{}) bool
}
func IndexOfComparator(arr []Comparator, value Comparator) int {
for i,v := range arr {
if v.Compare(value) {
return i
}
}
return -1
}
```
這回我們不會出錯了,因為字面量根本不能傳入函式,因為內建型別都沒實現`Comparator`介面。
### 內建型別何去何從
然而這是介面的第二個坑,我們不得不為內建型別建立包裝類和包裝方法。
假設我們還想把前文的`arr`直接傳入`IndexOfComparator`,那必定得到編譯器的抱怨:
```
cannot use arr (type []interface {}) as type []Comparator in argument to IndexOfComparator
```
為了使用這個函式我們不得不對程式碼進行修改:
```golang
type MyUint uint
func (u MyUint) Compare(v interface{}) bool {
value := v.(MyUint)
return u == value
}
arr2 := []Comparator{MyUint(1),MyUint(2),MyUint(3),MyUint(4),MyUint(5)}
fmt.Println(IndexOfComparator(arr2, MyUint(5)))
```
我們希望泛型能簡化程式碼,但現在卻反其道而行之了。
### 效能陷阱
第三個,也是被人詬病最多的,是介面帶來的效能下降。
我們對如下幾個函式做個簡單的效能測試:
```golang
func IndexOfByReflect(arr interface{}, value interface{}) int {
arrValue := reflect.ValueOf(arr)
length := arrValue.Len()
for i := 0; i < length; i++ {
if arrValue.Index(i).Interface() == value {
return i
}
}
return -1
}
func IndexOfInterface(arr []interface{}, value interface{}) int {
for i, v := range arr {
if v == value {
return i
}
}
return -1
}
func IndexOfInterfacePacking(value interface{}, arr ...interface{}) int {
for i, v := range arr {
if v == value {
return i
}
}
return -1
}
```
這是測試程式碼(golang1.15.2):
```golang
const ArrLength = 500
var _arr []interface{}
var _uintArr []uint
func init() {
_arr = make([]interface{}, ArrLength)
_uintArr = make([]uint, ArrLength)
for i := 0; i < ArrLength - 1; i++ {
_uintArr[i] = uint(rand.Int() % 10 + 2)
_arr[i] = _uintArr[i]
}
_arr[ArrLength - 1] = uint(1)
_uintArr[ArrLength - 1] = uint(1)
}
func BenchmarkIndexOfInterface(b *testing.B) {
for i := 0; i < b.N; i++ {
IndexOfInterface(_arr, uint(1))
}
}
func BenchmarkIndexOfInterfacePacking(b *testing.B) {
for i := 0; i < b.N; i++ {
IndexOfInterfacePacking(uint(1), _arr...)
}
}
func indexOfUint(arr []uint, value uint) int {
for i,v := range arr {
if v == value {
return i
}
}
return -1
}
func BenchmarkIndexOfUint(b *testing.B) {
for i := 0; i < b.N; i++ {
indexOfUint(_uintArr, uint(1))
}
}
func BenchmarkIndexOfByReflectInterface(b *testing.B) {
for i := 0; i < b.N; i++ {
IndexOfByReflect(_arr, uint(1))
}
}
func BenchmarkIndexOfByReflectUint(b *testing.B) {
for i := 0; i < b.N; i++ {
IndexOfByReflect(_uintArr, uint(1))
}
}
```
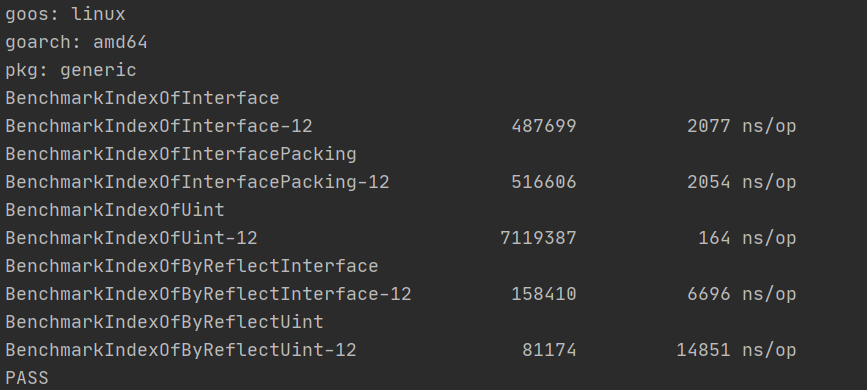
我們吃驚地發現,直接使用interface比原生型別慢了10倍,如果使用反射並接收原生將會慢整整100倍!
另一個使用介面的例子是比較slice是否相等,我們沒有辦法直接進行比較,需要藉助輔助手段,在我以前的[這篇部落格](https://www.cnblogs.com/apocelipes/p/11116725.html)有詳細的講解。效能問題同樣很顯眼。
### 複合型別的迷思
`interface{}`是介面,而`[]interface{}`只是一個普通的slice。複合型別中的介面是不存在協變的。所以下面的程式碼是有問題的:
```golang
func work(arr []interface{}) {}
ss := []string{"hello", "golang"}
work(ss)
```
類似的問題其實在前文裡已經出現過了。這導致我們無法用interface統一處理slice,因為`interface{}`並不是slice,slice的操作無法對interface使用。
為了解決這個問題,golang的sort包給出了一個頗為曲折的方案:
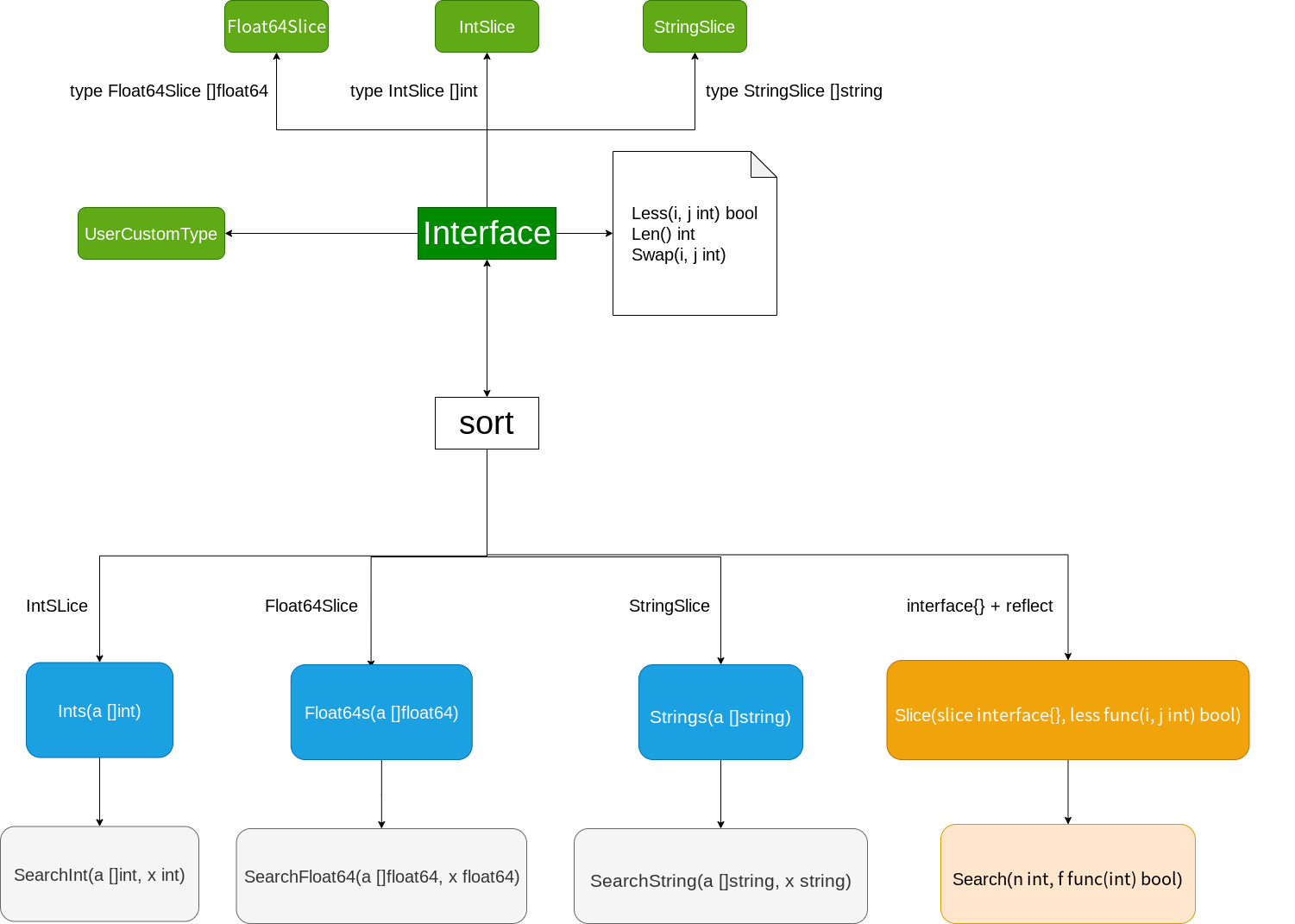
sort為了能處理slice,不得不包裝了常見的基本型別的slice,為了相容自定義型別包裡提供了`Interface`,需要你自己對自定義型別的slice進行包裝。
這實現就像是千層餅,一環套一環,即使內部的quicksort寫得再漂亮效能也是要打不少折扣的。
### 最後也是最重要的
對於獲取介面型別變數的值,我們需要型別斷言,然而型別斷言是執行時進行的:
```golang
var i interface{}
i = 1
s := i.(string)
```
這會導致panic。如果不想panic就需要第二個變數去獲取是否型別斷言成功:`s, ok := i.(string)`。
然而真正的泛型是在編譯期就能發現這類錯誤的,而不是等到程式執行得如火如荼時突然因為panic退出。
## 泛型帶來的影響,以及拯救
### 徹底從沒有泛型的泥沼中解放
同樣是上面的IndexOf的例子,有了泛型我們可以簡單寫為:
```golang
package main
import (
"fmt"
)
func IndexOf[T comparable](arr []T, value T) int {
for i, v := range arr {
if v == value {
return i
}
}
return -1
}
func main() {
q := []uint{1,2,3,4,5}
fmt.Println(IndexOf(q, 5))
}
```
`comparable`是go2提供的內建設施,代表所有可比較型別,你可以在[這裡](https://go2goplay.golang.org/)執行上面的測試程式碼。
泛型函式會自動做型別推導,字面量可以用於初始化uint型別,所以函式正常執行。
程式碼簡單幹淨,而且沒有效能問題(至少官方承諾泛型的絕大部分工作會在編譯期完成)。
再舉個slice判斷相等的例子:
```golang
func isEqual[T comparable](a,b []T) bool {
if len(a) != len(b) {
return false;
}
for i := range a {
if a[i] != b[i] {
return false
}
}
return true
}
```
除了大幅簡化程式碼之外,泛型還將給我們帶來如下改變:
- 真正的型別安全,像`isEqual([]int, []string)`這樣的程式碼在編譯時就會被發現並被我們修正
- 雖然泛型也不支援協變,但slice等複合型別只要符合引數推導的規則就能被使用,限制更少
- 沒有了介面和反射,效能自不必說,編譯期就能確定變數型別的話還可以增加程式碼被優化的機會
可以說泛型是真正救人於水火。這也是泛型最終能進入go2提案的原因。
### 泛型的代價
最後說了這麼多泛型的必要性,也該是時候談談泛型之暗了。
其實目前golang的泛型還在提案階段,雖然已經有了預覽版,但今後變數還是很多,所以這裡只能針對草案簡單說說兩方面的問題。
第一個還是型別系統的割裂問題,golang使用的泛型系統比typwscript更加嚴格,any約束的型別甚至無法使用賦值運算之外的其他內建運算子。因此想要型別能比較大小的時候必定建立自定義型別和自定義的型別約束,內建型別是無法新增方法的,所以需要包裝型別。
解決這個問題不難,一條路是golang官方提供內建型別的包裝型別,並且實現java那樣的自動拆裝箱。另一條路是支援類似rust的運算子過載,例如`add`代表`+`,`mul`代表`*`,這樣只需要將內建運算子進行簡單的對映即可相容內建型別,同時又能滿足自定義型別。不過鑑於golang官方一直對運算子過載持否定態度,方案2也只能想想了。
另一個黑暗面就是泛型如何實現,現有的主流方案不是型別擦除(java,typescript),就是將泛型程式碼看作模板進行例項化程式碼生成(c++,rust),另外還有個另類的c#在執行時進行例項化。
目前社群仍然偏向於模板替換,採用型別字典的方案暫時無法處理泛型struct,實現也非常複雜,所以反對聲不少。如果最終敲定了模板方案,那麼golang要面對的新問題就是連結時間過長和程式碼膨脹了。一份泛型程式碼可以生產數份相同的例項,這些例項需要在連結階段被連結器剔除,這會導致連結時間爆增。程式碼膨脹是老生常談的問題了,更大的二進位制檔案會導致啟動更慢,程式碼裡的雜音更多導致cpu快取利用率的下降。
連結時間的優化社群有人提議可以在編譯期標記各個例項提前去重,因為golang各個程式碼直接是有清晰的聯絡的,不像c++檔案之間單獨編譯最終需要在連結階段統一處理。程式碼膨脹目前沒有辦法,而且程式碼膨脹會不會對效能產生影響,影響多大能否限定在可接受範圍都還是未知數。
但不管怎麼說,我們都需要泛型,因為帶來的遠比失去的要多。
##### 參考
## 沒有泛型的世界 泛型最常見也是最簡單的需求就是建立一組操作相同或類似的演算法,這些演算法應該是和資料型別無關的,不管什麼資料型別只要符合要求就可以操作。 看起來很簡單,我們只需要專注於演算法自身的實現,而不用操心其他細枝末節。然而現實是骨感的,想要實現型別無關演算法在沒有泛型的世界裡卻是困難的,需要在許多條件中利弊取捨。 下面我們就來看看在沒有泛型的參與下我們是如何處理資料的。 ### 暴力窮舉 這是最簡單也是最容易想到的方法。 既然演算法部分的程式碼是幾乎相同的,那麼就copy幾遍,然後把資料型別的地方做個修改替換,這樣的工作甚至可以用文字編輯器的程式碼片段+查詢替換來快速實現。比如下面的c程式碼: ```c++ float a = logf(2.0f); double b = log(2.0); typedef struct { int *data; unsigned int max_size; } IntQueue; typedef struct { double *data; unsigned int max_size; } DoubleQueue; IntQueue* NewIntQueue(unsigned int size) { IntQueue* q = (IntQueue*)malloc(sizeof(IntQueue)); if (q == NULL) { return NULL; } q->本文索引
- 沒有泛型的世界
- 暴力窮舉
- 依靠通用引用型別
- 動態型別語言的特例
- 動靜結合
- 使用interface模擬泛型
- interface會進行嚴格的型別檢查
- 內建型別何去何從
- 效能陷阱
- 複合型別的迷思
- 最後也是最重要的
- 泛型帶來的影響,以及拯救
- 徹底從沒有泛型的泥沼中解放
- 泛型的代價