
從Linux原始碼看TIME_WAIT狀態的持續時間
阿新 • • 發佈:2020-10-27
# 從Linux原始碼看TIME_WAIT狀態的持續時間
## 前言
筆者一直以為在Linux下TIME\_WAIT狀態的Socket持續狀態是60s左右。線上實際卻存在TIME\_WAIT超過100s的Socket。由於這牽涉到最近出現的一個複雜Bug的分析。所以,筆者就去Linux原始碼裡面,一探究竟。
## 首先介紹下Linux環境
TIME\_WAIT這個引數通常和五元組重用扯上關係。在這裡,筆者先給出機器的核心引數設定,以免和其它問題相混淆。
```
cat /proc/sys/net/ipv4/tcp_tw_reuse 0
cat /proc/sys/net/ipv4/tcp_tw_recycle 0
cat /proc/sys/net/ipv4/tcp_timestamps 1
```
可以看到,我們設定了tcp\_tw\_recycle為0,這可以避免NAT下tcp\_tw\_recycle和tcp\_timestamps同時開啟導致的問題。具體問題可以看筆者的以往部落格。
```
https://my.oschina.net/alchemystar/blog/3119992
```
## TIME\_WAIT狀態轉移圖
提到Socket的TIME\_WAIT狀態,不得就不亮出TCP狀態轉移圖了:
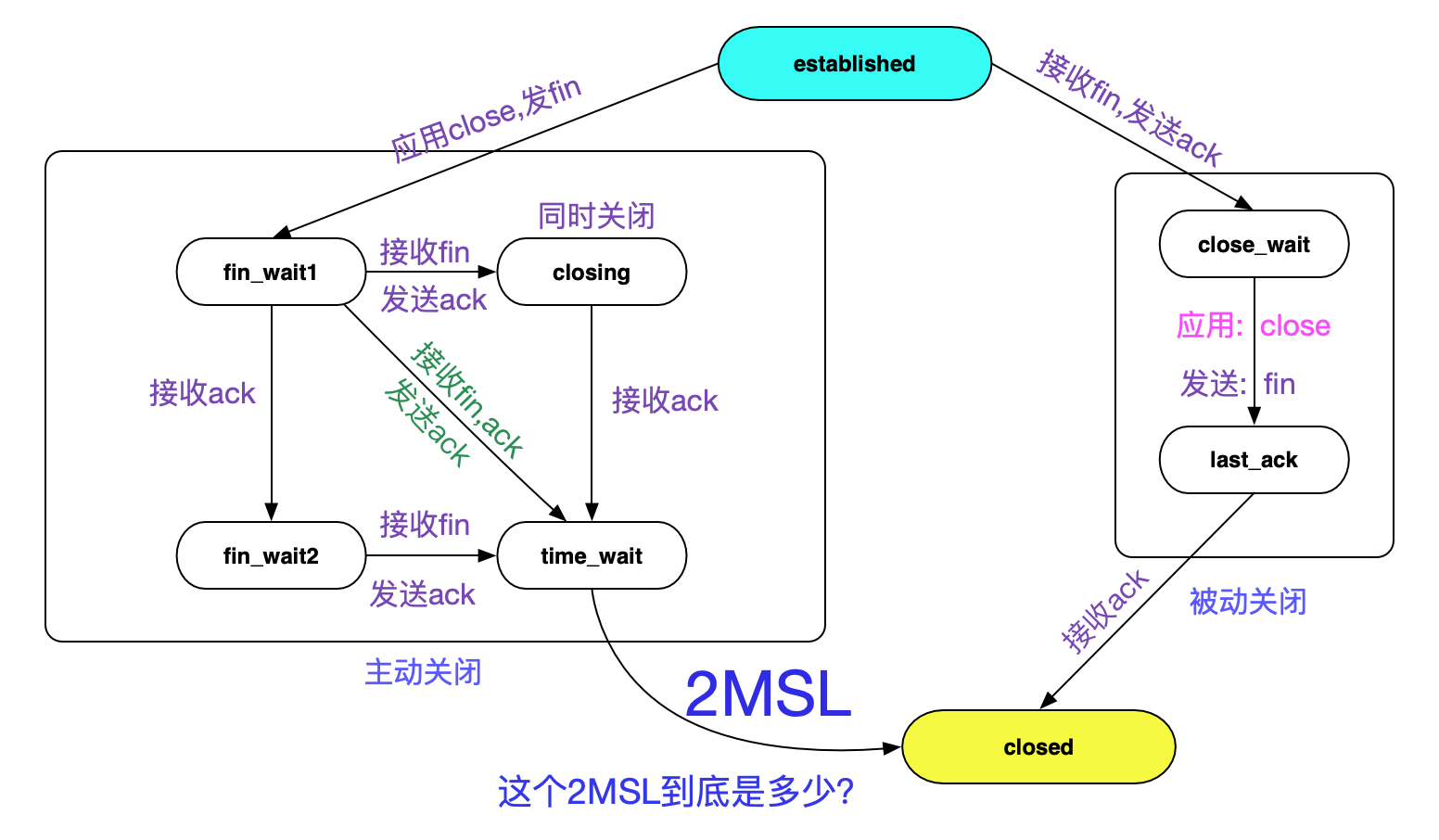
持續時間就如圖中所示的2MSL。但圖中並沒有指出2MSL到底是多長時間,但筆者從Linux原始碼裡面翻到了下面這個巨集定義。
```
#define TCP_TIMEWAIT_LEN (60*HZ) /* how long to wait to destroy TIME-WAIT
* state, about 60 seconds */
```
如英文字面意思所示,60s後銷燬TIME\_WAIT狀態,那麼2MSL肯定就是60s嘍?
## 持續時間真如TCP\_TIMEWAIT\_LEN所定義麼?
筆者之前一直是相信60秒TIME\_WAIT狀態的socket就能夠被Kernel回收的。甚至筆者自己做實驗telnet一個埠號,人為製造TIME\_WAIT,自己計時,也是60s左右即可回收。
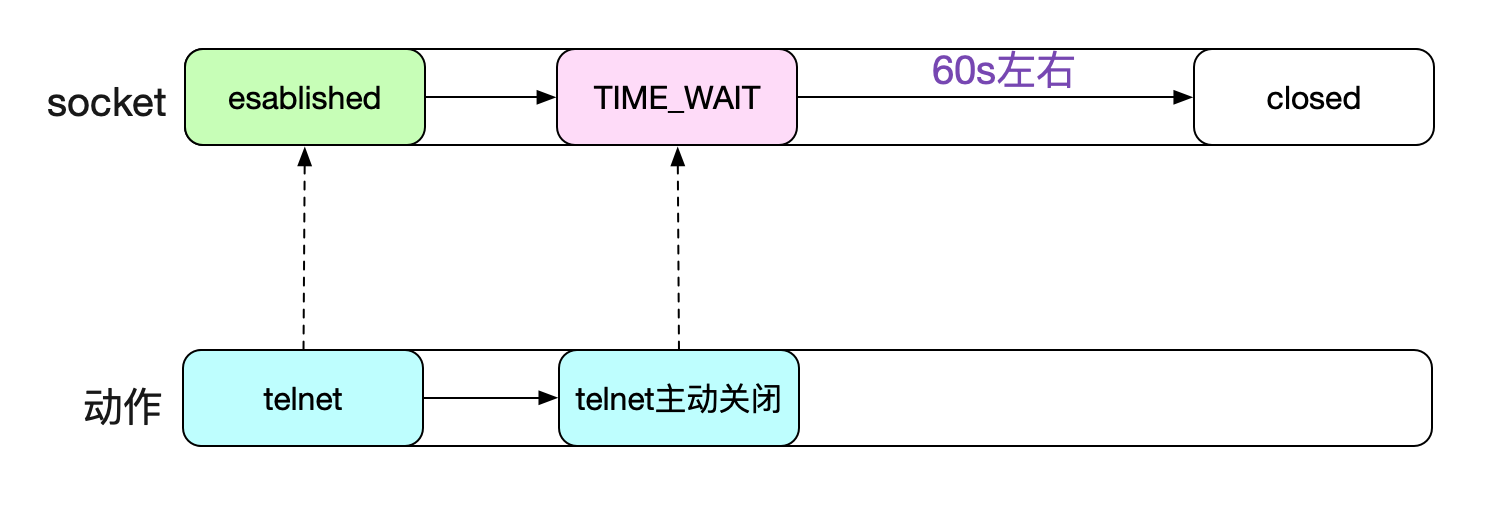
但在追查一個問題時候,發現,TIME\_WAIT有時候能夠持續到111s,不然完全無法解釋問題的現象。這就逼得筆者不得不推翻自己的結論,重新細細閱讀核心對於TIME\_WAIT狀態處理的原始碼。當然,這個追查的問題也會寫成部落格分享出來,敬請期待^_^。
## TIME\_WAIT定時器原始碼
談到TIME\_WAIT何時能夠被回收,不得不談到TIME\_WAIT定時器,這個就是專門用來銷燬到期的TIME\_WAIT Socket的。而每一個Socket進入TIME\_WAIT時,必然會經過下面的程式碼分支:
```
tcp_v4_rcv
|->tcp_timewait_state_process
/* 將time_wait狀態的socket鏈入時間輪
|->inet_twsk_schedule
```
由於我們的kernel並沒有開啟tcp\_tw\_recycle,所以最終的呼叫為:
```
/* 這邊TCP_TIMEWAIT_LEN 60 * HZ */
inet_twsk_schedule(tw, &tcp_death_row, TCP_TIMEWAIT_LEN,
TCP_TIMEWAIT_LEN);
```
好了,讓我們按下這個核心函式吧。
## inet\_twsk\_schedule
在閱讀原始碼前,先看下大致的處理流程。Linux核心是通過時間輪來處理到期的TIME\_WAIT socket,如下圖所示:
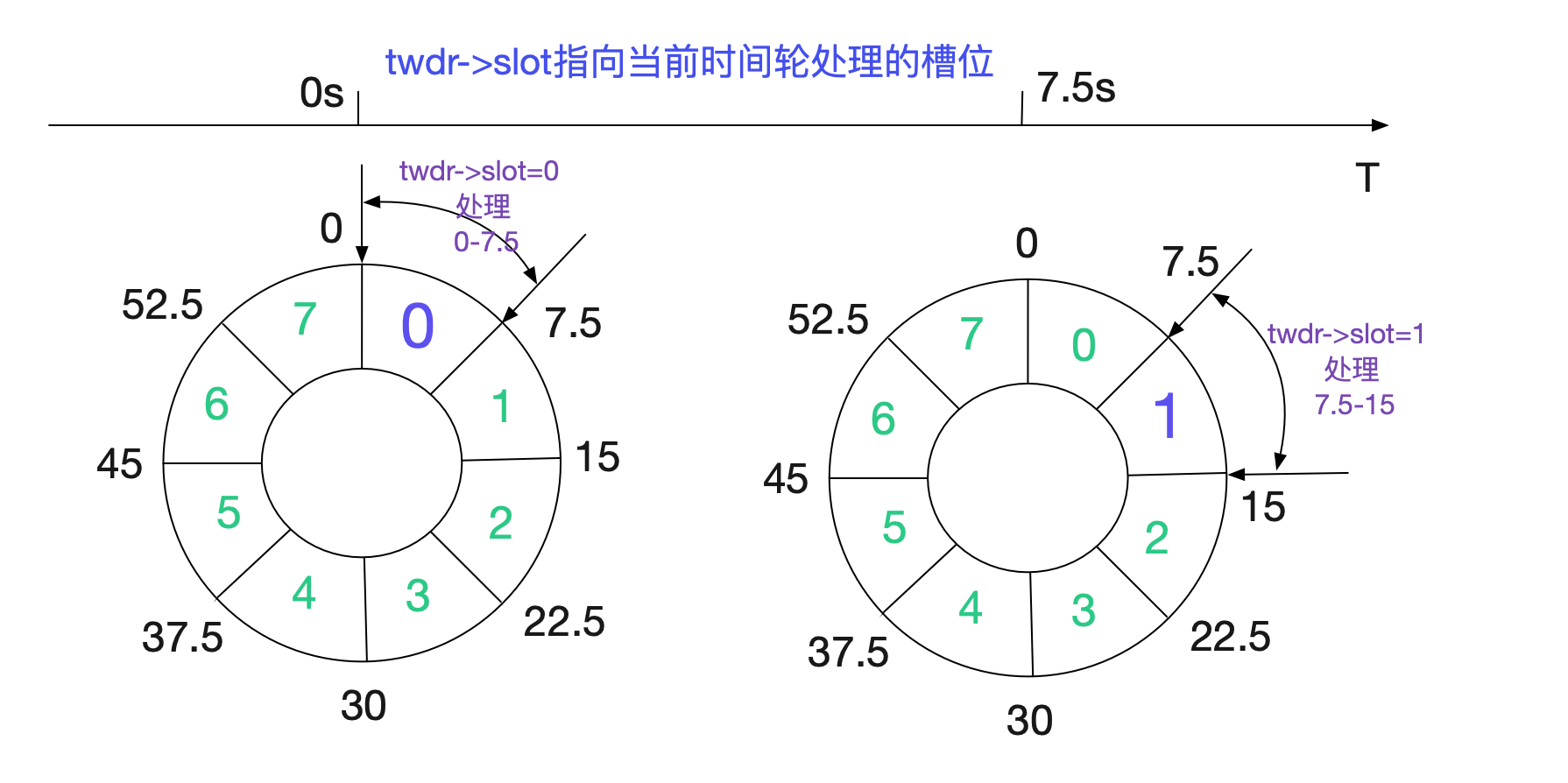
核心將60s的時間分為8個slot(INET\_TWDR\_RECYCLE\_SLOTS),每個slot處理7.5(60/8)範圍time\_wait狀態的socket。
```
void inet_twsk_schedule(struct inet_timewait_sock *tw,struct inet_timewait_death_row *twdr,const int timeo, const int timewait_len)
{
......
// 計算時間輪的slot
slot = (timeo + (1 << INET_TWDR_RECYCLE_TICK) - 1) >> INET_TWDR_RECYCLE_TICK;
......
// 慢時間輪的邏輯,由於沒有開啟TCP\_TW\_RECYCLE,timeo總是60*HZ(60s)
// 所有都走slow_timer邏輯
if (slot >= INET_TWDR_RECYCLE_SLOTS) {
/* Schedule to slow timer */
if (timeo >= timewait_len) {
slot = INET_TWDR_TWKILL_SLOTS - 1;
} else {
slot = DIV_ROUND_UP(timeo, twdr->period);
if (slot >= INET_TWDR_TWKILL_SLOTS)
slot = INET_TWDR_TWKILL_SLOTS - 1;
}
tw->tw_ttd = jiffies + timeo;
// twdr->slot當前正在處理的slot
// 在TIME_WAIT_LEN下,這個邏輯一般7
slot = (twdr->slot + slot) & (INET_TWDR_TWKILL_SLOTS - 1);
list = &twdr->cells[slot];
} else{
// 走短時間定時器,由於篇幅原因,不在這裡贅述
......
}
......
/* twdr->period 60/8=7.5 */
if (twdr->tw_count++ == 0)
mod_timer(&twdr->tw_timer, jiffies + twdr->period);
spin_unlock(&twdr->death_lock);
}
```
從原始碼中可以看到,由於我們傳入的timeout皆為TCP\_TIMEWAIT\_LEN。所以,每次剛成為的TIME\_WAIT狀態的socket即將連結到當前處理slot最遠的slot(+7)以便處理。如下圖所示:
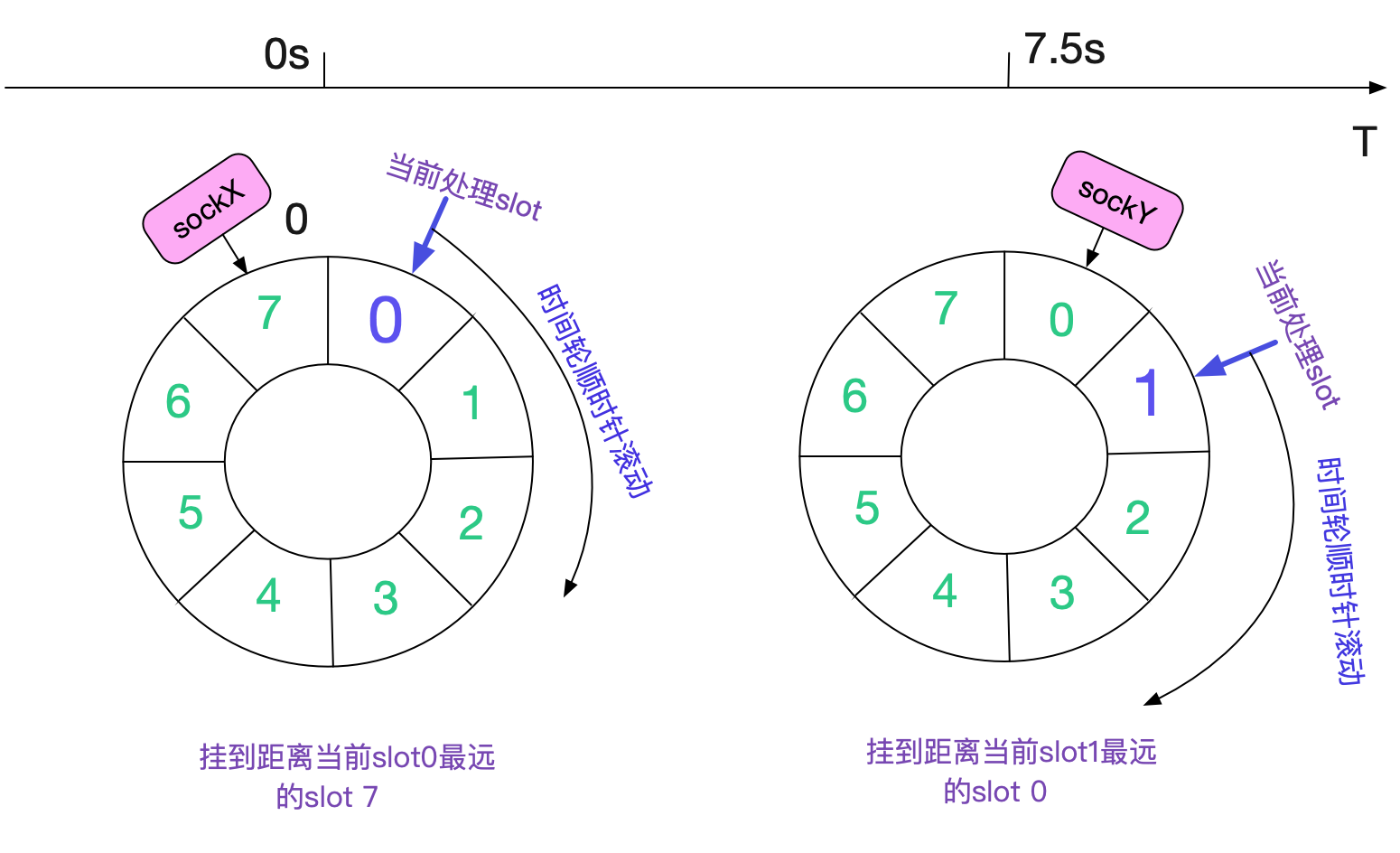
如果Kernel不停的產生TIME\_WAIT,那麼整個slow timer時間輪就會如下圖所示:
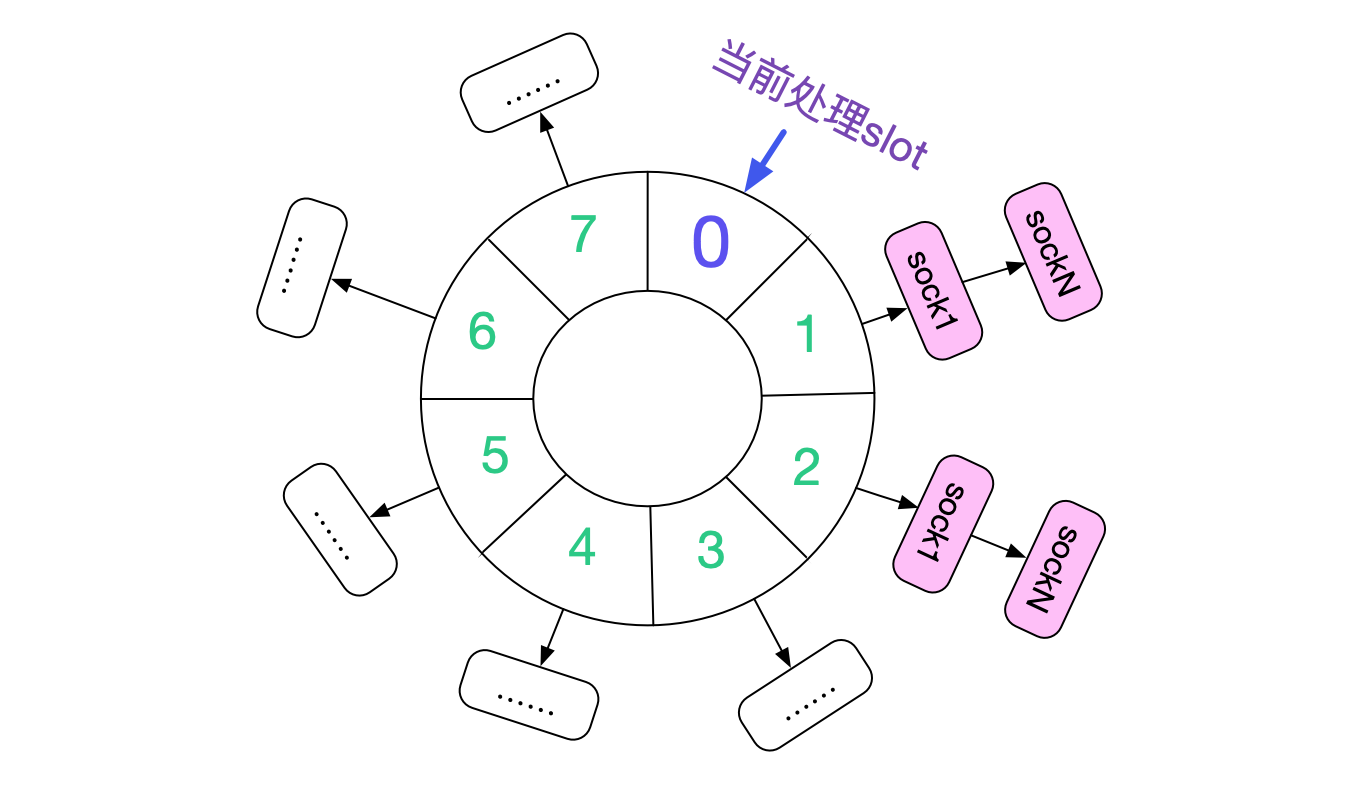
所有的slot全部掛滿了TIME\_WAIT狀態的Socket。
## 具體的清理函式
每次呼叫inet\_twsk\_schedule時候傳入的處理函式都是:
```
/*引數中的tcp_death_row即為承載時間輪處理函式的結構體*/
inet_twsk_schedule(tw,&tcp_death_row,TCP_TIMEWAIT_LEN,TCP_TIMEWAIT_LEN)
/* 具體的處理結構體 */
struct inet_timewait_death_row tcp_death_row = {
......
/* slow_timer時間輪處理函式 */
.tw_timer = TIMER_INITIALIZER(inet_twdr_hangman, 0,
(unsigned long)&tcp_death_row),
/* slow_timer時間輪輔助處理函式*/
.twkill_work = __WORK_INITIALIZER(tcp_death_row.twkill_work,
inet_twdr_twkill_work),
/* 短時間輪處理函式 */
.twcal_timer = TIMER_INITIALIZER(inet_twdr_twcal_tick, 0,
(unsigned long)&tcp_death_row),
};
```
由於我們這邊主要考慮的是設定為TCP\_TIMEWAIT\_LEN(60s)的處理時間,所以直接考察slow\_timer時間輪處理函式,也就是inet\_twdr\_hangman。這個函式還是比較簡短的:
```
void inet_twdr_hangman(unsigned long data)
{
struct inet_timewait_death_row *twdr;
unsigned int need_timer;
twdr = (struct inet_timewait_death_row *)data;
spin_lock(&twdr->death_lock);
if (twdr->tw_count == 0)
goto out;
need_timer = 0;
// 如果此slot處理的time_wait socket已經達到了100個,且還沒處理完
if (inet_twdr_do_twkill_work(twdr, twdr->slot)) {
twdr->thread_slots |= (1 << twdr->slot);
// 將餘下的任務交給work queue處理
schedule_work(&twdr->twkill_work);
need_timer = 1;
} else {
/* We purged the entire slot, anything left? */
// 判斷是否還需要繼續處理
if (twdr->tw_count)
need_timer = 1;
// 如果當前slot處理完了,才跳轉到下一個slot
twdr->slot = ((twdr->slot + 1) & (INET_TWDR_TWKILL_SLOTS - 1));
}
// 如果還需要繼續處理,則在7.5s後再執行此函式
if (need_timer)
mod_timer(&twdr->tw_timer, jiffies + twdr->period);
out:
spin_unlock(&twdr->death_lock);
}
```
雖然簡單,但這個函式裡面有不少細節。第一個細節,就在inet\_twdr\_do\_twkill\_work,為了防止這個slot的time\_wait過多,卡住當前的流程,其會在處理完100個time\_wait socket之後就回返回。這個slot餘下的time\_wait會交給Kernel的work\_queue機制去處理。
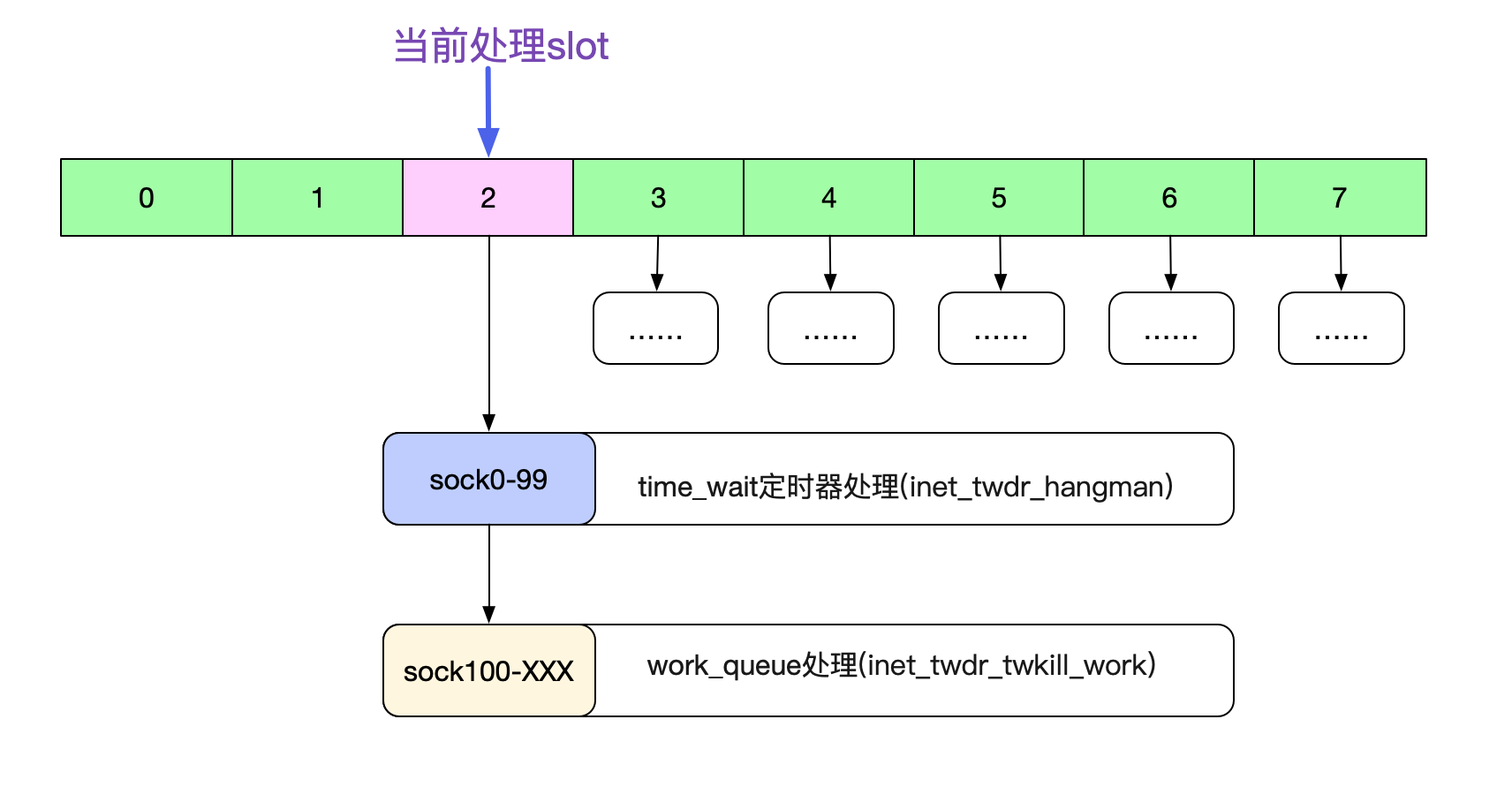
值得注意的是。由於在這個slow\_timer時間輪判斷裡面,根本不判斷精確時間,直接全部刪除。所以輪到某個slot,例如到了52.5-60s這個slot,直接清理52.5-60s的所有time\_wait。即使time\_wait還沒有到60s也是如此。而小時間輪(tw\_cal)會精確的判定時間,由於篇幅原因,就不在這裡細講了。
```
注: 小時間輪(tw\_cal)在tcp\_tw\_recycle開啟的情況下會使用
```
## 先作出一個假設
我們假設,一個時間輪的資料最多能在一個slot間隔時間,也就是(60/8=7.5)內肯定能處理完畢。由於系統有tcp\_tw\_max\_buckets設定,如果設定的比較合理,這個假設還是比較靠譜的。
```
注: 這裡的60/8為什麼需要精確到小數,而不是7。
因為實際計算的時候是拿60*HZ進行計算,
如果HZ是1024的話,那麼period應該是7680,即精度精確到ms級。
所以在本文中計算的時候需要精確到小數。
```
## 如果一個slot中的TIME\_WAIT<=100
如果一個slot的TIME\_WAIT<=100,很自然的,我們的處理函式並不會啟用work\_queue。同時,還將slot+1,使得在下一個period的時候可以處理下一個slot。如下圖所示:

## 如果一個slot中的TIME\_WAIT>100
如果一個slot的TIME\_WAIT>100,Kernel會將餘下的任務交給work\_queue處理。同時,slot不變!也即是說,下一個period(7.5s後)到達的時候,還會處理同樣的slot。按照我們的假設,這時候slot已經處理完畢,那麼在第7.5s的時候才將slot向前推進。也就是說,假設slot一開始為0,到真正處理slot 1需要15s!

假設每一個slot的TIME\_WAIT都>100的話,那麼每個slot的處理都需要15s。
對於這種情況,筆者寫了個程式進行模擬。
```
public class TimeWaitSimulator {
public static void main(String[] args) {
double delta = (60) * 1.0 / 8;
// 0表示開始清理,1表示清理完畢
// 清理完畢之後slot向前推進
int startPurge = 0;
double sum = 0;
int slot = 0;
while (slot < 8) {
if (startPurge == 0) {
sum += delta;
startPurge = 1;
if (slot == 7) {
// 因為假設進入work_queue之後,很快就會清理完
// 所以在slot為7的時候並不需要等最後的那個purge過程7.5s
System.out.println("slot " + slot + " has reach the last " + sum);
break;
}
}
if (startPurge == 1) {
sum += delta;
startPurge = 0;
System.out.println("slot " + "move to next at time " + sum);
// 清理完之後,slot才應該向前推進
slot++;
}
}
}
}
```
得出結果如下面所示:
```
slot move to next at time 15.0
slot move to next at time 30.0
slot move to next at time 45.0
slot move to next at time 60.0
slot move to next at time 75.0
slot move to next at time 90.0
slot move to next at time 105.0
slot 7 has reach the last 112.5
```
也即處理到52.5-60s這個時間輪的時候,其實外面時間已經過去了112.5s,處理已經完全滯後了。不過由於TIME\_WAIT狀態下的Socket(inet\_timewait\_sock)所佔用記憶體很少,所以不會對系統可用資源造成太大的影響。但是,這會在NAT環境下造成一個坑,這也是筆者文章前面提到過的Bug。
上面的計算如果按照圖和時間線畫出來,應該是這麼個情況:
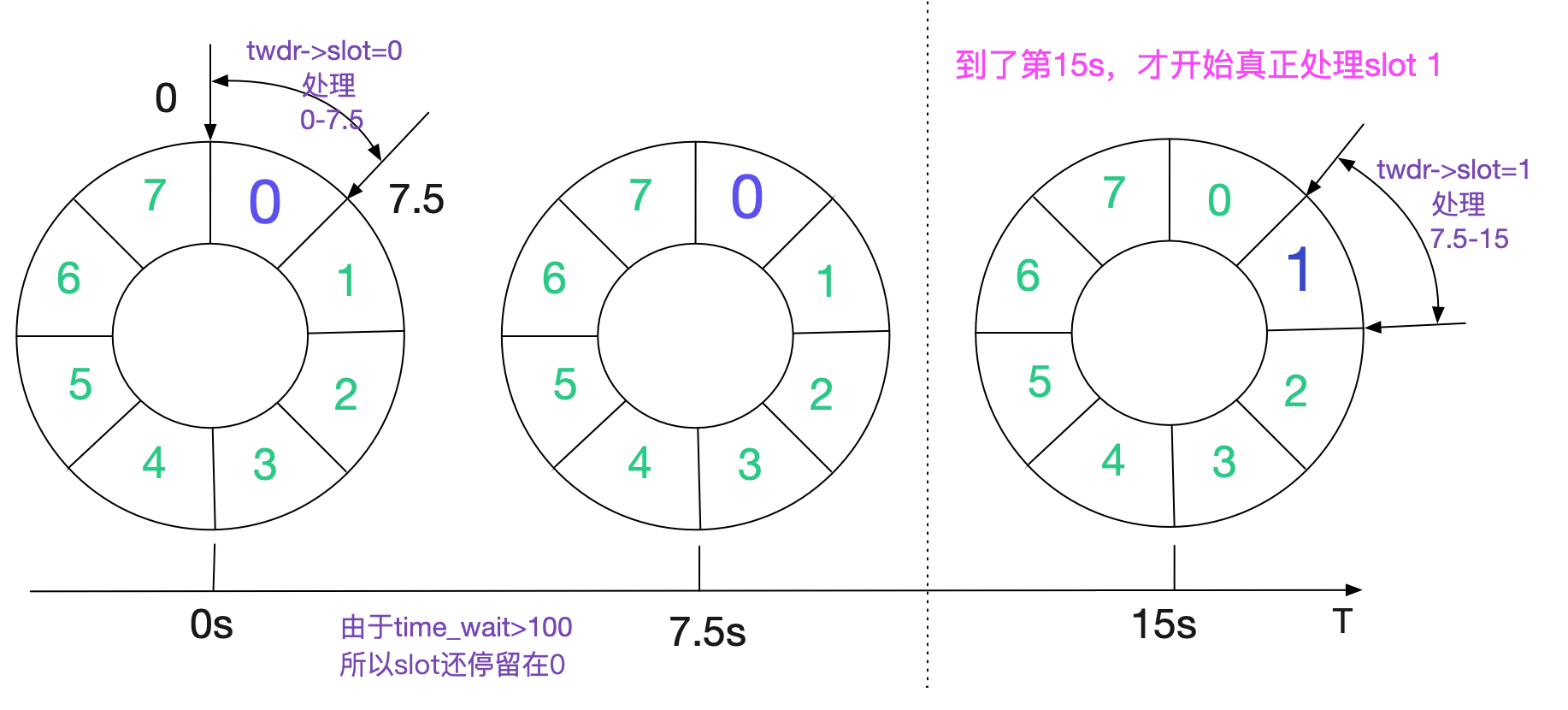
也即TIME\_WAIT狀態的Socket在一個period(7.5s)內能處理完當前slot的情況下,最多能夠存在112.5s!
如果7.5s內還處理不完,那麼響應時間輪的輪轉還得繼續加上一個或多個perod。但在tcp\_tw\_max\_buckets的限制,應該無法達到這麼嚴苛的條件。
## PAWS(Protection Against Wrapped Sequences)使得TIME\_WAIT延長
事實上,以上結論還是不夠嚴謹。TIME\_WAIT時間還可以繼續延長!看下這段原始碼:
```
enum tcp_tw_status
tcp_timewait_state_process(struct inet_timewait_sock *tw, struct sk_buff *skb,
const struct tcphdr *th)
{
......
if (paws_reject)
NET_INC_STATS_BH(twsk_net(tw), LINUX_MIB_PAWSESTABREJECTED);
if (!th->rst) {
/* In this case we must reset the TIMEWAIT timer.
*
* If it is ACKless SYN it may be both old duplicate
* and new good SYN with random sequence number