
從資料倉庫雙集群系統模式探討,看GaussDB(DWS)的容災設計
摘要:本文主要是探討OLAP關係型資料庫框架的資料倉庫平臺如何設計雙集群系統,即增強系統高可用的保障水準,然後討論一下GaussDB(DWS)的容災應該如何設計。
當前社會、企業運行當中,大資料分析、資料倉庫平臺已逐漸成為生產、生活的重要地位,不再是一個附屬的可有可無的分析系統,外部監控要求、企業內部服務,湧現大批要求7*24小時線上的應用,逐步出現不同等級要求的雙集群系統。
資料倉庫主流資料庫平臺均已存在多重高可靠保障措施設計,如硬碟冗餘的raid設計、資料表冗餘、節點備用冗餘、機櫃備用資料交叉等,以及加上服務程序高可用冗餘設計,其最大化程度滿足資料倉庫服務持續線上。
但現實場景,如資料庫軟體缺陷、定期加固補丁、產品迭代、硬體升級這些產品現實因素,以及來自機房、資料中心、地域、網路的外部災難故障因素,均在降低資料倉庫可用性服務水平。
鑑於資料倉庫存在大量資料吞吐,針對不同資料庫、不同可用性要求,若需要設計雙叢集冗餘設計,可選技術手段分別有資料同步模式、雙ETL模式、雙活模式,具體探討如下:
1.資料同步模式
a)架構
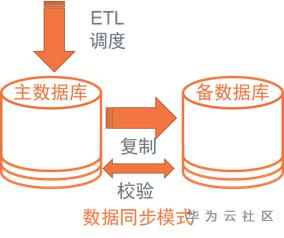
由於資料庫IO能力有限、且兩個資料庫間頻寬有限,除了首次全量同步之後,後續通常考慮增量同步技術,即如何準確、高效獲取“變化資料”,一般存在日誌同步技術、備份增量同步技術、邏輯資料同步;
b)日誌同步技術
日誌同步技術,有業內最著名Oracle Golden Gate,大部分廠家也有自己的實現方式,像Teradata近年來推出Unity CDM(變化資料廣播)技術,而我司GaussDB for DWS可採用xlog及page進行變化資料同步。
優勢:直接同步變化資料增量,資料量少,要求頻寬低,但目前市面技術大都只適合資料每日變化量較少的資料倉庫環境;
劣勢:現實的技術門檻高,應對各類異常場景適應能力差,對主資料庫侵入效能要求高,一旦主庫繁忙,同步時效低;面對全刪全插等變化資料量大場景,同步吃力;
c)備份增量同步技術
主要利用各資料庫平臺備份恢復能力,進行資料增、全量備份、恢復;通常源庫備份資料壓縮之後,經網路傳輸後,解壓恢復到目標庫;對應GaussDB for DWS可採用roach備份恢復工具實現;
優勢:利用同一技術實現增、全量資料同步,邏輯清晰,各場景容錯能力強;
劣勢:要求資料庫支援增備能力,且往往鎖等待嚴重;
d)邏輯資料同步
該項主要涉及較高的業務侵入性,即充分獲取ETL排程資料流元資料,對應資料庫當日資料穩定之後,發起資料表匯出-匯入操作,針對資料表加工特性,選擇增全量同步規則,進行資料準實時同步。
優勢:較上述同步技術,可以實現多樣選擇性同步,同步過程由實施專案本身控制,做到表級資料同步,不需要全系統同步,即可實現部分業務雙叢集;
劣勢:客戶化同步邏輯,操作前置依賴多,實施投入人力多,較難推廣;
2.雙ETL模式
a)架構
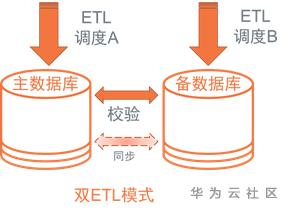
即採用兩套獨立排程平臺進行資料加工,抽取同一個資料來源(往往是落地穩定的資料交換平臺),採用同一套ETL程式碼依賴邏輯排程,各自生成目標資料,往往批量過程中,採取主庫對外持續服務,待主備庫資料準實時或批後校驗一致後,再開放備庫對外服務。
若雙叢集資料發生不一致場景,主要以主庫資料為準,覆蓋備庫。該同步過程,需要使用到“資料同步模式”相關同步技術。
b)參照落地架構
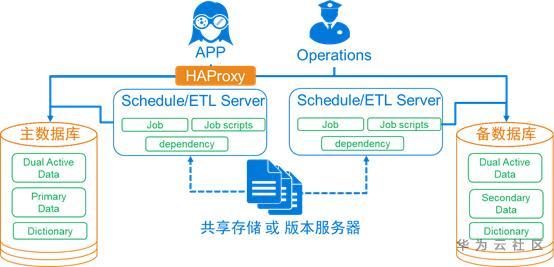
c)載入源資料考慮
為保證兩套ETL排程載入資料來源一致及資料複用,往往要求搭建一個數據交換平臺。因為至少存在一個檔案被兩套排程讀取,要求資料交換平臺兩倍過往吞吐能力;且禁止載入的資料檔案被二次覆蓋,導致兩套系統載入不一致;
d)排程依賴順序考慮
由於ETL作業排程關係沒有配置完備,即存在A作業使用B作業的資料,但不配置依賴關係(絕大部分的情況是A作業可容忍B資料的時效,是否最新資料均可以使用,故為時效,業務上不配置依賴關係;當然也存在物理時間上,通常B遠遠早於A執行),導致兩套系統A作業生成資料不一致。
該場景下,在一套排程平臺無法發現此問題,但存在兩套系統的校驗比對,即發現數據不一致;
該問題建議使用者補全依賴關係,確認執行順序一致性;
當然若希望靈活使用依賴關係,則需二次開發,控制兩套排程當日時序一致性;
e) ETL程式碼伺服器考慮
為了避免兩套ETL排程程式碼維護不一致,需考慮統一維護渠道,包含不限於同一個程式碼儲存源、版本伺服器,以及程式碼變更時機
f)存在不確定值的SQL函式返回
ETL程式碼中往往存在sample、random、row_number排序這種同一份資料產生不同結果集的函式,造成兩套系統資料不一致;
該問題建議使用者使用替代函式、明確取值、唯一排序,確保最終資料一致性;
同時,該設計邏輯正確情況下,哪份資料均可被業務採信,若該資料對下游影響少,可每日批後從主庫同步備庫,拉平資料;
g)報錯修數邏輯考慮
其中一套系統的資料發生報錯、修數行為,會涉及到另一套系統的維護行為;
可選作法是保留操作邏輯,待另一套系統發生報錯時重複執行一次;
其它交給資料質量校驗(DQC)、資料校驗去複查;
h)干預重跑修數邏輯考慮
若批後重跑,兩套系統重跑邏輯一致,涉及重複勞動(或支撐平臺優化),相對簡單;
但涉及批量過程中發現部分資料需要重跑,由於兩套排程進度不一致,會導致
i)資料校驗
i.校驗時機
批後校驗,邏輯清晰,對排程依賴少,即根據整體排程進度,做到分層、分庫或整體資料校驗;
準實時校驗,即侵入排程環節,在每個作業完成時,均發起日誌解析,提取每個SQL影響記錄數,若相應作業SQL存在影響記錄數不一致場景,即中止較晚完成的排程平臺排程後續作業;
ii.校驗手段
增全量校驗,即針對不同加工邏輯的資料表,區分增、全量資料值,以最小代價覆蓋所有業務表
iii.校驗方法
通常作法有記錄數、彙總值、checksum校驗;
彙總值校驗,通過是數值型欄位直接sum、字元型計算字元長度的sum、時間型別則轉換成數值相加的比對;
Checksum校驗,針對全表或部分欄位,進行md5或hash運算,完成兩套系統一致性比對;
對於關係型資料庫,校驗開銷代價逐步遞增(記錄數 < 彙總值 < checksum校驗);往往是結合增量校驗、結合重要指標,區分維度校驗,日常增量邏輯校驗,定期全量校驗,在校驗資料一致性和系統性能之間取得平衡點。
j)優化考量
i.校驗改進
即嵌入排程平臺,提取ETL程式碼執行日誌,通過執行SQL影響的記錄值,實時進行兩套系統完成作業日誌比對,發現記錄值影響,立即停止備庫排程,採用人工或自動方式修復資料,繼續後續批量。
該作法最大好處是,即時發現數據異常,避免問題放大,保障備庫更高可用性;
ii.引入統一維護平臺
即減少人為雙系統維護操作,程式碼變更平臺化,修數邏輯平臺化,由平臺分別下發兩套排程平臺、兩套資料庫。
3.雙活模式
以下基於Teradata Unity產品理念的延伸構想
a)架構
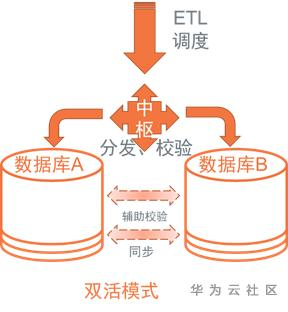
b)雙活功能點
i.訪問路由能力
客戶端直接將中介軟體作為資料庫登陸,保持原來登陸邏輯不變;
中介軟體根據登陸使用者及附加引數實現拒絕登陸、雙系統登陸、或單系統登陸,實現寫登陸、讀登陸,實現受控方式登陸、或非受控方式登陸;即實現受控和非受控方式的系統讀寫;
同時兼顧考慮異常路由選擇或同步路由選擇,滿足最大化異常執行及少部分同步需求場景;
ii. SQL分發能力
經中介軟體傳送的SQL指令,正常傳送到相應資料庫,並接受資料庫響應資訊;
iii.批量匯入、匯出能力
針對資料大批量的匯入,需要考慮採用更加高效的載入協議進行資料載入,並考慮經中介軟體複製資料塊,非同步分發兩個資料庫;
資料匯出,需要考慮高效資料匯出協議,從其中一套資料庫正確匯出資料;
iv.更新類SQL校驗能力
Delete、Update、Insert、Merge等更新類DML SQL進行SQL影響記錄數校驗;
DDL/DCL執行返回碼驗證一致性能力;
v.物件註冊功能
通過路由及建立物件的DDL語句,實現物件動態註冊;
通過命令列指令實現物件註冊;
適當增加物件索引、約束索引的註冊資訊,用於擴充套件細粒度物件鎖能力,提高資料倉庫ETL SQL併發能力;
*資料倉庫環境下,只需要考慮到表級雙活的能力,不建議實施欄位級、記錄級雙活;
vi.物件鎖能力
根據SQL指令給相應物件動態加鎖、釋放鎖;
同時根據資料庫自帶的鎖特徵,至少區分讀、寫鎖控制,以及部分資料庫的髒讀功能鎖;
vii.物件狀態控制能力
進行管理的多套資料庫線上狀態控制;
進行物件狀態控制功能,包含不限於線上、離線、只讀、只寫、主動中斷快取中、被動中斷快取中、不可用等狀態;
viii. 快取能力
進行SQL指令流快取能力,以及快取恢復執行的能力;
進行SQL與載入資料結合快取、以及快取恢復執行的能力;
ix. SQL異常控制能力
考慮使用者體驗,始終由返回響應正確的SQL指令返回客戶端;
兩個資料庫返回均成功,但返回的影響記錄數不一致,則響應慢的資料庫對應SQL及涉及物件被設定成不可用狀態;
若兩套資料庫其中一套執行成功,另一套執行失敗,則執行失敗的資料庫SQL和涉及物件被設定為被動中斷快取中,同時快取SQL,定時重試SQL;
若兩套資料庫返回均報錯,才通知客戶端報錯;
若SQL涉及物件已處理非線上狀態,則新提交的SQL被快取,新提交SQL相應物件被設定為被動中斷快取中。
針對中介軟體和資料庫之間,存在資料庫已執行完、但中介軟體未收到訊號場景,需考慮閃環該場景(如增加事務鎖等);
c) Teradata Unity參照落地架構
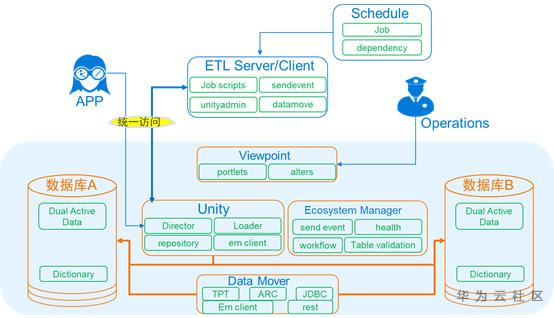
ü 主要通過Unity實現多叢集SQL、資料分發與管理;
ü Data Mover實現叢集間資料同步;
ü Eocsystem Manager實現資料批後自動校驗及不一致重同步事件觸發;
ü Viewpoint實現系統平臺透檢視展現與維護,並對接使用者告警平臺;
d)中介軟體高可用考慮
由於引入了中介軟體(前置)服務,即該服務的穩定、可靠對雙活模式至關重要。
資料庫單套系統本身已經具備極高的可用性,引入中介軟體後,由於所有資料庫訪問行為均通過該中介軟體,中介軟體任何異常均同時影響兩套資料庫訪問能力。
除了中介軟體本身所有相關服務需要滿足高可用之外,還需考慮極端場景下bypass能力,此項能力在於極端異常條件下,可以保障系統持續服務的能力。
高可用場景中,存在控制節點腦裂與自動升主場景,需借鑑仲裁機制減少腦殘裂發生;
e) 資料重同步考慮
即利用“資料同步模式”相關同步技術,實現兩套資料庫資料重同步能力;
f)不確定值的SQL函式考慮
最佳方案,是採用“資料同步模式”的資料日誌重同步技術,直接將第一套資料庫SQL執行結果的日誌資訊同步到第二套資料庫中,消除返回結果不一致;
部分簡單的系統時間函式,直接通過中介軟體改寫,保障SQL執行結果一致性;
另外,則通過SQL改寫,保證row_number函式進行主鍵或全欄位排序,保證SQL執行結果一致性;
g)異常會話重放能力
針對異常會話過程的SQL,可能需要從會話建立後,視覺化選擇,倒回前幾個SQL重新執行,並指定過程SQL是否參與結果集校驗,以及SQL回放結束的確認動作,讓異常場景處理手段更加豐富。
4.適用場景
a) “資料同步模式” – 日誌同步技術
適用資料變化量小、資料傳輸壓力小的資料場景,通常只適用於小型資料倉庫平臺;
對於規模小的平臺,RPO、RTO可以接近0;
b) “資料同步模式” – 備份增量同步技術
適合大資料量同步場景,實現方式容易被使用者理解;
往往需要資料庫備份工具具備增量備份恢復能力;同時考驗備份工具消除相關硬體限制條件,讓該技術方案更加靈活;
雙叢集的初始化同步往往採用全備全恢的邏輯實現,可以最大化、最快拉平存量資料;
對於規模大的平臺,RPO往往需要小時級別,RTO最好水準也在分鐘、10分鐘以上;同時主叢集需要保障一定資源量供資料同步使用,對主叢集開銷大;
c) “資料同步模式” – 邏輯資料同步技術
適用靈活同步場景,往往資料同步量不會太大,或同步時間可容忍場景;
此場景往往適合於使用者對其資料倉庫ETL過程元資料資訊清晰、完整,依賴客戶開發能力,相關同步資料存在清晰ETL演算法,結合排程作業執行進度,動態發起相關資料表增、全量同步;
對於中等規模的平臺,RPO可以做到分鐘、半小時,RTO可以維持在分鐘級;
d) “雙ETL模式”
需要兩套ETL排程環境,整體成本翻倍,但排程邏輯清晰、易於理解和維護;
較容易匹配不同規模的資料倉庫平臺採納;
較難實現資料實時比對,以及資料發生不一致之後的控制邏輯(若需要實現,對於排程邏輯侵入性大);
ETL排程批量中途,較難實現兩套排程鏈路協調重跑;
同時資料不一致,依賴於”資料同步模式”技術輔助實施;
由於主備排程進行不一致,無法做到主備統一檢視展現;
若雙叢集硬體相當,RPO、RTO均可以維持在分鐘級別;
e) “雙活模式”
需要獨立中介軟體、且嚴重依賴資料庫自身廠商,中介軟體實現難度大;
中介軟體的高可用(穩定性)成為它落地的最大障礙;
“雙ETL模式”的升級版,能適應各類資料倉庫雙叢集場景;
絕大部分場景下,RPO、RTO均可以接近0,特別是雙活同時線上能力,不存在雙叢集的主備切換,RTO可以做到0;同時存在統一檢視,不會因為其中一個叢集故障,造成前後同一個查詢返回結果不一致場景;
5.總結比對
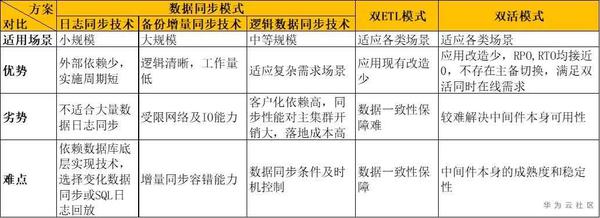
接下來,我們展開討論一下GaussDB(DWS)的容災應該如何設計。
對於方案探討中涉及到幾種形態,從數倉核心的角度去分析一下各個方案的問題:
- 日誌同步技術:
- 列存資料不記日誌無法通過日誌來同步
- 支援列存xlog後會導致匯入效能劣化,xlog資料量大,同時會影響日誌同步效率
- 備份增量同步技術:
- 無法達到 RPO = 0
- 備叢集只能讀,無法支援寫操作
- 邏輯資料同步技術:
- 列存資料需要支援邏輯解碼,需要從列存XLog的方向進行演進
- 分散式事務,DDL等處理難度較大
- 備份/恢復
- 不能馬上提供服務,RTO時間較長
- 需要較大空間儲存備份集
GaussDB(DWS) 當前在備份增量同步和備份/恢復兩個方向進行演進,他們都是基於備份/恢復工具Roach
(詳情參見Roach備份恢復GaussDB(DWS))
- 備份/恢復
備份/恢復的原理圖如下,在各個結點將例項備份到相應的介質上,並從介質上恢復到新叢集或老叢集中。詳細的功能不在此處展開描述,大家可以參考(詳情參見Roach備份恢復GaussDB(DWS)) 來了解細節。
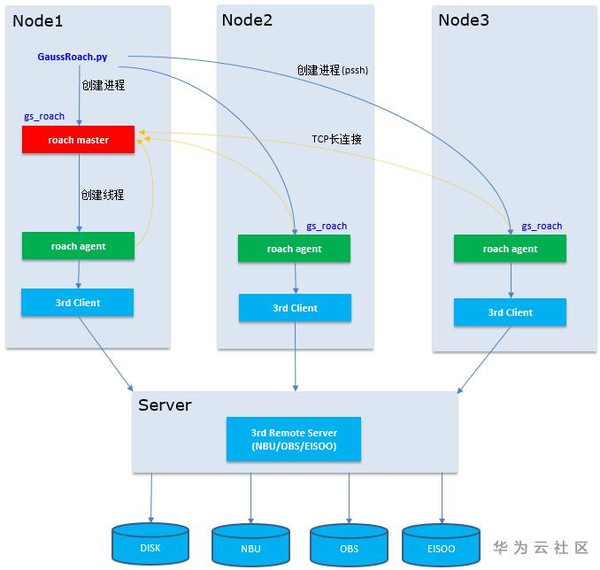
對於實現容災要求,需要解決的問題大體分三類:
- 快速的備份恢復
高效能備份、恢復操作保證在較短的時間內將資料遷移到另一個叢集,對於RPO/RTO要求不大的系統來說實現和使用非常簡單。
- 備份恢復在叢集可用的情況下即可進行,不受單點故障的影響
備份恢復在叢集可用的情況下就可以進行,叢集只需要保證有可用副本就可以持續的進行備份,並且可以正常恢復。
- 備份集的可靠性
備份集需要儲存在可靠的儲存上,類似 OBS/NBU, 由於磁碟故障率相對比較高,類似備份集儲存在磁碟上是非可靠的方案。
- 雙叢集備份增量同步技術
當前GaussDB(DWS)使用在備份/恢復的雙叢集架構來實現容災,將生產叢集的資料使用增量的方式同步到容災的叢集。
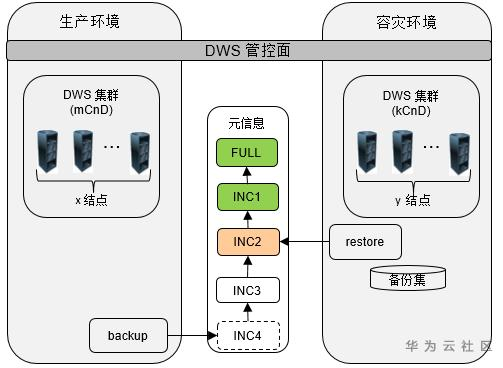
在這種架構下需要解決如下問題:
1.減少RPO
備份恢復無法達到與流式的同步方式的RPO, 做不到RPO=0的程度。
2.備叢集的可用性問題
- 備叢集支援持續讀/寫
備叢集是物理恢復的方式,無法支援寫的操作的;但是在恢復過程中是可以支援持續讀的,當前在恢復過程中需要停集群后將備份集中檔案覆蓋。
- 備叢集叢集恢復失敗可回退到一致性狀態
在恢復過程中會出結點故障,備份集損壞等等問題,會造成當前的恢復過程無法執行過去,此時需要回退到恢復前的狀態,保證備叢集的可用性。
- 備叢集恢復不受單點故障影響
對於備叢集來說,也會出現各種單點故障的情況,例項故障,結點故障,CN剔除等情況下,仍然可以把叢集恢復成可用的狀態。
- 備叢集支援備份
備叢集可以支援備份,用於擴充套件一些其它功能,實現類似多AZ,異地的容災。
3.備份集管理
- 備份集生命週期管理
容災是實現資料同步的功能,並非一個備份恢復場景,並不需要儲存大量備份集以及週期的去做全量備份,因此需要有一個機制實現備份集及時清理,保證佔用資源可按。
- 備份集的可靠性
在容災過程中,同樣考慮備份集的可靠性,防止備份集損壞情況,可以通過可靠的介質來儲存備份集,又能保證可靠的讀寫效能。
- 持續增量資料同步
保持持續的增量備份,類似升級前後,擴容前後,都要保持增量備份來保證同步的效能。這裡隱含著一個顯而易見的原因,如果全量備份的話,備份時間長,並且恢復進會將叢集清空,此時容災叢集不可用,這個嚴重影響可用性。可以說避免全量備份是基於Roach的雙叢集容災一個重要工作。
4. 雙叢集切換及Failover
- 快速切換
雙叢集的應用場景中,類似滾動升級,故障演練,此時需要切換兩個叢集,切換時要保證快速將兩邊資料拉平,儘快提供服務並保證可用性。
- Failover及之後的加回操作
由於RPO != 0,所以在生產叢集無法提供服務時,容災叢集在Failover操作後會提供讀寫服務,此時會有一部分資料丟失,並在兩個叢集的資料產生了“分叉”,那麼在生產叢集恢復後,加回之後中要將“分叉”的資料進行回退,以保證兩邊資料一致。
5. 異構的支援
此處異構是指邏輯結構DN數量一致,而CN數、結點數可以不相同的情況,眾所周知是由於當前方案是物理備份方式,因此如果DN數量發生變化,無法從物理層進行重分佈操作。
以上說明的幾點都是基於可靠性的角度來分析,還有一個重要的因素是基於數倉的資料量和叢集規模,不論備份/恢復方案還是在此基礎上的雙叢集備份增量同步的方案,對於網路頻寬,介質的讀寫效能有較高的要求,因此需要根據叢集規模和資料增量來選擇合適的組網方式和介質。
本文分享自華為雲社群《GaussDB(DWS)的容災應該如何設計》,原文作者:Puyol 。
點選關注,第一時間瞭解華為雲新鮮技