
使用Apache Hudi + Amazon S3 + Amazon EMR + AWS DMS構建資料湖
阿新 • • 發佈:2020-11-05
### 1. 引入
資料湖使組織能夠在更短的時間內利用多個源的資料,而不同角色使用者可以以不同的方式協作和分析資料,從而實現更好、更快的決策。Amazon Simple Storage Service(amazon S3)是針對結構化和非結構化資料的高效能物件儲存服務,可以用來作為資料湖底層的儲存服務。
然而許多用例,如從上游關係資料庫執行變更資料捕獲(CDC)到基於Amazon S3的資料湖,都需要在記錄級別處理資料,執行諸如從資料集中插入、更新和刪除單條記錄的操作需要處理引擎讀取所有物件(檔案),進行更改,並將整個資料集重寫為新檔案。此外為使資料湖中的資料以近乎實時的方式被訪問,通常會導致資料被分割成許多小檔案,從而導致查詢效能較差。Apache Hudi是一個開源的資料管理框架,它使您能夠在Amazon S3 資料湖中以記錄級別管理資料,從而簡化了CDC管道的構建,並使流資料攝取變得高效,Hudi管理的資料集使用開放儲存格式儲存在Amazon S3中,通過與Presto、Apache Hive、Apache Spark和AWS Glue資料目錄的整合,您可以使用熟悉的工具近乎實時地訪問更新的資料。Amazon EMR已經內建Hudi,在部署EMR叢集時選擇Spark、Hive或Presto時自動安裝Hudi。
本篇文章將展示如何構建一個CDC管道,該管道使用AWS資料庫遷移服務(AWS DMS)從Amazon關係資料庫服務(Amazon RDS)for MySQL資料庫中捕獲資料,並將這些更改應用到Amazon S3中的一個數據集上。Apache Hudi包含了HoodieDeltaStreamer實用程式,它提供了一種從許多源(如分散式檔案系統DFS或Kafka)攝取資料的簡單方法,它可以自己管理檢查點、回滾和恢復,因此不需要跟蹤從源讀取和處理了哪些資料,這使得使用更改資料變得很容易,同時還可以在接收資料時對資料進行基於SQL的輕量級轉換,有關詳細資訊,請參見[寫Hudi表](https://hudi.apache.org/docs/0.5.2-writing_data.html)。ApacheHudi版本0.5.2提供了對帶有HoodieDeltaStreamer的AWS DMS支援,並在Amazon EMR 5.30.x和6.1.0上可用。
### 2. 架構
下圖展示了構建CDC管道而部署的體系結構。
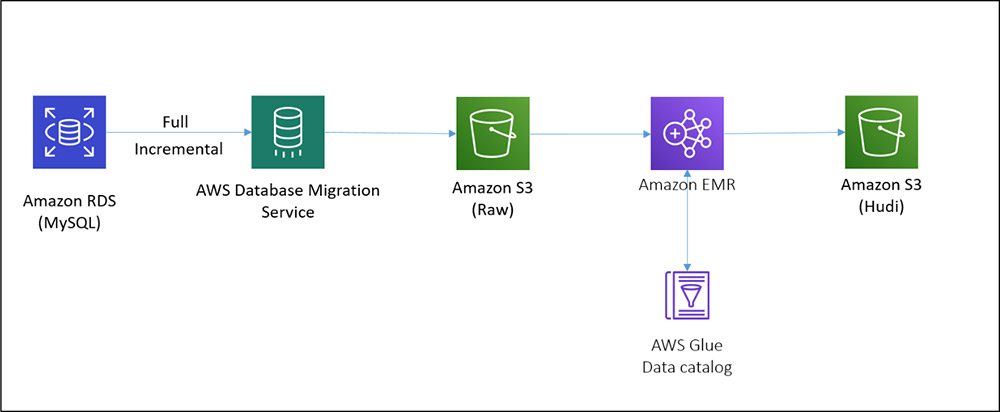
在該架構中,我們在Amazon RDS上有一個MySQL例項,AWS-DMS將完整的增量資料(使用AWS-DMS的CDC特性)以Parquet格式存入S3中,EMR叢集上的HoodieDeltaStreamer用於處理全量和增量資料,以建立Hudi資料集,當更新MySQL資料庫中的資料後,AWS-DMS任務將獲取這些更改並將它們變更到原始的S3儲存桶中。HoodieDeltastreamer作業可以在EMR叢集上以特定的頻率或連續模式執行,以將這些更改應用於Amazon S3資料湖中的Hudi資料集,然後可以使用SparkSQL、Presto、執行在EMR叢集上的Apache Hive和Amazon Athena等工具查詢這些資料。
### 3. 部署解決方案資源
使用AWS CloudFormation在AWS帳戶中部署這些元件,選擇一個AWS區域部署以下服務:
* Amazon EMR
* AWS DMS
* Amazon S3
* Amazon RDS
* AWS Glue
* AWS Systems Manager
在部署CloudFormation模板之前需要先滿足如下條件:
* 擁有一個至少有兩個公共子網的專有網路(VPC)。
* 有一個S3儲存桶來從EMR叢集收集日誌,需要在同一個AWS區域。
* 具有AWS身份和訪問管理(IAM)角色DMS VPC角色`dms-vpc-role`。
* 如果要使用AWS Lake Formation許可權模型在帳戶中部署,請驗證以下設定:
* 用於部署技術棧的IAM使用者需要被新增為Lake Formation下的data lake administrator,或者用於部署堆疊的IAM使用者具有在AWS Glue data Catalog中建立資料庫的IAM許可權。
* Lake Formation下的資料目錄(Data Catalog)設定配置為僅對新資料庫和新資料庫中的新表使用IAM訪問控制,這將確保僅使用IAM許可權控制對資料目錄(Data Catalog)中新建立的資料庫和表的所有訪問許可權。

* `IAMAllowedPrincipals`在Lake Formation database creators頁面上被授予資料庫建立者許可權。

如果此許可權不存在,請通過選擇`授予`並選擇授予`建立資料庫`許可權。
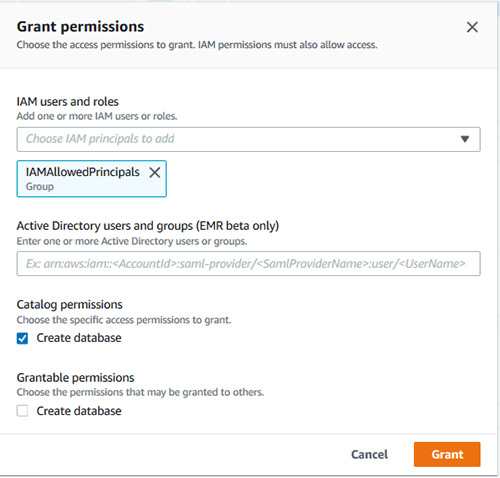
這些設定是必需的,以便僅使用IAM控制對資料目錄物件的所有許可權。
### 4. 啟動CloudFormation
要啟動CloudFormation棧,請完成以下步驟
* 選擇啟動CloudFormation棧
* 在Parameters部分提供必需的引數,包括一個用於儲存Amazon EMR日誌的S3 Bucket和一個您想要訪問Amazon RDS for MySQL的CIDR IP範圍。

* 遵循CloudFormation建立嚮導,保持其餘預設值不變。
* 在最後一個頁面上,選擇允許AWS CloudFormation可能會使用自定義名稱建立IAM資源。
* 選擇`建立`。
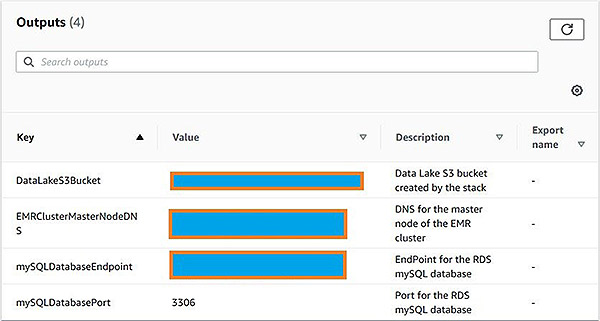
* 當建立完成後,在CloudFormation堆疊的Outputs選項卡上記錄S3 Bucket、EMR叢集和Amazon RDS for MySQL的詳細資訊。
CloudFormation模板為EMR叢集使用m5.xlarge和m5.2xlarge例項,如果這些例項型別在你選擇用於部署的區域或可用性區域中不可用,那麼CloudFormation將會建立失敗。如果發生這種情況,請選擇例項型別可用的區域或子網。
CloudFormation還使用必要的連線屬性(如`dataFormat`、`timestampColumnName`和`parquetTimestampInMillisecond`)建立和配置AWS DMS端點和任務。
作為CloudFormation棧的一部分部署的資料庫例項已經被建立,其中包含AWS-DMS在資料庫的CDC模式下工作所需的設定。
- `binlog_format=ROW`
- `binlog_checksum=NONE`
另外在RDS DB例項上啟用自動備份,這是AWS-DMS進行CDC所必需的屬性。
### 5. 執行端到端資料流
CloudFormation部署好後就可以執行資料流,將MySQL中的完整和增量資料放入資料湖中的Hudi資料集。
1. 作為最佳實踐,請將binlog保留至少24小時。使用SQL客戶端登入Amazon RDS for MySQL資料庫並執行以下命令:
```sql
call mysql.rds_set_configuration('binlog retention hours', 24)
```
2. 在dev資料庫中建立表:
```sql
create table dev.retail_transactions(
tran_id INT,
tran_date DATE,
store_id INT,
store_city varchar(50),
store_state char(2),
item_code varchar(50),
quantity INT,
total FLOAT);
```
3. 建立表時,將一些測試資料插入資料庫:
```sql
insert into dev.retail_transactions values(1,'2019-03-17',1,'CHICAGO','IL','XXXXXX',5,106.25);
insert into dev.retail_transactions values(2,'2019-03-16',2,'NEW YORK','NY','XXXXXX',6,116.25);
insert into dev.retail_transactions values(3,'2019-03-15',3,'SPRINGFIELD','IL','XXXXXX',7,126.25);
insert into dev.retail_transactions values(4,'2019-03-17',4,'SAN FRANCISCO','CA','XXXXXX',8,136.25);
insert into dev.retail_transactions values(5,'2019-03-11',1,'CHICAGO','IL','XXXXXX',9,146.25);
insert into dev.retail_transactions values(6,'2019-03-18',1,'CHICAGO','IL','XXXXXX',10,156.25);
insert into dev.retail_transactions values(7,'2019-03-14',2,'NEW YORK','NY','XXXXXX',11,166.25);
insert into dev.retail_transactions values(8,'2019-03-11',1,'CHICAGO','IL','XXXXXX',12,176.25);
insert into dev.retail_transactions values(9,'2019-03-10',4,'SAN FRANCISCO','CA','XXXXXX',13,186.25);
insert into dev.retail_transactions values(10,'2019-03-13',1,'CHICAGO','IL','XXXXXX',14,196.25);
insert into dev.retail_transactions values(11,'2019-03-14',5,'CHICAGO','IL','XXXXXX',15,106.25);
insert into dev.retail_transactions values(12,'2019-03-15',6,'CHICAGO','IL','XXXXXX',16,116.25);
insert into dev.retail_transactions values(13,'2019-03-16',7,'CHICAGO','IL','XXXXXX',17,126.25);
insert into dev.retail_transactions values(14,'2019-03-16',7,'CHICAGO','IL','XXXXXX',17,126.25);
```
現在使用AWS DMS將這些資料推送到Amazon S3。
4. 在AWS DMS控制檯上,執行hudiblogload任務。
此任務將表的全量資料載入到Amazon S3,然後開始寫增量資料。

如果第一次啟動AWS-DMS任務時系統提示測試AWS-DMS端點,那麼可以先進行測試,在第一次啟動AWS-DMS任務之前測試源和目標端點通常是一個好的實踐。
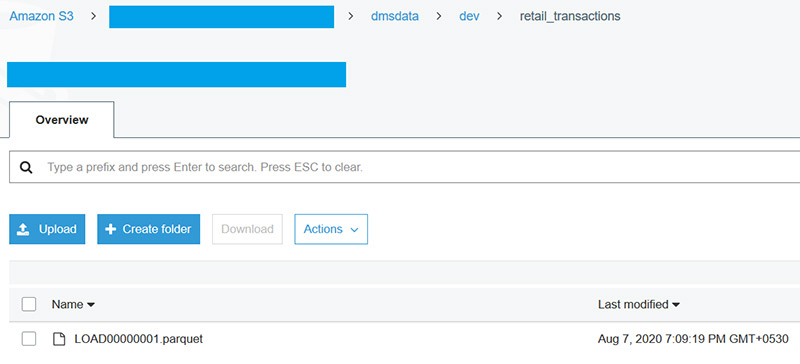
幾分鐘後,任務的狀態將變更為"載入完成"、"複製正在進行",這意味著已完成全量載入,並且正在進行的複製已開始,可以轉到由CloudFormation建立的S3 Bucket,應該會在S3 Bucket的dmsdata/dev/retail_transactions資料夾下看到一個.parquet檔案。
5. 在EMR叢集的Hardware選項卡上,選擇主例項組並記錄主例項的EC2例項ID。
6. 在Systems Manager控制檯上,選擇會話管理器。
7. 選擇"啟動會話"以啟動與群集主節點的會話。
8. 通過執行以下命令將使用者切換到Hadoop
```sql
sudo su hadoop
```
在實際用例中,AWS DMS任務在全量載入完成後開始向相同的Amazon S3位置寫入增量檔案,區分全量載入和增量載入檔案的方法是,完全載入檔案的名稱以load開頭,而CDC檔名具有日期時間戳,如在後面步驟所示。從處理的角度來看,我們希望將全部負載處理到Hudi資料集中,然後開始增量資料處理。為此,我們將滿載檔案移動到同一S3儲存桶下的另一個S3資料夾中,並在開始處理增量檔案之前處理這些檔案。
9. 在EMR叢集的主節點上執行以下命令(將\替換為實際的bucket name):
```sql
aws s3 mv s3:///dmsdata/dev/retail_transactions/ s3:///dmsdata/data-full/dev/retail_transactions/ --exclude "*" --include "LOAD*.parquet" --recursive
```
有了datafull資料夾中的全量表轉儲,接著使用EMR叢集上的HoodieDeltaStreamer實用程式來向Amazon S3上寫入Hudi資料集。
10. 執行以下命令將Hudi資料集填充到同一個S3 bucket中的Hudi資料夾中(將\替換為CloudFormation建立的S3 bucket的名稱):
```shell
spark-submit --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer \
--packages org.apache.hudi:hudi-utilities-bundle_2.11:0.5.2-incubating,org.apache.spark:spark-avro_2.11:2.4.5 \
--master yarn --deploy-mode cluster \
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \
--conf spark.sql.hive.convertMetastoreParquet=false \
/usr/lib/hudi/hudi-utilities-bundle_2.11-0.5.2-incubating.jar \
--table-type COPY_ON_WRITE \
--source-ordering-field dms_received_ts \
--props s3:///properties/dfs-source-retail-transactions-full.properties \
--source-class org.apache.hudi.utilities.sources.ParquetDFSSource \
--target-base-path s3:///hudi/retail_transactions --target-table hudiblogdb.retail_transactions \
--transformer-class org.apache.hudi.utilities.transform.SqlQueryBasedTransformer \
--payload-class org.apache.hudi.payload.AWSDmsAvroPayload \
--schemaprovider-class org.apache.hudi.utilities.schema.FilebasedSchemaProvider \
--enable-hive-sync
```
前面的命令執行一個執行HoodieDeltaStreamer實用程式的Spark作業。有關此命令中使用的引數的詳細資訊,請參閱編寫Hudi表。
當Spark作業完成後,可以導航到AWS Glue控制檯,找到在hudiblogdb資料庫下建立的名為retail_transactions的表,表的input format是org.apache.hudi.hadoop.HoodieParquetInputFormat.

接下來查詢資料並檢視目錄中retail_transactions表的資料。
11. 在先前建立的Systems Manager會話中,執行以下命令(確保已完成post的所有先前條件,包括在Lake Formation中將IAMAllowedPrincipals新增為資料庫建立者):
```shell
spark-shell --conf "spark.serializer=org.apache.spark.serializer.KryoSerializer" --conf "spark.sql.hive.convertMetastoreParquet=false" \
--packages org.apache.hudi:hudi-spark-bundle_2.11:0.5.2-incubating,org.apache.spark:spark-avro_2.11:2.4.5 \
--jars /usr/lib/hudi/hudi-spark-bundle_2.11-0.5.2-incubating.jar,/usr/lib/spark/external/lib/spark-avro.jar
```
12. 對retail_transactions表執行以下查詢:
```sql
spark.sql("select * from hudiblogdb.retail_transactions order by tran_id").show()
```
接著可以在表中看到與MySQL資料庫相同的資料,其中有幾個列是由HoodieDeltaStreamer自動新增Hudi元資料。

現在在MySQL資料庫上執行一些DML語句,並將這些更改傳遞到Hudi資料集。
13. 在MySQL資料庫上執行以下DML語句
```sql
insert into dev.retail_transactions values(15,'2019-03-16',7,'CHICAGO','IL','XXXXXX',17,126.25);
update dev.retail_transactions set store_city='SPRINGFIELD' where tran_id=12;
delete from dev.retail_transactions where tran_id=2;
```
幾分鐘後將看到在S3儲存桶中的dmsdata/dev/retail_transactions資料夾下建立了一個新的.parquet檔案。

14. 在EMR叢集上執行以下命令,將增量資料獲取到Hudi資料集(將\替換為CloudFormation模板建立的s3 bucket的名稱):
```shell
spark-submit --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer \
--packages org.apache.hudi:hudi-utilities-bundle_2.11:0.5.2-incubating,org.apache.spark:spark-avro_2.11:2.4.5 \
--master yarn --deploy-mode cluster \
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \
--conf spark.sql.hive.convertMetastoreParquet=false \
/usr/lib/hudi/hudi-utilities-bundle_2.11-0.5.2-incubating.jar \
--table-type COPY_ON_WRITE \
--source-ordering-field dms_received_ts \
--props s3:///properties/dfs-source-retail-transactions-incremental.properties \
--source-class org.apache.hudi.utilities.sources.ParquetDFSSource \
--target-base-path s3:///hudi/retail_transactions --target-table hudiblogdb.retail_transactions \
--transformer-class org.apache.hudi.utilities.transform.SqlQueryBasedTransformer \
--payload-class org.apache.hudi.payload.AWSDmsAvroPayload \
--schemaprovider-class org.apache.hudi.utilities.schema.FilebasedSchemaProvider \
--enable-hive-sync \
--checkpoint 0
```
此命令與上一個命令之間的關鍵區別在於屬性檔案,該檔案包含–-props和--checkpoint引數,對於先前執行全量載入的命令,我們使用`dfs-source-retail-transactions-full.properties`進行全量載入、`dfs-source-retail-transactions-incremental.properties`進行增量載入,這兩個屬性檔案之間的區別是:
* 源資料的位置在AmazonS3中的全量資料和增量資料之間發生變化。
* SQL transformer查詢包含了一個全量任務的`Op`欄位,因為AWS DMS首次全量載入不包括parquet資料集的Op欄位,Op欄位可有I、U和D值,表示插入、更新和刪除。
本文後面的"部署到生產環境時的注意事項"部分討論--checkpoint引數的詳細資訊。
15. 作業完成後,在spark shell中執行相同的查詢。
將會看到這些更新應用於Hudi資料集。
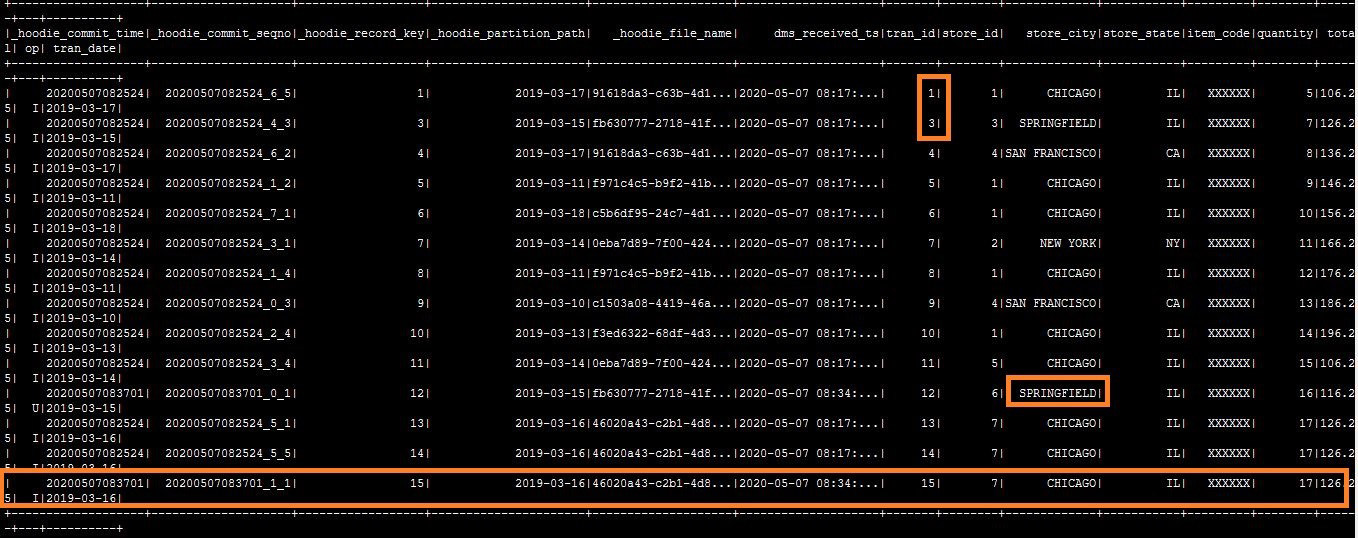
另外還可以使用Hudi Cli來管理Hudi資料集,以檢視有關提交、檔案系統、統計資訊等的資訊。
16. 為此在Systems Manager會話中,執行以下命令
```sql
/usr/lib/hudi/cli/bin/hudi-cli.sh
```
17. 在Hudi Cli中,執行以下命令(將\替換為CloudFormation模板建立的s3 bucket的名稱):
```sql
connect --path s3:///hudi/retail_transactions
```
18. 要檢查Hudi資料集上的提交(commit),請執行以下命令
```sql
commits show
```

還可以從Hudi資料集查詢增量資料,這對於希望將增量資料用於下游處理(如聚合)時非常有用,Hudi提供了多種增量提取資料的方法,Hudi快速入門指南中提供瞭如何使用此功能的示例。
### 6. 部署到生產環境時的注意事項
前面展示了一個如何從關係資料庫到基於Amazon S3的資料湖構建CDC管道的示例,但如果要將此解決方案用於生產,則應考慮以下事項:
* 為了確保高可用性,可以在多AZ配置中設定AWS-DMS例項。
* CloudFormation將deltastreamer實用程式所需的屬性檔案部署到S3://\/properties/處的S3 bucket中,你可以根據需求定製修改,其中有幾個引數需要注意
* **deltastreamer.transformer.sql** – 此屬性是Deltastreamer實用程式的一個非常強大的特性:它使您能夠在資料被攝取並儲存在Hudi資料集中時動態地轉換資料,在本文中,我們展示了一個基本的轉換,它將`tran_date`列強制轉換為字串,但是您可以將任何轉換作為此查詢的一部分應用。
* **parquet.small.file.limit**– 此欄位以位元組為單位,是一個關鍵儲存配置,指定Hudi如何處理Amazon S3上的小檔案,由於每個分割槽的每個插入操作中要處理的記錄數,可能會出現小檔案,設定此值允許Hudi繼續將特定分割槽中的插入視為對現有檔案的更新,從而使檔案的大小小於此值`small.file.limit`被重寫。
* **parquet.max.file.size** – 這是Hudi資料集中單個parquet檔案的最大檔案大小,之後將建立一個新檔案來儲存更多資料。對於Amazon S3的儲存和資料查詢需求,我們可以將其保持在256MB-1GB(256x1024x1024=268435456)。
* **[Insert|Upsert|bulkinsert].shuffle.parallelism**。本篇文章中我們只處理了少量記錄的小資料集。然而,在實際情況下可能希望在第一次載入時引入數億條記錄,然後增量CDC資料達百萬,當希望對每個Hudi資料集分割槽中的檔案數量進行非常可預測的控制時,需要設定一個非常重要的引數,這也需要確保在處理大量資料時,不會達到Apache Spark對資料shuffle的2GB限制。例如,如果計劃在第一次載入時載入200 GB的資料,並希望檔案大小保持在大約256 MB,則將此資料集的shuffle parallelism引數設定為800(200×1024/256)。有關詳細資訊,請參閱[調優指南](https://cwiki.apache.org/confluence/display/HUDI/Tuning+Guide)。
* 在增量載入deltastreamer命令中,我們使用了一個附加引數:--checkpoint 0。當Deltastreamer寫Hudi資料集時,它將檢查點資訊儲存在.hoodie資料夾下的.commit檔案中,它在隨後的執行中使用這些資訊,並且只從Amazon S3讀取資料,後者是在這個檢查點時間之後建立的,在生產場景中,在啟動AWS-DMS任務之後,只要完成全量載入,該任務就會繼續向目標S3資料夾寫入增量資料。在接下來的步驟中,我們在EMR叢集上運行了一個命令,將全量檔案手動移動到另一個資料夾中,並從那裡處理資料。當我們這樣做時,與S3物件相關聯的時間戳將更改為最新的時間戳,如果在沒有checkpoint引數的情況下執行增量載入,deltastreamer在手動移動滿載檔案之前不會提取任何寫入Amazon S3的增量資料,要確保Deltastreamer第一次處理所有增量資料,請將檢查點設定為0,這將使它處理資料夾中的所有增量資料。但是,只對第一次增量載入使用此引數,並讓Deltastreamer從該點開始使用自己的檢查點方法。
* 對於本文,我們手動執行Spark submit命令,但是在生產叢集中可以執行這一[步驟](https://docs.aws.amazon.com/emr/latest/ReleaseGuide/emr-spark-submit-step.html)。
* 可以使用排程或編排工具安排增量資料載入命令以固定間隔執行,也可以通過向spark submit命令傳遞附加引數`--min-sync-interval-seconds *XX* –continuous`,以特定的頻率以連續方式執行它,其中XX是資料拉取每次執行之間的秒數。例如,如果要每5分鐘執行一次處理,請將XX替換為300。
### 7. 清理
當完成對解決方案的探索後,請完成以下步驟以清理CloudFormation部署的資源
* 清空CloudFormation堆疊建立的S3 bucket
* 刪除在s3://\/HudiBlogEMRLogs/下生成的任何Amazon EMR日誌檔案。
* 停止AWS DMS任務Hudiblogload。
* 刪除CloudFormation。
* 刪除CloudFormation模板後保留的所有Amazon RDS for MySQL資料庫快照。
### 8. 結束
越來越多的資料湖構建在Amazon S3,當對資料湖的資料進行變更時,使用傳統方法處理資料刪除和更新涉及到許多繁重的工作,在這篇文章中,我們看到了如何在Amazon EMR上使用AWS DMS和`HoodieDeltaStreamer`輕鬆構建解決方案。我們還研究了在將資料整合到資料湖時如何執行輕量級的記錄級轉換,以及如何將這些資料用於聚合等下游流程。我們還討論了使用的重要設定和命令列選項,以及如何修改它們以滿足個性化的