
華為雲FusionInsight湖倉一體解決方案的前世今生
摘要:華為雲釋出新一代智慧資料湖華為雲FusionInsight時再次提到了湖倉一體理念,那我們就來看看湖倉一體的前世今生。
伴隨5G、大資料、AI、IoT的飛速發展,資料呈現大規模、多樣性的極速增長,為了應對多變的業務訴求,政企客戶對資料處理分析的實時性和融合性提出了更高的要求,“湖倉一體”的概念應運而生,它打破資料湖與數倉間的壁壘,使得割裂資料融合統一,減少資料分析中的搬遷,實現統一的資料管理。
早在2020年5月份的華為全球分析師大會上,華為雲CTO張宇昕提出了“湖倉一體”概念,在隨後的華為雲與計算城市峰會上,“湖倉一體”理念跟隨華為雲FusionInsight智慧資料湖在南京、深圳、西安、重慶等地均有呈現,在剛結束的HC2020上,張宇昕在釋出新一代智慧資料湖華為雲FusionInsight時再次提到了湖倉一體理念。那我們就來看看湖倉一體的來世今生。
資料湖和資料倉庫的發展歷程和挑戰
早在1990年,比爾·恩門(Bill Inmon)提出了資料倉庫,主要是將組織內資訊系統聯機事務處理(OLTP)常年累積的大量資料,按資料倉庫特有的資料儲存架構進行聯機分析處理(OLAP)、資料探勘(Data Mining)等分析,幫助決策者快速有效地從大量資料中分析出有價值的資訊,以利決策制定及快速響應外在環境變化,幫助構建商業智慧(BI)。
大約十年前,企業開始構建資料湖來應對大資料時代,它通常把所有的企業資料統一儲存,既包括源系統中的原始副本,也包括轉換後的資料,比如那些用於報表, 視覺化, 資料分析和機器學習的資料。
縱觀資料湖與資料倉庫的技術發展,不難發現兩者有著各自的優劣,具體表現如下:

表1 湖倉對比, 各有千秋
企業在進行系統架構設計選型時,需要從具體的分析場景出發,單一的模式已經無法滿足企業發展的業務訴求,集中表現在以下兩個痛點:
- 資料湖主要以離線批量計算為主,因為不支援資料倉庫的資料管理能力,難以提高資料質量;資料入湖時效差不支援實時更新,資料無法強一致性;主題建模不友好,無法直接歷史拉鍊建模;同時互動分析通常將資料搬遷到資料倉庫平臺,造成分析鏈路長,資料冗餘儲存;批&流等場景融合不夠,無法滿足企業的海量資料處理訴求。
- 資料倉庫滿足不了非結構化資料的分析需求,價效比不高;同時倉&湖間難以互聯互通,資料協同效率較低,無法支援跨平臺透明訪問,形成了事實上的資料孤島,找數困難;缺乏全域性資料檢視,不同平臺介面差異和不同開發管理工具,造成使用者開發使用複雜,資料分別管理維護代價高體驗差。
資料湖和資料倉庫正在從兩條技術演進路線走向融合
綜上,資料湖和資料倉庫在企業資料分析場景分別承擔一湖一倉的重要角色,形成了完整的資料分析生態系統,上述企業場景面臨的2個關鍵痛點也在驅動資料湖和資料倉庫在技術演進上走向融合:
第一個融合方向是基於Hadoop體系的資料湖向資料倉庫能力擴充套件,湖中建倉,從DataLake進化到LakeHouse。LakeHouse結合了資料湖和資料倉庫特點,直接在用於資料湖的低成本儲存上實現與資料倉庫中類似的資料結構和資料管理功能。目前業界已經湧現了一些LakeHouse產品,如Netflix開源Iceberg、Uber開源Hudi、Databricks的 DeltaLake。
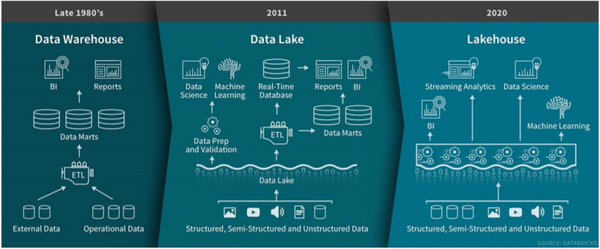
圖2從DataLake進化到LakeHouse,資料湖擴充套件數倉能力
以目前生態發展迅速的Apache Hudi為例:統一資料儲存,分散式儲存不同應用所需的各種型別資料;數倉模式執行和治理,實現事務&更新機制,保證資料完整性和一致性,具有健壯的治理&審計機制;支援各種分析引擎,統一資料儲存通過開放和標準化的儲存格式(如Parquet),提供API以便各類工具和引擎(包括機器學習和Python / R庫)直接有效地訪問資料。
雖然LakeHouse並不能完全替代資料倉庫,但通過增強效能,支援實時入湖、建模、互動分析等場景,將在企業分析環境中發揮更大作用。
第二個融合方向是資料湖和資料倉庫協同起來向湖倉一體的融合分析架構發展,隨著企業資料量快速增長,不僅是結構化資料,也有非結構化資料,同時提出了對搜尋/機器學習更多的能力要求,使得原來數倉技術不能夠有效的處理複雜場景,為此需擴充套件原有系統,引入Hadoop大資料平臺實現新型別資料、新業務場景的支援。在這個背景下由Gartner在2011年提出邏輯資料倉庫的概念,預測企業資料分析傾向於轉向一種更加邏輯化的架構,利用分散式處理、資料虛擬化以及元資料管理等技術,實現邏輯統一物理分開的協同體系。

圖2 邏輯數倉的高階架構
湖倉一體可以認為是邏輯資料倉庫架構理念下針對Hadoop資料湖和MPPDB資料倉庫的融合架構的最好詮釋,資料對使用者將完全實現虛擬化,以邏輯統一的資料分析系統為企業提供資料分析服務:
使用者使用層面提供統一元資料管理和資料檢視,實現全域性資料可見可查,支援標準統一訪問介面簡化使用者開發,提供統一開發和治理的工具體系。
平臺層面Hadoop與MPPDB具備資料共享和跨庫分析能力,支援互聯互通、計算下推、協同計算,實現資料多平臺之間透明流動。
華為雲FusionInsight湖倉一體解決方案參考架構
華為雲FusionInsight智慧資料湖涵蓋了分散式儲存、大資料、資料倉庫、資料治理等,融合了上述兩個技術演進方向,為企業使用者提供雲原生湖倉一體解決方案,整體的參考架構如下:

圖4 華為雲FusionInsight湖倉一體解決方案參考架構
下面一起來看看:
資料儲存層:通過OBS統一管理湖&倉的儲存底座,將儲存在EC(Erasure Code糾錯碼)、可靠性方面的優勢融入進了大資料生態:
- 雲原生架構領先:基於雲原生架構的OBS儲存,具有高頻寬,大併發,分散式元資料等特徵,因此相同成本的華為存算分離的湖倉一體化叢集,資料讀寫效能領先業界30%。
- 儲存計算分離有效降低TCO:支援大比例EC, 副本數從3最低可降低至1.09,TCO下降20%+。
- 統一元資料管理實現湖倉共享儲存資源池:通過獨立的Data Lake Catalog提供統一元資料管理,相容Hive Metastore介面,可以無縫對接各類大資料元件。實現針對同一份元資料定義支援各類場景、物件、檔案、大資料等不同協議間的資料共享,讓資料倉庫、資料湖、圖引擎、AI等多種計算引擎共享統一的資料儲存池。此方案不僅消除了孤立系統中的資料副本,還使得客戶可以按照業務按需使用計算儲存資源,不僅降低了CAPEX,還簡化了運維,從而達成最佳TCO。同時,Data Lake Catalog開放介面,支援和第三方的計算引擎層、資料治理層對接。
計算引擎層:把事務能力引入資料湖,通過HetuEngine標準SQL實現跨域多源統一訪問,湖&倉資料互通協同計算,資料免搬遷:
- CarbonData & Hudi資料實時入湖,實現資料湖事務能力:企業內部許多資料管道通常會併發讀寫資料,我們通過CarbonData& Hudi資料儲存引擎實現資料實時、增量更新,資料T+0實時入湖,大幅縮短傳統T+1、T+2時延;引入的增量處理框架,實現了資料湖事務能力,支援入湖過程中的Update/Delete等。
- HetuEngine支援跨源跨域統一SQL訪問,簡單易用:使用者層基於統一的標準SQL介面,對接多個數據源(HDFS, HBase, DWS等),提供秒級互動式訪問,滿足各種統計分析、多表Join關聯等,讓分析建模人員資料分析更容易,降低訪問門檻。
- HetuEngine & DWS-Express打破資料牆,資料免搬遷創新更敏捷:支援資料湖與資料倉庫間的資料互聯互通、跨平臺協同計算,資料免搬遷。HetuEngine在湖內基於統一資料目錄,實現高併發,高效能的互動式查詢,基於一份資料進行批、流、互動式融合分析,貼源加工、整合關聯、主題加工等都在湖內,資料不出湖,分析鏈路短,加速業務創新;使用者可使用DWS-Express提供由成百上千節點組成的加速叢集,對儲存在OBS上的海量資料進行線上分析,相比本地託管叢集,效率提升數百倍。
- 自研Superior排程器支援單叢集2萬+節點規模,業界最佳:在一個叢集內,通過華為自研的Superior排程器支援各種工作負載統一排程,包括資料科學、機器學習以及SQL和分析,排程速率達35萬Container/s,資源利用率達90%+,大幅降低企業投入成本。
- 資料冷熱分級儲存實現更高效的全生命週期管理:DWS具備與OBS的雙向互通的能力,既能直接讀取OBS上的海量歷史資料,也能夠直接寫入資料到OBS。通過這個特性,我們可以對企業中的海量資料進行更加高效的全生命週期管理,分析中經常使用到的熱/溫資料存放在DWS中,較少使用的冷資料存放到OBS中,兼顧企業對分析效能和儲存經濟性的訴求。
- 無縫銜接AI挖掘更多資料價值:深度優化一站式開發平臺ModelArts&分散式圖計算引擎GES提高開發效率。提供基於資料湖的AI訓練推理能力,減少資料搬遷次數,基於100+機器學習運算元和NLP演算法,實現海量資料快速價值挖掘,滿足場景預測、自然語言處理及企業知識圖譜等應用; 讓GES更快捷地為金融等場景提供關係網路分析等服務。
運營管理層:通過DAYU實現了湖&倉統一的資料整合、開發、目錄、治理、開放服務等的運營管理:
- 資料整合:實現多源異構資料高效入湖,支援批/流/實時資料多種方式接入。其中,批量資料遷移基於分散式計算框架,利用並行化處理技術,支援使用者穩定高效地對海量資料進行移動,實現不停服資料遷移,快速構建所需的資料架構;流和實時資料接入每小時可從數十萬種資料來源(例如日誌和定位追蹤事件、網站點選流、社交媒體源等)中連續捕獲、傳送和儲存數TB資料。
- 資料開發:提供一站式敏捷資料開發平臺,提供視覺化的圖形開發介面、豐富的資料開發型別(指令碼開發和作業開發)、全託管的作業排程和運維監控能力,內建行業資料處理pipeline,一鍵式開發,全流程視覺化,支援多人線上協同開發,支援管理多種大資料雲服務,極大地降低了使用者使用大資料的門檻,幫助使用者快速構建資料湖資料處理中心。
- 資料治理:為企業提供資料體系標準和資料規範定義的方法論,統一資料語言和資料建模;為普通業務人員提供高效、準確的資料搜尋工具,高效找到資料;提供技術元資料與業務元資料的關聯,業務人員快速讀懂資料;為資料提供有效的質量管控和評估手段,資料可信質量高。
- 資料開放:為資料湖搭建統一的資料服務匯流排,幫助企業統一管理對內對外的API服務,支撐業務主題/畫像/指標的訪問、查詢和檢索,提升資料消費體驗和效率;支援100+開放API,擁有10+行業模板,使能行業ISV快速整合,助力客戶資料標準資產沉澱。
綜上所述,正是在三層架構都打通了湖倉的技術壁壘,我們才看到了真正的湖倉一體:
資料儲存層基於雲原生領先架構,存算分離有效降低TCO,統一元資料管理實現湖倉共享儲存資源池,針對同一份元資料定義支援各種場景,提供API方便各類工具和引擎(包括機器學習、Python、R等)直接有效地訪問資料,這是實現湖倉一體的一個關鍵點;
計算引擎層為資料湖增加了事務能力提升了資料質量;利用HetuEngine通過標準SQL訪問跨域多源資料,實現湖&倉資料關聯分析協同計算,簡單易用; 打破資料牆,在湖內基於統一資料目錄,可基於資料湖實現融合分析&AI訓練推理,減少資料搬遷,實現海量資料快速價值挖掘。
運營管理層則提供統一的資料開發和治理環境,具備安全管理功能,支援多引擎任務統一開發和編排,資料統一建模和質量監測,實現湖倉一致的開發治理體驗。
未來展望
華為雲FusionInsight智慧資料湖基於客戶需求和技術演進趨勢持續創新,為企業客戶提供湖倉一體解決方案,致力於打造業界最佳的資料底座,讓企業業務的創新更敏捷,業務洞察更準確,加速釋放資料價值,和資料使能協同更好地服務千行萬業!
點選關注,第一時間瞭解華為雲新鮮技