
主流開源分散式圖資料庫 Benchmark
阿新 • • 發佈:2020-10-21
> 本文由美團 NLP 團隊高辰、趙登昌撰寫
> 首發於 Nebula Graph 官方論壇:[https://discuss.nebula-graph.com.cn/t/topic/1377](https://discuss.nebula-graph.com.cn/t/topic/1377)

## 1. 前言
近年來,深度學習和知識圖譜技術發展迅速,相比於深度學習的“黑盒子”,知識圖譜具有很強的可解釋性,在搜尋推薦、智慧助理、金融風控等場景中有著廣泛的應用。美團基於積累的海量業務資料,結合使用場景進行充分地挖掘關聯,逐步建立起包括美食圖譜、旅遊圖譜、商品圖譜在內的近十個領域知識圖譜,並在多業務場景落地,助力本地生活服務的智慧化。
為了高效儲存並檢索圖譜資料,相比傳統關係型資料庫,選擇圖資料庫作為儲存引擎,在多跳查詢上具有明顯的效能優勢。當前業界知名的圖資料庫產品有數十款,選型一款能夠滿足美團實際業務需求的圖資料庫產品,是建設圖儲存和圖學習平臺的基礎。我們結合業務現狀,制定了選型的基本條件:
- **開源專案,對商業應用友好**
- 擁有對原始碼的控制力,才能保證資料安全和服務可用性。
- **支援叢集模式,具備儲存和計算的橫向擴充套件能力**
- 美團圖譜業務資料量可以達到千億以上點邊總數,吞吐量可達到數萬 qps,單節點部署無法滿足儲存需求。
- **能夠服務 OLTP 場景,具備毫秒級多跳查詢能力**
- 美團搜尋場景下,為確保使用者搜尋體驗,各鏈路的超時時間具有嚴格限制,不能接受秒級以上的查詢響應時間。
- **具備批量匯入資料能力**
- 圖譜資料一般儲存在 Hive 等資料倉庫中。必須有快速將資料匯入到圖儲存的手段,服務的時效性才能得到保證。
我們試用了 DB-Engines 網站上排名前 30 的圖資料庫產品,發現多數知名的圖資料庫開源版本只支援單節點,不能橫向擴充套件儲存,無法滿足大規模圖譜資料的儲存需求,例如:Neo4j、ArangoDB、Virtuoso、TigerGraph、RedisGraph。經過調研比較,最終納入評測範圍的產品為:NebulaGraph(原阿里巴巴團隊創業開發)、Dgraph(原 Google 團隊創業開發)、HugeGraph(百度團隊開發)。
## 2. 測試概要
### 2.1 硬體配置
- 資料庫例項:執行在不同物理機上的 Docker 容器。
- 單例項資源:32 核心,64GB 記憶體,1TB SSD 儲存。【Intel(R) Xeon(R) Gold 5218 CPU @ 2.30GHz】
- 例項數量:3
### 2.2 部署方案
- [Nebula v1.0.1](https://github.com/vesoft-inc/nebula)
Metad 負責管理叢集元資料,Graphd 負責執行查詢,Storaged 負責資料分片儲存。儲存後端採用 RocksDB。
|例項 1 | 例項 2 | 例項 3 |
|-|-|-|
|Metad | Metad | Metad|
|Graphd | Graphd | Graphd|
|Storaged[RocksDB] | Storaged[RocksDB] | Storaged[RocksDB]|
- [Dgraph v20.07.0](https://github.com/dgraph-io/dgraph)
Zero 負責管理叢集元資料,Alpha 負責執行查詢和儲存。儲存後端為 Dgraph 自有實現。
|例項 1 | 例項 2 | 例項 3 |
|-|-|-|
|Zero | Zero | Zero|
|Alpha | Alpha | Alpha|
- [HugeGraph v0.10.4](https://github.com/hugegraph/hugegraph)
HugeServer 負責管理叢集元資料和查詢。HugeGraph 雖然支援 RocksDB 後端,但不支援 RocksDB 後端的叢集部署,因此儲存後端採用 HBase。
|例項1 | 例項2 | 例項3 |
|-|-|-|
|HugeServer[HBase]|HugeServer[HBase]|HugeServer[HBase]|
|JournalNode | JournalNode | JournalNode|
|DataNode | DataNode | DataNode|
|NodeManager | NodeManager | NodeManager|
|RegionServer | RegionServer | RegionServer|
|ZooKeeper | ZooKeeper | ZooKeeper|
|NameNode | NameNode[Backup] | -|
| -|ResourceManager | ResourceManager[Backup]|
|HBase Master | HBase Master[Backup] |-|
## 3. 評測資料集
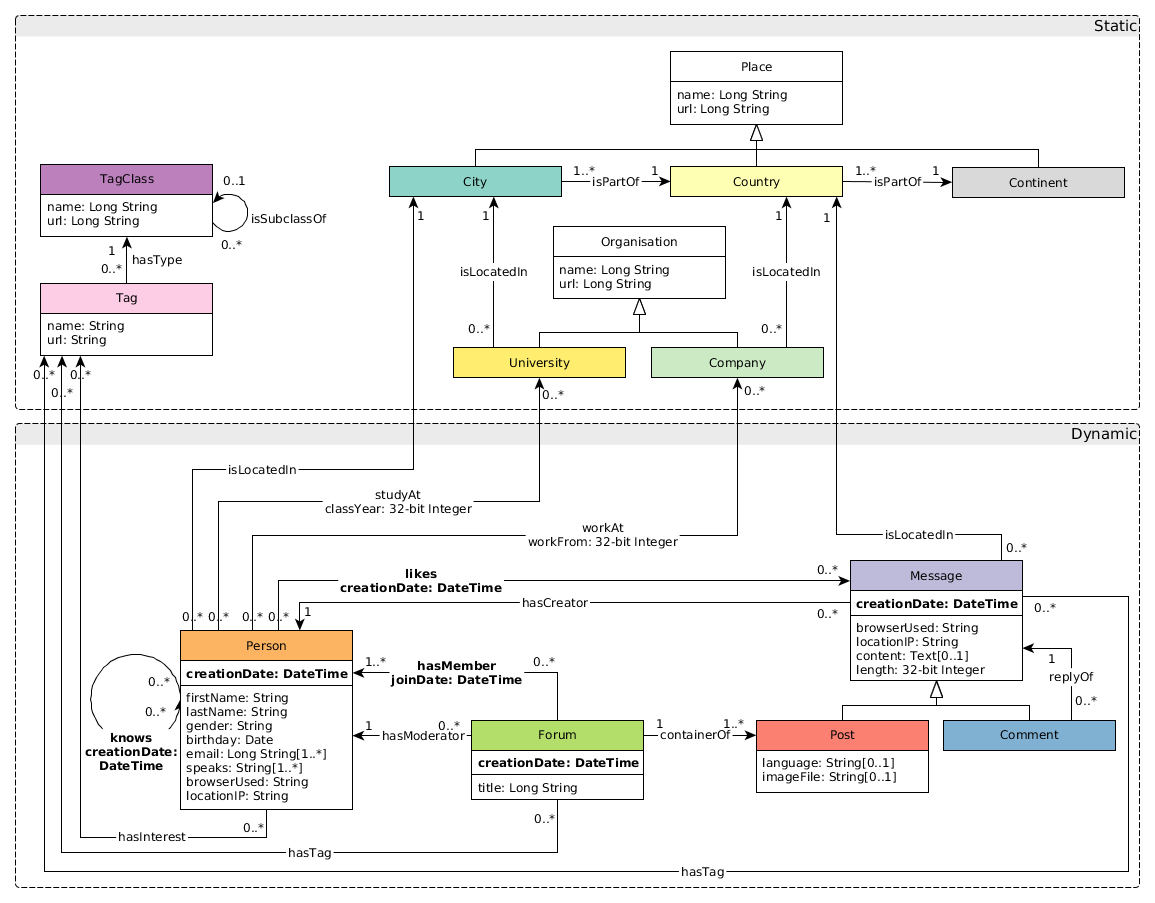
- 社交圖譜資料集:[https://github.com/ldbc](https://github.com/ldbc)011
- 生成引數:branch=stable, version=0.3.3, scale=1000
- 實體情況:4 類實體,總數 26 億
- 關係情況:19 類關係,總數 177 億
- 資料格式:csv
- GZip 壓縮後大小:194 G
## 4. 測試結果
### 4.1 批量資料匯入
#### 4.1.1 測試說明
批量匯入的步驟為:`Hive 倉庫底層 csv 檔案 -> 圖資料庫支援的中間檔案 -> 圖資料庫`。各圖資料庫具體匯入方式如下:
- [Nebula](https://github.com/vesoft-inc/nebula):執行 Spark 任務,從數倉生成 RocksDB 的底層儲存 sst 檔案,然後執行 sst Ingest 操作插入資料。
- [Dgraph](https://github.com/dgraph-io/dgraph):執行 Spark 任務,從數倉生成三元組 rdf 檔案,然後執行 bulk load 操作直接生成各節點的持久化檔案。
- [HugeGraph](https://github.com/hugegraph/hugegraph):支援直接從數倉的 csv 檔案匯入資料,因此不需要數倉-中間檔案的步驟。通過 loader 批量插入資料。
#### 4.1.2 測試結果
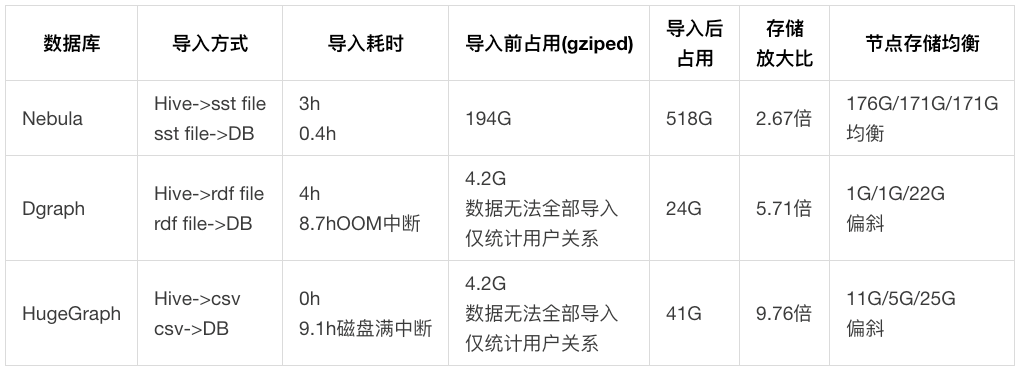
#### 4.1.3 資料分析
- Nebula:資料儲存分佈方式是主鍵雜湊,各節點儲存分佈基本均衡。匯入速度最快,儲存放大比最優。
- Dgraph:原始 194G 資料在記憶體 392G 的機器上執行匯入命令,8.7h 後 OOM 退出,無法匯入全量資料。資料儲存分佈方式是三元組謂詞,同一種關係只能儲存在一個數據節點上,導致儲存和計算嚴重偏斜。
- HugeGraph:原始 194G 的資料執行匯入命令,寫滿了一個節點 1,000G 的磁碟,造成匯入失敗,無法匯入全量資料。儲存放大比最差,同時存在嚴重的資料偏斜。
### 4.2 實時資料寫入
#### 4.2.1 測試說明
- 向圖資料庫插入點和邊,測試實時寫入和併發能力。
- 響應時間:固定的 50,000 條資料,以固定 qps 發出寫請求,全部發送完畢即結束。取客戶端從發出請求到收到響應的 Avg、p99、p999 耗時。
- 最大吞吐量:固定的 1,000,000 條資料,以遞增 qps 發出寫請求,Query 迴圈使用。取 1 分鐘內成功請求的峰值 qps 為最大吞吐量。
- 插入點
- Nebula
```
INSERT VERTEX t_rich_node (creation_date, first_name, last_name, gender, birthday, location_ip, browser_used) VALUES ${mid}:('2012-07-18T01:16:17.119+0000', 'Rodrigo', 'Silva', 'female', '1984-10-11', '84.194.222.86', 'Firefox')
```
- Dgraph
```
{
set {
<${m