
想要做讀寫分離,送你一些小經驗
阿新 • • 發佈:2020-10-27
讀寫分離是應用中提升資料訪問效能最常見的一種技術,當用戶量越來越多,訪問量越來越大,單節點資料庫難免會遇到效能瓶頸。很多場景基本上都是讀多寫少,所以增加多個從節點來分擔主節點的壓力自然是水到渠成的事情。
在應用接入讀寫分離後,難免會有一些我們意料之外的問題,這篇文章主要給大家介紹下一些經常會遇到的問題,有其他的問題歡迎留言補充。
分庫分表之前的文章可以檢視:[http://mp.weixin.qq.com/mp/homepage?\_\_biz=MzIwMDY0Nzk2Mw==&hid=4&sn=1b96093ec951a5f997bdd3225e5f2fdf&scene=18#wechat_redirect](http://mp.weixin.qq.com/mp/homepage?__biz=MzIwMDY0Nzk2Mw==&hid=4&sn=1b96093ec951a5f997bdd3225e5f2fdf&scene=18#wechat_redirect)
## 實現方式
對於讀寫分離的使用,主要分為兩種方式,客戶端方式和代理方式。
客戶端方式可以自己用 Spring 自帶的 AbstractRoutingDataSource 來實現,也可以用開源的框架來實現,比如 Sharding-JDBC。

代理方式需要編寫代理服務來對所有節點進行管理,應用不需要關注多個數據庫節點資訊。可以自己實現,也可以用開源的框架,也可以用商業的雲服務。

## 資料延遲
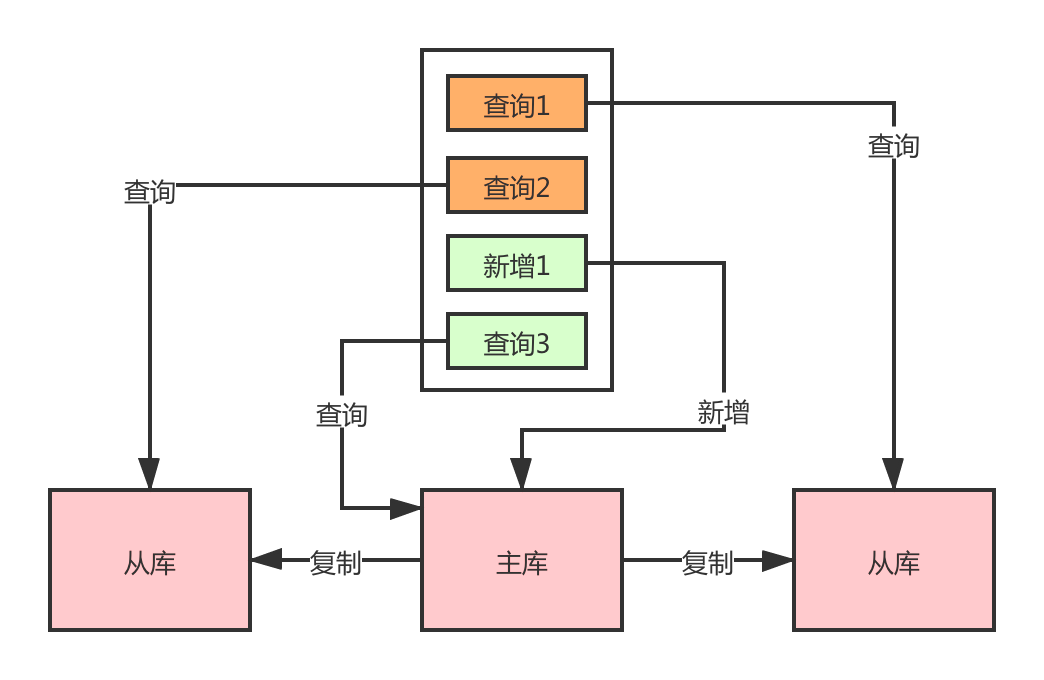
談到資料延遲,你先得理解主從架構的原理。對資料的增刪改操作在主庫上執行,查詢在從庫上執行,當資料剛插入到主庫,然後馬上去查詢的時候,很有可能資料還沒同步到從庫上,就會出現查詢不到的情況。
像我之前在某些網站發表文章,發表之後跳轉到列表頁面,發現沒有新發表的文章,重新重新整理下頁面又有了,這一看這就是讀寫分離後的資料延遲導致的現象。
### 強制路由
資料延遲要不要解決,一般取決於業務場景。對於實時性要求沒有那麼高的業務場景,允許一定的延遲,對於實時性要求高的場景,唯一的方式就是直接從主庫進行查詢,這樣才能及時讀到剛插入或者修改後最新的資料。
強制路由就是一種解決方案,也就是將讀請求強制分發到主庫進行查詢。大部分中介軟體都支援 Hint 語法/_FORCE_MASTER_/和/_FORCE_SLAVE_/。
以 Sharding-JDBC 舉例,框架提供了 HintManager 來強制路由,使用方式如下:
```plain
HintManager hintManager = HintManager.getInstance();
hintManager.setMasterRouteOnly();
```
為了方便使用,建議封裝一個註解,在需要實時查詢的業務方法上加上註解,通過切面進行強制路由的設定。
註解使用:
```plain
@MasterRoute
@Override
public UserBO getUser(Long id) {
log.info("查詢使用者 [{}]", id);
if (id == null) {
throw new BizException(ResponseCode.PARAM_ERROR_CODE, "id不能為空");
}
UserDO userDO = userDao.getById(id);
if (userDO == null) {
throw new BizException(ResponseCode.NOT_FOUND_CODE);
}
return userBoConvert.convert(userDO);
}
```
切面設定:
```plain
@Aspect
public class MasterRouteAspect {
@Around("@annotation(masterRoute)")
public Object aroundGetConnection(final ProceedingJoinPoint pjp, MasterRoute masterRoute) throws Throwable {
HintManager hintManager = HintManager.getInstance();
hintManager.setMasterRouteOnly();
try {
return pjp.proceed();
} finally {
hintManager.close();
}
}
}
```
### 事務操作
在事務中的讀請求,走主庫還是從庫呢?對於這個問題,最簡單的方式就是所有事務中的操作都走主庫,在事務中經常會存在插入,然後再重新查詢的場景,此時事務沒提交,就算同步很快,從庫也是沒有資料的,所以只能走主庫。
但還有一些請求,只需要查詢從庫就行了,如果針對所有事務中的操作都強制路由,也不是很好。在 Sharding-JDBC 中的做法挺好的,對於**同一執行緒且同一資料庫連線內,如有寫入操作,以後的讀操作均從主庫讀取,用於保證資料一致性**。如果我們在資料寫入之前有查詢請求,還是走的從庫,減輕主庫壓力。
### 動態強制路由
在功能開發的時候就決定了哪些介面要強制走主庫,這個時候我們會在程式碼上進行路由的控制,也就是前面講的自定義註解。如果有些是沒有加的,但是在線上執行的時候發現還是要走主庫才可以,這個時候就需要改程式碼重新發布了。
動態強制路由可以結合配置中心來實現,通過配置的方式來決定哪些介面要強制路由,然後在 Filter 中通過 HintManager 來設定,避免改程式碼重啟。
也可以通過切面精確到業務方法級別的動態路由配置。
## 流量分發
**場景一:**
假設你有一個主節點,兩個從節點,讀請求較多,兩個從節點壓力有點大。這個時候只能增加第三個從節點來分擔壓力。現象是主庫的壓力並不大,寫入較少,從成本來考慮,是否可以不增加第三個從節點呢?
**場景二:**
假設你有一個 8 核 64G 的主庫,8 核 64G 的從庫,4 核 32G 的從庫,從配置上來看,4 核 32G 的從庫處理能力肯定是要低於其他兩個的,這個時候如果我們沒有定製流量分發的比例,就會出現低配資料庫壓力過高而導致的問題。當然這個也能避免使用不同規則的從庫。
上面的場景需要能夠對請求進行管理,在 Sharding-JDBC 中提供了讀寫分離的路由演算法,我們可以自定義演算法來進行流量的分發管理。
實現演算法類:
```plain
public class KittyMasterSlaveLoadBalanceAlgorithm implements MasterSlaveLoadBalanceAlgorithm {
private RoundRobinMasterSlaveLoadBalanceAlgorithm roundRobin = new RoundRobinMasterSlaveLoadBalanceAlgorithm();
@Override
public String getDataSource(String name, String masterDataSourceName, List