
理解記憶體對齊
阿新 • • 發佈:2020-11-06
原文地址: [https://blog.fanscore.cn/p/24/](https://blog.fanscore.cn/p/24/)
相信大家都聽說過記憶體對齊的概念,不過這裡還是通過一個現象來引出本篇話題。
# 一、求一個結構體的size
猜下下面這個結構體會佔用多少位元組
```
type S struct {
B byte // Go中一個byte佔1位元組,int32佔4個位元組,int64佔8個位元組
I64 int64
I32 int32
}
```
是不是以為是1+8+4 = 13個位元組?寫段程式碼驗證下:
```
type S struct {
B byte
I64 int64
I32 int32
}
func main() {
s := S{}
fmt.Printf("s size:%d\n", unsafe.Sizeof(s))
}
```
輸出:
```
s size:24
```
與預想顯然不同,這是為什麼呢?答案是編譯器替我們做了記憶體對齊。
# 二、什麼是記憶體對齊
要理解這個問題需要先了解一下字長的概念以及記憶體的物理結構
## 2.1 字長
在計算器領域,對於某種特定的計算機設計而言,字(word)是用於表示其自然的資料單位的術語。在這個特定計算機中,字是其用來一次性處理事務的一個固定長度的位(bit)組。一個字的位數即為**字長**。
字長在計算機結構和操作的多個方面均有體現,**計算機中大多數暫存器(這裡應該是指通用暫存器)的大小是一個字長**。
上面這段話可能太過於概念化不太好理解,那麼請看下面的這段64位機器上的GUN彙編器語法的彙編程式碼:
```
movq (%ecx) %eax
```
這段彙編程式碼是將eax這個暫存器中的資料作為地址訪問記憶體,並將記憶體中的資料載入到eax暫存器中。
我們可以看到mov指令的字尾是`q`,意味著該指令將載入一個64位的資料到eax暫存器中,這樣一條指令可以操作一個64位的資料,說明該機器的字長為64位,同時這段程式碼能夠執行則說明我們機器上的CPU中的**eax暫存器必定是64位**的,而一條指令能夠從記憶體中載入一個64位的資料也說明了**資料匯流排的位寬也為64位**,說明了我們的CPU可以一次從記憶體中載入8個位元組的資料。
## 2.2 64位記憶體物理結構
記憶體是由若干個黑色顆粒組成的,每個記憶體顆粒叫做一個chip,每個chip是由8個bank組成,每個bank是二維平面上的矩陣,矩陣中的每個元素儲存1個位元組也就是8個bit。
對於記憶體中連續的8個位元組比如0x0000-0x0007,並非位於一個bank上,而是位於8個bank上,每個bank儲存一個位元組,8個bank像是垂直疊在一起,物理上它們並不是連續的。
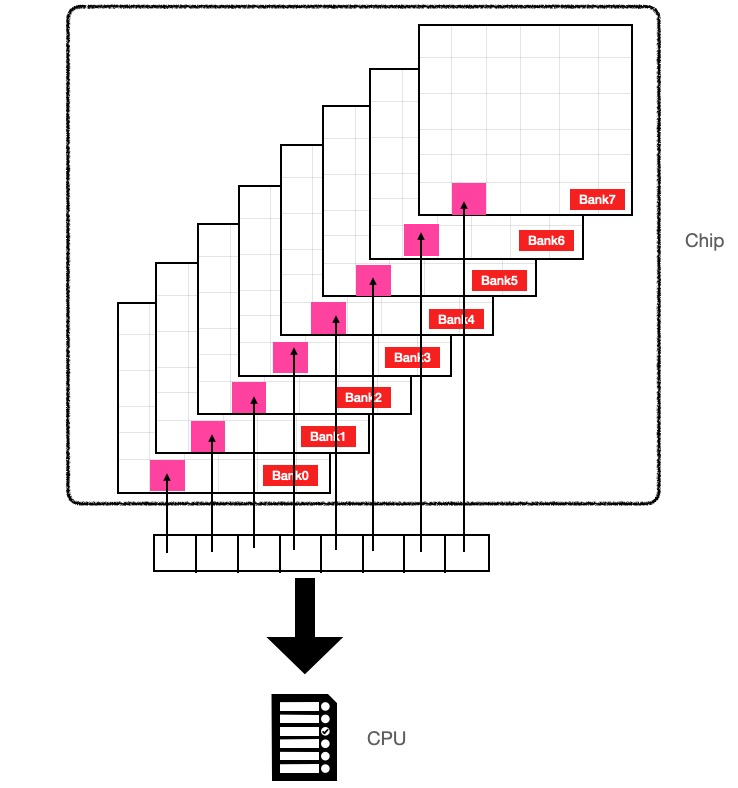
之所以這樣設計是基於電路工作效率考慮,這樣的設計可以並行取8個位元組的資料,如果想取址0x0000-0x0007,每個bank只需要工作一次就可以取到,IO效率比較高,如果這8個位元組在同一個bank上則需要序列讀取該bank8次才能取到。
結合上面的結構圖可以看到0x0000-0x0007是一列,0x0008-0x000F是另外一列,如果從記憶體中取8-15位元組的資料也可以一次取出來,但如果我們要取1-9的資料就需要先取0-7的資料,再取8-15的資料然後拼起來,這樣的話就會產生兩次記憶體IO。所以基於效能的考慮某些CPU會強制只能讀取8的倍數的記憶體,而這也導致了編譯器再此類平臺上編譯時**必須**做記憶體對齊。
## 2.3 再來看結構體size的問題
> 以下均以64位平臺,即:64位寬記憶體以及64位cpu(資料匯流排64位,暫存器64位)為前提
```
type S struct {
B byte
I64 int64
I32 int32
}
```
在不瞭解記憶體對齊前我們可能會簡單以為結構體在記憶體中可能是這樣排列的:
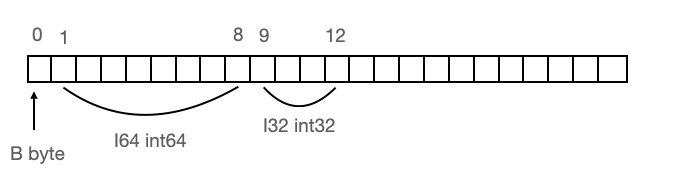
總共佔用13個位元組。我們可以看到 `I64` 這個欄位的記憶體地址是1-8,而在64位平臺上為了將這個欄位載入到暫存器中,CPU需要兩次記憶體IO。
但做記憶體對齊後:
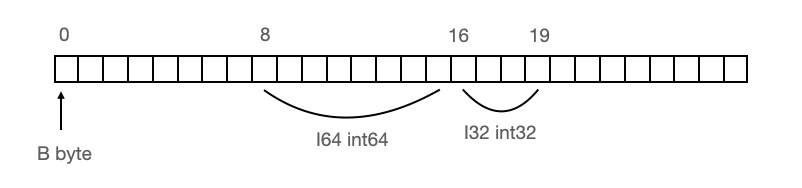
總共佔用20個位元組,`I64`這個欄位的記憶體地址是8-15,為了將這個欄位載入到暫存器中,只需要一次記憶體IO即可。
我們寫段程式碼驗證下是否真的佔用了20個位元組:
```
type S struct {
B byte
I64 int64
I32 int32
}
func main() {
s := S{}
fmt.Printf("s size: %d, align: %d\n", unsafe.Sizeof(s), unsafe.Alignof(s))
}
```
輸出:
```
s size: 24, align: 8
```
程式輸出了24,而非上面我們以為的20,這是怎麼回事呢?原因是**結構體本身也必須要做對齊**,它必須在後面再額外佔用4個位元組以使自己的size為8的倍數。
```
上面的結構體如果後面跟一個4位元組的變數的話理論上說不用對齊也能保證一次記憶體IO就可載入,所以結構體對齊的根本原因目前我還不是特別能理解,可能為編譯器做的優化,瞭解的同學歡迎在評論區指點一下
```
我們再調整下結構體的宣告:
```
type S struct {
B byte
I32 int32
I64 int64
}
```
再做記憶體對齊的話該結構體在記憶體中應該就是下面這個樣子了:
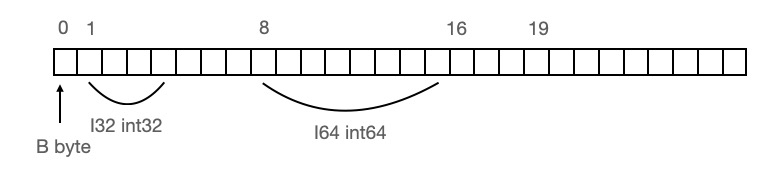
這時總共佔用16個位元組,相比較上面我們節省了8個位元組。
寫段程式碼驗證下:
```
type S struct {
B byte
I32 int32
I64 int64
}
func main() {
s := S{}
fmt.Printf("s size:%v, s.B地址:%v, s.I32地址:%v, s.I64地址:%v\n", unsafe.Sizeof(s), &s.B, &s.I32, &s.I64)
}
```
輸出結果:
```
s size:16, s.B地址:0xc0000b4010, s.I32地址:0xc0000b4014, s.I64地址:0xc0000b4018
```
確實佔用了16位元組,但貌似`I32`這個欄位跟我們預想的不太一樣,它被對齊到了4的倍數地址上,而非緊跟在`B`後邊,這大概是編譯器考慮到使用者可能使用32位cpu/記憶體而導致的,目前沒有查到相關資料姑且這麼認為吧。
# 參考資料
[字 (計算機)](https://zh.wikipedia.org/wiki/%E5%AD%97_(%E8%AE%A1%E7%AE%97%E6%9C%BA))
[帶你深入理解記憶體對齊最底層原理
](https://zhuanlan.zhihu.com/p/8