
kafka 消費組功能驗證以及消費者資料重複資料丟失問題說明 3
阿新 • • 發佈:2020-12-04
[原創宣告:作者:Arnold.zhao 部落格園地址:https://www.cnblogs.com/zh94](https://www.cnblogs.com/zh94)
# 背景
[ 上一篇文章](https://www.cnblogs.com/zh94/p/14066638.html)記錄了kafka的副本機制和容錯功能的說明,本篇則主要在上一篇文章的基礎上,驗證多分割槽Topic的消費者的功能驗證;
目錄:
* [消費組功能驗證](#消費組功能驗證)
* [消費者與分割槽的對應關係總結](#消費者與分割槽的對應關係總結)
* [消費者資料重複問題說明](#消費者資料重複問題說明)
* [生產者的可靠性保證](#生產者的可靠性保證)
* [Kafka 生產者CP系統](#kafka生產者cp系統)
* [Kafka 生產者AP系統](#kafka生產者ap系統)
* [命令彙總](#上述命令彙總)
# 消費組功能驗證
新建1副本,2分割槽的Topic做測試驗證
```
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 2 --topic arnold_consumer_test
```
檢視對應的Topic分割槽情況
```
[root@dev bin]# ./kafka-topics.sh --describe --zookeeper 10.0.3.17:2181 --topic arnold_consumer_test
Topic:arnold_consumer_test PartitionCount:2 ReplicationFactor:1 Configs:
Topic: arnold_consumer_test Partition: 0 Leader: 1 Replicas: 1 Isr: 1
Topic: arnold_consumer_test Partition: 1 Leader: 2 Replicas: 2 Isr: 2
```
建立Topic每個分割槽只設置了一個副本及主副本,所以如上可看到,各分割槽所在的broker節點的情況。
配置消費者組group.id資訊為:test-consumer-group-arnold-1
```
修改 kafka下 config目錄下的consumer.properties,修改內容為:
bootstrap.servers=10.0.3.17:9092,10.0.6.39:9092,10.0.3.18:9092
group.id=test-consumer-group-arnold-1
```
分別在兩臺kafka伺服器上的 kafka 主目錄下啟動兩個消費者,並指定對應的消費者配置為 consumer.properties檔案,消費的Topic 為arnold_consumer_test topic
```
10.0.6.39啟動消費者
[gangtise@yinhua-ca000003 kafka_2.11-2.1.0]$ bin/kafka-console-consumer.sh --bootstrap-server 10.0.3.17:9092,10.0.6.39:9092,10.0.3.18:9092 --from-beginning --topic arnold_consumer_test --consumer.config config/consumer.properties
10.0.3.17 啟動消費者
[root@dev kafka_2.11-2.1.0]# bin/kafka-console-consumer.sh --bootstrap-server 10.0.3.17:9092,10.0.6.39:9092,10.0.3.18:9092 --from-beginning --topic arnold_consumer_test --consumer.config config/consumer.properties
兩個消費者都是使用的相同的consumer.properties檔案,即都是在一個消費組裡面(為什麼要在兩臺伺服器上啟動兩個消費者?不能在一個伺服器上啟動兩個消費者嗎?答:都可以,我之所以用兩個不同的伺服器啟動消費者是因為我當前39伺服器啟動消費者後,當前的shell程序就已經被佔用了,處於等待狀態,除非我再開一個39伺服器的會話,重新開一個消費者。)
```
OK,消費者啟動以後,觀察下消費者和Topic分割槽的對應情況
檢視當前所有的消費組的列表資訊
```
[root@dev bin]# ./kafka-consumer-groups.sh --bootstrap-server 10.0.3.17:9092 --list
test-consumer-group-arnold-1
test-consumer-group-arnold
test-consumer-group
```
如上,可以知道當前kafka伺服器上已有的消費組分別是有三個,而我們現在已經啟動了的消費者組是test-consumer-group-arnold-1,所以,詳細檢視下消費組test-consumer-group-arnold-1的詳細資訊
```
[root@dev bin]# ./kafka-consumer-groups.sh --bootstrap-server 10.0.3.17:9092 --describe --group test-consumer-group-arnold-1
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
arnold_consumer_test 0 19 19 0 consumer-1-2da16674-5b57-4e6c-9660-ab45de6ed5ae /10.0.6.39 consumer-1
arnold_consumer_test 1 19 19 0 consumer-1-917ecb37-3027-45de-b293-fe5125867432 /10.0.3.17 consumer-1
```
CURRENT-OFFSET: 當前消費組消費到的偏移量
LOG-END-OFFSET: 日誌最後的偏移量
CURRENT-OFFSET = LOG-END-OFFSET 說明當前消費組已經全部消費了;
LAG:表示落後未消費的資料量
可以看到當前topic arnold_consumer_test 的Partition 0分割槽對應的消費者id是
consumer-1-2da16674-5b57-4e6c-9660-ab45de6ed5ae,該消費者對應的host是
10.0.6.39;通過上述內容就可以很清晰的知道,當前所啟動的消費組下的兩個消費者分別對應消費的是topic的那個分割槽,OK進行下測試
啟動生產者生產資料
```
[root@dev bin]# ./kafka-console-producer.sh --broker-list 10.0.3.17:9092 --topic arnold_consumer_test
>message1
>message2
按照kafka的訊息路由策略,此時插入message1和message2兩條訊息,將會採用輪訓的策略分別插入到兩個分割槽中;(不清楚的話可以看下上篇的內容,這塊都有做過說明)
此時partition0分割槽中將會接收到 message1的訊息,partition2分割槽中將會接受到message2的訊息,然後又分別由partition0分割槽所對應的 10.0.6.39的消費者消費到對應的資料,partition1同理
此時檢視消費者的狀況如下:
10.0.6.39
[root@dev kafka_2.11-2.1.0]# bin/kafka-console-consumer.sh --bootstrap-server 10.0.3.17:9092,10.0.6.39:9092,10.0.3.18:9092 --from-beginning --topic arnold_consumer_test --consumer.config config/consumer.properties
message1
10.0.3.17
[gangtise@yinhua-ca000003 kafka_2.11-2.1.0]$ bin/kafka-console-consumer.sh --bootstrap-server 10.0.3.17:9092,10.0.6.39:9092,10.0.3.18:9092 --from-beginning --topic arnold_consumer_test --consumer.config config/consumer.properties
message2
```
驗證完畢,內容很簡單,但是想要表達記錄下來還真的是著實有些麻煩;所以,後續其他的一些規則,此處就直接放總結了,不再列出來實驗過程;
## 消費者與分割槽的對應關係總結
* topic 3個分割槽的情況,啟動一個消費者組且只有一個消費者,則該消費者會消費topic的3個分割槽;
* topic 3個分割槽的情況,啟動一個消費者組且只有兩個消費者c1,c2,則將會有一個消費者負責消費兩個分割槽,另外一個消費者負責消費一個分割槽;
* topic 3個分割槽的情況,啟動一個消費者組且有三個消費者c1,c2,c3,則正常對應分割槽消費,一個消費者對應一個partition分割槽;
* topic 3個分割槽的情況,啟動一個消費者組且有四個消費者c1,c2,c3,c4,則一般情況下沒有人這樣做。。。太愚蠢了。。。所以我也就沒做這個測試,但是按照kafka的規則來看,會有第四個消費者消費不到對應的分割槽,也就是不會消費到任何資料。。
上述的內容,則也是都可以通過使用kafka-consumer-groups.sh命令,檢視消費組下的消費者所對應的分割槽的情況即可得知對應的結果;
> 此時如果一個消費組已經在消費的情況下,此時又來了新的消費組進行消費,那就按照新的消費組規則來消費即可, 不會影響到其他消費組;舉例,此時一個消費組三個消費者,在進行資料的消費;此時新來了一個消費組,只有一個消費者,那麼此時這個消費者會消費所有的消費分割槽,不會和其他的消費組有任何的重疊,**原理是,kafka的消費組其實在kafka中也是一個消費者topic分割槽的概念,分割槽中記錄各個消費組的消費的offset位移資訊,以此保證所有的消費者所消費的內容的offset位移互不影響,關於這個概念後續會詳細說明一下,其實挺重要的。**
另外,上述只做了部分的測試驗證,便直接給出了最終的總結內容,對於部分測試內容並沒有再在本篇列出來(因為很多步驟其實都是重複的);但是,無意中發現了一個老哥的部落格,已經對這方面也做了詳細的測試,詳情還需要看剩下的測試方式的,可以[點選這個連結](https://www.cnblogs.com/sa-dan/p/8080197.html)檢視;
[原創宣告:作者:Arnold.zhao 部落格園地址:https://www.cnblogs.com/zh94](https://www.cnblogs.com/zh94)
# 消費者資料重複問題說明
本來這篇文章在上述的消費者和Partition的關係介紹完以後也就結束了,但是在寫完以後,翻了下部落格園的首頁發現有一個推薦的kafka的帖子就順手點進去想get點技能,然後結果有點傷心,文章中對於一些kafka資料重複的問題一筆帶過。。甚至沒有說明為什麼kakfa會出現資料重複的問題,只是說這是kafka的一種自我保護的機制產生的。。。這,就很傷心,於是本篇內容再對kafka資料重複的問題做一下說明,這些問題早晚也都要記錄的。
對於kafka的使用上,其實Java程式碼的實現是相對簡單的,網上的內容也有很多,但是如果對於kafka的一些基本概念就不熟悉的話,在使用過程中便會出現很多懵逼的事情,所以這篇文章包括前兩篇的文章,則都是重點在說kafka的一些機制的問題,當然後續對於kafka java的一些配置和實現,也會做一些記錄說明。
> 回到問題本身,為什麼kafka有時候會出現消費者的資料重複問題?首先,消費者的資料本身是來自於生產者生產的資料,所以瞭解生產者所生產資料的可靠性機制,便和當前的問題有這直接的關聯了。
## 生產者的可靠性保證
生產者的資料可靠性,在配置上是根據kafka 生產者的 Request.required.acks 來配置生產者訊息可靠性;
```
Request.required.acks=-1 (ISR全量同步確認,強可靠性保證)
Request.required.acks = 1(leader 確認收到,無需保證其它副本也確認收到, 預設)
Request.required.acks = 0 (不確認,但是吞吐量大)
```
在分散式的系統中,有一個對應的ACP理論,分別是:
* 可用性(Availability):在叢集中一部分節點故障後,叢集整體是否還能響應客戶端的讀寫請求。(對資料更新具備高可用性)
* 一致性(Consistency):在分散式系統中的所有資料備份,在同一時刻是否同樣的值。(等同於所有節點訪問同一份最新的資料副本)
* 分割槽容忍性(Partition tolerance):以實際效果而言,分割槽相當於對通訊的時限要求。系統如果不能在時限內達成資料一致性,就意味著發生了分割槽的情況,必須就當前操作在C和A之間做出選擇。
在分散式系統的設計中,沒有一種設計可以同時滿足一致性,可用性,分割槽容錯性 3個特性;所以kafka也不例外;
### Kafka 生產者CP系統
**如果想實現 kafka 配置為 CP(Consistency & Partition tolerance) 系統, 配置需要如下:**
```
request.required.acks=-1
min.insync.replicas = ${N/2 + 1}
unclean.leader.election.enable = false
```
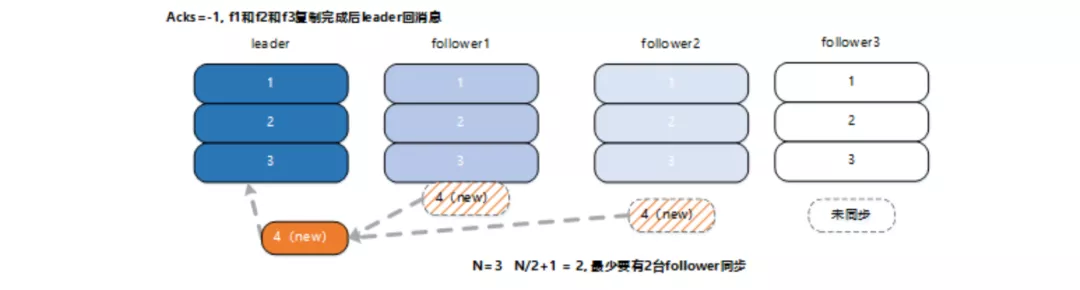
如圖所示,在 acks=-1 的情況下,新訊息只有被 ISR 中的所有 follower(f1 和 f2, f3) 都從 leader 複製過去才會回 ack, ack 後,無論那種機器故障情況(全部或部分), 寫入的 msg4,都不會丟失, 訊息狀態滿足一致性 C 要求。
正常情況下,所有 follower 複製完成後,leader 回 producer ack。
**異常情況下,如果當資料傳送到 leader 後部分副本(f1 和 f2 同步), leader 掛了?此時任何 follower 都有可能變成新的 leader, producer 端會得到返回異常,此時producer端會重新發送資料,此時資料重複**
解決消費重複的方式有很多啊,第一個就是你的業務場景無需在意資料重複的問題,這個自然也就業務上解決了;第二個則是消費者自己做一層快取過濾即可,因為生產資料重複畢竟是節點down機才會出現的問題,在down機的這一剎那沒有被同步到follower的資料並不會很多,所以,以資料量為快取,或者以時間為快取都可以解決這個問題,比如加一個快取區,只要判斷資料重複了則不再重複消費即可,然後當快取的資料超過了1M,則清除一次快取區;或者直接快取到redis中,使用redis api來去重,定時清理一下redis中的資料也可以;
--------
除了生產者資料重複外,還有一種問題是,生產者資料沒有重複,**但是消費者消費的資料重複了**,這種問題,則是由於消費者offset自動提交的問題,如,消費者offset是1s提交一次,此時0.5s消費了5條資料,但是消費者還沒有到1s自動提交的時候,消費者掛掉,此時已經消費的5條資料的偏移量由於沒有提交到kafka,所以kafka中是沒有記錄到當前已經消費到的偏移量的,此時消費者重啟,則會從5條資料前重新消費,這個問題一般比較好解決,因為大多數情況下如果使用消費者手動提交的模式,一般不會出現這種問題(手動提交的情況下如果出現異常,沒有執行提交程式碼,那麼程式碼中做好資料消費的回滾操作即可,更加可控);
**除了資料重複的情況,另外一種問題,則是kafka資料丟失的問題**
首先按照上述的kafka的cp系統的配置方式,是絕對不會出現資料丟失的情況的,因為要麼各節點不工作,要麼各節點資料同步完成後,才會返回ack,此時訊息不會丟失且訊息狀態一致;
### Kafka 生產者AP系統
**除了配置kakfa為cp系統外,還可以配置kafka為AP(Availability & Partition tolerance)系統**
```
request.required.acks=1
min.insync.replicas = 1
unclean.leader.election.enable = false
```
AP系統下生產者的吞吐量相對更高,但是由於request.required.acks 配置為1,即leader主副本收到訊息便直接返回ack,此時如果leader接收到生產者訊息後,返回了ack的標識,但是此時副本節點還都沒有進行同步,此時leader節點掛掉,重新進行leader選舉,新的follower選為leader後,則此時訊息丟失;
所以根據合適的業務場景,使用合適的kafka模式則是最佳的選擇。
[原創宣告:作者:Arnold.zhao 部落格園地址:https://www.cnblogs.com/zh94](https://www.cnblogs.com/zh94)
# 上述命令彙總
```
新建Topic
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 2 --topic arnold_consumer_test
檢視Topic詳細資訊
[root@dev bin]# ./kafka-topics.sh --describe --zookeeper 10.0.3.17:2181 --topic arnold_consumer_test
Topic:arnold_consumer_test PartitionCount:2 ReplicationFactor:1 Configs:
Topic: arnold_consumer_test Partition: 0 Leader: 1 Replicas: 1 Isr: 1
Topic: arnold_consumer_test Partition: 1 Leader: 2 Replicas: 2 Isr: 2
啟動消費者
bin/kafka-console-consumer.sh --bootstrap-server 10.0.3.17:9092,10.0.6.39:9092,10.0.3.18:9092 --from-beginning --topic arnold_consumer_test --consumer.config config/consumer.properties
啟動生產者
./kafka-console-producer.sh --broker-list 10.0.3.17:9092 --topic arnold_consumer_test
檢視當前所有的消費組的列表資訊
./kafka-consumer-groups.sh --bootstrap-server 10.0.3.17:9092 --list test-consumer-group-arnold-1
檢視消費者組的詳細資訊
[root@dev bin]# ./kafka-consumer-groups.sh --bootstrap-server 10.0.3.17:9092 --describe --group test-consumer-group-arnold-1
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
arnold_consumer_test 0 19 19 0 consumer-1-2da16674-5b57-4e6c-9660-ab45de6ed5ae /10.0.6.39 consumer-1
arnold_consumer_test 1 19 19 0 consumer-1-917ecb37-3027-45de-b293-fe5125867432 /10.0.3.17 consumer-1
```
---------------
[文章來源於本人的印象筆記,如出現格式問題可訪問該連結檢視原文](https://app.yinxiang.com/fx/b22b205a-e463-4d17-99e4-f91d9d0faa5a)
[原創宣告:作者:Arnold.zhao 部落格園地址:https://www.cnblogs.com/zh94](https://www.cnblogs.c