
MYSQL學習(二) --MYSQL框架
MYSQL架構理解
通過對MYSQL重要的幾個屬性的理解,建立一個基本的MYSQL的知識框架。後續再補充完善。
一、MYSQL架構
這裡給的架構描述,是很巨集觀的架構。有助於建立對MYSQL整體理解。
1. 架構圖
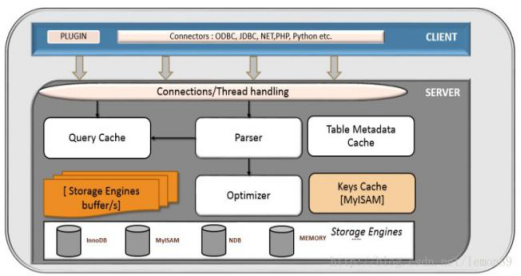
以下是在網上找的兩張MYSQL架構圖。能反映MYSQL的結構。
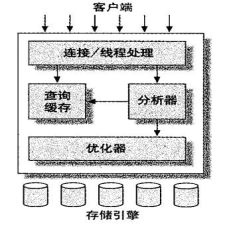
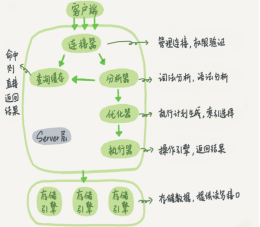
結構基本一致,都是連線、服務和儲存引擎三部分。
2.分層實現
MYSQL大致分為3個層次。連線層、服務層和引擎層。連線層功能是客戶端的連結服務。服務層完成快取查詢、SQL分析、SQL優化。引擎層真正負責MYSQL資料的儲存和提取。
1.連線層
核心功能是完成客戶端的連結安全服務。負責一些連線處理、授權認證以及相關安全方案。該層提供了執行緒池功能。為通過安全認證的客戶端提供執行緒。
驗證主要是使用者名稱、密碼的驗證。
2.服務層
服務層提供的服務包括查詢的解析、分析(語法、語義)、優化(SQL)、快取查詢、內建函式(日期、數學、時間、加密)、跨儲存引擎的功能(儲存過程、觸發器、檢視)等。
3.引擎層
儲存引擎層主要負責資料的儲存和提取。伺服器通過API和引擎層進行通訊。
核心需要了解的引擎有InnoDB和MyISAM兩種引擎。絕大多數情況下都選擇使用使用InnoDB引擎。
- InnoDB:支援事務、支援行表鎖(高併發友好-行鎖更好的支援併發)、支援主外來鍵、不支援全文檢索。
- MyISAM:支援全文檢索、不支援事務、只支援表鎖(對併發不好--操作一條資料就需要鎖住整張表)。
3.查詢元件
按照查詢過程,描述各元件的功能。
1.聯結器
管理資料庫連結、許可權驗證。
2.使用者許可權是連結時刻的使用者許可權
一個使用者成功建立
連線後,即使你用管理員賬號對這個使用者的許可權做了修改,也不會影響已經存在連線的許可權。修改完成後,只有再新建的連線才會使用新的許可權設定。
- 連結
連結過程比較麻煩,通常使用長連結。
(1) 長連結
如果客戶端和服務端連結上之後,客戶端有持續的請求,則一直使用同一個連結。
長連結缺點:容易佔用記憶體。在執行語句中使用的記憶體是管理在連結物件中的。這些資源只有在斷開連結的使用才能釋放。如果長連結時間較長,可能積累的記憶體很大,造成記憶體溢位。解決思路(定期斷開重連)。
(2)短連結
連線後執行SQL之後,斷開連結,下次使用時,重新連結。
2.查詢快取
核心思想就是看,快取中是否存在剛剛查詢過和當前一樣的SQL。如果存在,則直接使用快取資料返回。如果不存在,才執行後續的查詢步驟。缺點是:適合於靜態表。如果是動態表,資料實時發生變化。查詢以前的快取資料不準確。
- 查詢快取
建立連結後,首先是在記憶體中查詢,看之前是否執行過這條語句。之前執行過的語句可能以KEY-VALUE的形式儲存在記憶體中。KEY為查詢的語句。VALUE是查詢的結果。
(1)快取存在
直接將快取的資料返回給客戶端。
(2)快取不存在
執行後面的階段。
3.分析器
將SQL的字串轉成語法樹。過程包含詞法解析和語法解析。
(1)詞法解析
識別字符串中的SQL關鍵字和函式關鍵字。
(2)語法解析
在詞法分析基礎之上,生成語法樹。可以向後提交給優化器。
4.優化器
優化器對語法樹進行進一步優化,給出更合理的執行計劃。從而提高SQL的執行效率。
比如:多個表JOIN的時候,決定表的關聯順序。多個索引時,選擇使用哪個索引。
5.執行器
經過優化器優化後的語句,進入執行器階段。開始執行語句。
(1)判斷許可權
判斷使用者有沒有對錶操作的許可權。如果沒有,則直接返回該使用者沒有許可權錯誤。如果有,就繼續執行。
(2)呼叫引擎API,繼續執行
開啟表,執行器會根據表的引擎定義,去執行這個引擎提供的介面。
二、併發控制
當多個執行緒,同時修改同一張表的資料的時候,就需要併發控制。MYSQL在兩個級別實現併發控制。伺服器級(the server level)和儲存引擎級(the storage engine level)。加鎖實現併發控制。對鎖從不同的角度分析,儘量減小鎖對併發的影響。從提升併發效能的角度來分析的。
(一)、盡小可能使用互斥,盡大可能使用共享
互斥是實現同步的一種方式。也是代價比較大的一種。對併發效能影響較大。因此,對鎖分為共享鎖和互斥鎖。也是經常說的讀鎖和寫鎖。根據不同的情況,在保證正確性的前提下,儘可能使用共享鎖(讀鎖)。
1.讀鎖(共享鎖)
讀鎖允許多個連線,併發的讀取統一資源,互不干涉。讀鎖之間是共享的。不互斥。
2.寫鎖(互斥鎖、排它鎖)
一個寫鎖阻塞其它寫鎖和讀鎖。保證同一時刻只有一個連線寫入資料。同時,防止其它使用者對這個資料進行讀寫。
(二)、 粒度(盡小範圍加鎖)
在滿足邏輯正確的情況下。加鎖範圍越小,產生阻塞的可能性越小。併發的效能就越高。因此。從這個角度來分析MYSQL的鎖機制。MYSQL中分為表鎖和行級鎖。
1.表鎖
表鎖是使用者操作的過程中對整張表鎖定。只允許一個使用者對錶進行操作(插入、刪除、更新)。MYSQL獨立於儲存引擎提供表鎖,例如,對於ALTER TABLE語句,伺服器提供表鎖(table-level lock)。
表鎖是MYSQL基本的鎖策略。也是開銷最小的鎖策略(因為簡單可行)。
2.行級鎖
最大程度的支援併發處理。InnoDB支援行級鎖。指鎖定需要的幾行資料即可。也是開銷最大的所策略(需要精確的控制,代價很大)。
(三)、 多版本控制
多版本控制的核心是 讀事務不用等待鎖。從而更加提升了效能。MYSQL的MVCC的實現邏輯。
通過在每行資料後新增兩個隱藏列來實現。一個是建立時間,一個死過期時間(刪除時間)。這兩個列儲存的是系統版本號(版本號的大小體現時間的先後順序)。每開始一個新的事務,版本號都會增加。事務開始時刻的版本號作為這個事務的版本號。
MVCC的具體操作,InnoDB引擎為例
(1)INSERT
插入每行資料,建立時間為當前的系統版本號
(2)DELETE
刪除每行資料,儲存當前系統版本號為刪除時間。
(3)UPDATE
插入一行新資料。當前系統版本號為建立時間。另外,當前版本號為原來行的刪除時間
(4)SELECT
讀操作不需要等待其它鎖
查詢的時候,需要滿足一下兩個條件的資料。
- 只需要找建立時間小於或等於當前版本號的資料。(這樣能確保事務讀取的行,要麼在事務開始之前就已經存在,要麼是事務自身插入或者修改的)
- 行的刪除時間,要麼未定義,要麼大於當前版本。
符合以上兩個條件的記錄,才能作為查詢結果。
三、 事務
資料庫的事務處理原則是ACID的正確性。
(一)、事務的ACID屬性
1.原子性
一個事務被視為最小的工作單元,整個事務所有操作,要麼都執行,要麼全部回滾,都不執行。不能執行其中的一部分,任務不能分割。
2.一致性
符合邏輯,從一個一致性狀態轉換到另一個一致性狀態。
3.隔離性
提供一定的隔離機制,保證事務在執行過程中不受外部併發操作的影響。一個事務所做的修改,在提交之前,對其它事務不可見。
4.永續性
一旦事務提交,其所做的修改就會儲存到資料庫中。即事務提交後,對資料的修改是永久性的。
(二)、 隔離級別
隔離規定了,一個事務所做的修改,那些在事務內部和事務間是可見的,那些是不可見的。較低級別的隔離通常可以執行較高的併發。系統的開銷更低。
1.未提交讀 REDA UNCOMMITED
事務中的修改,即使沒有提交,對其它事務也都是可見的。
這種情況下,容易造成髒讀。
2.提交讀 READ COMMITED
一個事務中的修改,只有在事務提交之後,對其它事務才可見。換句話說,一個事務的修改,在其提交之前,對其餘事務是不可見的。
這個級別滿足隔離性的定義,也稱為不可重複讀。因為,即使在一個事務中,重複兩次查詢,可能得到不一樣的結果。
3.可重複讀 REPEATABLE READ
同一個事務中,多次讀取,記錄結果是一致的(因為同一個事務,版本號是一樣的,有版本號控制,能夠保證,多次查詢結果是一致的)。重複讀能解決髒讀的問題。
可重複讀是MYSQL預設的隔離級別。
4.可序列化 SERIALIZABLE
是隔離的最高級別。強制要求事務序列執行。是加鎖讀。

(三)、 死鎖
兩個或多個事務,在同一資源上相互佔用。並請求佔用對方佔用的資源。
(四)、MYSQL中的事務
MYSQL預設為自動提交(AUTOCOMMIT)。
1.自動提交
如果不是顯示的提交一個事務(START TRANSACTION ---COMMIT),每個查詢都會作為一個事務提交。
引數設定:set autocommit = 1;
2.手動提交
所有的查詢都是在一個事務中,直至顯示的執行commit提交或者rollback回滾,該事務才結束。
引數設定: set autocommit = 0;
(五)、 事務處理的幾個問題
由於事務的併發執行,帶來以下一些著名的問題:
1.更新丟失(Lost Update)
當兩個或多個事務選擇同一行,然後基於最初選定的值更新該行時,由於每個事務都不知道其他事務的存在,就會發生丟失更新問題--最後的更新覆蓋了由其他事務所做的更新。
2.髒讀(Dirty Reads)
一個事務正在對一條記錄做修改,在這個事務完成並提交前,這條記錄的資料就處於不一致狀態;這時,另一個事務也來讀取同一條記錄,如果不加控制,第二個事務讀取了這些"髒"資料,並據此做進一步的處理,就會產生未提交的資料依賴關係。這種現象被形象地叫做"髒讀"。
3.不可重複讀(Non-Repeatable Reads)
一個事務在讀取某些資料後的某個時間,再次讀取以前讀過的資料,卻發現其讀出的資料已經發生了改變、或某些記錄已經被刪除了!這種現象就叫做"不可重複讀"。
4.幻讀(Phantom Reads)
一個事務按相同的查詢條件重新讀取以前檢索過的資料,卻發現其他事務插入了滿足其查詢條件的新資料,這種現象就稱為"幻讀"。
四、引擎
資料庫中的引擎是真正執行SQL的元件,被MYSQL整合在內部。MYSQL是一個多引擎的資料庫管理系統。核心的有InnoDB(預設引擎)和MyISAM。
(一)、 InnoDB
MYSQL預設的儲存引擎。最大的特點是支援事務、支援行級鎖,因此能支援高併發的訪問。不支援全文索引。索引是基於聚簇索引建立的。對主鍵的查詢有很高的效能。
(二)、MyISAM
MYSQL5之前的預設儲存引擎。最大的特點是支援全文索引。但是,不支援事務,支援表鎖。併發支援性不