
重要 | Spark和MapReduce的對比,不僅僅是計算模型?
【前言:筆者將分上下篇文章進行闡述Spark和MapReduce的對比,首篇側重於"巨集觀"上的對比,更多的是筆者總結的針對"相對於MapReduce我們為什麼選擇Spark"之類的問題的幾個核心歸納點;次篇則從任務處理級別運用的並行機制/計算模型方面上對比,更多的是讓大家對Spark為什麼比MapReduce快有一個更深、更全面的認識。通過兩篇文章的解讀,希望幫助大家對Spark和MapReduce有一個更深入的瞭解,並且能夠在遇到諸如"MapReduce相對於Spark的侷限性?"等類似的面試題時能夠得到較好地表現,順利拿下offer】
>> 上篇
首先糾正一個誤區:在瀏覽Spark官網時,經常能看到如下這張圖:
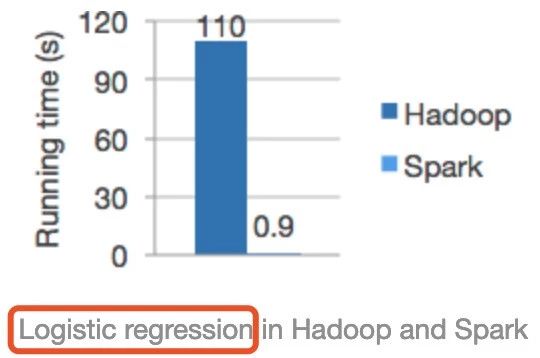
從上圖可以看出Spark的執行速度明顯比Hadoop(其實是跟MapReduce計算引擎對比)快上百倍!相信很多人在初學Spark時,認為Spark比MapReduce快的第一直觀概念都是由此而來,甚至筆者發現網上有些資料更是直接照搬這個對比,給初學者造成一個很嚴重的誤區。
這張圖是分別使用Spark和Hadoop執行邏輯迴歸機器學習演算法的執行時間比較,那麼能代表Spark執行任何型別的任務在相同的條件下都能得到這個對比結果嗎?很顯然是不對的,對於這個對比我們要知其然更要知其所以然。
首先,大多數機器學習演算法的核心是什麼?就是對同一份資料在訓練模型時,進行不斷的迭代、調參然後形成一個相對優的模型。而Spark作為一個基於記憶體迭代式大資料計算引擎很適合這樣的場景,之前的文章《Spark RDD詳解》也有介紹,對於相同的資料集,我們是可以在第一次訪問它之後,將資料集載入到記憶體,後續的訪問直接從記憶體中取即可。但是MapReduce由於執行時中間結果必然刷磁碟等因素,導致不適合機器學習等的迭代場景應用,還有就是HDFS本身也有快取功能,官方的對比極有可能在執行邏輯迴歸時沒有很好配置該快取功能,否則效能差距也不至於這麼大。
相對於MapReduce,我們為什麼選擇Spark,筆者做了如下總結:
>> Spark
1.集流批處理、互動式查詢、機器學習及圖計算等於一體
2.基於記憶體迭代式計算,適合低延遲、迭代運算型別作業
3.可以通過快取共享rdd、DataFrame,提升效率【尤其是SparkSQL可以將資料以列式的形式儲存於記憶體中】
4.中間結果支援checkpoint,遇錯可快速恢復
5.支援DAG、map之間以pipeline方式執行,無需刷磁碟
6.多執行緒模型,每個worker節點執行一個或多個executor服務,每個task作為執行緒執行在executor中,task間可共享資源
7.Spark程式設計模型更靈活,支援多種語言如java、scala、python、R,並支援豐富的transformation和action的運算元
>> MapReduce
1.適合離線資料處理,不適合迭代計算、互動式處理、流式處理
2.中間結果需要落地,需要大量的磁碟IO和網路IO影響效能
3.雖然MapReduce中間結果可以儲存於HDFS,利用HDFS快取功能,但相對Spark快取功能較低效
4.多程序模型,任務排程(頻繁申請、釋放資源)和啟動開銷大,不適合低延遲型別作業
5.MR程式設計不夠靈活,僅支援map和reduce兩種操作。當一個計算邏輯複雜的時候,需要寫多個MR任務執行【並且這些MR任務生成的結果在下一個MR任務使用時需要將資料持久化到磁碟才行,這就不可避免的進行遭遇大量磁碟IO影響效率】
但是,雖然Spark相對於MapReduce有很多優勢,但並不代表Spark目前可以完全取代MapReduce。
筆者之前負責的一個任務,資料儲存格式是parquet,壓縮比比較高,解壓後資料量劇增,又加上存在一些大欄位問題,任務比較複雜僅sql語句就幾千行,導致Spark處理時總是報OOM,在有限的資源試了各種調優方法都不能使任務正常穩定的執行。最後改用Hive的原生引擎MapReduce執行,在資源配置相同的情況下,任務能夠穩定執行,而且速度並沒有想象中的那麼慢。所以,對於技術之間的對比以及應用,還是建議首先要對技術本身有深入的理解比如設計思想、程式設計模型、原始碼分析等,並且要結合實際的業務場景需求等,不能空談技術。
>> 下篇
【前言:本文主要從任務處理的執行模式為角度,分析Spark計算模型,希望幫助大家對Spark有一個更深入的瞭解。同時拿MapReduce和Spark計算模型做對比,強化對Spark和MapReduce理解】
從整體上看,無論是Spark還是MapReduce都是多程序模型。如,MapReduce是由很多MapTask、ReduceTask等程序級別的例項組成的;Spark是由多個worker、executor等程序級別例項組成。但是當細分到具體的處理任務,MapReduce仍然是多程序級別,這一點在文章《詳解MapReduce》已有說明。而Spark處理任務的單位task是執行在executor中的執行緒,是多執行緒級別的。
對於多程序,我們可以很容易控制它們能夠使用的資源,並且一個程序的失敗一般不會影響其他程序的正常執行,但是程序的啟動和銷燬會佔用很多時間,同時該程序申請的資源在程序銷燬時也會釋放,這就造成了對資源的頻繁申請和釋放也是很影響效能的,這也是MapReduce廣為詬病的原因之一。
對於MapReduce處理任務模型,有如下特點:
1.每個MapTask、ReduceTask都各自執行在一個獨立的JVM程序中,因此便於細粒度控制每個task佔用的資源(資源可控性好)
2.每個MapTask/ReduceTask都要經歷申請資源 -> 執行task -> 釋放資源的過程。強調一點:每個MapTask/ReduceTask執行完畢所佔用的資源必須釋放,並且這些釋放的資源不能夠為該任務中其他task所使用
3.可以通過JVM重用在一定程度上緩解MapReduce讓每個task動態申請資源且執行完後馬上釋放資源帶來的效能開銷
但是JVM重用並不是多個task可以並行執行在一個JVM程序中,而是對於同一個job,一個JVM上最多可以順序執行的task數目,這個需要配置引數mapred.job.reuse.jvm.num.tasks,預設1。
對於多執行緒模型的Spark正好與MapReduce相反,這也決定了Spark比較適合執行低延遲的任務。在Spark中處於同一節點上的task以多執行緒的方式執行在一個executor程序中,構建了一個可重用的資源池,有如下特點:
1.每個executor單獨執行在一個JVM程序中,每個task則是執行在executor中的一個執行緒。很顯然執行緒執行緒級別的task啟動速度更快
2.同一節點上所有task執行在一個executor中,有利於共享記憶體。比如通過Spark的廣播變數,將某個檔案廣播到executor端,那麼在這個executor中的task不用每個都拷貝一份處理,而只需處理這個executor持有的共有檔案即可
3.executor所佔資源不會在一些task執行結束後立即釋放掉,可連續被多批任務使用,這避免了每個任務重複申請資源帶來的開銷
但是多執行緒模型有一個缺陷:同一節點的一個executor中多個task很容易出現資源徵用。畢竟資源分配最細粒度是按照executor級別的,無法對執行在executor中的task做細粒度控制。這也導致在執行一些超大資料量的任務並且資源比較有限時,執行不太穩定。相比較而言,MapReduce更有利於這種大任務的平穩執行。
關注微信公眾號:大資料學習與分享,獲取更對技術