
論文分享:用於模型解釋的對抗不忠學習
阿新 • • 發佈:2020-11-25
## 前言
本文介紹一篇發表在 KDD 2020 的論文《Adversarial Infidelity Learning for Model Interpretation》。該工作提出了一種高效的模型無關的例項特徵選擇(IFS)方法,其目標在於解決現有IFS方法中存在的 完備性(sanity)、組合捷徑(combinatorial shortcuts)、模型可識別性(model identifiability)和資訊傳遞(information transmission)四個方面的問題。
為此,這項工作提出了三種策略:將原模型輸出作為直譯器的額外輸入,增加針對於未選中特徵的對抗學習機制以輔助學習選中特徵與目標的條件概率,將其他高效的解釋性方法作為先驗實現熱啟動。該方法在文字資料和影象資料以及時間序列資料的五個基準資料集中的四個都達到了最佳效能,在沒有達到最佳精度的資料集上也表現出接近最佳的效果,並且有著最好的魯棒性。

###### 論文連結:[Adversarial Infidelity Learning for Model Interpretation](https://arxiv.org/abs/2006.05379)
###### 程式碼連結:[MEED](https://github.com/langlrsw/MEED)
## 作者及團隊 本文是騰訊發表的一篇文章,一作分別是 Jian Liang, Bing Bai, Yuren Cao, Kun Bai. 其中 Jian Liang是來自阿里巴巴團隊的,另外三位都來自騰訊團隊。
## 背景介紹 [1] ### 模型可解釋性 #### 什麼是模型可解釋性 模型可解釋性表達了模型內在機制的透明度以及人類理解模型決策原因的難易程度,主要體現在兩個方面: - **為什麼模型會做出某種決策?**對於一個分類任務,當往模型中輸入一個樣本時會得到一個預測,模型的可解釋性幫助我們去確定模型為什麼會產生這一預測。更具體地,樣本的哪些特徵使模型做出了這一預測。 - **人類能否理解並信任這一決策?**對於任何希望模型能預期工作的人而言,模型的解釋必須是易於理解的,否則無法輕易信任模型或是對模型進行鍼對性的調整。
### 例項特徵選擇(IFS) #### IFS 是什麼 IFS全稱為Instance-wise Feature Selection,是一種經典的模型不可知(Model-agnostic)的解釋方法。該方法會為每個樣本生成一個特徵重要度的分數,這分數表明了對於某一樣本而言哪些特徵對產生對應的輸出起著至關重要的作用。
#### 理想的解釋應該有什麼屬性 - Expressiveness:這一屬性指出能獲得高分數的特徵的數量應當是較少的。一個直接的理解應該是重要特徵和不重要特徵間區分度應該較大。 - Fidelity:保真度這一屬性指出模型的輸出應當主要由高分的特徵所決定。 - Low sensitivity:低敏感這一屬性指出生成的特徵分數應該是高魯棒性的,對對抗樣本的攻擊是不敏感的。 - Sanity:這一屬性指出生成的特徵分數應當取決於被解釋的模型。需要注意的是,前面提到的LIME方法中獲得的特徵分數更多是針對於用於解釋的模型而不是針對於需要解釋的模型。
## 問題與動機 ### 問題定義 考慮一個數據集包含有$n$個獨立的樣本,其中第$i$個樣本記為 $x^i \in X \subset R^d$,資料驅動的黑盒模型 $m \in M$,模型輸出 $y^i=M(x^i)\in Y \subset R^c$。IFS問題需要構建一個直譯器$E$,它的輸出是一個特徵重要性得分向量 $z \in Z \subset R^d$。換言之,直譯器需要建立起一個對映 $E:X\times M \to Z$,但由於黑盒模型無法直接作為神經網路的輸入,因此通常使用替代對映 $E:X\times Y \to Z$。
### 動機 #### Sanity problem 直譯器選中的特徵可能是與原模型無關,而僅僅只與輸入的樣本有關。這意味著選中的特徵可能和原模型在預測中真正使用的特徵是不一致的。這要求生成的解釋具有Sanity這一屬性。
#### Combinatorial shortcuts problem 直譯器選中的特徵可能並不是良好的特徵,解釋模型可能將生成的mask作為額外的特徵以輔助資料和標籤的擬合。舉個例子,解釋模型可以對每個樣本都選擇取前半部分或後半部分進行擬合,解釋模型將會關注這種模式是否對效能有提升,而不是考慮是否是因為選擇了好的向量才使得效能提升。這要求生成的解釋需要具有Fidelity這一屬性。
#### Model identifiability problem 直譯器可能會產生多種具有相似效能的特徵組合,直譯器很難確定哪一種組合才是最好的。這要求生成的解釋需要具有Expressiveness這一屬性。
#### Information transmission problem 直譯器生成特徵得分向量的過程是無監督的,因此難以將監督資訊傳遞給直譯器,直譯器也很難利用好監督資訊,因此直譯器訓練起來難度很大。
### 解決方案 #### 將原模型輸出作為直譯器的額外訊號 現有的很多方法直接將原樣本輸入到直譯器中,這一過程沒有黑盒模型的參與,這往往會產生Sanity Problem。因此該方法將原模型的輸出也作為直譯器的一個輸入,可以加強生成的特徵得分向量與原模型間的聯絡。另外這一策略為直譯器提供了額外的資訊,這可以直譯器能學習到更多的知識,在一定程度上也能減輕Information transmission problem。
關於這一策略的表述有一些疑惑之處,利用其他模型學習到的知識的技術是比較成熟的了,比如知識蒸餾在2016年提出了,資料蒸餾在前兩年也提出了。因此SOTA的方法中應該也有應用這一策略的,但是文章中挑選了幾個沒有使用的用於說明這一策略的優越性,個人認為說服力不夠強。
#### 針對於未選中特徵的對抗學習機制(AIL) AIL機制的提出是為了解決combinatorial shortcuts problem和model identifiability problem。簡而言之,希望直譯器選中的特徵組合是足夠好且唯一的,而未選中的特徵包含的都應該是無用的資訊。基於此想法,AIL機制中增加了一個逼近器(Approximator),使用它來擬合未選中特徵和模型的輸出,直譯器的目標是使這個Approximator的精度儘可能小。
#### 基於先驗知識的暖啟動 直譯器的訓練本身存在有Information transmission problem,再加入AIL對抗學習機制後由於對抗學習的不穩定性導致模型更難以收斂。為此,論文提出整合其他高效模型的解釋和先驗用作MEED模型的暖啟動,在訓練進行到一定程度,可以學到更好的直譯器後,先驗的約束就會逐漸放寬。
## MEED Framework ### 總體框架 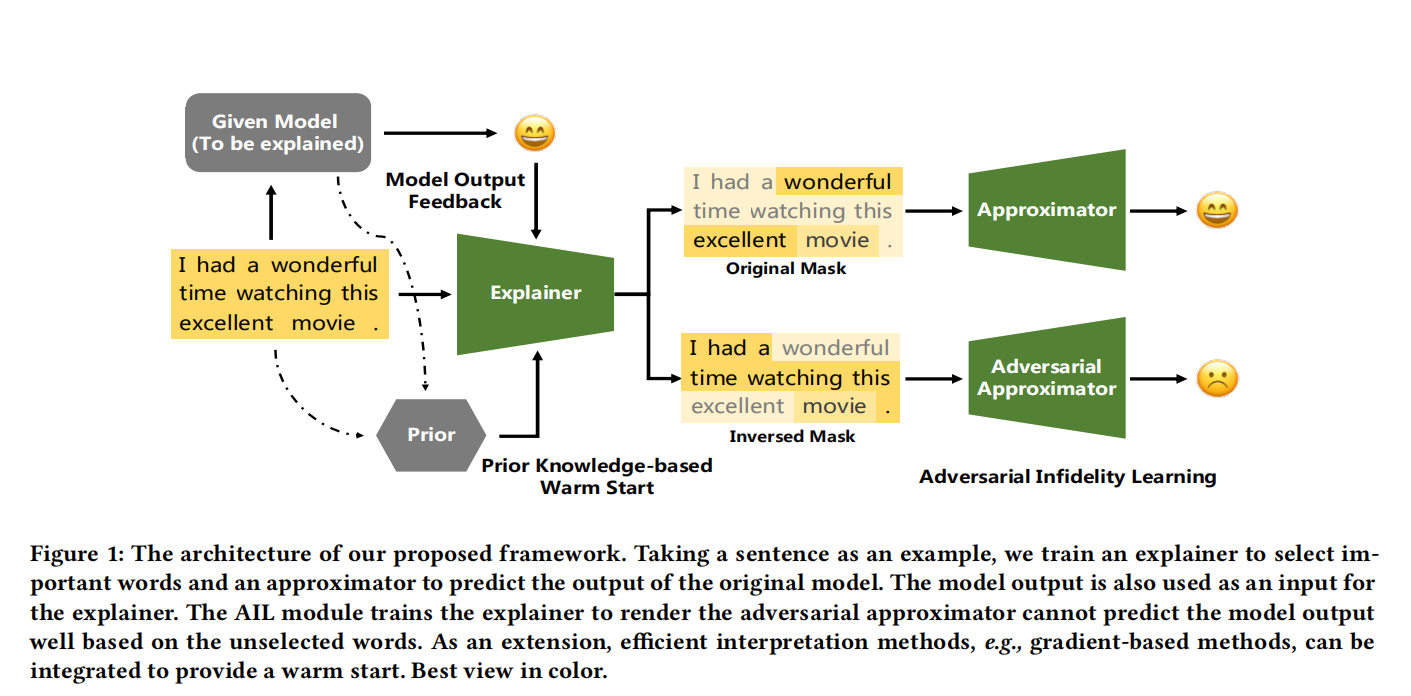 圖中展示了一個MEED怎麼為一個特定的資料樣本生成IFS解釋,即選中最重要的特徵。
首先樣本輸入到直譯器後會輸出一個mask,通過這個mask可以將特徵分為選中和未選中兩個部分,二者分別會用來訓練一個Approximator以近似模型輸出。對於這張圖而言,兩個Approximator都使用各自的特徵以逼近黑盒模型的輸出,也就是判斷為積極的情感。接著會訓練直譯器,在這一過程中會加強選中樣本的Approximator的逼近效果,並破壞Adversarial Approximator的逼近效果,這使得Adversarial Approximator不管怎麼逼近都只能判斷為消極的情感。與GAN相同,直譯器和逼近器之間是輪流訓練的,通過不斷迭代最後會獲得最終的mask,自然也能知道哪些特徵被選中了。
### AIL 機制 > 由於使用了Approximator,因此需要嚴謹的數學證明逼近是合理且能達到預期的。論文中這一部分的數學推導較多,在這就不逐一分析,只介紹其中AIL機制中部分數學原理。至於AIL的完整推導以及其他策略的理論部分,感興趣的朋友請自行檢視論文的這一章節和附錄部分。
#### 互資訊 首先簡單介紹一下熵和互資訊的概念來幫助理解。在資訊理論中,熵用於衡量隨機變數的不確定程度,兩個隨機變數$X,Y$和互資訊$I(X,Y)$之間的關係如下面公式所示,描述的是已知 $X$ 後 ,$Y$ 減少了多少不確定度。 $I(X;Y) = H(Y) - H(Y|X)$
#### 優化問題 在知道理解了互資訊這一概念後,就很容易理解論文定義的優化問題: 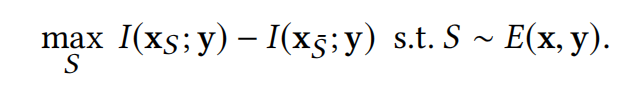 $S$ 意思是select,$x_S$是選中的特徵,$x_\bar{S}$是未選中的特徵。定性分析一下,想要最大化這一個式子,意思是希望前半部分儘可能大,後半部分儘可能小。根據剛剛介紹的互資訊的概念,這一個優化問題的含義就是:希望能找到一個mask,將特徵劃分為選中和未選中兩組,其中選中的特徵使得預測y的不確定度儘可能減少,而未選中特徵則對預測y的不確定度的減少沒有幫助。簡而言之,選中特徵包含儘可能多的決策資訊,而未選中特徵則對預測沒有幫助。
#### 損失函式 我們可以通過損失函式來理解AIL機制是怎麼運作且為什麼有效。$L_s,L_u$分別是逼近器$A_s,A_u$的逼近(擬合)損失。 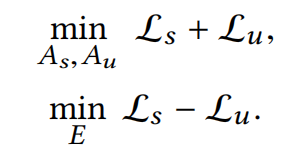 如果瞭解過GAN,相信對這種形式的損失函式一定不陌生,我簡單舉一個例子,在ACGAN中,鑑別器$D$的損失函式是$\mathop{max}L_c+L_s$,生成器$G$的損失函式是$\mathop{min}L_c - L_s$,二者的訓練就是一個對抗的過程。
回到MEED,接下來簡單描述一下AIL的訓練過程: 首先需要固定住直譯器$E$,對$A_s$和$A_u$進行訓練,這一過程使$L_s$和$L_u$都儘可能小,這意味著兩個逼近器會被擬合得很好。接著固定住$A_s$和$A_u$,對直譯器$E$進行訓練,這一過程會破壞$A_u$的精度使$L_u$增大以達到優化目標。這兩個過程交替迭代,直譯器$E$和逼近器$A_u$的訓練呈現出對抗的局面,這迫使直譯器找到一種劃分方式使$A_u$無論訓練都無法很好地逼近。可以理解為直譯器$E$找到了使未選中特徵包含最少的有用資訊的劃分方式,進而得到了高質量的選中特徵。
## 實驗與分析 ### 實驗Setting #### 基線模型 作者將他們提出的方法與多個基線模型進行了比較,其中包含了6個SOTA的 model-agnostic 方法以及2個分別發表在2013年和2017年的 model-specific 方法,它們分別是 - **Model-agnostic baselines:**LIME , kernel SHAP , CXPlain(CXP) , INFD , L2X , VIBI - **Model-specific baselines:**Gradient (Grad) , Gradient $\times$ Input (GI)
#### 指標 實驗部分主要是基於保真度(Fidelity)進行評估,用於衡量兩個值之間的一致性。以下的指標中F都是指Fidelity,根據前文的描述可以得到預期的結果:FS-M和FS-A應該儘可能高,說明黑盒模型的輸出依賴於選中的特徵,FU-M和FU-A應該儘可能低,說明沒有選中的特徵對黑盒模型的影響很小。需要注意的是,如果選中特徵的數量很少,可能會使 $A'_s$ 擬合效果不好而 $A'_u$擬合得很好,表現為FS-A較低以及FU-A較高。以上提到的四個指標用於驗證選中的特徵能否很好解釋黑盒模型是怎樣產生預測的,在此之上可解釋性還要求模型產生的解釋儘可能讓人容易理解,因此引入了FS-H指標。 | 指標 | 二者保真度/含義 | | :------: | :-----------------------------------------: | | FS-M (%) | $M(x)$和$M(\widetilde{x}_S)$ | | FS-A (%) | $M(x)$和$A'_s(\widetilde{x}_S)$ | | FU-M (%) | $M(x)$和$M(\widetilde{x}_\bar{S})$ | | FU-A (%) | $M(x)$和$A'_u(\widetilde{x}_\bar{S})$ | | FS-H (%) | $M(x)$和人類使用$\widetilde{x}_S$產生的判斷 | | SEN (%) | 對抗樣本對特徵分數的影響 | | TPS | 每個樣本獲取預測的平均用時 |
### 文字資料(IMDB) #### 評估結果 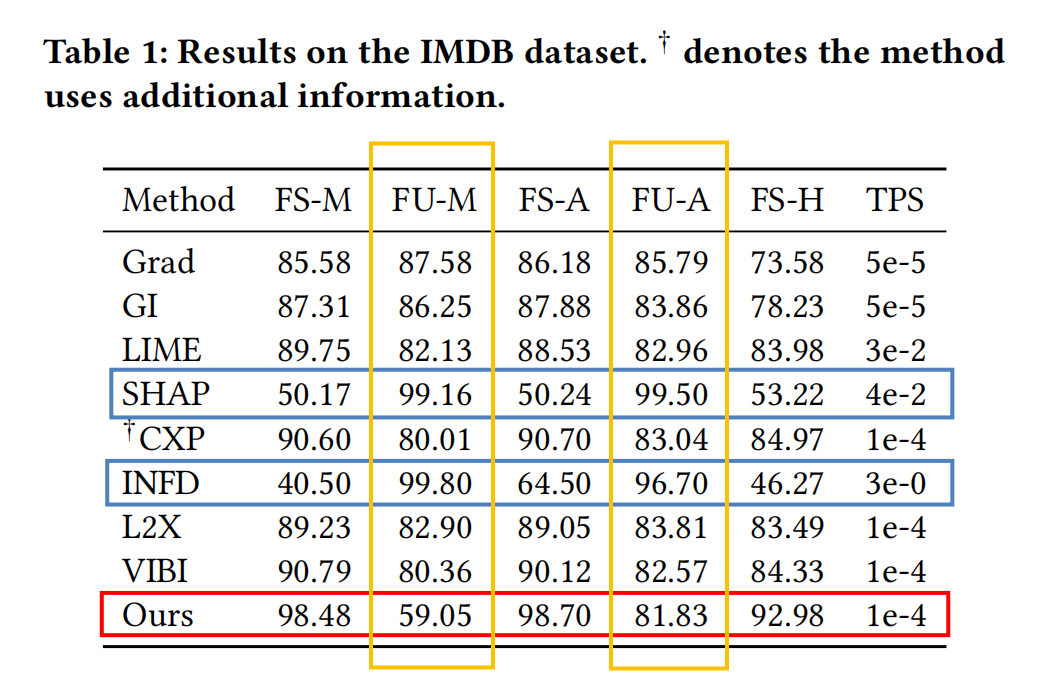 如表中紅色方框圈出的,在IMDB資料集上,MEED方法在各指標上都達到了最優的效能,生成解釋的用時也相對較快。 除此之外還可以注意到橙色框圈出的兩個指標FU-M和FU-A,其他的模型因為沒有對抗學習的機制,所以FU-A和FU-M都可以達到較高的點。對於存在對抗學習機制的MEED方法,FU-M和FU-A會互相抑制,均不能達到直接擬合的效果,這說明了直譯器E選擇了一組合適的特徵,未選中的特徵是無用的且儘可能被擬合。另外,從表中看其他的baseline均會在四個指標上達到較高的點,但藍色框圈出的兩個模型的FS-M和FS-A都較低,文中沒有給出相應解釋,這是比較讓人疑惑的一個點。  從例項來看,MEED方法能在減少無傾向詞的選擇。在(2)(3)(4)例項中劃線部分和框柱的部分中也能看出,MEED方法能較為有效地減少歧義詞的選擇,以幫助解釋方法做出正確的判斷。
#### 消融研究 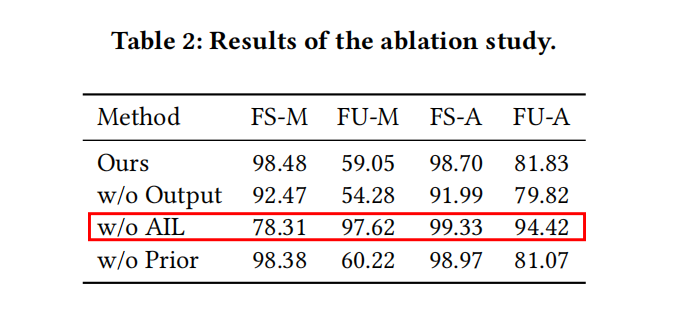 消融研究的結果看出,去除了AIL後FS-M下降,FU-M升高,這說明此時模型生成的解釋的質量不高,證明了對抗學習(AIL)機制的有效性。同時也能觀察到,使用原模型輸出作為額外的監督資訊的策略,和使用先驗知識進行暖啟動的策略並不能對保真度(Fidelity)指標有著顯著影響。
#### 完備性(Sanity)檢查 論文還使用了一種顯著性檢測的方法[3]對解釋模型進行了完備性檢查。其大致操作是將正常的生成的特徵分數與資料隨機化和黑盒模型引數隨機化後生成的特徵分數進行對比,二者得到的sanity score分別是9.39%和10.25%。這兩個值越低代表著對資料和黑盒模型進行改動後生成的特徵分數越不同,這表明這種解釋方法是依賴於黑盒模型和資料本身的,解決了現有方法中的Sanity Problem。
#### 暖啟動(warm start) 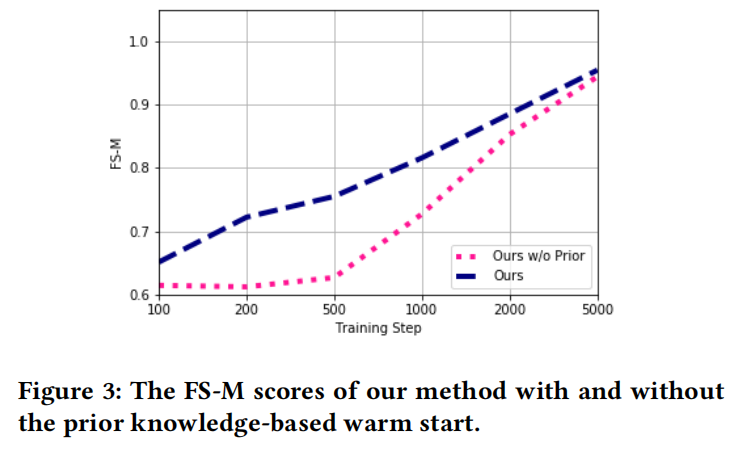 暖啟動的效果如上圖所示,雖然這一策略並不能對指標有顯著影響,但可以有效地提高訓練初期的收斂速度,這也代表著對抗學習中常出現的收斂困難的問題在一定程度得到改善。
### 影象資料 #### MNIST to classify 3 and 8 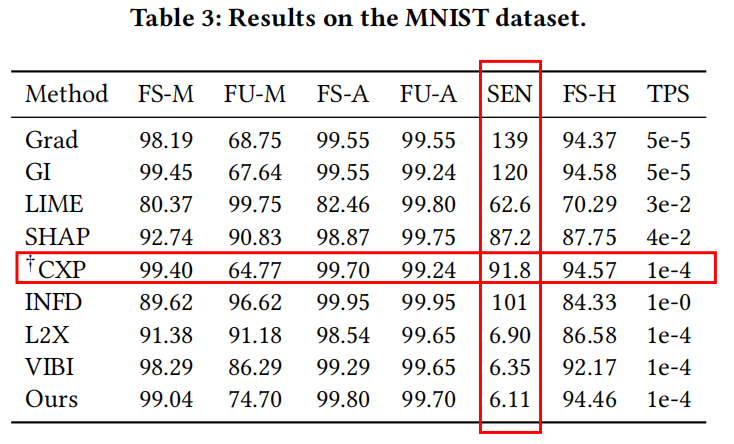 在MNIST資料集上,MEED方法雖然不能達到最優的效能,但也能獲得次優的效果。除此之外,MEED方法的SEN指標是最低的,這意味著該方法在保證效能的同時兼具良好的魯棒性。  論文中給出了3和8預測中選擇特徵的兩個例項,意在說明MEED方法選擇的特徵歧義相對較小。但就我個人來看,從上圖並不能很明顯地得出這一結論。
#### Fashion-MNIST to classify Pullover and Coat 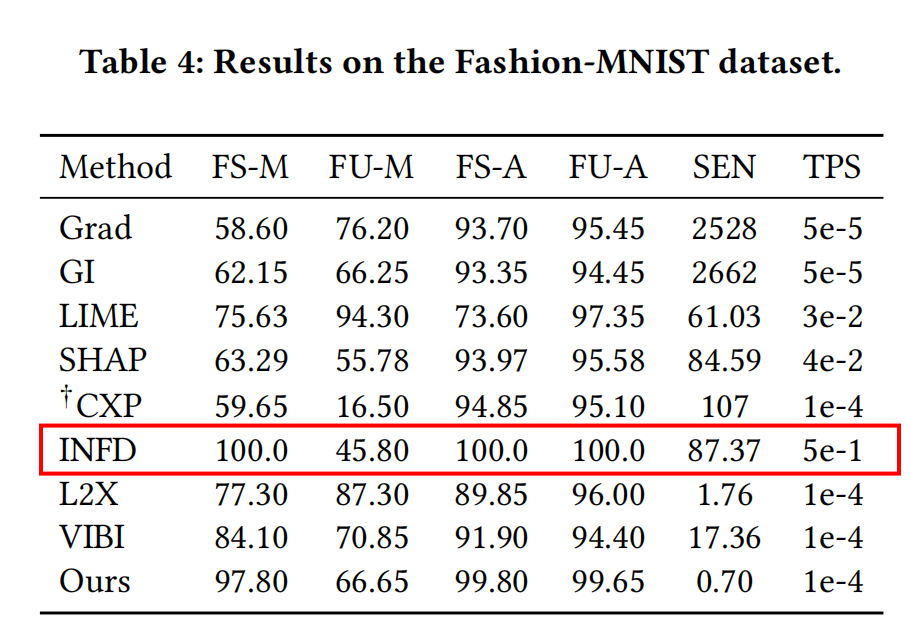  在Fashion-MNIST資料集上也能得到與MNIST資料集上相似的結論,因此不再贅述。
#### ImageNet to classify Gorilla and Zebra 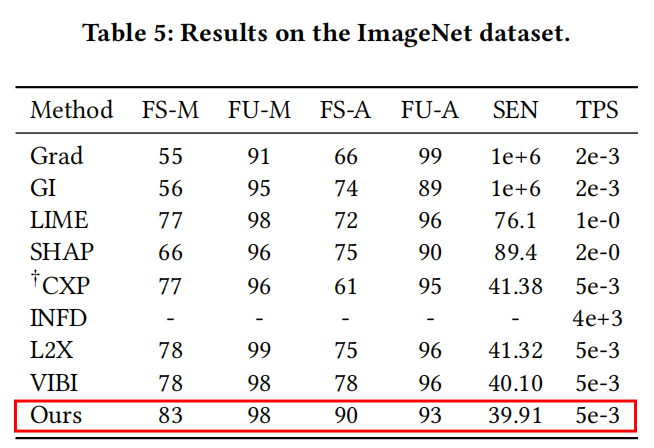 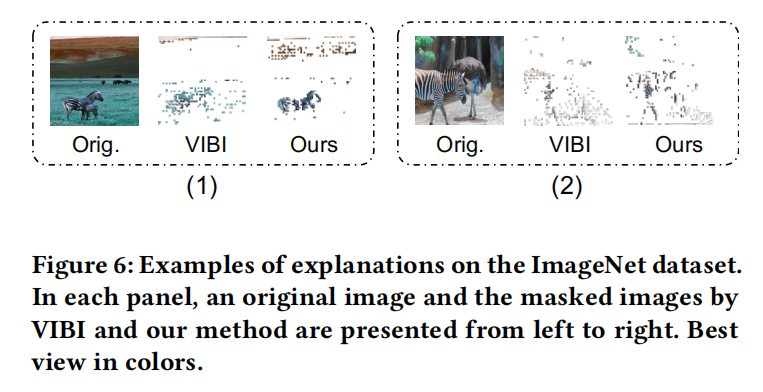 如表格所示,在ImageNet上,MEED方法達到了最優的效能。除此之外,如給出的例項所示,該方法更多地關注於標籤相關的區域,相比VIBI這一基線模型更具可解釋性。
### 時間序列資料 #### Tencent Honor of Kings gam for teenager recognition 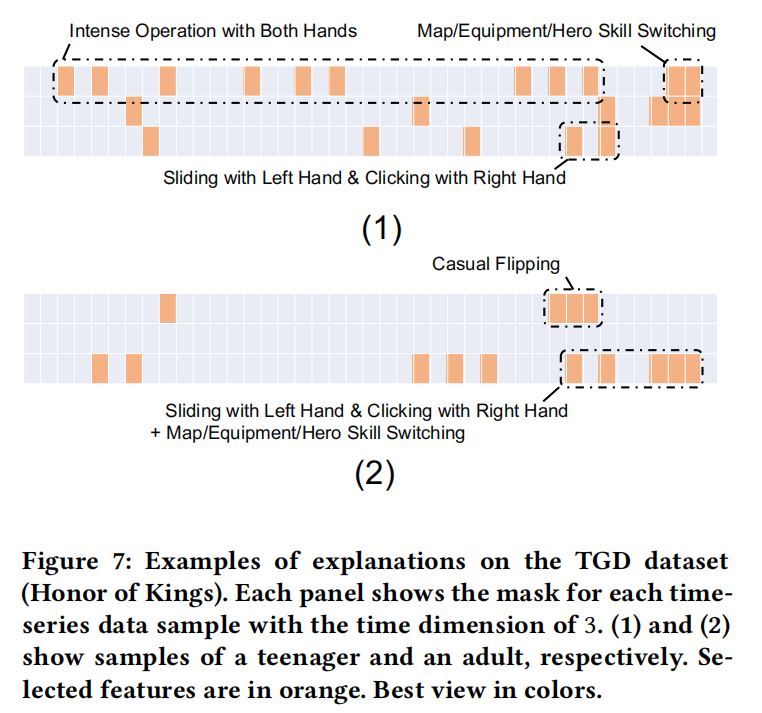 圖中展示了王者榮耀中未成年人(1)和成年人(2)的操作序列資料,以及使用MEED方法選中的特徵。MEED方法在該資料集上的指標 FS-M,FU-M,FS-A,FU-A, 和 SEN 分別是95.68%,82.24%,95.33%,82.37%,and 0.18%。從指標可以看出MEED方法構建出的預測模型有著很高的效能以及魯棒性。除此之外,解釋模型選中的特徵也具有很強的可解釋性。對於未成年人而言,選中的特徵多集中於遊戲前期;對於成年人而言,選中的特徵多集中於遊戲後期。這對應了遊戲中兩類人的行為模式,未成年人在遊戲初期的操作比較複雜,越往後操作越單調;而成年人在遊戲初期顯得比較隨意,但隨著遊戲進行,操作變得熟練且複雜。
## 結論 該工作是在模型可解釋性領域內的研究,其提出了一個模型無關的IFS方法。其主要貢獻在於提出了三種策略在一定程度上解決了現有IFS方法中存在的四個問題。該工作通過理論和大量實驗證明了MEED方法在特徵選擇上的有效性和通用性,也證明了通過該方法選擇的特徵具有較高的質量。MEED方法在多種型別的資料集中均達到了SOTA的效能。
## 收穫 1. AIL借鑑了GAN的對抗的思想,IFS的選擇過程本身也可以看作是生成一個feature mask,這種對抗機制可以作用在區域性以實現隱式的約束。 2. 在引文注意到一篇發表在NAACL 2019的《Attention is not Explanation》[2]。Attention和IFS表面上看都是一種分配權重的機制,只是二者的目的不同。雖然Attention並不一定具備可解釋性,但也許可以結合IFS和Attention的共通之處去指導去建立一個本身就具有可解釋性的複雜網路。而不是需要依賴一些黑盒解釋方法。用黑盒解釋黑盒是需要比較嚴謹的推導的,沒有經過嚴謹推導的解釋模型只能給予有限的信任,一個例子是發表在NIPS 2018的《Sanity Checks for Saliency Maps》[3]就證明了一些廣泛使用的saliency method是獨立於訓練資料和模型,這會導致在某些任務上的失效。
## 參考資料 [1] https://www.jiqizhixin.com/articles/2019-10-30-9 [2] Sarthak Jain and Byron C Wallace. 2019. Attention is not Explanation. In *Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers)*. 3543–3556. [3] Julius Adebayo, Justin Gilmer, Michael Muelly, Ian Goodfellow, Moritz Hardt, and Been Kim. 2018. Sanity checks for saliency maps. In *Advances in Neural Information Processing Systems*. 9505
## 作者及團隊 本文是騰訊發表的一篇文章,一作分別是 Jian Liang, Bing Bai, Yuren Cao, Kun Bai. 其中 Jian Liang是來自阿里巴巴團隊的,另外三位都來自騰訊團隊。
## 背景介紹 [1] ### 模型可解釋性 #### 什麼是模型可解釋性 模型可解釋性表達了模型內在機制的透明度以及人類理解模型決策原因的難易程度,主要體現在兩個方面: - **為什麼模型會做出某種決策?**對於一個分類任務,當往模型中輸入一個樣本時會得到一個預測,模型的可解釋性幫助我們去確定模型為什麼會產生這一預測。更具體地,樣本的哪些特徵使模型做出了這一預測。 - **人類能否理解並信任這一決策?**對於任何希望模型能預期工作的人而言,模型的解釋必須是易於理解的,否則無法輕易信任模型或是對模型進行鍼對性的調整。
### 例項特徵選擇(IFS) #### IFS 是什麼 IFS全稱為Instance-wise Feature Selection,是一種經典的模型不可知(Model-agnostic)的解釋方法。該方法會為每個樣本生成一個特徵重要度的分數,這分數表明了對於某一樣本而言哪些特徵對產生對應的輸出起著至關重要的作用。
#### 理想的解釋應該有什麼屬性 - Expressiveness:這一屬性指出能獲得高分數的特徵的數量應當是較少的。一個直接的理解應該是重要特徵和不重要特徵間區分度應該較大。 - Fidelity:保真度這一屬性指出模型的輸出應當主要由高分的特徵所決定。 - Low sensitivity:低敏感這一屬性指出生成的特徵分數應該是高魯棒性的,對對抗樣本的攻擊是不敏感的。 - Sanity:這一屬性指出生成的特徵分數應當取決於被解釋的模型。需要注意的是,前面提到的LIME方法中獲得的特徵分數更多是針對於用於解釋的模型而不是針對於需要解釋的模型。
## 問題與動機 ### 問題定義 考慮一個數據集包含有$n$個獨立的樣本,其中第$i$個樣本記為 $x^i \in X \subset R^d$,資料驅動的黑盒模型 $m \in M$,模型輸出 $y^i=M(x^i)\in Y \subset R^c$。IFS問題需要構建一個直譯器$E$,它的輸出是一個特徵重要性得分向量 $z \in Z \subset R^d$。換言之,直譯器需要建立起一個對映 $E:X\times M \to Z$,但由於黑盒模型無法直接作為神經網路的輸入,因此通常使用替代對映 $E:X\times Y \to Z$。
### 動機 #### Sanity problem 直譯器選中的特徵可能是與原模型無關,而僅僅只與輸入的樣本有關。這意味著選中的特徵可能和原模型在預測中真正使用的特徵是不一致的。這要求生成的解釋具有Sanity這一屬性。
#### Combinatorial shortcuts problem 直譯器選中的特徵可能並不是良好的特徵,解釋模型可能將生成的mask作為額外的特徵以輔助資料和標籤的擬合。舉個例子,解釋模型可以對每個樣本都選擇取前半部分或後半部分進行擬合,解釋模型將會關注這種模式是否對效能有提升,而不是考慮是否是因為選擇了好的向量才使得效能提升。這要求生成的解釋需要具有Fidelity這一屬性。
#### Model identifiability problem 直譯器可能會產生多種具有相似效能的特徵組合,直譯器很難確定哪一種組合才是最好的。這要求生成的解釋需要具有Expressiveness這一屬性。
#### Information transmission problem 直譯器生成特徵得分向量的過程是無監督的,因此難以將監督資訊傳遞給直譯器,直譯器也很難利用好監督資訊,因此直譯器訓練起來難度很大。
### 解決方案 #### 將原模型輸出作為直譯器的額外訊號 現有的很多方法直接將原樣本輸入到直譯器中,這一過程沒有黑盒模型的參與,這往往會產生Sanity Problem。因此該方法將原模型的輸出也作為直譯器的一個輸入,可以加強生成的特徵得分向量與原模型間的聯絡。另外這一策略為直譯器提供了額外的資訊,這可以直譯器能學習到更多的知識,在一定程度上也能減輕Information transmission problem。
關於這一策略的表述有一些疑惑之處,利用其他模型學習到的知識的技術是比較成熟的了,比如知識蒸餾在2016年提出了,資料蒸餾在前兩年也提出了。因此SOTA的方法中應該也有應用這一策略的,但是文章中挑選了幾個沒有使用的用於說明這一策略的優越性,個人認為說服力不夠強。
#### 針對於未選中特徵的對抗學習機制(AIL) AIL機制的提出是為了解決combinatorial shortcuts problem和model identifiability problem。簡而言之,希望直譯器選中的特徵組合是足夠好且唯一的,而未選中的特徵包含的都應該是無用的資訊。基於此想法,AIL機制中增加了一個逼近器(Approximator),使用它來擬合未選中特徵和模型的輸出,直譯器的目標是使這個Approximator的精度儘可能小。
#### 基於先驗知識的暖啟動 直譯器的訓練本身存在有Information transmission problem,再加入AIL對抗學習機制後由於對抗學習的不穩定性導致模型更難以收斂。為此,論文提出整合其他高效模型的解釋和先驗用作MEED模型的暖啟動,在訓練進行到一定程度,可以學到更好的直譯器後,先驗的約束就會逐漸放寬。
## MEED Framework ### 總體框架  圖中展示了一個MEED怎麼為一個特定的資料樣本生成IFS解釋,即選中最重要的特徵。
首先樣本輸入到直譯器後會輸出一個mask,通過這個mask可以將特徵分為選中和未選中兩個部分,二者分別會用來訓練一個Approximator以近似模型輸出。對於這張圖而言,兩個Approximator都使用各自的特徵以逼近黑盒模型的輸出,也就是判斷為積極的情感。接著會訓練直譯器,在這一過程中會加強選中樣本的Approximator的逼近效果,並破壞Adversarial Approximator的逼近效果,這使得Adversarial Approximator不管怎麼逼近都只能判斷為消極的情感。與GAN相同,直譯器和逼近器之間是輪流訓練的,通過不斷迭代最後會獲得最終的mask,自然也能知道哪些特徵被選中了。
### AIL 機制 > 由於使用了Approximator,因此需要嚴謹的數學證明逼近是合理且能達到預期的。論文中這一部分的數學推導較多,在這就不逐一分析,只介紹其中AIL機制中部分數學原理。至於AIL的完整推導以及其他策略的理論部分,感興趣的朋友請自行檢視論文的這一章節和附錄部分。
#### 互資訊 首先簡單介紹一下熵和互資訊的概念來幫助理解。在資訊理論中,熵用於衡量隨機變數的不確定程度,兩個隨機變數$X,Y$和互資訊$I(X,Y)$之間的關係如下面公式所示,描述的是已知 $X$ 後 ,$Y$ 減少了多少不確定度。 $I(X;Y) = H(Y) - H(Y|X)$
#### 優化問題 在知道理解了互資訊這一概念後,就很容易理解論文定義的優化問題: 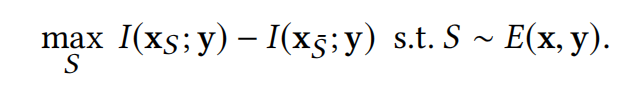 $S$ 意思是select,$x_S$是選中的特徵,$x_\bar{S}$是未選中的特徵。定性分析一下,想要最大化這一個式子,意思是希望前半部分儘可能大,後半部分儘可能小。根據剛剛介紹的互資訊的概念,這一個優化問題的含義就是:希望能找到一個mask,將特徵劃分為選中和未選中兩組,其中選中的特徵使得預測y的不確定度儘可能減少,而未選中特徵則對預測y的不確定度的減少沒有幫助。簡而言之,選中特徵包含儘可能多的決策資訊,而未選中特徵則對預測沒有幫助。
#### 損失函式 我們可以通過損失函式來理解AIL機制是怎麼運作且為什麼有效。$L_s,L_u$分別是逼近器$A_s,A_u$的逼近(擬合)損失。 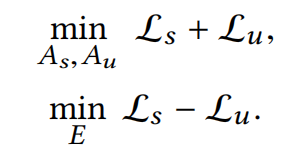 如果瞭解過GAN,相信對這種形式的損失函式一定不陌生,我簡單舉一個例子,在ACGAN中,鑑別器$D$的損失函式是$\mathop{max}L_c+L_s$,生成器$G$的損失函式是$\mathop{min}L_c - L_s$,二者的訓練就是一個對抗的過程。
回到MEED,接下來簡單描述一下AIL的訓練過程: 首先需要固定住直譯器$E$,對$A_s$和$A_u$進行訓練,這一過程使$L_s$和$L_u$都儘可能小,這意味著兩個逼近器會被擬合得很好。接著固定住$A_s$和$A_u$,對直譯器$E$進行訓練,這一過程會破壞$A_u$的精度使$L_u$增大以達到優化目標。這兩個過程交替迭代,直譯器$E$和逼近器$A_u$的訓練呈現出對抗的局面,這迫使直譯器找到一種劃分方式使$A_u$無論訓練都無法很好地逼近。可以理解為直譯器$E$找到了使未選中特徵包含最少的有用資訊的劃分方式,進而得到了高質量的選中特徵。
## 實驗與分析 ### 實驗Setting #### 基線模型 作者將他們提出的方法與多個基線模型進行了比較,其中包含了6個SOTA的 model-agnostic 方法以及2個分別發表在2013年和2017年的 model-specific 方法,它們分別是 - **Model-agnostic baselines:**LIME , kernel SHAP , CXPlain(CXP) , INFD , L2X , VIBI - **Model-specific baselines:**Gradient (Grad) , Gradient $\times$ Input (GI)
#### 指標 實驗部分主要是基於保真度(Fidelity)進行評估,用於衡量兩個值之間的一致性。以下的指標中F都是指Fidelity,根據前文的描述可以得到預期的結果:FS-M和FS-A應該儘可能高,說明黑盒模型的輸出依賴於選中的特徵,FU-M和FU-A應該儘可能低,說明沒有選中的特徵對黑盒模型的影響很小。需要注意的是,如果選中特徵的數量很少,可能會使 $A'_s$ 擬合效果不好而 $A'_u$擬合得很好,表現為FS-A較低以及FU-A較高。以上提到的四個指標用於驗證選中的特徵能否很好解釋黑盒模型是怎樣產生預測的,在此之上可解釋性還要求模型產生的解釋儘可能讓人容易理解,因此引入了FS-H指標。 | 指標 | 二者保真度/含義 | | :------: | :-----------------------------------------: | | FS-M (%) | $M(x)$和$M(\widetilde{x}_S)$ | | FS-A (%) | $M(x)$和$A'_s(\widetilde{x}_S)$ | | FU-M (%) | $M(x)$和$M(\widetilde{x}_\bar{S})$ | | FU-A (%) | $M(x)$和$A'_u(\widetilde{x}_\bar{S})$ | | FS-H (%) | $M(x)$和人類使用$\widetilde{x}_S$產生的判斷 | | SEN (%) | 對抗樣本對特徵分數的影響 | | TPS | 每個樣本獲取預測的平均用時 |
### 文字資料(IMDB) #### 評估結果  如表中紅色方框圈出的,在IMDB資料集上,MEED方法在各指標上都達到了最優的效能,生成解釋的用時也相對較快。 除此之外還可以注意到橙色框圈出的兩個指標FU-M和FU-A,其他的模型因為沒有對抗學習的機制,所以FU-A和FU-M都可以達到較高的點。對於存在對抗學習機制的MEED方法,FU-M和FU-A會互相抑制,均不能達到直接擬合的效果,這說明了直譯器E選擇了一組合適的特徵,未選中的特徵是無用的且儘可能被擬合。另外,從表中看其他的baseline均會在四個指標上達到較高的點,但藍色框圈出的兩個模型的FS-M和FS-A都較低,文中沒有給出相應解釋,這是比較讓人疑惑的一個點。  從例項來看,MEED方法能在減少無傾向詞的選擇。在(2)(3)(4)例項中劃線部分和框柱的部分中也能看出,MEED方法能較為有效地減少歧義詞的選擇,以幫助解釋方法做出正確的判斷。
#### 消融研究  消融研究的結果看出,去除了AIL後FS-M下降,FU-M升高,這說明此時模型生成的解釋的質量不高,證明了對抗學習(AIL)機制的有效性。同時也能觀察到,使用原模型輸出作為額外的監督資訊的策略,和使用先驗知識進行暖啟動的策略並不能對保真度(Fidelity)指標有著顯著影響。
#### 完備性(Sanity)檢查 論文還使用了一種顯著性檢測的方法[3]對解釋模型進行了完備性檢查。其大致操作是將正常的生成的特徵分數與資料隨機化和黑盒模型引數隨機化後生成的特徵分數進行對比,二者得到的sanity score分別是9.39%和10.25%。這兩個值越低代表著對資料和黑盒模型進行改動後生成的特徵分數越不同,這表明這種解釋方法是依賴於黑盒模型和資料本身的,解決了現有方法中的Sanity Problem。
#### 暖啟動(warm start)  暖啟動的效果如上圖所示,雖然這一策略並不能對指標有顯著影響,但可以有效地提高訓練初期的收斂速度,這也代表著對抗學習中常出現的收斂困難的問題在一定程度得到改善。
### 影象資料 #### MNIST to classify 3 and 8  在MNIST資料集上,MEED方法雖然不能達到最優的效能,但也能獲得次優的效果。除此之外,MEED方法的SEN指標是最低的,這意味著該方法在保證效能的同時兼具良好的魯棒性。  論文中給出了3和8預測中選擇特徵的兩個例項,意在說明MEED方法選擇的特徵歧義相對較小。但就我個人來看,從上圖並不能很明顯地得出這一結論。
#### Fashion-MNIST to classify Pullover and Coat   在Fashion-MNIST資料集上也能得到與MNIST資料集上相似的結論,因此不再贅述。
#### ImageNet to classify Gorilla and Zebra   如表格所示,在ImageNet上,MEED方法達到了最優的效能。除此之外,如給出的例項所示,該方法更多地關注於標籤相關的區域,相比VIBI這一基線模型更具可解釋性。
### 時間序列資料 #### Tencent Honor of Kings gam for teenager recognition  圖中展示了王者榮耀中未成年人(1)和成年人(2)的操作序列資料,以及使用MEED方法選中的特徵。MEED方法在該資料集上的指標 FS-M,FU-M,FS-A,FU-A, 和 SEN 分別是95.68%,82.24%,95.33%,82.37%,and 0.18%。從指標可以看出MEED方法構建出的預測模型有著很高的效能以及魯棒性。除此之外,解釋模型選中的特徵也具有很強的可解釋性。對於未成年人而言,選中的特徵多集中於遊戲前期;對於成年人而言,選中的特徵多集中於遊戲後期。這對應了遊戲中兩類人的行為模式,未成年人在遊戲初期的操作比較複雜,越往後操作越單調;而成年人在遊戲初期顯得比較隨意,但隨著遊戲進行,操作變得熟練且複雜。
## 結論 該工作是在模型可解釋性領域內的研究,其提出了一個模型無關的IFS方法。其主要貢獻在於提出了三種策略在一定程度上解決了現有IFS方法中存在的四個問題。該工作通過理論和大量實驗證明了MEED方法在特徵選擇上的有效性和通用性,也證明了通過該方法選擇的特徵具有較高的質量。MEED方法在多種型別的資料集中均達到了SOTA的效能。
## 收穫 1. AIL借鑑了GAN的對抗的思想,IFS的選擇過程本身也可以看作是生成一個feature mask,這種對抗機制可以作用在區域性以實現隱式的約束。 2. 在引文注意到一篇發表在NAACL 2019的《Attention is not Explanation》[2]。Attention和IFS表面上看都是一種分配權重的機制,只是二者的目的不同。雖然Attention並不一定具備可解釋性,但也許可以結合IFS和Attention的共通之處去指導去建立一個本身就具有可解釋性的複雜網路。而不是需要依賴一些黑盒解釋方法。用黑盒解釋黑盒是需要比較嚴謹的推導的,沒有經過嚴謹推導的解釋模型只能給予有限的信任,一個例子是發表在NIPS 2018的《Sanity Checks for Saliency Maps》[3]就證明了一些廣泛使用的saliency method是獨立於訓練資料和模型,這會導致在某些任務上的失效。
## 參考資料 [1] https://www.jiqizhixin.com/articles/2019-10-30-9 [2] Sarthak Jain and Byron C Wallace. 2019. Attention is not Explanation. In *Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers)*. 3543–3556. [3] Julius Adebayo, Justin Gilmer, Michael Muelly, Ian Goodfellow, Moritz Hardt, and Been Kim. 2018. Sanity checks for saliency maps. In *Advances in Neural Information Processing Systems*. 9505