【Elasticsearch 技術分享】—— 十張圖帶大家看懂 ES 原理 !明白為什麼說:ES 是準實時的!
阿新 • • 發佈:2020-11-08
> **前言**
>
>
> 說到 Elasticsearch ,其中最明顯的一個特點就是 *near real-time* 準實時 —— 當文件儲存在Elasticsearch中時,將在1秒內以幾乎實時的方式對其進行索引和完全搜尋。那為什麼說 ES 是準實時的呢?
>
>
> 公眾號:『 劉志航 』,記錄工作學習中的技術、開發及原始碼筆記;時不時分享一些生活中的見聞感悟。歡迎大佬來指導!
### Lucene 和 ES
#### Lucene
Lucene 是 Elasticsearch所基於的 Java 庫,它引入了按段搜尋的概念。
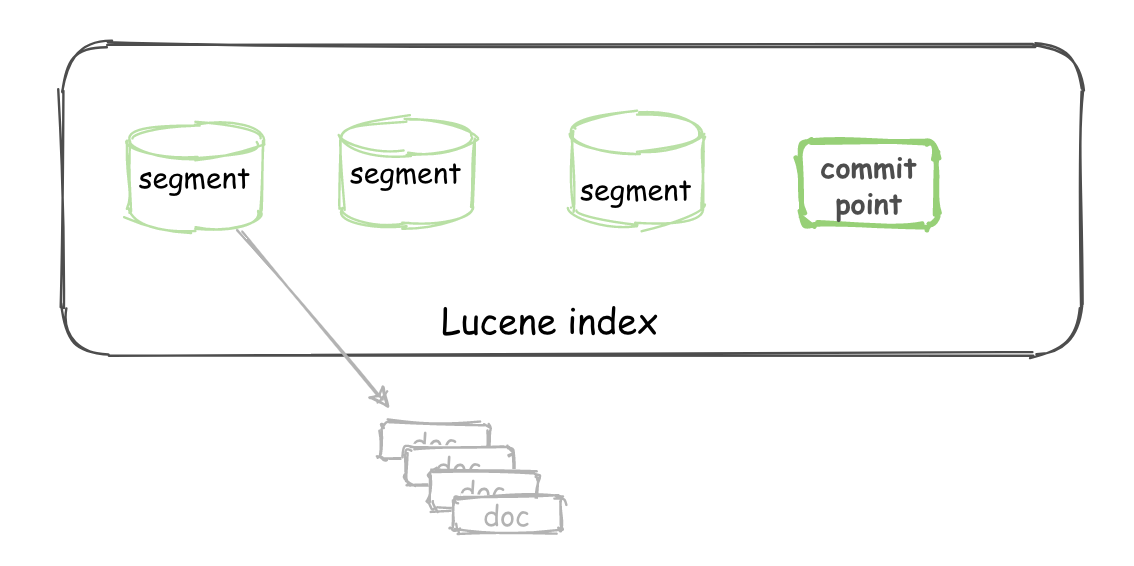
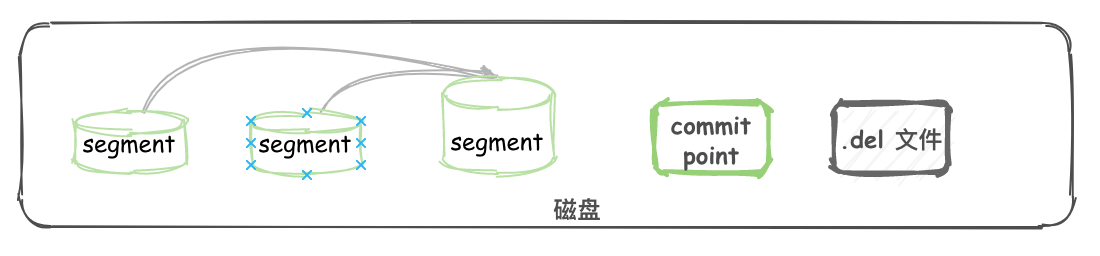
Segment: 也叫段,類似於倒排索引,相當於一個數據集。
Commit point:提交點,記錄著所有已知的段。
Lucene index: “a collection of segments plus a commit point”。由一堆 Segment 的集合加上一個提交點組成。
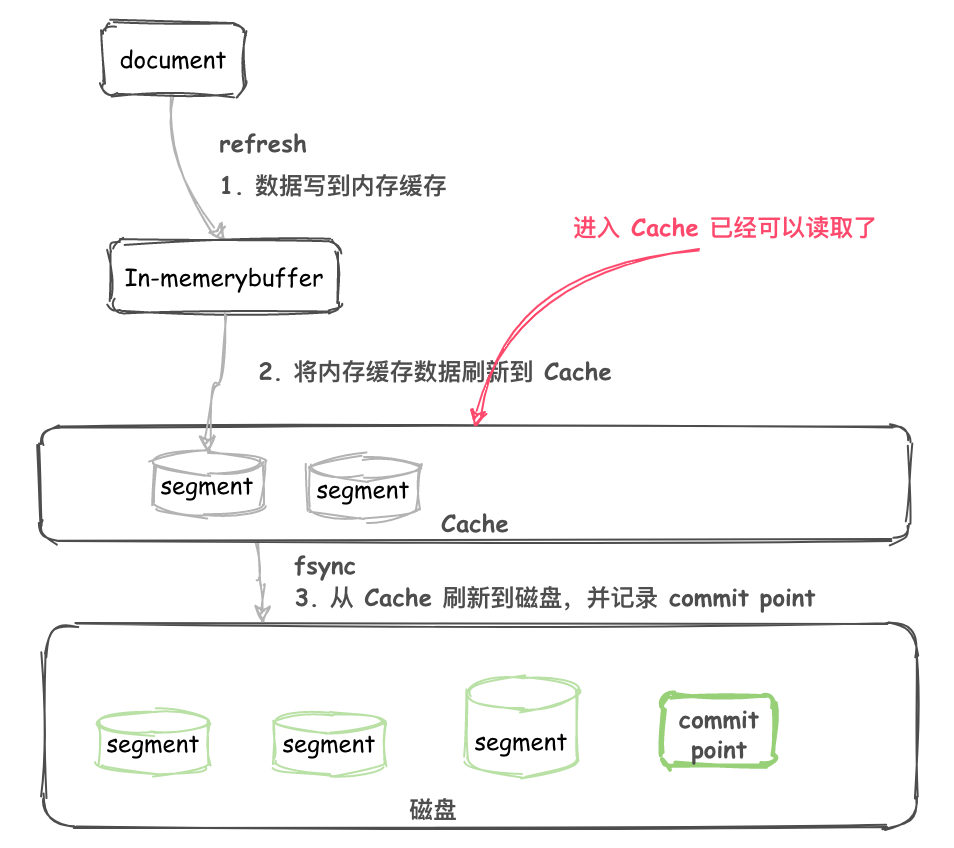
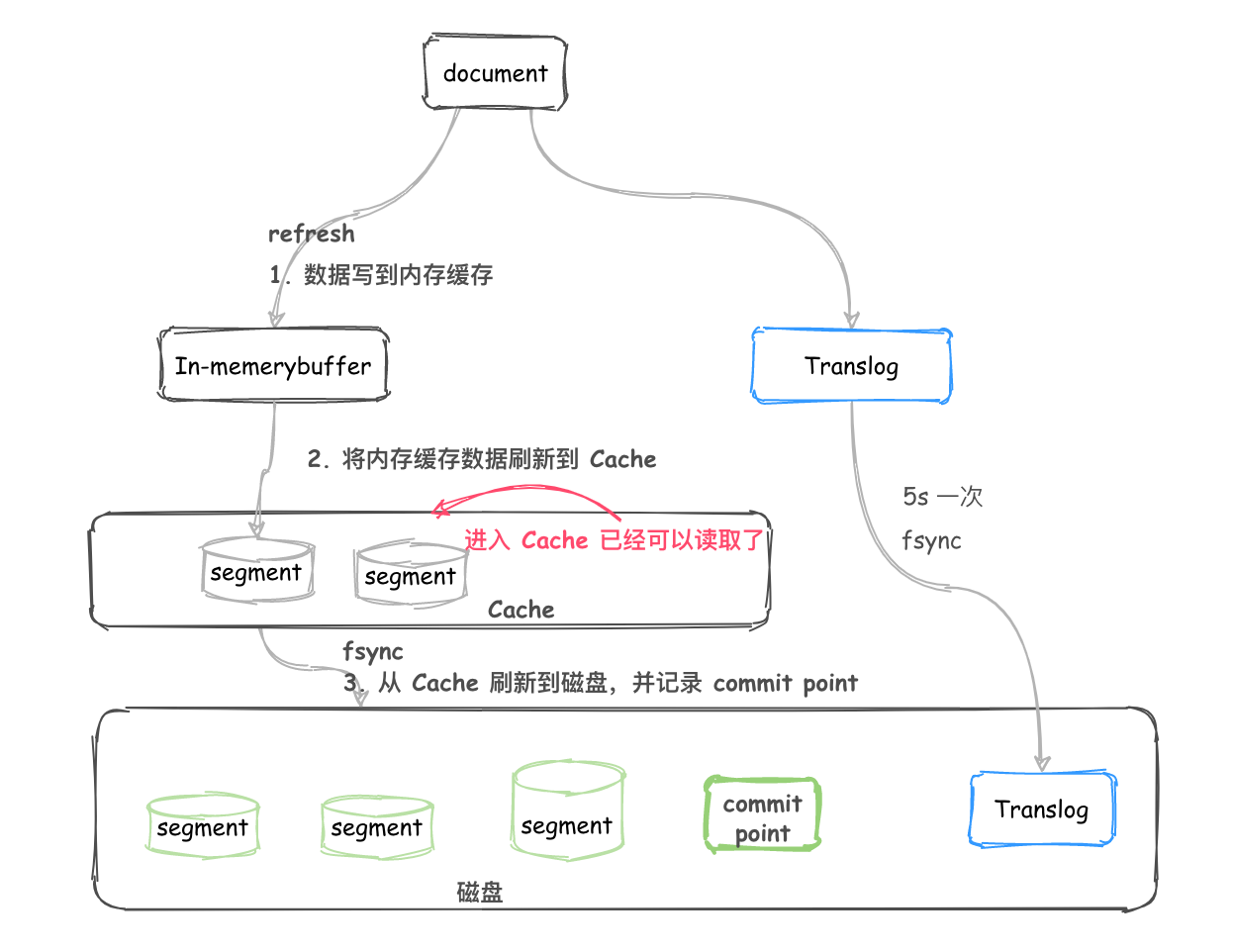
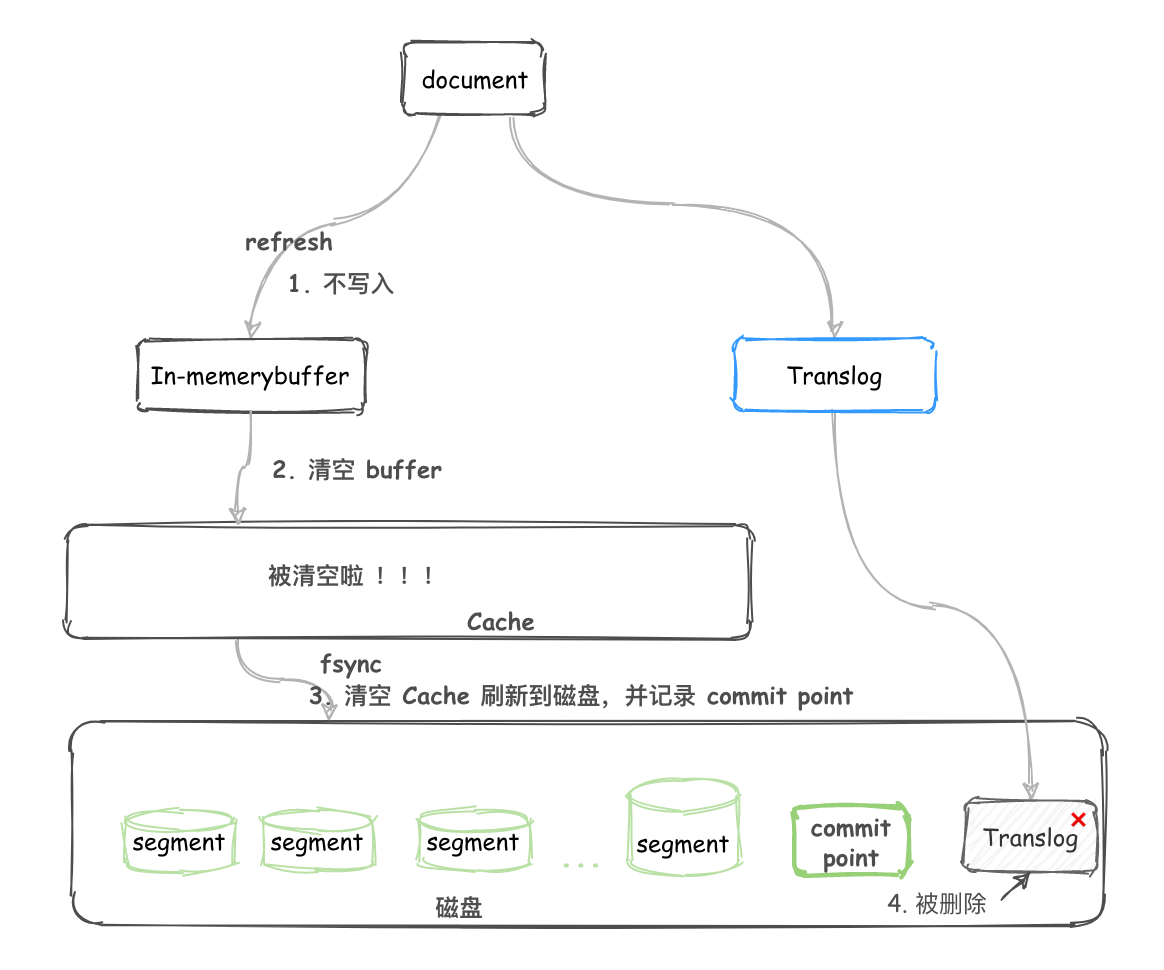
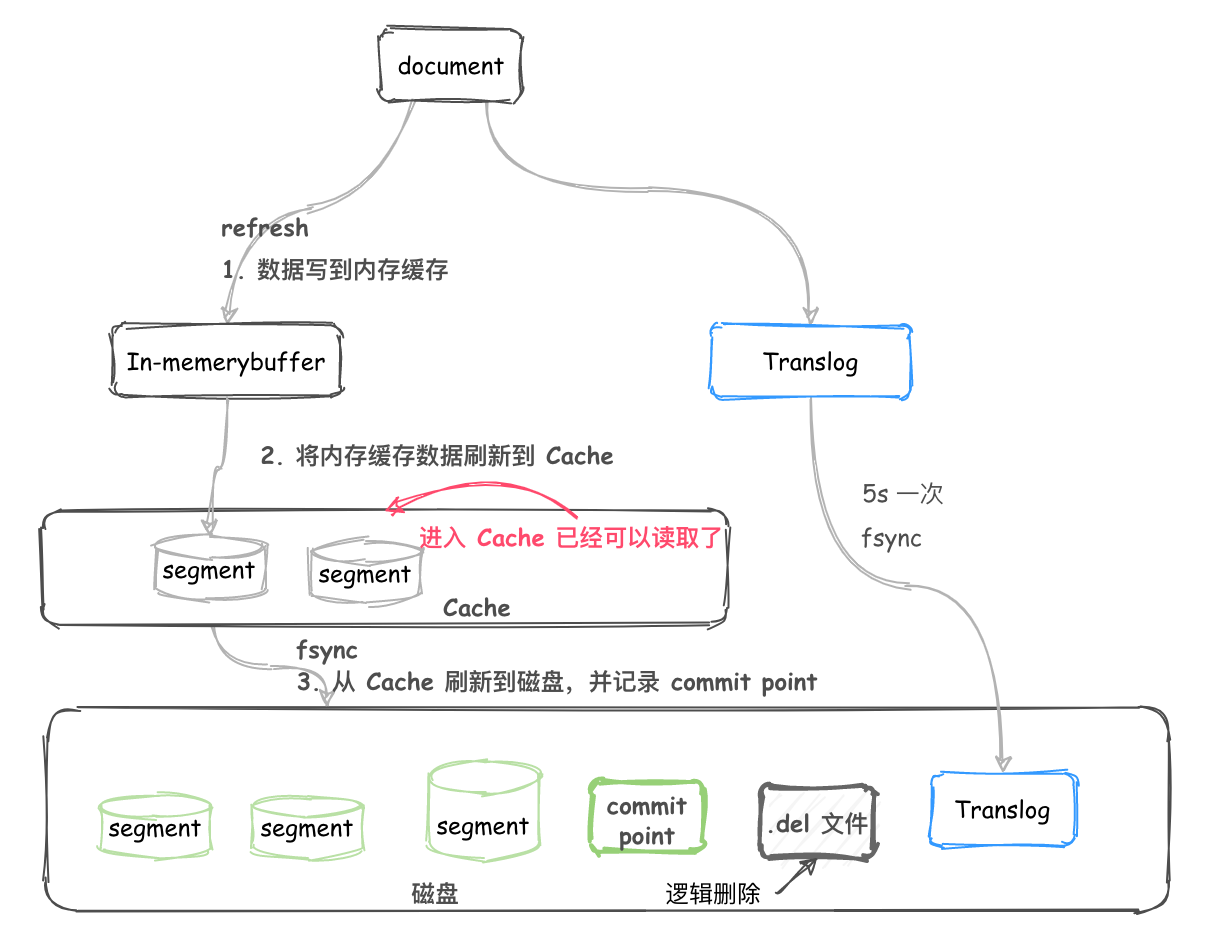
對於一個 Lucene index 的組成,如下圖所示。