
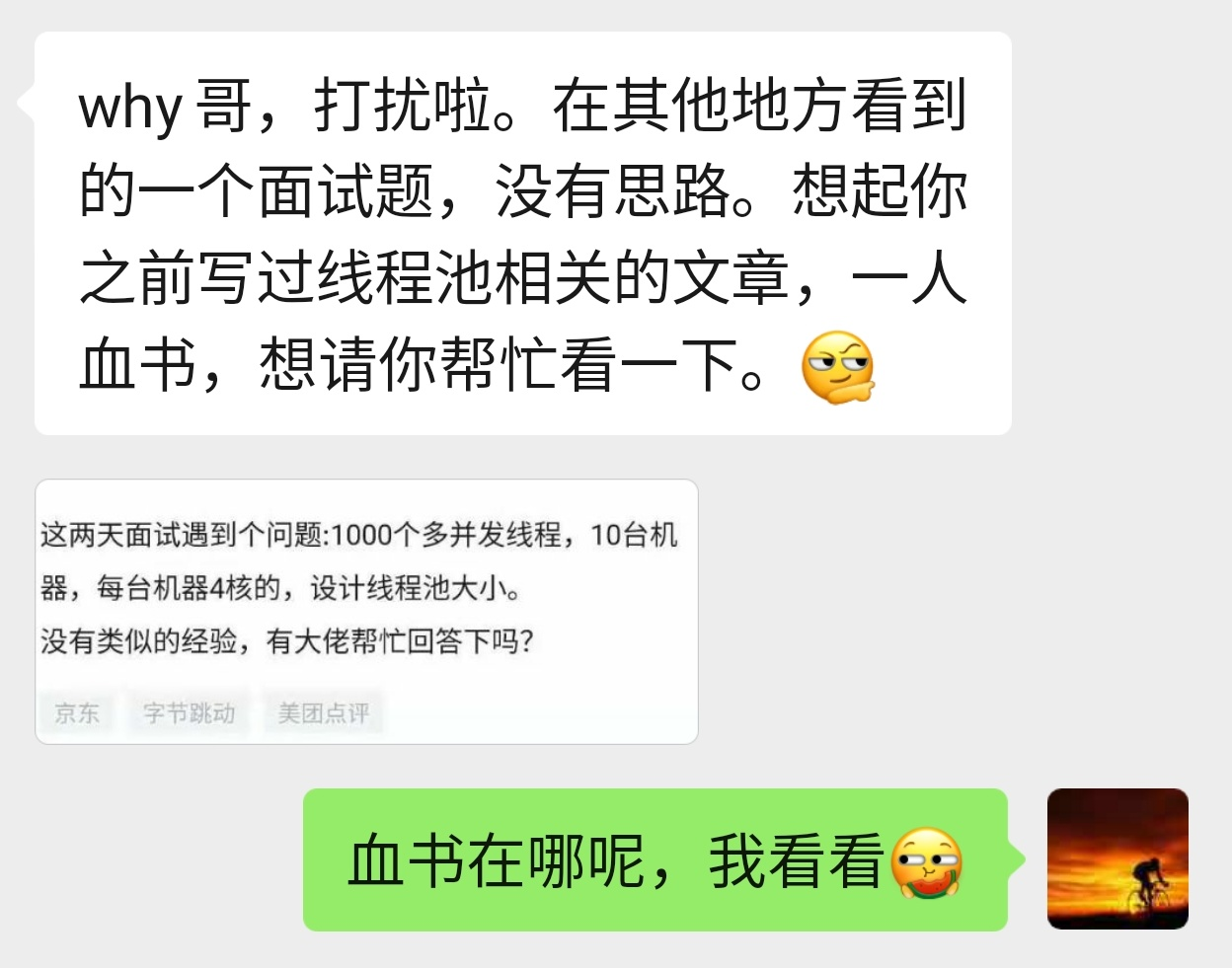
1000個併發執行緒,10臺機器,每臺機器4核,設計執行緒池大小
這是why哥的第 71 篇原創文章
一道面試題
兄弟們,怎麼說?
我覺得如果你工作了兩年左右的時間,或者是突擊準備了面試,這題回答個八成上來,應該是手到擒來的事情。這題中規中矩,考點清晰,可以說的東西不是很多。
但是這都上血書了,那不得分析一波?
先把這個面試題拿出來一下:
1000 多個併發執行緒,10 臺機器,每臺機器 4 核,設計執行緒池大小。
這題給的資訊非常的簡陋,但是簡陋的好處就是想象空間足夠大。

第一眼看到這題的時候,我直觀的感受到了兩個考點:
執行緒池設計。
負載均衡策略。
我就開門見山的給你說了,這兩個考點,剛好都在我之前的文章的射程範圍之內:
《如何設定執行緒池引數?美團給出了一個讓面試官虎軀一震的回答》
《吐血輸出:2萬字長文帶你細細盤點五種負載均衡策略》
下面我會針對我感受到的這兩個考點去進行分析。
執行緒池設計
我們先想簡單一點:1000 個併發執行緒交給 10 臺機器去處理,那麼 1 臺機器就是承擔 100 個併發請求。
100 個併發請求而已,確實不多。
而且他也沒有說是每 1 秒都有 1000 個併發執行緒過來,還是偶爾會有一次 1000 個併發執行緒過來。
先從執行緒池設計的角度去回答這個題。
要回答好這個題目,你必須有兩個最基本的知識貯備:
自定義執行緒池的 7 個引數。
JDK 執行緒池的執行流程。
先說第一個,自定義執行緒池的 7 個引數。
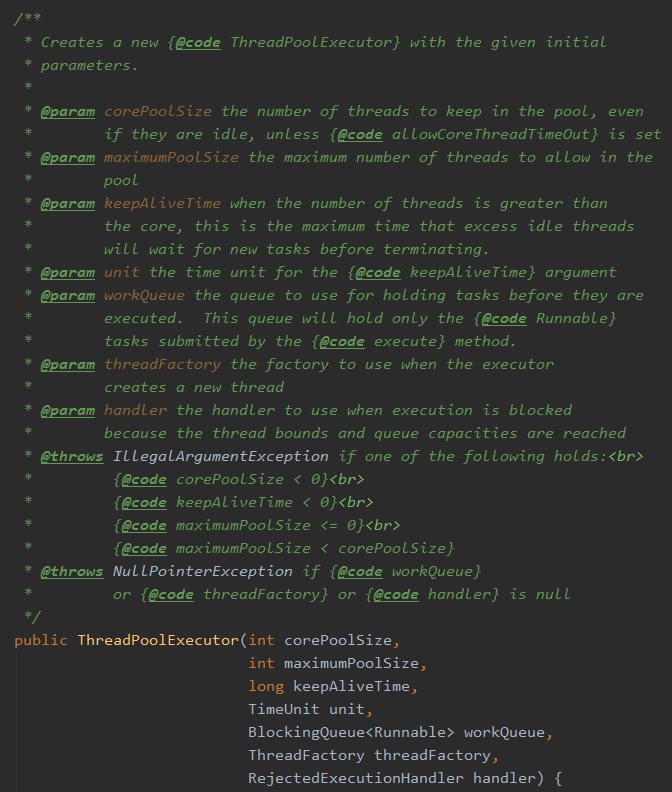
java.util.concurrent.ThreadPoolExecutor#ThreadPoolExecutor
害,這 7 個引數我真的都不想說了,你去翻翻歷史文章,我都寫過多少次了。你要是再說不出個頭頭是道的,你都對不起我寫的這些文章。
而且這個類上的 javadoc 已經寫的非常的明白了。這個 javadoc 是 Doug Lea 老爺子親自寫的,你都不拜讀拜讀?
為了防止你偷懶,我把老爺子寫的粘下來,我們一句句的看。
關於這幾個引數,我通過這篇文章再說最後一次。
如果以後的文章我要是再講這幾個引數,我就不叫 why 哥,以後你們就叫我小王吧。
寫著寫著,怎麼還有一種生氣的感覺呢。似乎突然明白了當年在講臺上越講越生氣的數學老師說的:這題我都講了多少遍了!還有人錯?

好了,不生氣了,說引數:
corePoolSize:the number of threads to keep in the pool, even if they are idle, unless {@code allowCoreThreadTimeOut} is set (核心執行緒數大小:不管它們建立以後是不是空閒的。執行緒池需要保持 corePoolSize 數量的執行緒,除非設定了 allowCoreThreadTimeOut。)
maximumPoolSize:the maximum number of threads to allow in the pool。 (最大執行緒數:執行緒池中最多允許建立 maximumPoolSize 個執行緒。)
keepAliveTime:when the number of threads is greater than the core, this is the maximum time that excess idle threads will wait for new tasks before terminating。 (存活時間:如果經過 keepAliveTime 時間後,超過核心執行緒數的執行緒還沒有接受到新的任務,那就回收。)
unit:the time unit for the {@code keepAliveTime} argument (keepAliveTime 的時間單位。)
workQueue:the queue to use for holding tasks before they are executed. This queue will hold only the {@code Runnable} tasks submitted by the {@code execute} method。 (存放待執行任務的佇列:當提交的任務數超過核心執行緒數大小後,再提交的任務就存放在這裡。它僅僅用來存放被 execute 方法提交的 Runnable 任務。所以這裡就不要翻譯為工作隊列了,好嗎?不要自己給自己挖坑。)
threadFactory:the factory to use when the executor creates a new thread。 (執行緒工程:用來建立執行緒工廠。比如這裡面可以自定義執行緒名稱,當進行虛擬機器棧分析時,看著名字就知道這個執行緒是哪裡來的,不會懵逼。)
handler :the handler to use when execution is blocked because the thread bounds and queue capacities are reached。 (拒絕策略:當佇列裡面放滿了任務、最大執行緒數的執行緒都在工作時,這時繼續提交的任務執行緒池就處理不了,應該執行怎麼樣的拒絕策略。)
第一個知識貯備就講完了,你先別開始背,這玩意你背下來有啥用,你得結合著執行流程去理解。
接下來我們看第二個:JDK 執行緒池的執行流程。
一圖勝千言:
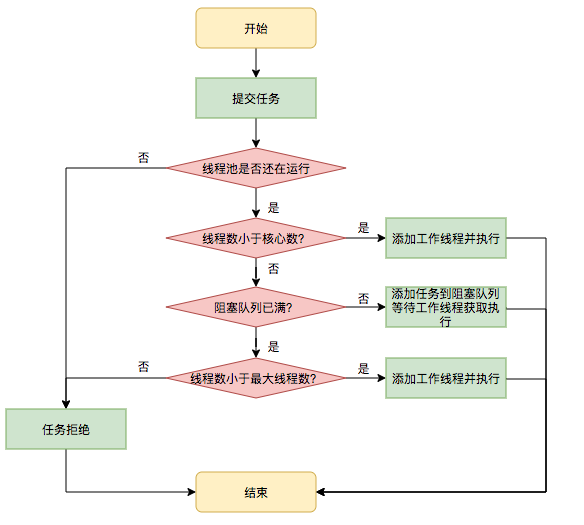
關於 JDK 執行緒池的 7 個引數和執行流程。
雖然我很久沒有參加面試了,但是我覺得這題屬於必考題吧。
所以如果你真的還不會,麻煩你寫個 Demo ,換幾個引數除錯一下。把它給掌握了。
而且還得多注意由這些知識點引申出來的面試題。
比如從圖片也可以看出來,JDK 執行緒池中如果核心執行緒數已經滿了的話,那麼後面再來的請求都是放到阻塞佇列裡面去,阻塞佇列再滿了,才會啟用最大執行緒數。
但是你得知道,假如我們是 web 服務,請求是通過 Tomcat 進來的話,那麼 Tomcat 執行緒池的執行流程可不是這樣的。
Tomcat 裡面的執行緒池的執行過程是:如果核心執行緒數用完了,接著用最大執行緒數,最後才提交任務到佇列裡面去的。這樣是為了保證響應時間優先。
所以,Tomcat 的執行流程是這樣的:
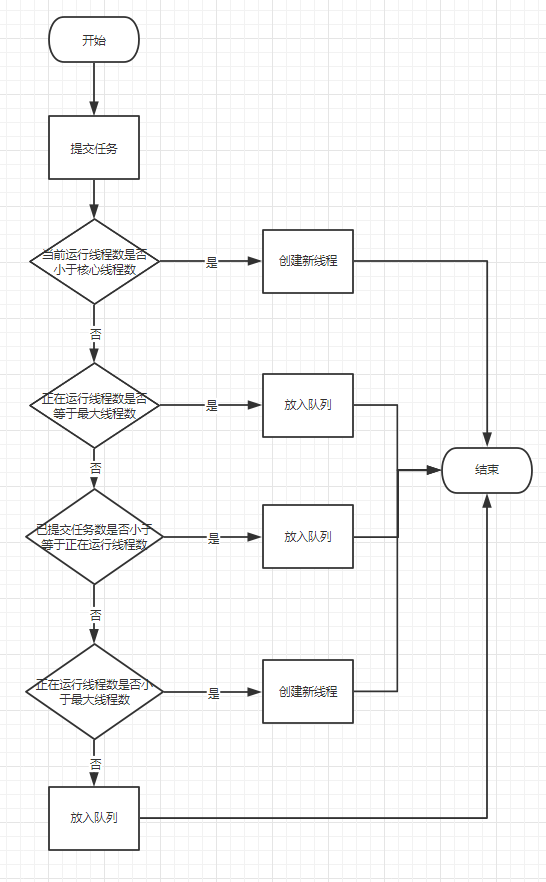
其技術細節就是自己重寫了佇列的 offer 方法。在這篇文章裡面說的很清楚了,大家可以看看:
《每天都在用,但你知道 Tomcat 的執行緒池有多努力嗎?》
好的,前面兩個知識點鋪墊完成了。

這個題,從執行緒池設計的角度,我會這樣去回答:
前面我們說了,10 個機器,1000 個請求併發,平均每個服務承擔 100 個請求。伺服器是 4 核的配置。
那麼如果是 CPU 密集型的任務,我們應該儘量的減少上下文切換,所以核心執行緒數可以設定為 5,佇列的長度可以設定為 100,最大執行緒數保持和核心執行緒數一致。
如果是 IO 密集型的任務,我們可以適當的多分配一點核心執行緒數,更好的利用 CPU,所以核心執行緒數可以設定為 8,佇列長度還是 100,最大執行緒池設定為 10。
當然,上面都是理論上的值。
我們也可以從核心執行緒數等於 5 開始進行系統壓測,通過壓測結果的對比,從而確定最合適的設定。
同時,我覺得執行緒池的引數應該是隨著系統流量的變化而變化的。
所以,對於核心服務中的執行緒池,我們應該是通過執行緒池監控,做到提前預警。同時可以通過手段對執行緒池響應引數,比如核心執行緒數、佇列長度進行動態修改。
上面的回答總結起來就是四點:
CPU密集型的情況。 IO密集型的情況。 通過壓測得到合理的引數配置。 執行緒池動態調整。
前兩個是教科書上的回答,記下來就行,面試官想聽到這兩個答案。
後兩個是更具有實際意義的回答,讓面試官眼前一亮。
基於這道面試題有限的資訊,設計出來的執行緒池佇列長度其實只要大於 100 就可以。
甚至還可以設定的極限一點,比如核心執行緒數和最大執行緒數都是 4,佇列長度為 96,剛好可以承擔這 100 個請求,多一個都不行了。
所以這題我覺得從這個角度來說,並不是要讓你給出一個完美的解決方案,而是考察你對於執行緒池引數的理解和技術的運用。
面試的時候我覺得這個題答到這裡就差不多了。
接下來,我們再發散一下。
比如面試官問:如果我們的系統裡面沒有運用執行緒池,那麼會是怎麼樣的呢?
首先假設我們開發的系統是一個執行在 Tomcat 容器裡面的,對外提供 http 介面的 web 服務。
系統中沒有運用執行緒池相關技術。那麼我們可以直接抗住這 100 個併發請求嗎?
答案是可以的。
Tomcat 裡面有一個執行緒池。其 maxThreads 預設值是 200(假定 BIO 模式):

maxThreads 用完了之後,進佇列。佇列長度(acceptCount)預設是 100:

在 BIO 的模式下,Tomcat 的預設配置,最多可以接受到 300 (200+100)個請求。再多就是連線拒絕,connection refused。
所以,你要說處理這 100 個併發請求,那不是綽綽有餘嗎?
但是,如果是每秒 100 個併發請求,源源不斷的過來,那就肯定是吃不消了。
這裡就涉及到兩個層面的修改:
Tomcat 引數配置的調優。 系統程式碼的優化。
針對 Tomcat 引數配置的調優,我們可以適當調大其 maxThreads 等引數的值。
針對系統程式碼的優化,我們就可以引入執行緒池技術,或者引入訊息佇列。總之其目的是增加系統吞吐量。
同理,假設我們是一個 Dubbo 服務,對外提供的是 RPC 介面。
預設情況下,服務端使用的是 fixed 執行緒池,核心執行緒池數和最大執行緒數都是 200。佇列長度預設為 0:
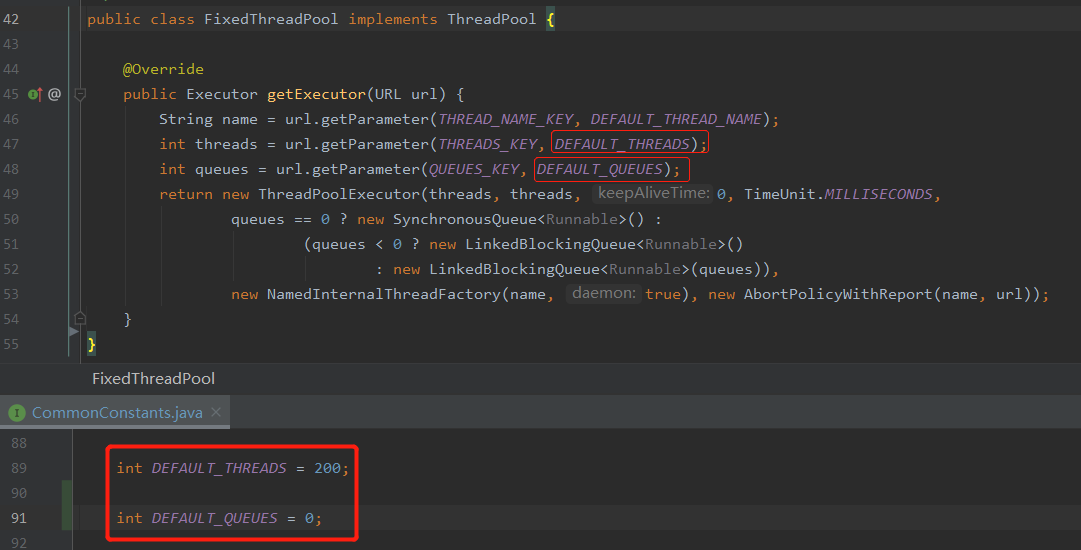
那麼處理這個 100 個併發請求也是綽綽有餘的。
同樣,如果是每秒 100 個併發請求源源不斷的過來,那麼很快就會丟擲執行緒池滿的異常:
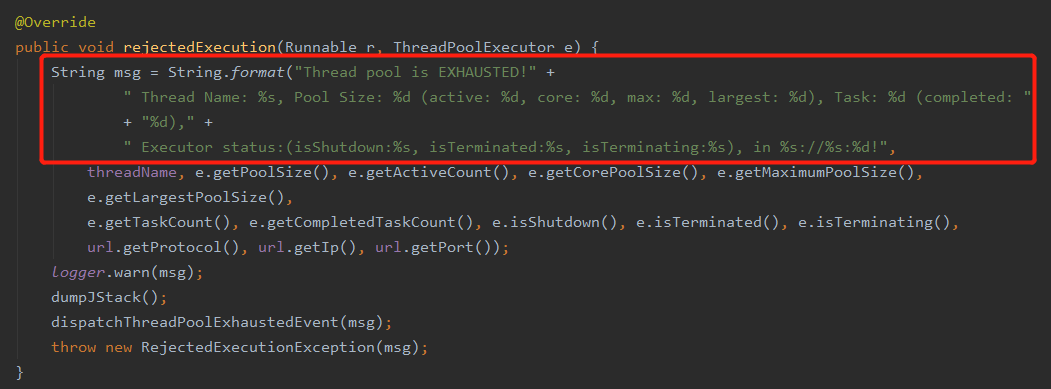
解決套路其實是和 Tomcat 的情況差不多的,調引數,改系統,加非同步。
這個情況下的併發,大多數系統還是抗住的。
面試官還可以接著追問:如果這時由於搞促銷活動,系統流量翻了好倍,那你說這種情況下最先出現效能瓶頸的地方是什麼?
最先出問題的地方肯定是資料庫嘛,對吧。
那麼怎麼辦?
分散壓力。分庫分表、讀寫分離這些東西往上套就完事了。
然後在系統入口的地方削峰填谷,引入快取,如果可以,把絕大部分流量攔截在入口處。
對於攔不住的大批流量,關鍵服務節點還需要支援服務熔斷、服務降級。
實在不行,加錢,堆機器。沒有問題是不能通過堆機器解決的,如果有,那麼就是你堆的機器不夠多。

面試反正也就是這樣的套路。看似一個發散性的題目,其實都是有套路可尋的。
好了,第一個角度我覺得我能想到的就是這麼多了。
首先正面回答了面試官執行緒池設計的問題。
然後分情況聊了一下如果我們專案中沒有用執行緒池,能不能直接抗住這 1000 的併發。
最後簡單講了一下突發流量的情況。
接下來,我們聊聊負載均衡。
負載均衡策略
我覺得這個考點雖然稍微隱藏了一下,但還是很容易就挖掘到的。
畢竟題目中已經說了:10 臺機器。
而且我們也假設了平均 1 臺處理 100 個情況。
這個假設的背後其實就是一個負載均衡策略:輪詢負載均衡。
如果負載均衡策略不是輪詢的話,那麼我們前面的執行緒池佇列長度設計也是有可能不成立的。
還是前面的場景,如果我們是執行在 Tomcat 容器中,假設前面是 nginx,那麼 nginx 的負載均衡策略有如下幾種:
(加權)輪詢負載均衡 隨機負載均衡 最少連線數負載均衡 最小響應時間負載均衡 ip_hash負載均衡 url_hash負載均衡
如果是 RPC 服務,以 Dubbo 為例,有下面幾種負載均衡策略:
(加權)輪詢負載均衡 隨機負載均衡 最少活躍數負載均衡 最小響應時間負載均衡 一致性雜湊負載均衡
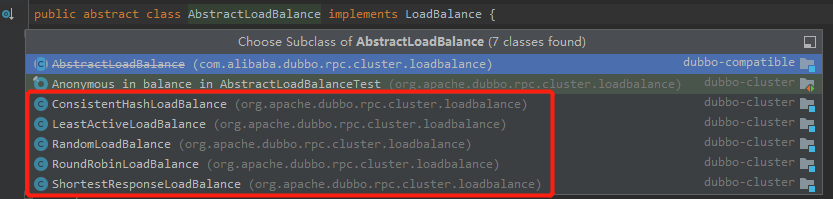
哦,對了。記得之前還有一個小夥伴問我,在 Dubbo + zookeeper 的場景下,負載均衡是 Dubbo 做的還是 zk 做的?
肯定是 Dubbo 啊,朋友。原始碼都寫在 Dubbo 裡面的,zk 只是一個註冊中心,關心的是自己管理著幾個服務,和這幾個服務的上下線。
你要用的時候,我把所有能用的都給你,至於你到底要用那個服務,也就是所謂的負載均衡策略,這不是 zk 關心的事情。
不扯遠了,說回來。
假設我們用的是隨機負載均衡,我們就不能保證每臺機器各自承擔 100 個請求了。
這時候我們前面給出的執行緒池設定就是不合理的。
常見的負載均衡策略對應的優缺點、適用場景可以看這個表格:
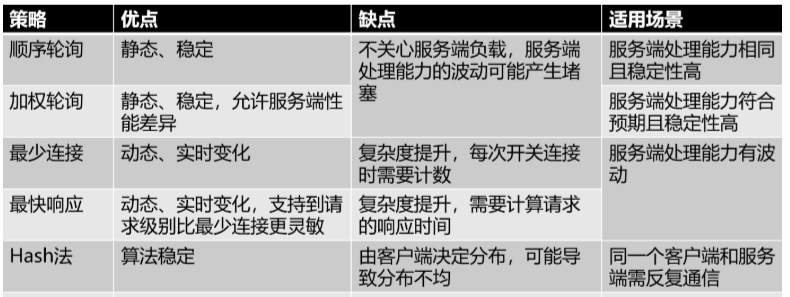
關於負載均衡策略,我的《吐血輸出:2萬字長文帶你細細盤點五種負載均衡策略》這篇文章,寫了 2 萬多字,算是寫的很清楚了,這裡就不贅述了。
說起負載均衡,我還想起了之前阿里舉辦的一個程式設計大賽。賽題是《自適應負載均衡的設計實現》。
賽題的背景是這樣的:
負載均衡是大規模計算機系統中的一個基礎問題。靈活的負載均衡演算法可以將請求合理地分配到負載較少的伺服器上。
理想狀態下,一個負載均衡演算法應該能夠最小化服務響應時間(RTT),使系統吞吐量最高,保持高效能服務能力。
自適應負載均衡是指無論處在空閒、穩定還是繁忙狀態,負載均衡演算法都會自動評估系統的服務能力,更好的進行流量分配,使整個系統始終保持較好的效能,不產生飢餓或者過載、宕機。
具體題目和獲獎團隊答辯可以看這裡:
題目:https://tianchi.aliyun.com/competition/entrance/231714/information?spm=a2c22.12849246.1359729.1.6b0d372cO8oYGK
答辯:https://tianchi.aliyun.com/course/video?spm=5176.12586971.1001.1.32de8188ivjLZj&liveId=41090
推薦大家有興趣的去看一下,還是很有意思的,可以學到很多的東西。
擴充套件閱讀
這一小節,我擷取自《分散式系統架構》這本書裡面,我覺得這個示例寫的還不錯,分享給大家:
這是一個購物商場的例子:
系統部署在一臺 4C/8G 的應用伺服器上、資料在一臺 8C/16G 的資料庫上,都是虛擬機器。
假設系統總使用者量是 20 萬,日均活躍使用者根據不同系統場景稍有區別,此處取 20%,就是 4 萬。
按照系統劃分二八法則,系統每天高峰算 4 小時,高峰期活躍使用者佔比 80%,高峰 4 小時內有 3.2 萬活躍使用者。
每個使用者對系統傳送請求,如每個使用者傳送 30 次,高峰期間 3.2 萬用戶發起的請求是 96 萬次,QPS=960 000/(4x60x60)≈67 次請求,每秒處理 67 次請求,處理流程如下圖有所示:
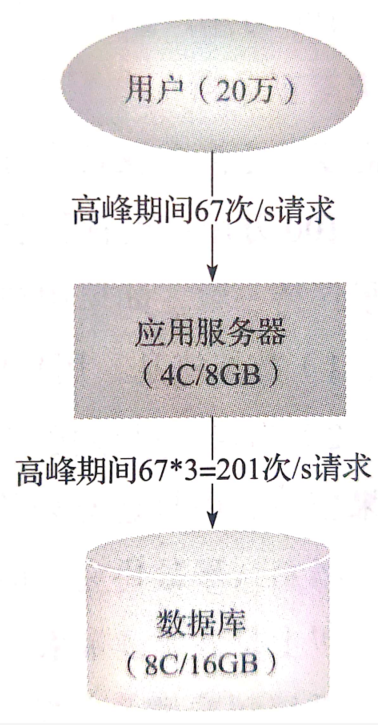
一次應用操作資料庫增刪改查(CRUD)次數平均是操作應用的三倍,具體頻率根據系統的操作算平均值即可。一臺應用、資料庫能處理多少請求呢?
具體分析如下。
首先應用、資料庫都分別部署在伺服器,所以和伺服器的效能有直接關係,如 CPU、記憶體、磁碟儲存等。
應用需要部署在容器裡面,如 Tomcat、Jetty、JBoss 等,所以和容器有關係,容器的系統引數、配置能增加或減少處理請求的數目。
Tomcat 部署應用。Tomcat 裡面需要分配記憶體,伺服器共 8GB 記憶體,伺服器主要用來部署應用,無其他用途,所以設計 Tomcat 的可用記憶體為8/2=4GB (實體記憶體的1/2),同時設定一個執行緒需要 128KB 的記憶體。由於應用伺服器預設的最大執行緒數是 1000(可以參考系統配置檔案),考慮到系統自身處理能力,調整 Tomcat 的預設執行緒數至 600,達到系統的最大處理執行緒能力。到此一臺應用最大可以處理 1000 次請求,當超過 1000 次請求時,暫存到佇列中,等待執行緒完成後進行處理。
資料庫用 MySQL。MySQL 中有連線數這個概念,預設是 100 個,1 個請求連線一次資料庫就佔用 1 個連線,如果 100 個請求同時連線資料庫,資料庫的連線數將被佔滿,後續的連線需要等待,等待之前的連線釋放掉。根據資料庫的配置及效能,可適當調整預設的連線數,本次調整到 500,即可以處理 500 次請求。
顯然當前的使用者數以及請求量達不到高併發的條件,如果活躍使用者從 3.2 萬擴大到 32 萬,每秒處理 670 次請求,已經超過預設最大的 600 ,此時會出現高併發的情況,高併發分為高併發讀操作和高併發寫操作。
好了,書上分享的案例就是這樣的。
最後說一句(求關注)
好了,看到了這裡安排個 “一鍵三連”吧,周更很累的,不要白嫖我,需要一點正反饋。
才疏學淺,難免會有紕漏,如果你發現了錯誤的地方,可以在留言區提出來,我對其加以修改。 感謝您的閱讀,我堅持原創,十分歡迎並感謝您的關注。
我是 why,一個被程式碼耽誤的文學創作者,不是大佬,但是喜歡分享,是一個又暖又有料的四川好男人。
還有,歡迎關注我呀。
