
監控系統選型,這篇不可不讀!
阿新 • • 發佈:2020-11-10
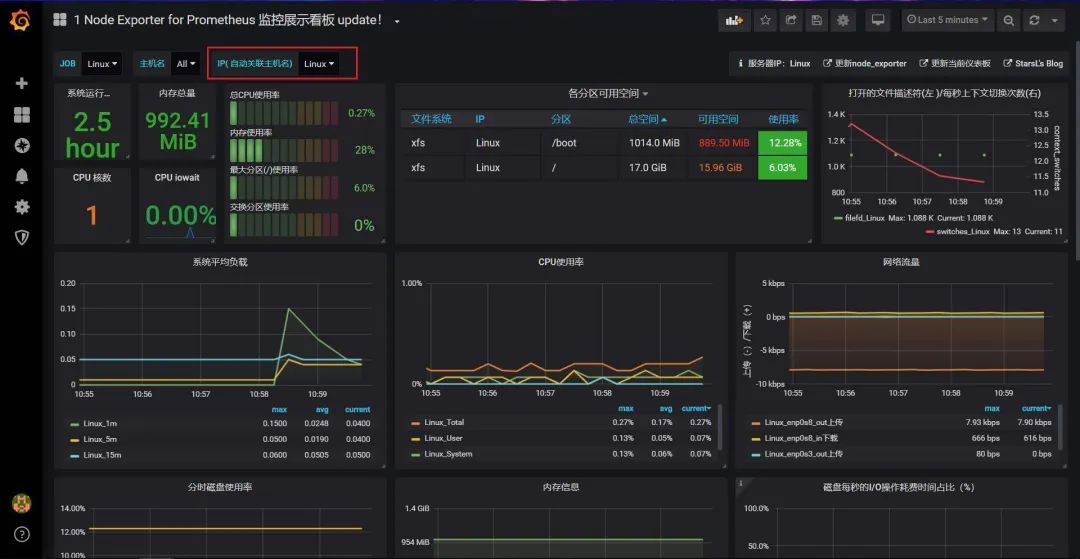
之前,我寫過幾篇有關「線上問題排查」的文章,文中附帶了一些監控圖,有些讀者對此很感興趣,問我監控系統選型上有沒有好的建議?
目前我所經歷的幾家公司,監控系統都是自研的。其實業界有很多優秀的開源產品可供選擇,能滿足絕大部分的監控需求,如果能從中選擇一款滿足企業當下的訴求,顯然最省時省力。
這篇文章,我將對監控體系的基礎知識、原理和架構做一次系統性整理,同時還會對幾款最常用的開源監控產品做下介紹,以便大家選型時參考。內容包括3部分:
- 必知必會的監控基礎知識
- 主流監控系統介紹
- 監控系統的選型建議
# 01 必知必會的監控基礎知識
監控系統俗稱「第三隻眼」,幾乎是我們每天都會打交道的系統,下面 4 項基礎知識我認為是必須要了解的。
## 1. 監控系統的7大作用
正所謂「無監控,不運維」,監控系統的地位不言而喻。不管你是監控系統的開發者還是使用者,首先肯定要清楚:監控系統的目標是什麼?它能發揮什麼作用?

- **實時採集監控資料**:包括 硬體、作業系統、中介軟體、應用程式等各個維度的資料。
- **實時反饋監控狀態**:通過對採集的資料進行多維度統計和視覺化展示,能實時體現監控物件的狀態是正常還是異常。
- **預知故障和告警:** 能夠提前預知故障風險,並及時發出告警資訊。
- **輔助定位故障**:提供故障發生時的各項指標資料,輔助故障分析和定位。
- **輔助效能調優**:為效能調優提供資料支援,比如慢SQL,介面響應時間等。
- **輔助容量規劃**:為伺服器、中介軟體以及應用叢集的容量規劃提供資料支撐。
- **輔助自動化運維**:為自動擴容或者根據配置的SLA進行服務降級等智慧運維提供資料支撐。
## 2. 使用監控系統的正確姿勢
> 出任何線上事故,先不說其他地方有問題,監控部分一定是有問題的。
聽著很甩鍋的一句話,仔細思考好像有一定道理。我們在事故覆盤時,通常會思考這3個和監控有關的問題:有沒有做監控?監控是否及時?監控資訊是否有助於快速定位問題?
可見光有一套好的監控系統還不夠,還必須知道 **「如何用好它」。一個成熟的研發團隊通常會定一個監控規範,用來統一監控系統的使用方法**。
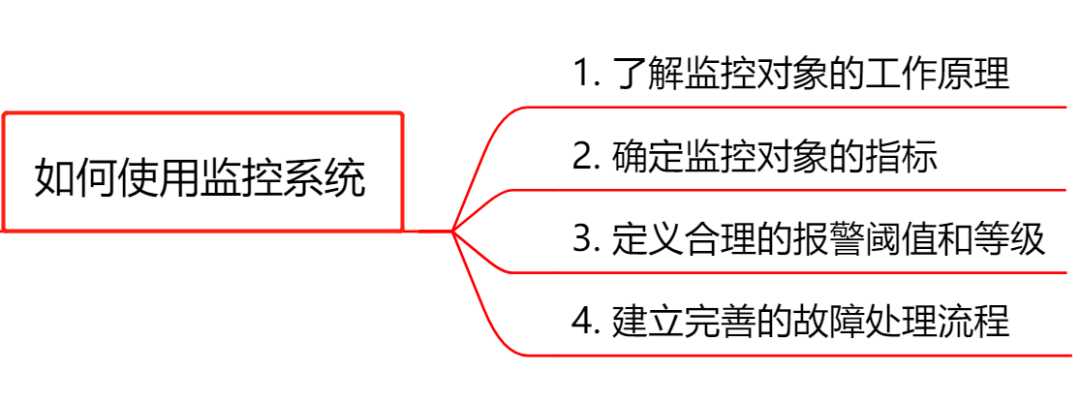
- **瞭解監控物件的工作原理**:要做到對監控物件有基本的瞭解,清楚它的工作原理。比如想對JVM進行監控,你必須清楚JVM的堆記憶體結構和垃圾回收機制。
- **確定監控物件的指標** :清楚使用哪些指標來刻畫監控物件的狀態?比如想對某個介面進行監控,可以採用請求量、耗時、超時量、異常量等指標來衡量。
- **定義合理的報警閾值和等級**:達到什麼閾值需要告警?對應的故障等級是多少?不需要處理的告警不是好告警,可見定義合理的閾值有多重要,否則只會降低運維效率或者讓監控系統失去它的作用。
- **建立完善的故障處理流程**:收到故障告警後,一定要有相應的處理流程和oncall機制,讓故障及時被跟進處理。
## 3\. 監控的物件和指標都有哪些?
監控已然成為了整個產品生命週期非常重要的一環,運維關注硬體和基礎監控,研發關注各類中介軟體和應用層的監控,產品關注核心業務指標的監控。 可見,監控的物件已經越來越立體化。
這裡,我對常用的監控物件以及監控指標做了分類整理,供大家參考。

**3.1 硬體監控**
包括:電源狀態、CPU狀態、機器溫度、風扇狀態、物理磁碟、raid狀態、記憶體狀態、網絡卡狀態
**3.2 伺服器基礎監控**
- CPU:單個CPU以及整體的使用情況
- 記憶體:已用記憶體、可用記憶體
- 磁碟:磁碟使用率、磁碟讀寫的吞吐量
- 網路:出口流量、入口流量、TCP連線狀態
**3.3 資料庫監控**
包括:資料庫連線數、QPS、TPS、並行處理的會話數、快取命中率、主從延時、鎖狀態、慢查詢
**3.4 中介軟體監控**
- Nginx:活躍連線數、等待連線數、丟棄連線數、請求量、耗時、5XX錯誤率
- Tomcat:最大執行緒數、當前執行緒數、請求量、耗時、錯誤量、堆記憶體使用情況、GC次數和耗時
- 快取 :成功連線數、阻塞連線數、已使用記憶體、記憶體碎片率、請求量、耗時、快取命中率
- 訊息佇列:連線數、佇列數、生產速率、消費速率、訊息堆積量
**3.5 應用監控**
- HTTP介面:URL存活、請求量、耗時、異常量
- RPC介面:請求量、耗時、超時量、拒絕量
- JVM :GC次數、GC耗時、各個記憶體區域的大小、當前執行緒數、死鎖執行緒數
- 執行緒池:活躍執行緒數、任務佇列大小、任務執行耗時、拒絕任務數
- 連線池:總連線數、活躍連線數
- 日誌監控:訪問日誌、錯誤日誌
- 業務指標:視業務來定,比如PV、訂單量等
## 4. 監控系統的基本流程
無論是開源的監控系統還是自研的監控系統,監控的整個流程大同小異,一般都包括以下模組:
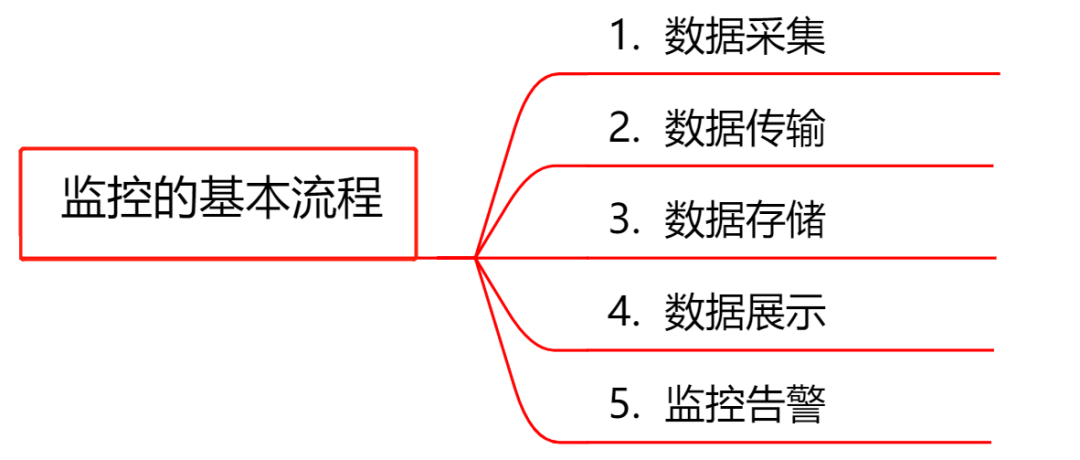
- **資料採集**:採集的方式有很多種,包括 日誌埋點進行採集(通過Logstash、Filebeat等進行上報和解析), JMX標準介面輸出監控指標,被監控物件提供REST API進行資料 採集(如Hadoop、ES),系統命令列,統一的SDK進行侵入式的埋點和上報等。
- **資料傳輸**:將採集的資料以TCP、UDP或者HTTP協議的形式上報給監控系統,有主動Push模式,也有被動Pull模式。
- **資料儲存**:有使用MySQL、Oracle等RDBMS儲存的,也有使用時序資料庫RRDTool、OpentTSDB、InfluxDB儲存的,還有使用HBase儲存的。
- **資料展示**:資料指標的圖形化展示。
- **監控告警**:靈活的告警設定,以及支援郵件、簡訊、IM等多種通知通道。
# 02 主流監控系統介紹
下面再來認識下主流的開源監控系統,由於篇幅有限,我挑選了3款使用最廣泛的監控系統:Zabbix、Open-Falcon、Prometheus,會對它們的架構進行介紹,同時總結下各自的優劣勢。
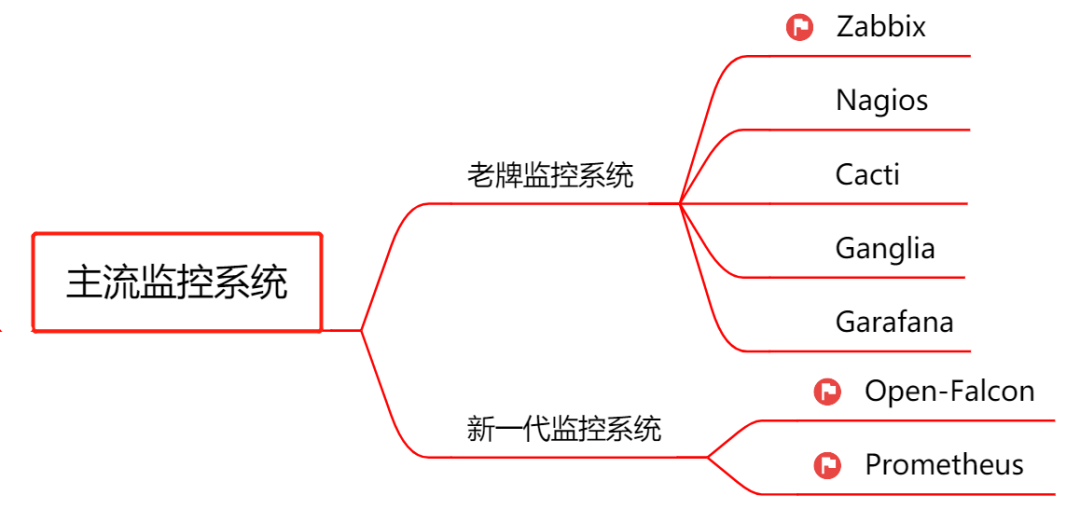
## 1\. Zabbix(老牌監控的優秀代表)
Zabbix 1998年誕生,核心元件採用C語言開發,Web端採用PHP開發。它屬於老牌監控系統中的優秀代表,監控功能很全面,使用也很廣泛,差不多有70%左右的網際網路公司都曾使用過 Zabbix 作為監控解決方案。
先來了解下Zabbix的架構設計:
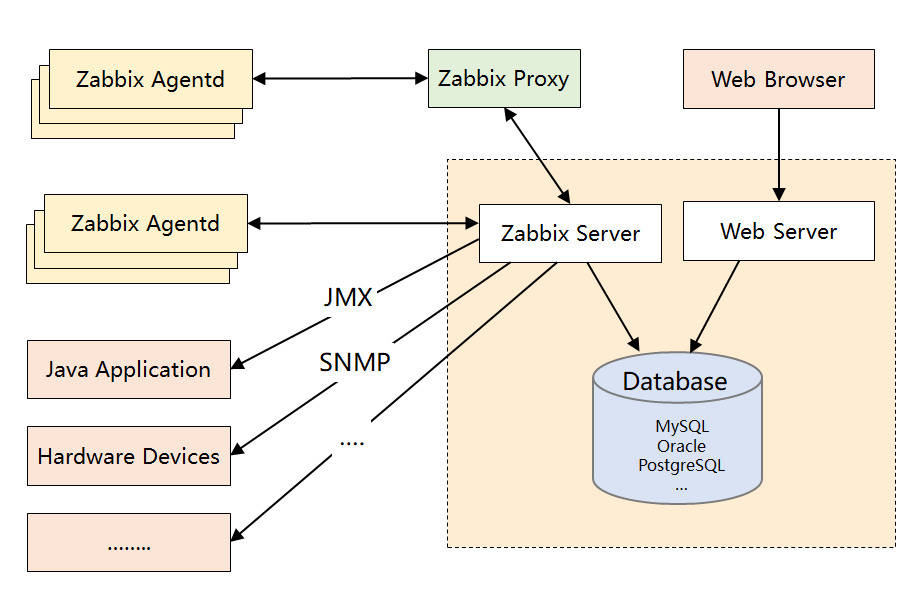
- **Zabbix Server**:核心元件,C語言編寫,負責接收Agent、Proxy傳送的監控資料,也支援JMX、SNMP等多種協議直接採集資料。同時,它還負責資料的彙總儲存以及告警觸發等。
- **Zabbix Proxy**:可選元件,對於被監控機器較多的情況下,可使用Proxy進行分散式監控,它能代理Server收集部分監控資料,以減輕Server的壓力。
- **Zabbix Agentd**:部署在被監控主機上,用於採集本機的資料併發送給Proxy或者Server,它的外掛機制支援使用者自定義資料採集指令碼。Agent可在Server端手動配置,也可以通過自動發現機制被識別。資料收集方式同時支援主動Push和被動Pull 兩種模式。
- **Database**:用於儲存配置資訊以及採集到的資料,支援MySQL、Oracle等關係型資料庫。同時,最新版本的Zabbix已經開始支援時序資料庫,不過成熟度還不高。
- **Web Server**:Zabbix的GUI元件,PHP編寫,提供監控資料的展現和告警配置。
下面是 Zabbix 的優勢:
- **產品成熟**:由於誕生時間長且使用廣泛,擁有豐富的文件資料以及各種開源的資料採集外掛,能覆蓋絕大部分監控場景。
- **採集方式豐富**:支援Agent、SNMP、JMX、SSH等多種採集方式,以及主動和被動的資料傳輸方式。
- **較強的擴充套件性**:支援Proxy分散式監控,有agent自動發現功能,外掛式架構支援使用者自定義資料採集指令碼。
- **配置管理方便** :能通過Web介面進行監控和告警配置,操作方便,上手簡單。
下面是 Zabbix 的劣勢:
- **效能瓶頸**:機器量或者業務量大了後,關係型資料庫的寫入一定是瓶頸,官方給出的單機上限是5000臺,個人感覺達不到,尤其現在應用層的指標越來越多。雖然最新版已經開始支援時序資料庫,不過成熟度還不高。
- **應用層監控支援有限**:如果想對應用程式做侵入式的埋點和採集(比如監控執行緒池或者介面效能),zabbix沒有提供對應的sdk,通過外掛式的指令碼也能曲線實現此功能,個人感覺zabbix就不是做這個事的。
- **資料模型不強大**:不支援tag,因此沒法按多維度進行聚合統計和告警配置,使用起來不靈活。
- **方便二次開發難度大** :Zabbix採用的是C語言,二次開發往往需要熟悉它的資料表結構,基於它提供的API更多隻能做展示層的定製。
## 2. Open-Falcon(小米出品,國內流行)
Open-falcon 是小米2015年開源的企業級監控工具,採用Go和Python語言開發,這是一款靈活、高效能且易擴充套件的新一代監控方案,目前小米、美團、滴滴等超過200家公司在使用它。
小米初期也使用的Zabbix進行監控,但是機器量和業務量上來後,Zabbix就有些力不從心了。因此,後來自主研發了Open-Falcon,在架構設計上吸取了Zabbix的經驗,同時很好地解決了Zabbix的諸多痛點。
先來了解下Open-Falcon的架構設計:
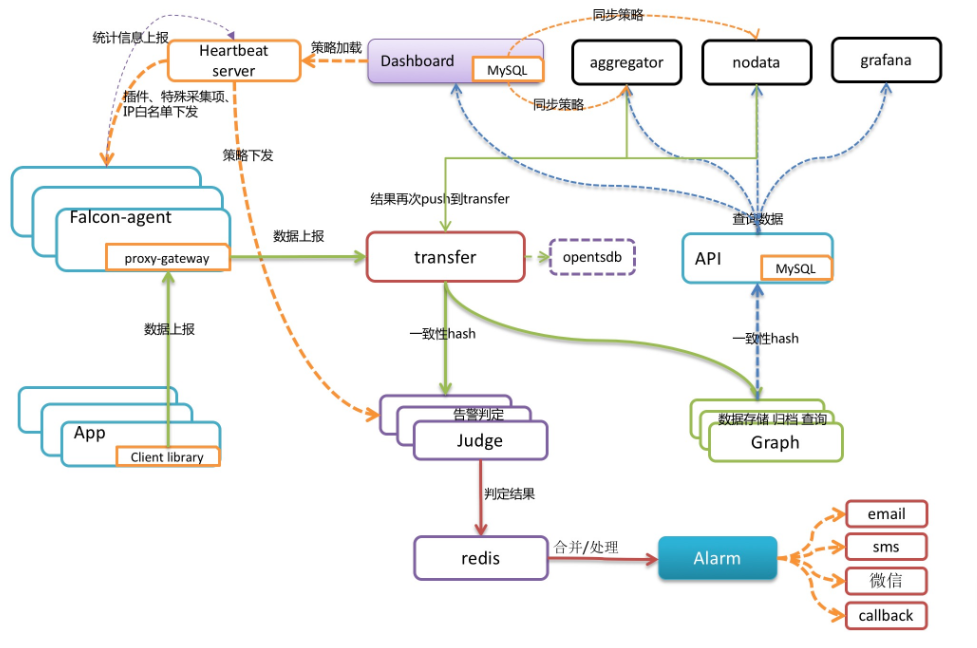
- **Falcon-agent**:資料採集器和收集器,Go開發,部署在被監控的機器上,支援3種資料採集方式。首先它能自動採集單機200多個基礎監控指標,無需做任何配置;同時支援使用者自定義的plugin獲取監控資料;此外,使用者可通過http介面,自主push資料到本機的proxy-gateway,由gateway轉發到server.
- **Transfer**:資料分發元件,接收客戶端傳送的資料,分別傳送給資料儲存元件Graph和告警判定元件Judge,Graph和Judge均採用一致性hash做資料分片,以提高橫向擴充套件能力。同時Transfer還支援將資料分發到OpenTSDB,用於歷史歸檔。
- **Graph**:資料儲存元件,底層使用RRDTool(時序資料庫)做單個指標的儲存,並通過快取、分批寫入磁碟等方式進行了優化。據說一個graph例項能夠處理8W+每秒的寫入速率。
- **Judge和Alarm**:告警元件,Judge對Transfer元件上報的資料進行實時計算,判斷是否要產生告警事件,Alarm元件對告警事件進行收斂處理後,將告警訊息推送給各個訊息通道。
- **API**:面向終端使用者,收到查詢請求後會去Graph中查詢指標資料,彙總結果後統一返回給使用者,遮蔽了儲存叢集的分片細節。
下面是Open-Falcon的優勢:
- **自動採集能力**:**Falcon-agent 能自動採集伺服器的200多個基礎指標(比如CPU、記憶體等),無需在server上做任何配置,這一點可以秒殺Zabbix.
- **強大的儲存能力** :底層採用RRDTool,並且通過一致性hash進行資料分片,構建了一個分散式的時序資料儲存系統,可擴充套件性強。
- **靈活的資料模型**:借鑑OpenTSDB,資料模型中引入了tag,這樣能支援多維度的聚合統計以及告警規則設定,大大提高了使用效率。
- **外掛統一管理**:Open-Falcon的外掛機制實現了對使用者自定義指令碼的統一化管理,可通過HeartBeat Server分發給agent,減輕了使用者自主維護指令碼的成本。
- **個性化監控支援**:基於Proxy-gateway,很容易通過自主埋點實現應用層的監控(比如監控介面的訪問量和耗時)和其他個性化監控需求,整合方便。
下面是Open-Falcon的劣勢:
- **整體發展一般****:**社群活躍度不算高,同時版本更新慢,有些大廠是基於它的穩定版本直接做二次開發的,關於以後的前景其實有點擔憂。
- **UI不夠友好** :對於業務線的研發來說,可能只想便捷地完成告警配置和業務監控,但是它把機器分組、策略模板、模板繼承等概念全部暴露在UI上,感覺在圍繞這幾個概念設計UI,理解有點費勁。
- **安裝比較複雜:**個人的親身感受,由於它是從小米內部衍生出來的,雖然去掉了對小米內部系統的依賴,但是元件還是比較多,如果對整個架構不熟悉,安裝很難一蹴而就。
## 3. Prometheus(號稱下一代監控系統)

Prometheus(普羅米修斯)是由前google員工2015年正式釋出的開源監控系統,採用Go語言開發。它不僅有一個很酷的名字,同時它有Google與k8s的強力支援,開源社群異常火爆。
Prometheus 2016年加入雲原生基金會,是繼k8s後託管的第二個專案,未來前景被相當看好。它和Open-Falcon最大不同在於:資料採集是基於Pull模式的,而不是Push模式,並且架構非常簡單。
先來了解下Prometheus的架構設計:

- **Prometheus Server**:核心元件,用於收集、儲存監控資料。它同時支援靜態配置和通過Service Discovery動態發現來管理監控目標,並從監控目標中獲取資料。此外,Prometheus Server 也是一個時序資料庫,它將監控資料儲存在本地磁碟中,並對外提供自定義的 PromQL 語言實現對資料的查詢和分析。
- **Exporter**:用來採集資料,作用類似於agent,區別在於Prometheus是基於Pull方式拉取採集資料的,因此,Exporter通過HTTP服務的形式將監控資料按照標準格式暴露給Prometheus Server,社群中已經有大量現成的Exporter可以直接使用,使用者也可以使用各種語言的client library自定義實現。
- **Push gateway**:主要用於瞬時任務的場景,防止Prometheus Server來pull資料之前此類Short-lived jobs就已經執行完畢了,因此job可以採用push的方式將監控資料主動彙報給Push gateway快取起來進行中轉。
- **Alert Manager**:當告警產生時,Prometheus Server將告警資訊推送給Alert Manager,由它傳送告警資訊給接收方。
- **Web UI**:Prometheus內建了一個簡單的web控制檯,可以查詢配置資訊和指標等,而實際應用中我們通常會將Prometheus作為Grafana的資料來源,建立儀表盤以及檢視指標。
下面是Prometheus的優勢:
- **輕量管理**:架構簡單,不依賴外部儲存,單個伺服器節點可直接工作,二進位制檔案啟動即可,屬於輕量級的Server,便於遷移和維護。
- **較強的處理能力**:監控資料直接儲存在Prometheus Server本地的時序資料庫中,單個例項可以處理數百萬的metrics。
- **靈活的資料模型**:同Open-Falcon,引入了tag,屬於多維資料模型,聚合統計更方便。
- **強大的查詢語句**:PromQL允許在同一個查詢語句中,對多個metrics進行加法、連線和取分位值等操作。
- **很好地支援雲環境**:能自動發現容器,同時k8s和etcd等專案都提供了對Prometheus的原生支援,是目前容器監控最流行的方案。
下面是Prometheus的劣勢:
- **功能不夠完善**:Prometheus從一開始的架構設計就是要做到簡單,不提供叢集化方案,長期的持久化儲存和使用者管理,而這些是企業變大後所必須的特性,目前要做到這些只能在Prometheus之上進行擴充套件。
- **網路規劃變複雜**:由於Prometheus採用的是Pull模型拉取資料,意味著所有被監控的endpoint必須是可達的,需要合理規劃網路的安全配置。
# 03 監控系統的選型建議
通過上面的介紹,大家對主流的監控系統應該有了一定的認識。面對選型問題,我的建議是:
1、先明確清楚你的監控需求:要監控的物件有哪些?機器數量和監控指標有多少?需要具備什麼樣的告警功能?
2、監控是一項長期建設的事情,一開始就想做一個 All In One 的監控解決方案,我覺得沒有必要。從成本角度考慮,在初期直接使用開源的監控方案即可,先解決有無問題。
3、從系統成熟度上看,Zabbix屬於老牌的監控系統,資料多,功能全面且穩定,如果機器數量在幾百臺以內,不用太擔心效能問題,另外,採用資料庫分割槽、SSD硬碟、Proxy架構、Push採集模式都可以提高監控效能。
4、Zabbix在伺服器監控方面佔絕對優勢,可以滿足90%以上的監控場景,但是應用層的監控似乎並不擅長,比如要監控執行緒池的狀態、某個內部介面的執行時間等,這種通常都要做侵入式埋點。相反,新一代的監控系統Open-Falcon和Prometheus在這一點做得很好。
5、從整體表現上來看,新一代監控系統也有明顯的優勢,比如:靈活的資料模型、更成熟的時序資料庫、強大的告警功能,如果之前對zabbix這種傳統監控沒有技術積累,建議使用Open-Falcon或者Prometheus.
6、Open-Falcon的核心優勢在於資料分片功能,能支撐更多的機器和監控項;Prometheus則是容器監控方面的標配,有Google和k8s加持。
7、Zabbix、Open-Falcon和Prometheus都支援和Grafana做快速整合,想要美觀且強大的視覺化體驗,可以和Grafana進行組合。
8、用合適的監控系統解決相應的問題即可,可以多套監控同時使用,這種在企業初期很常見。
9、到中後期,隨著機器資料增加和個性化需求增多(比如希望統一監控平臺、打通公司的CMDB和組織架構關係),往往需要二次開發或者通過監控系統提供的API做整合,從這點來看,Open-Falcon或者Prometheus更合適。
10、如果非要自研,可以多研究下主流監控系統的架構方案,借鑑它們的優勢。
# 寫在最後
本文對監控體系的基礎知識、原理和主流架構做了詳細梳理,希望有助於大家對監控系統的認識,以及在技術選型時做出更合適的選擇。
由於篇幅問題,本文的內容並未涉及到全鏈路監控、日誌監控、以及Web前端和客戶端的監控,可見監控真的是一個龐大且複雜的體系,如果想理解透徹,必須理論結合實踐再做深入。
對於運維監控體系,如果你們也有自己的經驗和體會,歡迎留言討論。
作者簡介:985碩士,前亞馬遜工程師,現58轉轉技術總監
**歡迎掃描下方的二維碼,關注我的個人公眾號:IT人的職場進階**
