
多目標跟蹤全解析,全網最全
與多目標跟蹤(Multiple Object Tracking簡稱MOT)對應的是單目標跟蹤(Single Object Tracking簡稱SOT),按照字面意思來理解,前者是對連續視訊畫面中多個目標進行跟蹤,後者是對連續視訊畫面中單個目標進行跟蹤。由於大部分應用場景都涉及到多個目標的跟蹤,因此多目標跟蹤也是目前大家主要研究內容,本文也主要介紹多目標跟蹤。跟蹤的本質是關聯視訊前後幀中的同一物體(目標),並賦予唯一TrackID。

隨著深度學習的興起,目標檢測的準確性越來越高,常見的yolo系列從V1到現在的V5(嚴格來講V5不太算),mAP一個比一個高,因此基於深度學習的目標檢測演算法實際工程落地也越來越廣泛,基於目標檢測的跟蹤我們稱為Tracking By Detecting,目標檢測演算法的輸出就是這種跟蹤演算法的輸入,比如left, top,width,right座標值。這種Tracking By Detecting的跟蹤演算法是大家講得比較多、工業界用得也比較廣的跟蹤演算法,我覺得主要還是歸功於目標檢測的成熟度越來越高。下面這張圖描述了Tracking By Detecting的跟蹤演算法流程:
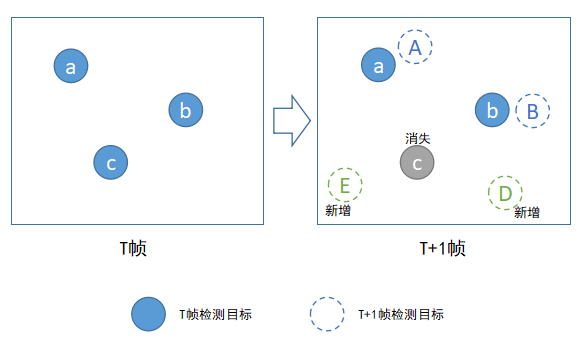
由上圖可以看出,這種跟蹤演算法要求有一種檢測演算法配合起來使用,可想而知,前面檢測演算法的穩定性會嚴重影響後面跟蹤演算法的效果。圖中實線圓形代表上一幀檢測到的目標,虛線圓形代表當前幀檢測到的目標,如何將前後幀目標正確關聯起來就是這類跟蹤演算法需要解決的問題。目標跟蹤是目標檢測的後續補充,它是某些視訊結構化應用中的必備環節,比如一些行為分析的應用系統中都需要先對檢測出來的目標進行跟蹤,然後再對跟蹤到的軌跡進行分析。

目標關聯
文章開頭提到過,目標跟蹤的本質是關聯視訊前後幀中的同一物體(目標),第T幀中有M個檢測目標,第T+1幀中有N個檢測目標,將前一幀中M個目標和後一幀中N個目標一一關聯起來,並賦予唯一標識TrackID,這個過程就是Tracking By Detecting跟蹤演算法的巨集觀流程。
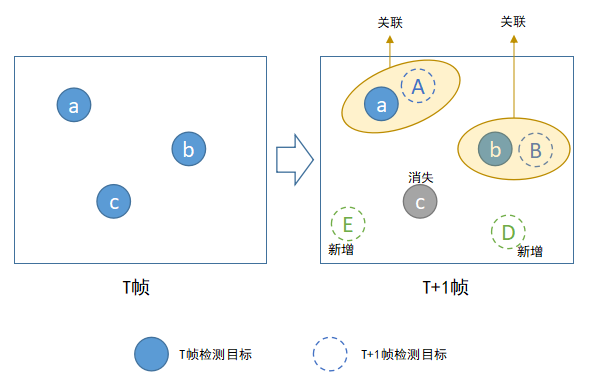
上圖描述目標關聯的具體流程,在實際目標關聯過程中,我們需要考慮的有:
1、如何處理中途出現的新目標
2、如何處理中途消失的目標
3、正確目標關聯
理想情況下,同一個物體(目標)在視訊畫面中從出現到消失,跟蹤演算法應該能賦予它唯一一個標識(TrackID),不管目標是否被遮擋、目標是否發生嚴重形變、是否和其他目標相距太近(相互干擾),只要這個目標被正確檢測出來,跟蹤演算法都應該能夠正確關聯上。但實際上,物體遮擋是跟蹤演算法最難解決的難題之一,物體被頻繁遮擋是TrackID變化的主要原因。原因很簡單,物體被遮擋後(或其他原因),檢測演算法檢測不到,跟蹤演算法無法連續關聯到每幀的資料,等該物體再出現時,物體在畫面中的位置、物體的外觀形狀與消失之前相比都發生了很大變化,而跟蹤演算法恰恰主要是根據物體的位置、外觀來進行資料關聯的。下面主要介紹目標跟蹤中兩種方式,一種容易實現、速度快,演算法純粹基於目標在畫面中的位置來進行資料關聯;另一種相對複雜,速度慢,演算法需要提取前後幀中每個目標的影象特徵(features),然後根據特徵匹配去做資料關聯。
基於座標的目標關聯
基於座標(目標中心點+長寬)的目標關聯是相對簡單的一種目標跟蹤方式,演算法認為前後幀中捱得近的物體為同一個目標,因為物體移動是平滑緩慢的,具體可以通過IOU(交併比,前後兩幀中目標檢測方框的重疊程度)來計算,這種演算法速度快、實現容易,在前面檢測演算法相對穩定的前提下,這種跟蹤方式能夠取得還不錯的效果,由於速度快,這種方式一般可以用於對實時性(realtime)要求比較高的場合。缺點也很明顯,因為它僅僅是以目標的座標(檢測演算法的輸出)為依據進行跟蹤的,所以受檢測演算法影響非常大,如果檢測演算法不穩定,對於一個視訊幀序列中的目標,檢測演算法經常漏檢,那麼通過這種方式去跟蹤效果就非常差。另外如果場景比較複雜,目標比較密集,這種跟蹤方式的效果也比不會太好,因為目標密集,相鄰目標的座標(left、top、width、height)重合度比較高,這給基於座標的目標關聯帶來困難。
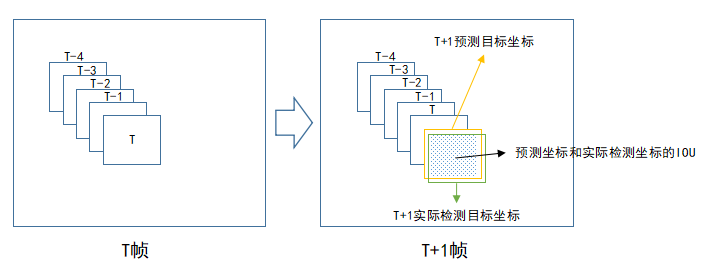
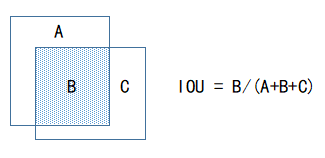
如上圖,在T+1幀中,我們根據目標前面若干幀的座標預測它在本幀中的座標(預測座標),然後再將該預測座標與本幀實際檢測的目標座標進行資料關聯。之所以需要先進行預測再關聯,是因為為了減少關聯過程的誤差,常見預測演算法可以使用卡爾曼濾波,根據目標前面若干座標值預測下一座標值,並且不斷地進行自我修正,卡爾曼濾波演算法網上有開原始碼。IOU(交併比)是衡量兩個矩形方框的重疊程度,IOU值越大代表矩形框重疊面積越大,它是目標檢測中常見的概念。在這裡,我們認為IOU越大,兩個目標為同一物體的可能性越大。
基於特徵的目標關聯
純粹基於座標的目標跟蹤演算法有一定的侷限性,單靠目標座標去關聯前後幀的同一目標在有些場合下效果比較差。在此基礎上,有人提出結合目標外觀特徵匹配做目標關聯,換句話說,在做目標關聯的時候,除了依賴目標座標外,還考慮目標的外觀特徵,道理很簡單:
前後兩幀中捱得近的物體且外觀長得比較像的物體為同一目標。
這樣的跟蹤方式準確率更高,但是同時出現了一個問題:如何判斷兩個物體外觀長得像?在計算機視覺中,有一個專門的研究領域叫Target Re-Identification(目標重識別),先通過對兩個待比較目標進行特徵編碼(特徵提取),然後再根據兩個特徵的相似度,來判斷這兩個目標是否為同一個物體,兩個特徵越相似代表兩個目標為同一個物體的可能性越大。Target Re-Identification常用在影象搜尋、軌跡生成(跨攝像機目標重識別)以及今天這裡要說的目標跟蹤。
熟悉深度學習的童鞋應該很清楚,神經網路的主要作用就是對原始輸入資料進行特徵編碼,尤其在計算機視覺中,卷積神經網路主要用於影象的特徵提取(Feature Extraction),從二維影象中提取高維特徵,這些特徵是對原始輸入影象的一種抽象表示,因此訓練神經網路的過程也可以稱為Representation Learning。相同或者相似的輸入圖片,神經網路提取到的特徵應該也是相同或者相似的。我們只要計算兩個特徵的相似度,就可以判斷原始輸入影象的相似性。
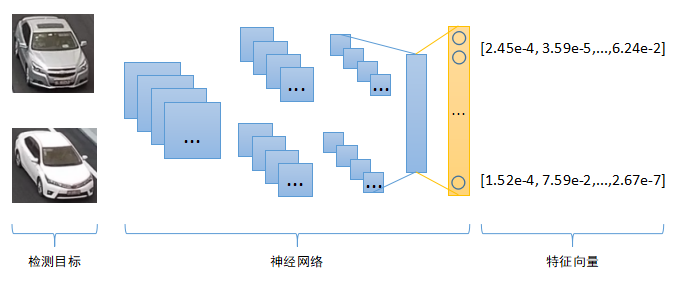
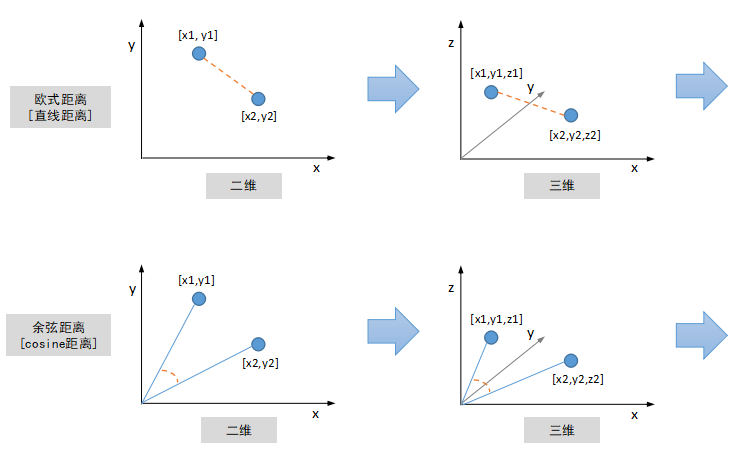
那麼如何計算兩個影象特徵的相似度呢?影象特徵的數學表示是一串數字,組合起來就是一個Vector向量,二維向量可以看成是平面座標系中的點,三維向量可以看成立體空間中的點,依次類推,因此影象特徵也被稱作為“特徵向量”。有很多度量標準來衡量兩個特徵向量的相似程度,最常見的是“歐式距離”,即計算兩點之間的直線距離,二維三維空間中兩點之間的直線距離我們都非常熟悉,更高維空間中兩點距離計算原理跟二三維空間保持一致。另外除了“歐式距離”之外,還有一種常見距離度量標準叫“餘弦距離”,計算兩個向量(點到中心原點的射線)之間的夾角,夾角越小,代表兩個向量越相似。
外觀特徵提取是一個耗時過程,因此對實時性要求比較高或者需要同時處理視訊路數比較多的場合可能不太適合。但是這種基於外觀特徵的跟蹤方式效果相對更好,對遮擋、目標密集等問題魯棒性更好,因為目標遮擋再出現後,只要特徵提取網路訓練得夠好,目標尺寸、角度變化對它的外觀特徵影響不大,因此關聯準確性也更高。類似的,這個也適用於目標密集場景。外觀特徵提取需要定義一個合適的神經網路結構,採用相關素材去訓練這個網路,網上有很多公開的Person-ReId資料集可以用來訓練行人跟蹤的特徵提取網路,類似的,還有一些Vehicle-ReId資料集可以用來訓練車輛跟蹤的特徵提取網路,關於這塊的內容,也是一個值得深入研究的領域,由於本篇文章主要介紹目標跟蹤,所以暫不展開講述了。

本文開頭第一張圖是基於座標的跟蹤方式效果圖,上圖是基於外觀特徵的跟蹤方式效果圖,我們可以看到,第一張圖中目標被遮擋再出現後,目標ID發生了變化,而第二張圖中大部分時候目標ID都比較穩定,同樣,人群密集場合中,同一目標ID發生改變的機率也小。實際上,同一目標ID是否發生變化是衡量跟蹤演算法好壞的一個重要指標,叫IDSwitch,同一目標ID變化次數越少,可以一定程度代表演算法跟蹤效果越好。
參考論文
| 1 | Simple Online Real-time Tracking | https://arxiv.org/pdf/1602.00763.pdf |
| 2 | Simple Online Real-time Tracking with a deep association metric | https://arxiv.org/pdf/1703.07402.pdf |
| 3 | Multiple Object Tracking: A Literature Review |
https://arxiv.org/pdf/1409.7618.pdf |