
ADF 第二篇:使用UI建立資料工廠
使用者可以通過UI來建立ADF,在UI中建立ADF時,使用者不需要下載單獨的IDE,而僅僅通過 Microsoft Edge 或者 Google Chrome瀏覽器。使用者登入Azure Portal,選擇 “Data factories” 服務,通過 Data factories 服務中建立ADF。

一,建立Data Factory例項
開啟 Data factories之後,點選“+ Add”,建立自己的資料工廠例項:
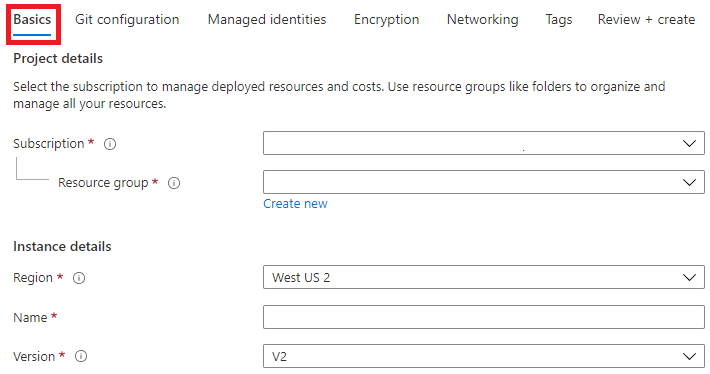
step1,填寫Basics資訊
在 “Create Data Factory” 面板中開始建立資料工廠例項,首先填寫“Basics”資訊:Subscription(訂閱)、資源組(Resource group)、區域(Region)、名稱(Name)和版本(Version),版本選擇V2。
step2:配置git
在V2版本中,使用者在建立資料工廠時,還可以配置“Git configuration”,用於版本控制,可以勾選“Configure Git later”,在建立資料工廠例項之後,擇機配置git。

step3:檢查和建立
檢查(Review+Create)無誤後,點選“Create” 按鈕建立Data factory 例項。等例項建立完成,點選Next Step “Go to resource” 導航到資料工廠頁面。
二,作者和監視器
在Data factory的overview頁面上,點選"Authoer & Monitor"按鈕,這會導航到 Azure Data Factory的使用者介面(UI)頁面中。

ADF的UI介面如下圖所示,介面中顯示了常用的幾個功能:Create Pipeline、Create Data Flow等。

由於我們是第一次建立Data Factory,在建立Pipeline之前,我們還需要建立連線(connection)和資料集(dataset)。
三,建立連線服務
點選UI介面左側的“Manage”選項卡,首先建立連線,連線有兩種型別:Linked services 和 Integration runtimes,本文建立Liked Services,由於Linked Services 依賴於Integration runtimes,因此,我們首先建立Integration runtimes。
1,建立Integration runtimes(IR)
如何建立Integration runtimes,請閱讀:《ADF 第三篇:Integration runtime和 Linked Service》
2,建立Linked Services
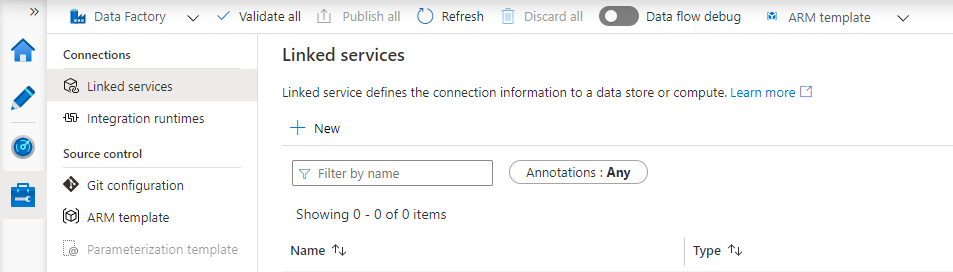
在Connections中選中“Linked Services”,點選“+New”,建立一個新的Linked Services:
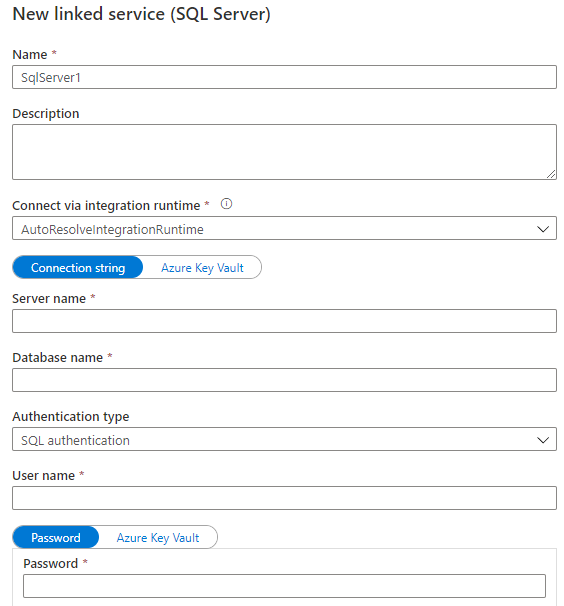
不同的資料來源,有不同的Linked Service,要根據實際的資料來源,選擇合適的資料來源的型別,下圖建立的Linked Service的型別是SQL Server,輸入 Name、Connect via integration runtime、Server name、Database name、Authentication type 、 User name和 Password。
注意,Connect via integration runtime 就是上一節建立的Integration runtimes。
Azure Key Vault是一個儲存空間,使用者把密碼儲存到Azure Key Vault中,輸入Key Vault的名稱和密碼就能提取它儲存的資訊。
四,建立Dataset
dataset 代表資料儲存的結構(schema),它既可以代表資料來源,從資料來源中讀取資料;也可以代表資料目標,把資料儲存到該資料目標中。
建立一個dataset例項,只是儲存了資料儲存的結構等元資料資訊,而不會真正儲存實際的資料。資料真正儲存在dataset指向的底層儲存物件中,舉個例子,dataset執行SQL Server例項中的一個表,那麼資料實際儲存在這個表中,而dataset儲存的資料是表的結構和導航到表的Linked Service。同一個dataset,既可以作為獲取資料的資料來源,也可以作為儲存資料的資料目標。
點選“鉛筆”對應的“Author”選項卡,進入到Fact Resources介面,點選“+”,選擇 Dataset,進入到建立Dataset的介面
設定Dataset的屬性,設定Dataset的Name,通過Linked service來獲取源資料的連線,通過Table name來指定表,建議把Import schema設定為From conneciton/store。

五,建立Pipeline
建立管道,管道相當於一個容器,可以把一個或多個Activity拖放到管道中。
如果向管道中放置Activity?使用者不需要編寫任何程式碼,只需要從“Activities”列表中選擇需要的Activity,拖放到Pipeline中,常用的Activity 通常位於“General”子目錄中。
本文演示Copy data Activity的用法,從“Move & transform”子目錄,選擇Copy data:

Copy Activity的作用是把資料從一個dataset轉移到另一個dataset中。
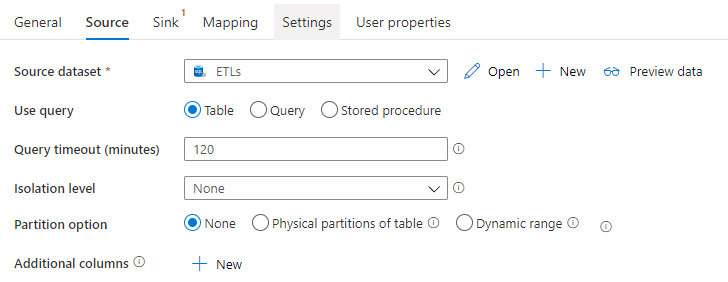
1,設定Copy Activity的Source屬性
Source 屬性表示資料來源,Copy Activity 從Source dataset中獲取資料:
2,Copy Activity的Sink屬性
Sink屬性用於設定資料目標,Sink dataset用於儲存資料:

3,Copy Activity的其他屬性
Mapping屬性選項卡用於設定Source dataset和Sink dataset之間的列對映,並可以設定列型別的轉換。
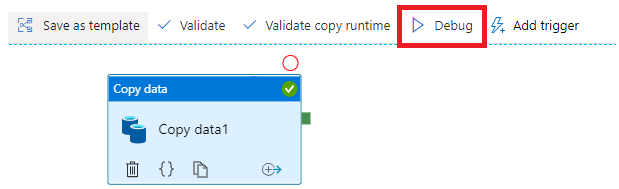
4,除錯Pipeline
點選“Debug”對當前Pipeline進行除錯
到此,一個簡單的ADF就建立完成。
參考文件:
Quickstart: Create a data factory by using the Azure Data Factor