
Spark SQL解析查詢parquet格式Hive表獲取分割槽欄位和查詢條件
首先說一下,這裡解決的問題應用場景:
sparksql處理Hive表資料時,判斷載入的是否是分割槽表,以及分割槽表的欄位有哪些?再進一步限制查詢分割槽表必須指定分割槽?
這裡涉及到兩種情況:select SQL查詢和載入Hive表路徑的方式。這裡僅就"載入Hive表路徑的方式"解析分割槽表字段,在處理時出現的一些問題及解決作出詳細說明。
如果大家有類似的需求,筆者建議通過解析Spark SQL logical plan和下面說的這種方式解決方案結合,封裝成一個通用的工具。
問題現象
sparksql載入指定Hive分割槽表路徑,生成的DataSet沒有分割槽欄位。
如,
sparkSession.read.format("parquet").load(s"${hive_path}"),hive_path為Hive分割槽表在HDFS上的儲存路徑。
hive_path的幾種指定方式會導致這種情況的發生(test_partition是一個Hive外部分割槽表,dt是它的分割槽欄位,分割槽資料有dt為20200101和20200102):
1. hive_path為"/spark/dw/test.db/test_partition/dt=20200101"
2. hive_path為"/spark/dw/test.db/test_partition/*"
因為牽涉到的原始碼比較多,這裡僅以示例的程式中涉及到的原始碼中的class、object和方法,繪製成xmind圖如下,想細心研究的可以參考該圖到spark原始碼中進行分析。
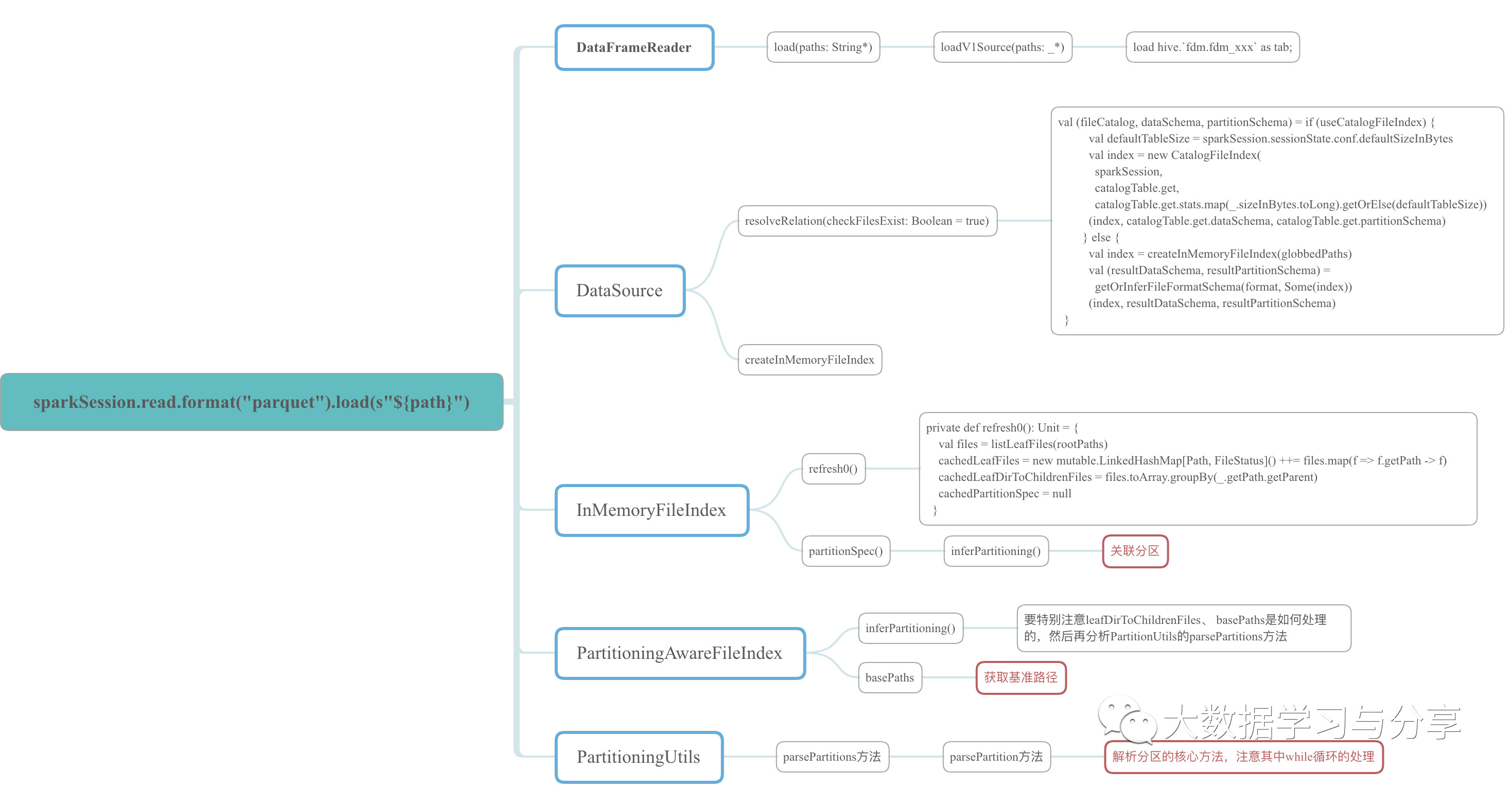
問題分析
我這裡主要給出幾個原始碼段,結合上述xmind圖理解:
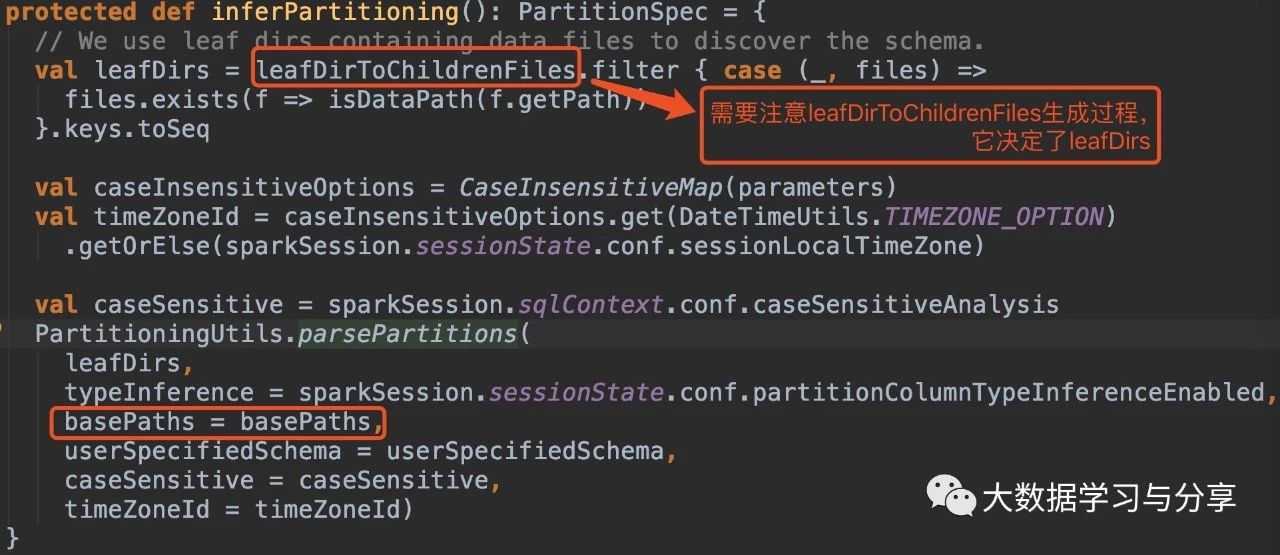
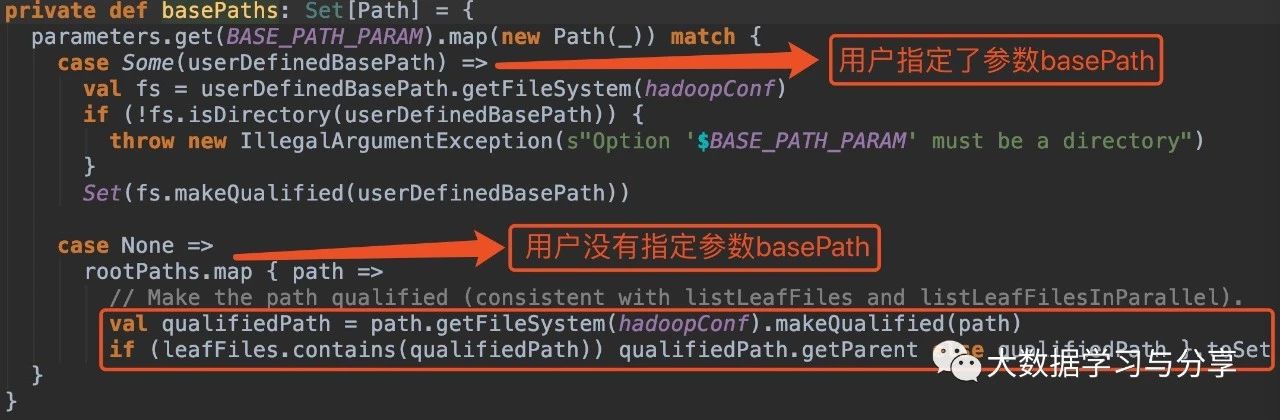
在沒有指定引數basePath的情況下:
1. hive_path為/spark/dw/test.db/test_partition/dt=20200101
sparksql底層處理後得到的basePaths: Set(new Path(“/spark/dw/test.db/test_partition/dt=20200101”))【虛擬碼】
leafDirs: Seq(new Path(“/spark/dw/test.db/test_partition/dt=20200101”))【虛擬碼】2. hive_path為/spark/dw/test.db/test_partition/*
sparksql底層處理後得到的basePaths: Set(new Path(“/spark/dw/test.db/test_partition/dt=20200101”),new Path(“/spark/dw/test.db/test_partition/dt=20200102”))【虛擬碼】
leafDirs: Seq(new Path(“/spark/dw/test.db/test_partition/dt=20200101”),new Path(“/spark/dw/test.db/test_partition/dt=20200102”))【虛擬碼】
這兩種情況導致原始碼if(basePaths.contains(currentPath))為true,還沒有解析分割槽就重置變數finished為true跳出迴圈,因此最終生成的結果也就沒有分割槽欄位:
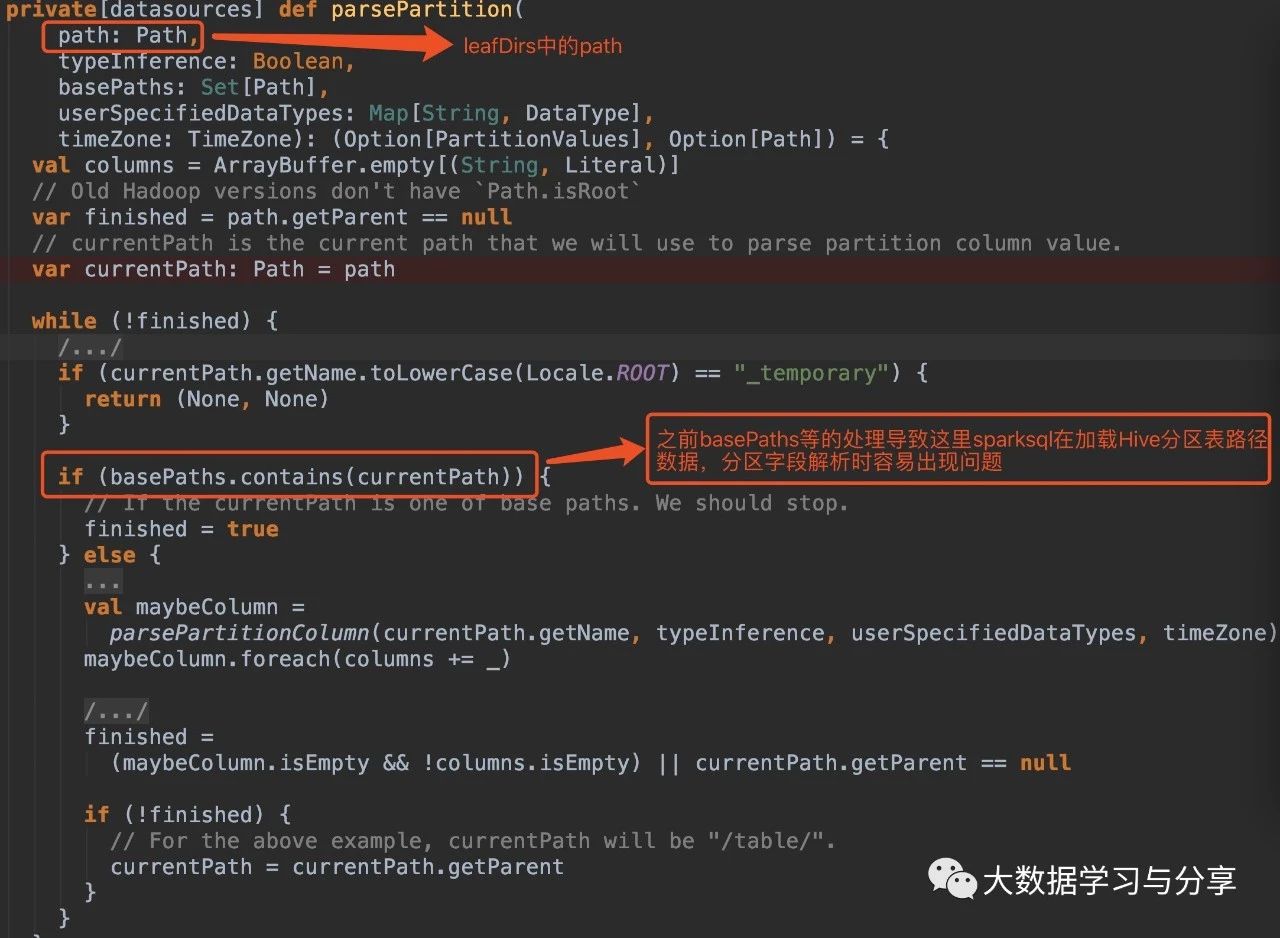
解決方案(親測有效)
1. 在Spark SQL載入Hive表資料路徑時,指定引數basePath,如
sparkSession.read.option("basePath","/spark/dw/test.db/test_partition")
2. 主要重寫basePaths方法和parsePartition方法中的處理邏輯,同時需要修改其他涉及的程式碼。由於涉及需要改寫的程式碼比較多,可以封裝成工具
關聯文章:
Spark SQL
Apache Hive
必須掌握的分散式檔案儲存系統—