
冰河開源了全網首個完全開源的分散式全域性有序序列號(分散式ID)框架!!
阿新 • • 發佈:2020-12-06
## 寫在前面
> mykit-serial框架的設計參考了李豔鵬大佬開源的vesta框架,並徹底重構了vesta框架,借鑑了雪花演算法(SnowFlake)的思想,並在此基礎上進行了全面升級和優化。支援嵌入式(Jar包)、RPC(Dubbo,motan、sofa、SpringCloud、SpringCloud Alibaba等主流的RPC框架)、Restful API(支援SpringBoot和Netty),可支援最大峰值型和最小粒度型兩種模式。
>
> 開源地址:
>
> GitHub:[https://github.com/sunshinelyz/mykit-serial](https://github.com/sunshinelyz/mykit-serial)
>
> Gitee:[https://gitee.com/binghe001/mykit-serial](https://gitee.com/binghe001/mykit-serial)
## 為何不用資料庫自增欄位?
如果在業務系統中使用資料庫的自增欄位,自增欄位完全依賴於資料庫,這在資料庫移植,擴容,清洗資料,分庫分表等操作時帶來很多麻煩。
在資料庫分庫分表時,有一種辦法是通過調整自增欄位或者資料庫sequence的步長來達到跨資料庫的ID的唯一性,但仍然是一種強依賴資料庫的解決方案,有諸多的限制,並且強依賴資料庫型別,如果我們想增加一個數據庫例項或者將業務遷移到一種不同型別的資料庫上,那是相當麻煩的。
## 為什麼不用UUID?
UUID雖然能夠保證ID的唯一性,但是,它無法滿足業務系統需要的很多其他特性,例如:時間粗略有序性,可反解和可製造型。另外,UUID產生的時候使用完全的時間資料,效能比較差,並且UUID比較長,佔用空間大,間接導致資料庫效能下降,更重要的是,UUID並不具有有序性,這就導致B+樹索引在寫的時候會有過多的隨機寫操作(連續的ID會產生部分順序寫),另外寫的時候由於不能產生順序的append操作,需要進行insert操作,這會讀取整個B+樹節點到記憶體,然後插入這條記錄後再將整個節點寫回磁碟,這種操作在記錄佔用空間比較大的情況下,效能下降比較大。所以,不建議使用UUID。
## 需要考慮的問題
既然資料庫自增ID和UUID有諸多的限制,我們就需要考慮如何設計一款分散式全域性唯一的序列號(分散式ID)服務。這裡,我們需要考慮如下一些因素。
### 全域性唯一
分散式系統保證全域性唯一的一個悲觀策略是使用鎖或者分散式鎖,但是,只要使用了鎖,就會大大的降低效能。
因此,我們可以借鑑Twitter的SnowFlake演算法,利用時間的有序性,並且在時間的某個單元下采用自增序列,達到全域性的唯一性。
### 粗略有序
UUID的最大問題就是無序的,任何業務都希望生成的ID是有序的,但是,分散式系統中要做到完全有序,就涉及到資料的匯聚,需要用到鎖或者分散式鎖,考慮到效率,需要採用折中的方案,粗略有序。目前有兩種主流的方案,一種是秒級有序,一種是毫秒級有序,這裡又有一個權衡和取捨,我們決定支援兩種方式,通過配置來決定服務使用其中的一種方式。
### 可反解
一個 ID 生成之後,ID本身帶有很多資訊量,線上排查的時候,我們通常首先看到的是ID,如果根據ID就能知道什麼時候產生的,從哪裡來的,這樣一個可反解的 ID 可以幫上很多忙。
如果ID 裡有了時間而且能反解,在儲存層面就會省下很多傳統的timestamp 一類的欄位所佔用的空間了,這也是一舉兩得的設計。
### 可製造
一個系統即使再高可用也不會保證永遠不出問題,出了問題怎麼辦,手工處理,資料被汙染怎麼辦,洗資料,可是手工處理或者洗資料的時候,假如使用資料庫自增欄位,ID已經被後來的業務覆蓋了,怎麼恢復到系統出問題的時間視窗呢?
所以,我們使用的分散式全域性序列號(分散式ID)服務一定要可複製,可恢復 ,可製造。
### 高效能
不管哪個業務,訂單也好,商品也好,如果有新記錄插入,那一定是業務的核心功能,對效能的要求非常高,ID生成取決於網路IO和CPU的效能,CPU一般不是瓶頸,根據經驗,單臺機器TPS應該達到10000/s。
### 高可用
首先,分散式全域性序列號(分散式ID)服務必須是一個對等的叢集,一臺機器掛掉,請求必須能夠轉發到其他機器,另外,重試機制也是必不可少的。最後,如果遠端服務宕機,我們需要有本地的容錯方案,本地庫的依賴方式可以作為高可用的最後一道屏障。
也就是說,我們支援RPC釋出模式,嵌入式釋出模式和REST釋出模式,如果某種模式不可用,可以回退到其他釋出模式,如果Zookeeper不可用,可以會退到使用本地預配的機器ID。從而達到服務的最大可用。
### 可伸縮
作為一個分散式系統,永遠都不能忽略的就是業務在不斷地增長,業務的絕對容量不是衡量一個系統的唯一標準,要知道業務是永遠增長的,所以,系統設計不但要考慮能承受的絕對容量,還必須考慮業務增長的速度,系統的水平伸縮是否能滿足業務的增長速度是衡量一個系統的另一個重要標準。
## 設計與實現
### 整體架構設計
mykit-serial的整體架構圖如下所示。
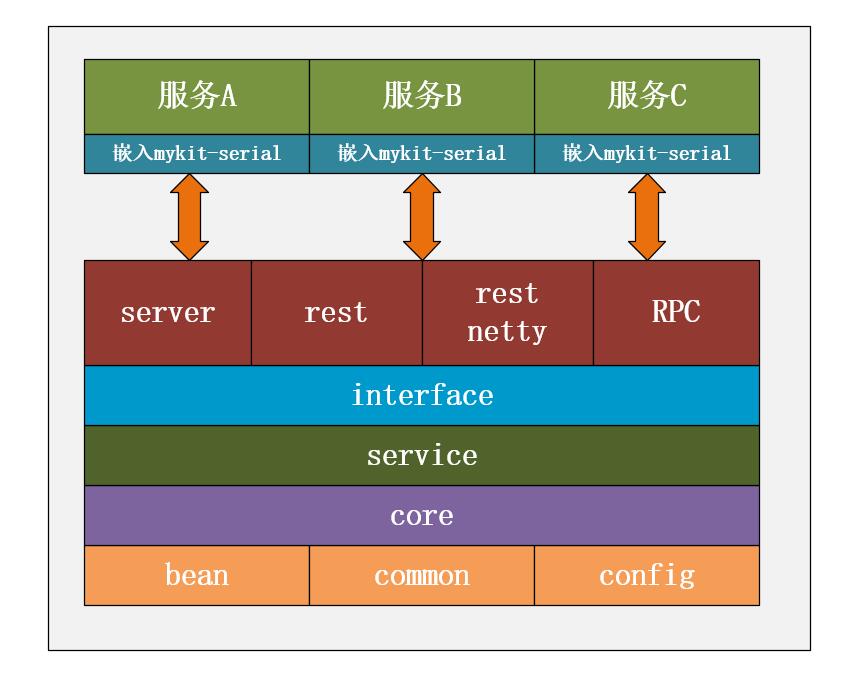
mykit-serial框架各模組的含義如下:
* mykit-bean:提供統一的bean類封裝和整個框架使用的常量等資訊。
* mykit-common:封裝整個框架通用的工具類。
* mykit-config:提供全域性配置能力。
* mykit-core:整個框架的核心實現模組。
* mykit-db:存放資料庫指令碼。
* mykit-interface:整個框架的核心抽象介面。
* mykit-service:基於Spring實現的核心功能。
* mykit-rpc:以RPC方式對外提供服服務(後續支援Dubbo,motan、sofa、SpringCloud、SpringCloud Alibaba等主流的RPC框架)。
* mykit-server:目前實現了Dubbo方式,後續遷移到mykit-rpc模組。
* mykit-rest:基於SpringBoot實現的Rest服務。
* mykit-rest_netty:基於Netty實現的Rest服務。
* mykit-test:整個框架的測試模組,通過此模組可以快速掌握mykit-serial的使用方式。
### 釋出模式
根據最終的客戶使用方式,可分為嵌入釋出模式,RPC釋出模式和Rest釋出模式。
1. **嵌入釋出模式**:只適用於Java客戶端,提供一個本地的Jar包,Jar包是嵌入式的原生服務,需要提前配置本地機器ID(或者服務啟動時,由Zookeeper動態分配唯一的分散式序列號),但是不依賴於中心伺服器。
2. **RPC釋出模式**:只適用於Java客戶端,提供一個服務的客戶端Jar包,Java程式像呼叫本地API一樣來呼叫,但是依賴於中心的分散式序列號(分散式ID)產生伺服器。
3. **REST釋出模式**:中心伺服器通過Restful API提供服務,供非Java語言客戶端使用。
釋出模式最後會記錄在生成的全域性序列號中。
### 序列號型別
根據時間的位數和序列號的位數,可分為最大峰值型和最小粒度型。
**1. 最大峰值型**:採用秒級有序,秒級時間佔用30位,序列號佔用20位
| 欄位 | 版本 | 型別 | 生成方式 | 秒級時間 | 序列號 | 機器ID |
| :--: | :--: | :--: | :------: | :------: | :----: | :----: |
| 位數 | 63 | 62 | 60-61 | 30-59 | 10-29 | 0-9 |
**2. 最小粒度型**:採用毫秒級有序,毫秒級時間佔用40位,序列號佔用10位
| 欄位 | 版本 | 型別 | 生成方式 | 毫秒級時間 | 序列號 | 機器ID |
| :--: | :--: | :--: | :------: | :--------: | :----: | :----: |
| 位數 | 63 | 62 | 60-61 | 20-59 | 10-19 | 0-9 |
最大峰值型能夠承受更大的峰值壓力,但是粗略有序的粒度有點大,最小粒度型有較細緻的粒度,但是每個毫秒能承受的理論峰值有限,為1024,同一個毫秒如果有更多的請求產生,必須等到下一個毫秒再響應。
分散式序列號(分散式ID)的型別在配置時指定,需要重啟服務才能互相切換。
### 資料結構
**1. 序列號**
最大峰值型
20位,理論上每秒內平均可產生2^20= 1048576個ID,百萬級別,如果系統的網路IO和CPU足夠強大,可承受的峰值達到每毫秒百萬級別。
最小粒度型
10位,每毫秒內序列號總計2^10=1024個, 也就是每個毫秒最多產生1000+個ID,理論上承受的峰值完全不如我們最大峰值方案。
**2. 秒級時間/毫秒級時間**
最大峰值型
30位,表示秒級時間,2^30/60/60/24/365=34,也就是可使用30+年。
最小粒度型
40位,表示毫秒級時間,2^40/1000/60/60/24/365=34,同樣可以使用30+年。
**3. 機器ID**
10位, 2^10=1024, 也就是最多支援1000+個伺服器。中心釋出模式和REST釋出模式一般不會有太多數量的機器,按照設計每臺機器TPS 1萬/s,10臺伺服器就可以有10萬/s的TPS,基本可以滿足大部分的業務需求。
但是考慮到我們在業務服務可以使用內嵌釋出方式,對機器ID的需求量變得更大,這裡最多支援1024個伺服器。
**4. 生成方式**
2位,用來區分三種釋出模式:嵌入釋出模式,RPC釋出模式,REST釋出模式。
>**00**:嵌入釋出模式
>**01**:RPC釋出模式
>**02**:REST釋出模式
>**03**:保留未用
**5. 序列號型別**
1位,用來區分兩種ID型別:最大峰值型和最小粒度型。
>**0**:最大峰值型
>**1**:最小粒度型
**6. 版本**
1位,用來做擴充套件位或者擴容時候的臨時方案。
>**0**:預設值,以免轉化為整型再轉化回字符串被截斷
>**1**:表示擴充套件或者擴容中
作為30年後擴充套件使用,或者在30年後ID將近用光之時,擴充套件為秒級時間或者毫秒級時間來掙得系統的移植時間視窗,其實只要擴充套件一位,完全可以再使用30年。
### 併發處理
對於中心伺服器和REST釋出方式,ID生成的過程涉及到網路IO和CPU操作,ID的生成基本都是記憶體到快取記憶體的操作,沒有IO操作,網路IO是系統的瓶頸。
相對於CPU計算速度來說網路IO是瓶頸,因此,ID產生的服務使用多執行緒的方式,對於ID生成過程中的競爭點time和sequence,這裡使用了多種實現方式
> 1. 使用concurrent包的ReentrantLock進行互斥,這是預設的實現方式,也是追求效能和穩定兩個目標的妥協方案。
> 1. 使用傳統的synchronized進行互斥,這種方式的效能稍微遜色一些,通過傳入JVM引數-Dmykit.serial.sync.lock.impl.key=true來開啟。
> 1. 使用CAS方式進行互斥,這種實現方式的效能非常高,但是在高併發環境下CPU負載會很高,通過傳入JVM引數-Dmykit.serial.atomic.impl.key=true來開啟。
### 機器ID的分配
我們將機器ID分為兩個區段,一個區段服務於RPC釋出模式和REST釋出模式,另外一個區段服務於嵌入釋出模式。
0-923:嵌入釋出模式,預先配置,(或者由Zookeeper產生),最多支援924臺內嵌伺服器
924 – 1023:中心伺服器釋出模式和REST釋出模式,最多支援300臺,最大支援300*1萬=300萬/s的TPS
如果嵌入式釋出模式和RPC釋出模式以及REST釋出模式的使用量不符合這個比例,我們可以動態調整兩個區間的值來適應。
另外,各個垂直業務之間具有天生的隔離性,每個業務都可以使用最多1024臺伺服器。
### 與Zookeeper整合
對於嵌入釋出模式,服務啟動需要連線Zookeeper叢集,Zookeeper分配一個0-923區間的一個ID,如果0-923區間的ID被用光,Zookeeper會分配一個大於923的ID,這種情況,拒絕啟動服務。
如果不想使用Zookeeper產生的唯一的機器ID,我們提供預設的預配的機器ID解決方案,每個使用統一分散式全域性序列號(分散式ID)服務的服務需要預先配置一個預設的機器ID。
### 時間同步
使用mykit-serial生成分散式全域性序列號(分散式ID)時,需要我們保證伺服器的時間正常。此時,我們可以使用Linux的定時任務crontab,定時通過授時伺服器虛擬叢集(全球有3000多臺伺服器)來核准伺服器的時間。
>**ntpdate -u pool.ntp.orgpool.ntp.org**
## 效能
最終的效能驗證要保證每臺伺服器的TPS達到1萬/s以上。
## Restful API文件
### 產生分散式全域性序列號
- 描述:根據系統時間產生一個全域性唯一的全域性序列號並且在方法體內返回。
- 路徑:/genSerialNumber
- 引數:N/A
- 非空引數:N/A
- 示例:http://localhost:8080/genSerialNumber
- 結果:3456526092514361344
### 反解全域性序列號
- 描述:對產生的serialNumber進行反解,在響應體內返回反解的JSON字串。
- 路徑:/expSerialNumber
- 引數:serialNumber=?
- 非空引數:serialNumber
- 示例:http://localhost:8080/expSerialNumber?serialNumber=3456526092514361344
- 結果:{"genMethod":2,"machine":1022,"seq":0,"time":12758739,"type":0,"version":0}
### 翻譯時間
- 描述:把長整型的時間轉化成可讀的格式。
- 路徑:/transtime
- 引數:time=?
- 非空引數:time
- 示例:http://localhost:8080/transtime?time=12758739
- 結果:Thu May 28 16:05:39 CST 2015
### 製造全域性序列號
- 描述:通過給定的分散式全域性序列號元素製造分散式全域性序列號。
- 路徑:/makeSerialNumber
- 引數:genMethod=?&machine=?&seq=?&time=?&type=?&version=?
- 非空引數:time,seq
- 示例:http://localhost:8080/makeSerialNumber?genMethod=2&machine=1022&seq=0&time=12758739&type=0&version=0
- 結果:3456526092514361344
## Java API文件
### 產生全域性序列號
- 描述:根據系統時間產生一個全域性唯一的分散式序列號(分散式ID)並且在方法體內返回。
- 類:SerialNumberService
- 方法:genSerialNumber
- 引數:N/A
- 返回型別:long
- 示例:long serialNumber= serialNumberService.genSerialNumber();
### 反解全域性序列號
- 描述:對產生的分散式序列號(分散式ID)進行反解,在響應體內返回反解的JSON字串。
- 類:SerialNumberService
- 方法:expSerialNumber
- 引數:long serialNumber
- 返回型別:SerialNumber
- 示例:SerialNumber serialNumber = serialNumberService.expSerialNumber(3456526092514361344);
### 翻譯時間
- 描述:把長整型的時間轉化成可讀的格式。
- 類:SerialNumberService
- 方法:transTime
- 引數:long time
- 返回型別:Date
- 示例:Date date = serialNumberService.transTime(12758739);
### 製造全域性序列號(1)
- 描述:通過給定的分散式序列號元素製造分散式序列號。
- 類:SerialNumberService
- 方法:makeSerialNumber
- 引數:long time, long seq
- 返回型別:long
- 示例:long serialNumber= SerialNumberService.makeSerialNumber(12758739, 0);
### 製造全域性序列號(2)
- 描述:通過給定的ID元素製造ID。
- 類:SerialNumberService
- 方法:makeSerialNumber
- 引數:long machine, long time, long seq
- 返回型別:long
- 示例:long serialNumber= serialNumberService.makeSerialNumber(1, 12758739, 0);
### 製造全域性序列號(3)
- 描述:通過給定的分散式序列號元素製造ID。
- 類:SerialNumberService
- 方法:makeSerialNumber
- 引數:long genMethod, long machine, long time, long seq
- 返回型別:long
- 示例:long serialNumber= serialNumberService.makeSerialNumber(0, 1, 12758739, 0);
### 製造全域性序列號(4)
- 描述:通過給定的分散式序列號元素製造ID。
- 類:SerialNumberService
- 方法:makeSerialNumber
- 引數:long type, long genMethod, long machine, long time, long seq
- 返回型別:long
- 示例:long serialNumber= serialNumberService.makeSerialNumber(0, 2, 1, 12758739, 0);
### 製造全域性序列號(5)
- 描述:通過給定的ID元素製造ID。
- 類:SerialNumberService
- 方法:makeSerialNumber
- 引數:long version, long type, long genMethod, long machine, long time, long seq
- 返回型別:long
- 示例:long serialNumber = serialNumberService.makeSerialNumber(0, 0, 2, 1, 12758739, 0);
## FAQ
**1.調整時間是否會影響ID產生功能?**
未重啟機器調慢時間,mykit-serial丟擲異常,拒絕產生ID。重啟機器調快時間,調整後正常產生ID,調整時段內沒有ID產生。
**2.重啟調慢或調快時間有何影響?**
重啟機器調慢時間,mykit-serial將可能產生重複的時間,系統管理員需要保證不會發生這種情況。重啟機器調快時間,調整後正常產生ID,調整時段內沒有ID產生。
**3.每4年一次同步潤秒會不會影響ID產生功能?**
原子時鐘和電子時鐘每四年誤差為1秒,也就是說電子時鐘每4年會比原子時鐘慢1秒,所以,每隔四年,網路時鐘都會同步一次時間,但是本地機器Windows,Linux等不會自動同步時間,需要手工同步,或者使用ntpupdate向網路時鐘同步。由於時鐘是調快1秒,調整後不影響ID產生,調整的1s內沒有ID產生。
**好了今天就到這兒吧,我是冰河,我們下期見~~**
## 重磅福利
微信搜一搜【冰河技術】微信公眾號,關注這個有深度的程式設計師,每天閱讀超硬核技術乾貨,公眾號內回覆【PDF】有我準備的一線大廠面試資料和我原創的超硬核PDF技術文件,以及我為大家精心準備的多套簡歷模板(不斷更新中),希望大家都能找到心儀的工作,學習是一條時而鬱鬱寡歡,時而開懷大笑的路,加油。如果你通過努力成功進入到了心儀的公司,一定不要懈怠放鬆,職場成長和新技術學習一樣,不進則退。如果有幸我們江湖再見!
另外,我開源的各個PDF,後續我都會持續更新和維護,感謝大家長期以來對冰河的支