
Java 中的語法糖,真甜。
阿新 • • 發佈:2020-12-08
> 我把自己以往的文章彙總成為了 Github ,歡迎各位大佬 star
> https://github.com/crisxuan/bestJavaer
我們在日常開發中經常會使用到諸如**泛型、自動拆箱和裝箱、內部類、增強 for 迴圈、try-with-resources 語法、lambda 表示式**等,我們只覺得用的很爽,因為這些特效能夠幫助我們減輕開發工作量;但我們未曾認真研究過這些特性的本質是什麼,那麼這篇文章,cxuan 就來為你揭開這些特性背後的真相。
## 語法糖
在聊之前我們需要先了解一下 `語法糖` 的概念:`語法糖(Syntactic sugar)`,也叫做糖衣語法,是英國科學家發明的一個術語,通常來說使用語法糖能夠增加程式的`可讀性`,從而減少程式程式碼出錯的機會,真是又香又甜。
語法糖指的是計算機語言中新增的某種語法,**這種語法對語言的功能並沒有影響,但是更方便程式設計師使用**。因為 Java 程式碼需要執行在 JVM 中,**JVM 是並不支援語法糖的,語法糖在程式編譯階段就會被還原成簡單的基礎語法結構,這個過程就是`解語法糖`**。所以在 Java 中,真正支援語法糖的是 Java 編譯器,真是換湯不換藥,萬變不離其宗,關了燈都一樣。。。。。。
下面我們就來認識一下 Java 中的這些語法糖
### 泛型
泛型是一種語法糖。在 JDK1.5 中,引入了泛型機制,但是泛型機制的本身是通過`型別擦除` 來實現的,在 JVM 中沒有泛型,只有普通型別和普通方法,泛型類的型別引數,在編譯時都會被擦除。泛型並沒有自己獨特的 Class型別。如下程式碼所示
```java
List aList = new ArrayList();
List bList = new ArrayList();
System.out.println(aList.getClass() == bList.getClass());
```
`List` 和 `List` 被認為是不同的型別,但是輸出卻得到了相同的結果,這是因為,**泛型資訊只存在於程式碼編譯階段,在進入 JVM 之前,與泛型相關的資訊會被擦除掉,專業術語叫做型別擦除**。但是,如果將一個 Integer 型別的資料放入到 `List` 中或者將一個 String 型別的資料放在 `List` 中是不允許的。
如下圖所示
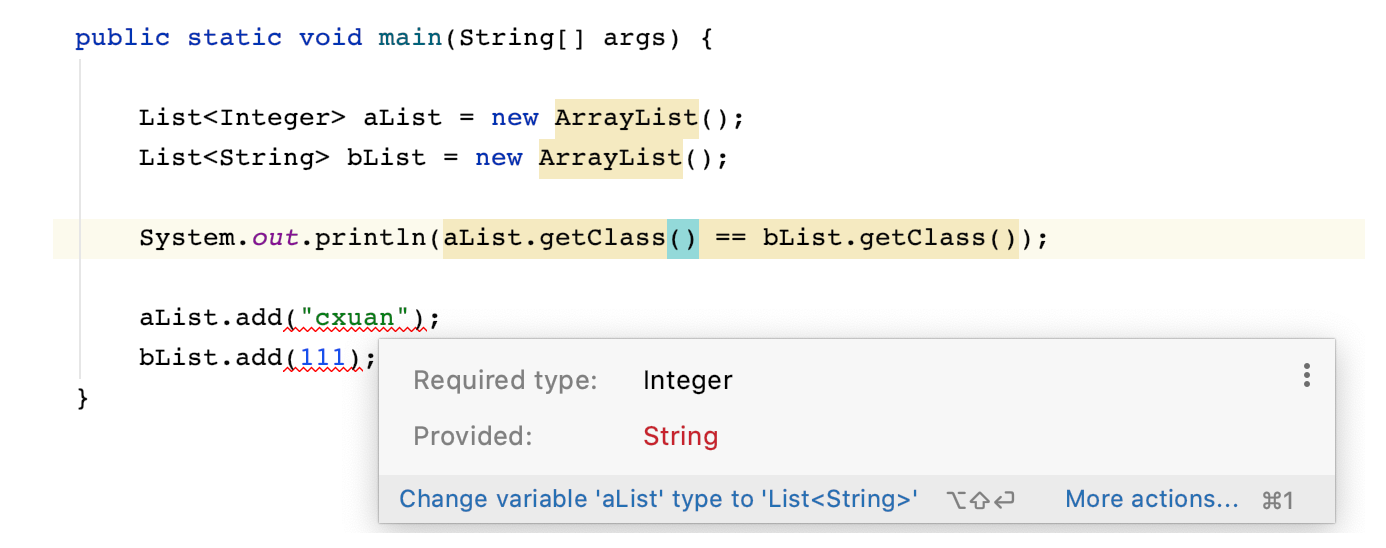
無法將一個 Integer 型別的資料放在 `List` 和無法將一個 String 型別的資料放在 `List` 中是一樣會編譯失敗。
### 自動拆箱和自動裝箱
自動拆箱和自動裝箱是一種語法糖,它說的是八種基本資料型別的包裝類和其基本資料型別之間的自動轉換。簡單的說,裝箱就是自動將基本資料型別轉換為`包裝器`型別;拆箱就是自動將包裝器型別轉換為基本資料型別。
我們先來了解一下基本資料型別的包裝類都有哪些
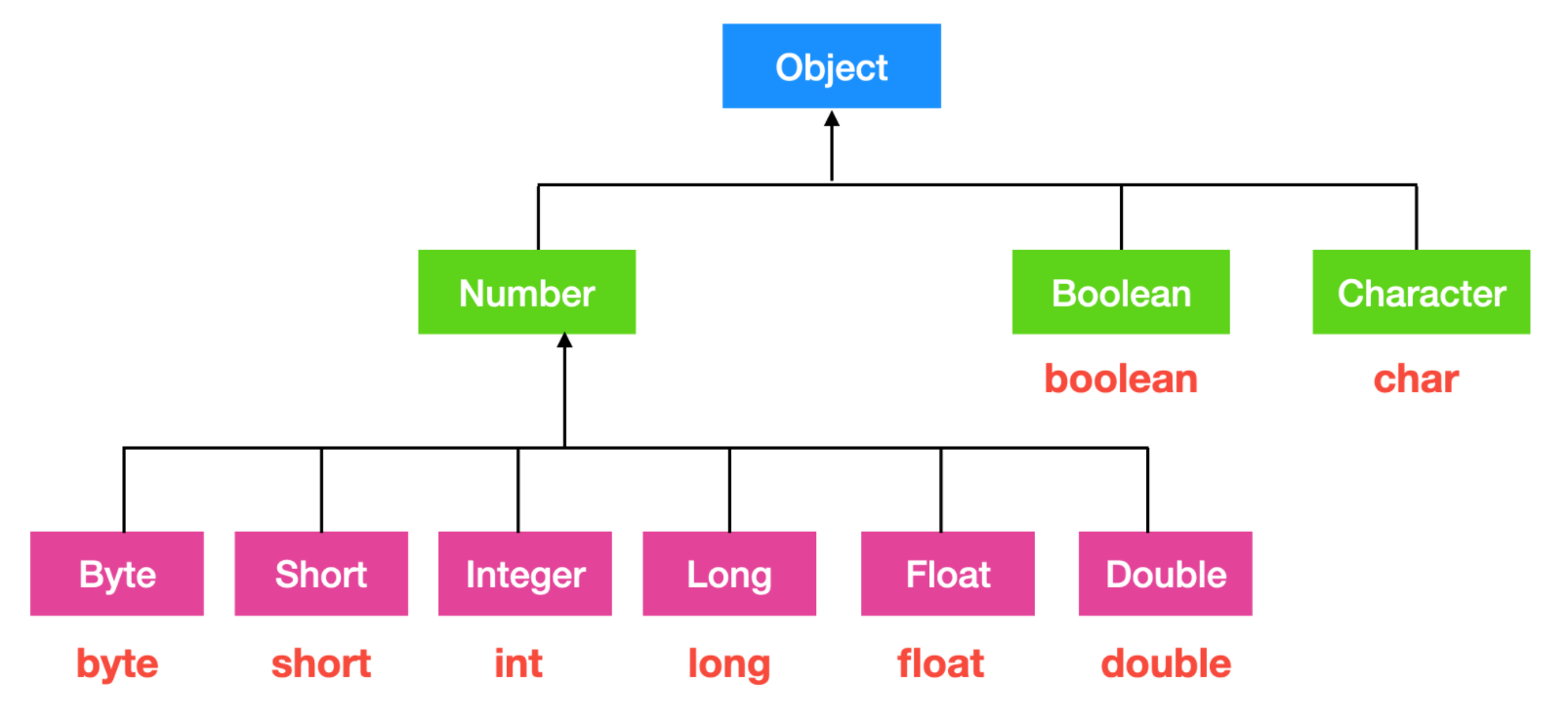
也就是說,上面這些基本資料型別和包裝類在進行轉換的過程中會發生自動裝箱/拆箱,例如下面程式碼
```java
Integer integer = 66; // 自動拆箱
int i1 = integer; // 自動裝箱
```
上面程式碼中的 integer 物件會使用基本資料型別來進行賦值,而基本資料型別 i1 卻把它賦值給了一個物件型別,一般情況下是不能這樣操作的,但是編譯器卻允許我們這麼做,這其實就是一種語法糖。這種語法糖使我們方便我們進行數值運算,如果沒有語法糖,在進行數值運算時,你需要先將物件轉換成基本資料型別,基本資料型別同時也需要轉換成包裝型別才能使用其內建的方法,無疑增加了程式碼冗餘。
>那麼自動拆箱和自動裝箱是如何實現的呢?
其實這背後的原理是編譯器做了優化。將基本型別賦值給包裝類其實是呼叫了包裝類的 `valueOf()` 方法建立了一個包裝類再賦值給了基本型別。
```java
int i1 = Integer.valueOf(1);
```
而包裝類賦值給基本型別就是呼叫了包裝類的 xxxValue() 方法拿到基本資料型別後再進行賦值。
```java
Integer i1 = new Integer(1).intValue();
```
我們使用 javap -c 反編譯一下上面的自動裝箱和自動拆箱來驗證一下

可以看到,在 Code 2 處呼叫 `invokestatic` 的時候,相當於是編譯器自動為我們添加了一下 Integer.valueOf 方法從而把基本資料型別轉換為了包裝型別。
在 Code 7 處呼叫了 `invokevirtual` 的時候,相當於是編譯器為我們添加了 Integer.intValue() 方法把 Integer 的值轉換為了基本資料型別。
### 列舉
我們在日常開發中經常會使用到 `enum` 和 `public static final ...` 這類語法。那麼什麼時候用 enum 或者是 public static final 這類常量呢?好像都可以。
但是在 Java 位元組碼結構中,並沒有列舉型別。**列舉只是一個語法糖,在編譯完成後就會被編譯成一個普通的類,也是用 Class 修飾。這個類繼承於 java.lang.Enum,並被 final 關鍵字修飾**。
我們舉個例子來看一下
```java
public enum School {
STUDENT,
TEACHER;
}
```
這是一個 School 的列舉,裡面包括兩個欄位,一個是 STUDENT ,一個是 TEACHER,除此之外並無其他。
下面我們使用 `javap` 反編譯一下這個 School.class 。反編譯完成之後的結果如下

從圖中我們可以看到,列舉其實就是一個繼承於 `java.lang.Enum` 類的 class 。而裡面的屬性 STUDENT 和 TEACHER 本質也就是 `public static final ` 修飾的欄位。這其實也是一種編譯器的優化,畢竟 STUDENT 要比 public static final School STUDENT 的美觀性、簡潔性都要好很多。
除此之外,編譯器還會為我們生成兩個方法,`values()` 方法和 `valueOf` 方法,這兩個方法都是編譯器為我們新增的方法,通過使用 values() 方法可以獲取所有的 Enum 屬性值,而通過 valueOf 方法用於獲取單個的屬性值。
>注意,Enum 的 values() 方法不屬於 JDK API 的一部分,在 Java 原始碼中,沒有 values() 方法的相關注釋。
用法如下
```java
public enum School {
STUDENT("Student"),
TEACHER("Teacher");
private String name;
School(String name){
this.name = name;
}
public String getName() {
return name;
}
public static void main(String[] args) {
System.out.println(School.STUDENT.getName());
School[] values = School.values();
for(School school : values){
System.out.println("name = "+ school.getName());
}
}
}
```
### 內部類
內部類是 Java 一個`小眾` 的特性,我之所以說小眾,並不是說內部類沒有用,而是我們日常開發中其實很少用到,但是翻看 JDK 原始碼,發現很多原始碼中都有內部類的構造。比如常見的 `ArrayList` 原始碼中就有一個 `Itr` 內部類繼承於 `Iterator` 類;再比如 `HashMap` 中就構造了一個 `Node` 繼承於 Map.Entry 來表示 HashMap 的每一個節點。
Java 語言中之所以引入內部類,是因為有些時候一個類只想在一個類中有用,不想讓其在其他地方被使用,也就是對外隱藏內部細節。
內部類其實也是一個語法糖,因為其只是一個編譯時的概念,一旦編譯完成,編譯器就會為內部類生成一個單獨的class 檔案,名為 outer$innter.class。
下面我們就根據一個示例來驗證一下。
```java
public class OuterClass {
private String label;
class InnerClass {
public String linkOuter(){
return label = "inner";
}
}
public static void main(String[] args) {
OuterClass outerClass = new OuterClass();
InnerClass innerClass = outerClass.new InnerClass();
System.out.println(innerClass.linkOuter());
}
}
```
上面這段編譯後就會生成兩個 class 檔案,一個是 `OuterClass.class` ,一個是 `OuterClass$InnerClass.class` ,這就表明,外部類可以連結到內部類,內部類可以修改外部類的屬性等。
我們來看一下內部類編譯後的結果

如上圖所示,內部類經過編譯後的 linkOuter() 方法會生成一個指向外部類的 this 引用,這個引用就是連線外部類和內部類的引用。
### 變長引數
變長引數也是一個比較小眾的用法,所謂變長引數,就是方法可以接受長度不定確定的引數。一般我們開發不會使用到變長引數,而且變長引數也不推薦使用,它會使我們的程式變的難以處理。但是我們有必要了解一下變長引數的特性。
其基本用法如下
```java
public class VariableArgs {
public static void printMessage(String... args){
for(String str : args){
System.out.println("str = " + str);
}
}
public static void main(String[] args) {
VariableArgs.printMessage("l","am","cxuan");
}
}
```
變長引數也是一種語法糖,那麼它是如何實現的呢?我們可以猜測一下其內部應該是由陣列構成,否則無法接受多個值,那麼我們反編譯看一下是不是由陣列實現的。

可以看到,printMessage() 的引數就是使用了一個數組來接收,所以千萬別被變長引數`忽悠`了!
變長引數特性是在 JDK 1.5 中引入的,使用變長引數有兩個條件,一是變長的那一部分引數具有相同的型別,二是變長引數必須位於方法引數列表的最後面。
### 增強 for 迴圈
為什麼有了普通的 for 迴圈後,還要有增強 for 迴圈呢?想一下,普通 for 迴圈你不是需要知道遍歷次數?每次還需要知道陣列的索引是多少,這種寫法明顯有些繁瑣。增強 for 迴圈與普通 for 迴圈相比,功能更強並且程式碼更加簡潔,你無需知道遍歷的次數和陣列的索引即可進行遍歷。
增強 for 迴圈的物件要麼是一個數組,要麼實現了 Iterable 介面。這個語法糖主要用來對陣列或者集合進行遍歷,其在迴圈過程中不能改變集合的大小。
```java
public static void main(String[] args) {
String[] params = new String[]{"hello","world"};
//增強for迴圈物件為陣列
for(String str : params){
System.out.println(str);
}
List lists = Arrays.asList("hello","world");
//增強for迴圈物件實現Iterable介面
for(String str : lists){
System.out.println(str);
}
}
```
經過編譯後的 class 檔案如下
```java
public static void main(String[] args) {
String[] params = new String[]{"hello", "world"};
String[] lists = params;
int var3 = params.length;
//陣列形式的增強for退化為普通for
for(int str = 0; str < var3; ++str) {
String str1 = lists[str];
System.out.println(str1);
}
List var6 = Arrays.asList(new String[]{"hello", "world"});
Iterator var7 = var6.iterator();
//實現Iterable介面的增強for使用iterator介面進行遍歷
while(var7.hasNext()) {
String var8 = (String)var7.next();
System.out.println(var8);
}
}
```
如上程式碼所示,如果對陣列進行增強 for 迴圈的話,其內部還是對陣列進行遍歷,只不過語法糖把你忽悠了,讓你以一種更簡潔的方式編寫程式碼。
而對繼承於 Iterator 迭代器進行增強 for 迴圈遍歷的話,相當於是呼叫了 Iterator 的 `hasNext()` 和 `next()` 方法。
### Switch 支援字串和列舉
`switch` 關鍵字原生只能支援`整數`型別。如果 switch 後面是 String 型別的話,編譯器會將其轉換成 String 的`hashCode` 的值,所以其實 switch 語法比較的是 String 的 hashCode 。
如下程式碼所示
```java
public class SwitchCaseTest {
public static void main(String[] args) {
String str = "cxuan";
switch (str){
case "cuan":
System.out.println("cuan");
break;
case "xuan":
System.out.println("xuan");
break;
case "cxuan":
System.out.println("cxuan");
break;
default:
break;
}
}
}
```
我們反編譯一下,看看我們的猜想是否正確

根據位元組碼可以看到,進行 switch 的實際是 hashcode 進行判斷,然後通過使用 equals 方法進行比較,因為字串有可能會產生雜湊衝突的現象。
### 條件編譯
這個又是讓小夥伴們摸不著頭腦了,什麼是條件編譯呢?其實,如果你用過 C 或者 C++ 你就知道可以通過預處理語句來實現條件編譯。
>