
Redis Sentinel-深入淺出原理和實戰
阿新 • • 發佈:2020-12-09
> 本篇部落格會簡單的介紹Redis的Sentinel相關的原理,同時也會在最後的文章給出**硬核的**實戰教程,讓你在瞭解原理之後,能夠實際上手的體驗整個過程。
之前的文章聊到了Redis的主從複製,聊到了其相關的原理和缺點,具體的建議可以看看我之前寫的文章[Redis的主從複製](https://mp.weixin.qq.com/s/VJTBmAB-A1aRT9DR6v5gow)。
總的來說,為了滿足Redis在真正複雜的生產環境的高可用,僅僅是用主從複製是明顯不夠的。例如,當master節點宕機了之後,進行主從切換的時候,我們需要人工的去做failover。
同時在流量方面,主從架構只能通過增加slave節點來擴充套件讀請求,**寫能力**由於受到master單節點的資源限制是無法進行擴充套件的。
這也是為什麼我們需要引入Sentinel。
## Sentinel
### 功能概覽
Sentinel其大致的功能如下圖。

Sentinel是Redis高可用的解決方案之一,本身也是分散式的架構,包含了**多個**Sentinel節點和**多個**Redis節點。而每個Sentinel節點會對Redis節點和其餘的Sentinel節點進行監控。
當其發現某個節點不可達時,如果是master節點就會與其餘的Sentinel節點協商。當大多數的Sentinel節點都認為master不可達時,就會選出一個Sentinel節點對master執行故障轉移,並通知Redis的呼叫方相關的變更。
相對於**主從**下的手動故障轉移,Sentinel的故障轉移是全自動的,**無需**人工介入。
### Sentinel自身高可用
> 666,那我怎麼知道滿足它自身的高可用需要部署多少個Sentinel節點?
因為Sentinel本身也是分散式的,所以也需要部署多例項來保證自身叢集的高可用,但是這個數量是有個最低的要求,最低需要**3個**。
> 我去,你說3個就3個?我今天偏偏就只部署2個
你別槓...等我說了為什麼就必須要3個...
因為哨兵執行故障轉移需要**大部分**的哨兵都同意才行,如果只有兩個哨兵例項,正常運作還好,就像這樣。
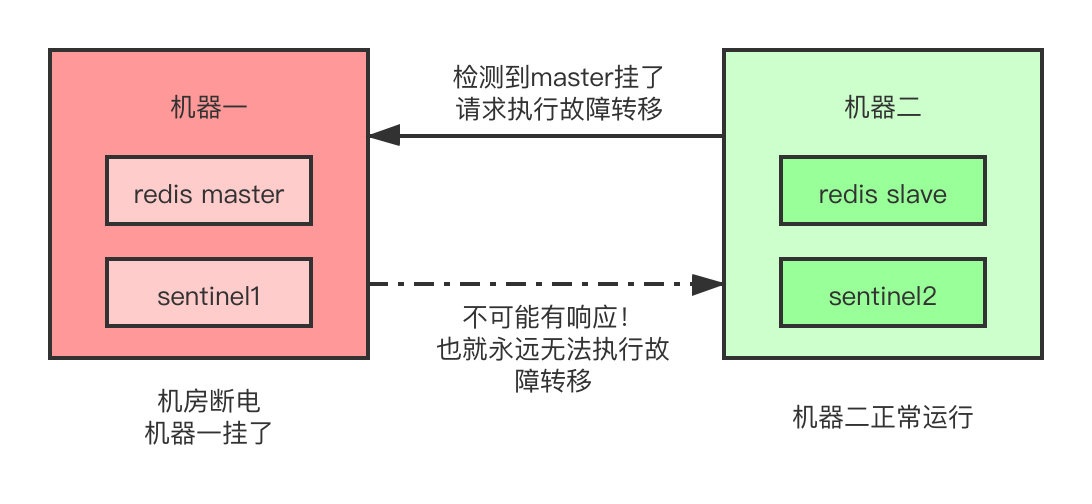 如果哨兵所在的那臺機器由於機房斷電啊,光纖被挖啊等極端情況整個掛掉了,那麼另一臺哨兵即使發現了master故障之後想要執行故障轉移,但是它無法得到任何**其餘哨兵節點**的同意,此時也**永遠**無法執行故障轉移,那Sentinel豈不是成了一個擺設?
所以我們需要至少3個節點,來保證Sentinel叢集自身的高可用。當然,這三個Sentinel節點肯定都推薦部署到**不同的**機器上,如果所有的Sentinel節點都部署到了同一臺機器上,那當這臺機器掛了,整個Sentinel也就不復存在了。
如果哨兵所在的那臺機器由於機房斷電啊,光纖被挖啊等極端情況整個掛掉了,那麼另一臺哨兵即使發現了master故障之後想要執行故障轉移,但是它無法得到任何**其餘哨兵節點**的同意,此時也**永遠**無法執行故障轉移,那Sentinel豈不是成了一個擺設?
所以我們需要至少3個節點,來保證Sentinel叢集自身的高可用。當然,這三個Sentinel節點肯定都推薦部署到**不同的**機器上,如果所有的Sentinel節點都部署到了同一臺機器上,那當這臺機器掛了,整個Sentinel也就不復存在了。
 ### quorum&majority
> 大部分?大哥這可是要上生產環境,大部分這個數量未免也太敷衍了,咱就不能專業一點?
前面提到的`大部分`哨兵同意涉及到兩個引數,一個叫`quorum`,如果Sentinel叢集有`quorum`個哨兵認為master宕機了,就**客觀**的認為master宕機了。另一個叫`majority`...
> 等等等等,不是已經有了一個叫什麼quorum的嗎?為什麼還需要這個majority?
你能不能等我把話說完...
`quorum`剛剛講過了,其作用是判斷master是否處於宕機的狀態,僅僅是一個**判斷**作用。而我們在實際的生產中,不是說只**判斷**master宕機就完了, 我們不還得執行**故障轉移**,讓叢集正常工作嗎?
同理,當哨兵叢集開始進行故障轉移時,如果有`majority`個哨兵同意進行故障轉移,才能夠最終選出一個哨兵節點,執行故障轉移操作。
### 主觀宕機&客觀宕機
> 你剛剛是不是提到了**客觀宕機**?笑死,難不成還有主觀宕機這一說?

Sentinel中認為一個節點掛了有兩種型別:
- Subjective Down,簡稱**sdown**,主觀的認為master宕機
- Objective Down,簡稱**odown**,客觀的認為master宕機
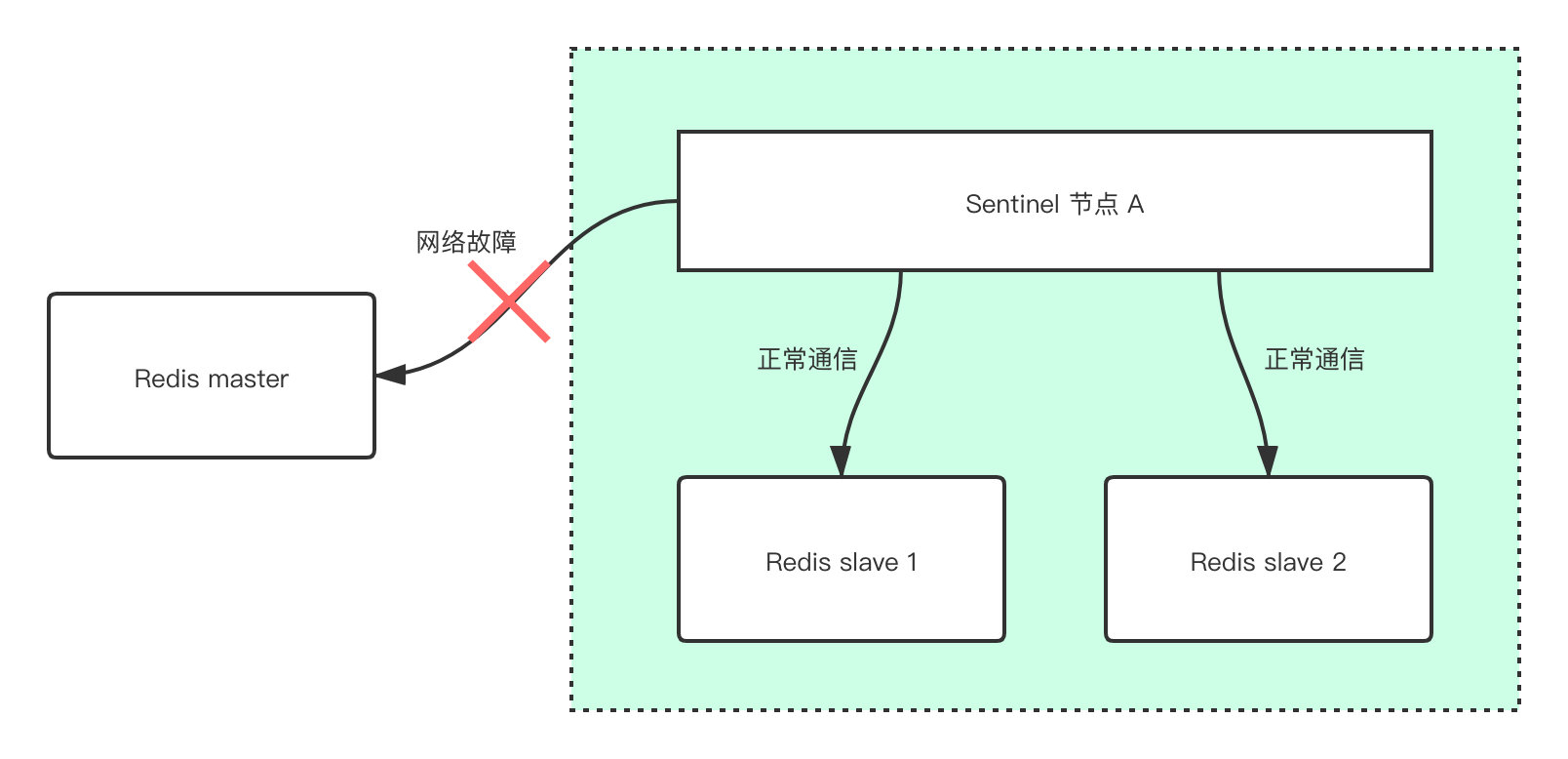
當一個Sentinel節點與其監控的Redis節點A進行通訊時,發現連線不上,此時這個哨兵節點就會**主觀**的認為這個Redis資料A節點sdown了。為什麼是**主觀**?我們得先知道什麼叫主觀
> 未經分析推算,下結論、決策和行為反應,暫時不能與其他不同看法的物件仔細商討,稱為*主觀*。
簡單來說,因為有可能**只是**當前的Sentinel節點和這個A節點的網路通訊有問題,其餘的Sentinel節點仍然可以和A正常的通訊。
### quorum&majority
> 大部分?大哥這可是要上生產環境,大部分這個數量未免也太敷衍了,咱就不能專業一點?
前面提到的`大部分`哨兵同意涉及到兩個引數,一個叫`quorum`,如果Sentinel叢集有`quorum`個哨兵認為master宕機了,就**客觀**的認為master宕機了。另一個叫`majority`...
> 等等等等,不是已經有了一個叫什麼quorum的嗎?為什麼還需要這個majority?
你能不能等我把話說完...
`quorum`剛剛講過了,其作用是判斷master是否處於宕機的狀態,僅僅是一個**判斷**作用。而我們在實際的生產中,不是說只**判斷**master宕機就完了, 我們不還得執行**故障轉移**,讓叢集正常工作嗎?
同理,當哨兵叢集開始進行故障轉移時,如果有`majority`個哨兵同意進行故障轉移,才能夠最終選出一個哨兵節點,執行故障轉移操作。
### 主觀宕機&客觀宕機
> 你剛剛是不是提到了**客觀宕機**?笑死,難不成還有主觀宕機這一說?

Sentinel中認為一個節點掛了有兩種型別:
- Subjective Down,簡稱**sdown**,主觀的認為master宕機
- Objective Down,簡稱**odown**,客觀的認為master宕機
當一個Sentinel節點與其監控的Redis節點A進行通訊時,發現連線不上,此時這個哨兵節點就會**主觀**的認為這個Redis資料A節點sdown了。為什麼是**主觀**?我們得先知道什麼叫主觀
> 未經分析推算,下結論、決策和行為反應,暫時不能與其他不同看法的物件仔細商討,稱為*主觀*。
簡單來說,因為有可能**只是**當前的Sentinel節點和這個A節點的網路通訊有問題,其餘的Sentinel節點仍然可以和A正常的通訊。
 通知呼叫的客戶端master發生了變化
通知其餘的原slave節點,去複製Sentinel選舉出來的新的master節點
如果此時原來的master又重新恢復了,Sentinel也會讓其去複製新的master節點。成為一個新的slave節點。
## 硬核教程
> 硬核教程旨在用最快速的方法,讓你在本地體驗Redis主從架構和Sentinel叢集的搭建,並體驗整個故障轉移的過程。
### 前置要求
1. 安裝了docker
2. 安裝了docker-compose
### 準備compose檔案
首先需要準備一個目錄,然後分別建立兩個子目錄。如下。
```bash
$ tree .
.
├── redis
│ └── docker-compose.yml
└── sentinel
├── docker-compose.yml
├── sentinel1.conf
├── sentinel2.conf
└── sentinel3.conf
2 directories, 5 files
```
### 搭建Redis主從伺服器
redis目錄下的`docker-compose.yml`內容如下。
```yaml
version: '3'
services:
master:
image: redis
container_name: redis-master
ports:
- 6380:6379
slave1:
image: redis
container_name: redis-slave-1
ports:
- 6381:6379
command: redis-server --slaveof redis-master 6379
slave2:
image: redis
container_name: redis-slave-2
ports:
- 6382:6379
command: redis-server --slaveof redis-master 6379
```
> 以上的命令,簡單解釋一下slaveof
>
> 就是讓兩個slave節點去複製container_name為redis-master的節點,這樣就組成了一個簡單的3個節點的主從架構
然後用命令列進入當前目錄,直接敲命令`docker-compose up`即可,剩下的事情交給docker-compose去做就好,它會把我們所需要的節點全部啟動起來。
此時我們還需要拿到剛剛我們啟動的master節點的IP,簡要步驟如下:
1. 通過`docker ps`找到對應的master節點的containerID
```
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9f682c199e9b redis "docker-entrypoint.s…" 3 seconds ago Up 2 seconds 0.0.0.0:6381->6379/tcp redis-slave-1
2572ab587558 redis "docker-entrypoint.s…" 3 seconds ago Up 2 seconds 0.0.0.0:6382->6379/tcp redis-slave-2
f70a9d9809bc redis "docker-entrypoint.s…" 3 seconds ago Up 2 seconds 0.0.0.0:6380->6379/tcp redis-master
```
也就是`f70a9d9809bc`。
2. 通過`docker inspect f70a9d9809bc`,拿到對應容器的IP,在NetworkSettings -> Networks -> IPAddress欄位。
然後把這個值給記錄下來,此處我的值為`172.28.0.3`。
### 搭建Sentinel叢集
sentinel目錄下的`docker-compose.yml`內容如下。
```yaml
version: '3'
services:
sentinel1:
image: redis
container_name: redis-sentinel-1
ports:
- 26379:26379
command: redis-sentinel /usr/local/etc/redis/sentinel.conf
volumes:
- ./sentinel1.conf:/usr/local/etc/redis/sentinel.conf
sentinel2:
image: redis
container_name: redis-sentinel-2
ports:
- 26380:26379
command: redis-sentinel /usr/local/etc/redis/sentinel.conf
volumes:
- ./sentinel2.conf:/usr/local/etc/redis/sentinel.conf
sentinel3:
image: redis
container_name: redis-sentinel-3
ports:
- 26381:26379
command: redis-sentinel /usr/local/etc/redis/sentinel.conf
volumes:
- ./sentinel3.conf:/usr/local/etc/redis/sentinel.conf
networks:
default:
external:
name: redis_default
```
> 同樣在這裡解釋一下命令
>
> redis-sentinel 命令讓 redis 以 sentinel 的模式啟動,本質上就是一個執行在特殊模式的 redis 伺服器。
>
> 和 redis-server 的區別在於,他們分別載入了不同的命令表,sentinel 中無法執行各種redis中特有的 set get操作。
建立三份一模一樣的檔案,分別命名為sentinel1.conf、sentinel2.conf和sentinel3.conf。其內容如下:
```
port 26379
dir "/tmp"
sentinel deny-scripts-reconfig yes
sentinel monitor mymaster 172.28.0.3 6379 2
sentinel config-epoch mymaster 1
sentinel leader-epoch mymaster 1
```
可以看到,我們對於sentinel的配置檔案中,`sentinel monitor mymaster 172.28.0.3 6379 2`表示讓它去監聽名為`mymaster`的master節點,注意此處的IP一定要是你自己master節點的IP,然後最後面的`2`就是我們之前提到的`quorum`。
然後命令列進入名為sentinel的目錄下,敲`docker-compose up`即可。至此,Sentinel叢集便啟動了起來。
### 手動模擬master掛掉
然後我們需要手動模擬master掛掉,來驗證我們搭建的Sentinel叢集是否可以正常的執行故障轉移。
命令列進入名為redis的目錄下,敲入如下命令。
```
docker-compose pause master
```
此時就會將master容器給暫停執行,讓我們等待**10秒**之後,就可以看到sentinel這邊輸出瞭如下的日誌。
```
redis-sentinel-2 | 1:X 07 Dec 2020 01:58:05.459 # +sdown master mymaster 172.28.0.3 6379
......
......
......
redis-sentinel-1 | 1:X 07 Dec 2020 01:58:06.932 # +switch-master mymaster 172.28.0.3 6379 172.28.0.2 6379
```
> 得得得,你幹什麼就甩一堆日誌檔案上來?湊字數?你這樣鬼能看懂?
的確,光從日誌檔案一行一行的看,就算是我自己過兩週再來看,也是一臉懵逼。日誌檔案完整了描述了整個Sentinel叢集從開始執行故障轉移到最終執行完成的所有細節,但是在這裡直接放出來不方便大家的理解。
所以為了讓大家能夠更加直觀的瞭解這個過程,我簡單的把過程抽象了成了一張圖,大家看圖結合日誌,應該能夠更容易理解。

裡面關鍵的步驟步驟的相關解釋我也一併放入了圖片中。
最終的結果就是,master已經從我們最開始的`172.28.0.3`切換到了`172.28.0.2`,後者則是原來的slave節點之一。此時我們也可以連線到`172.28.0.2`這個容器裡去,通過命令來看一下其現在的情況。
```
role:master
connected_slaves:1
slave0:ip=172.28.0.4,port=6379,state=online,offset=18952,lag=0
master_replid:f0bf5d1c843ec3ab005c5ac2b864f7ffdc6a8217
master_replid2:72c43e1f9c05d4b08bea6bf9b2549997587e261c
master_repl_offset:18952
second_repl_offset:16351
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:18952
```
可以看到,現在的`172.28.0.2`這個節點的角色已經變成了**master**,與其相連線的slave節點只有1個,因為現在的**原master**還沒有啟動起來,總共存活的只有2個例項。
### 原master重啟啟動
接下來我們模擬原master重新啟動,來看一下會發什麼什麼。
還是通過命令列進入到名為redis的本地目錄,通過`docker-compose unpause master`來模擬原master故障恢復之後的上線。同樣我們連線到原master的機器上去。
```
$ docker exec -it f70a9d9809bc1e924a5be0135888067ad3eb16552f9eaf82495e4c956b456cd9 /bin/sh; exit
# redis-cli
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:172.28.0.2
master_port:6379
master_link_status:up
......
```
master斷線重連之後,角色也變成了新的master(也就是`172.28.0.2`這個節點)的一個slave。
然後我們也可以通過再看一下新master節點的replication情況作證。
```
# Replication
role:master
connected_slaves:2
slave0:ip=172.28.0.4,port=6379,state=online,offset=179800,lag=0
slave1:ip=172.28.0.3,port=6379,state=online,offset=179800,lag=1
......
```
原master短線重連之後,其**connected_slaves**變成了2,且**原master**`172.28.0.3`被清晰的標註為了slave1,同樣與我們開篇和圖中所講的原理相符合。
> 好了,以上就是本篇部落格的全部內容
>
> 歡迎微信關注「SH的全棧筆記」,檢視更多相關的文章
> 往期文章
> - [Redis基礎—剖析基礎資料結構及其用法](https://mp.weixin.qq.com/s/Pje0emTqS4S_IbtbVY9S5w)
> - [Redis基礎—瞭解Redis是如何做資料持久化的](https://mp.weixin.qq.com/s/m7WEAC6juUYnA5yyKgR4uA)
> - [跟隨槓精的視角一起來了解Redis的主從複製](https://mp.weixin.qq.com/s/VJTBmAB-A1aRT9DR6v5gow)
> - [WebAssembly完全入門——瞭解wasm的前世今生](https://mp.weixin.qq.com/s/KGubO4ARo8IEBqzJ8t6GzA)
> - [淺談JVM與垃圾回收](https://mp.weixin.qq.com/s/1JVETSgjTrV-JjB
通知呼叫的客戶端master發生了變化
通知其餘的原slave節點,去複製Sentinel選舉出來的新的master節點
如果此時原來的master又重新恢復了,Sentinel也會讓其去複製新的master節點。成為一個新的slave節點。
## 硬核教程
> 硬核教程旨在用最快速的方法,讓你在本地體驗Redis主從架構和Sentinel叢集的搭建,並體驗整個故障轉移的過程。
### 前置要求
1. 安裝了docker
2. 安裝了docker-compose
### 準備compose檔案
首先需要準備一個目錄,然後分別建立兩個子目錄。如下。
```bash
$ tree .
.
├── redis
│ └── docker-compose.yml
└── sentinel
├── docker-compose.yml
├── sentinel1.conf
├── sentinel2.conf
└── sentinel3.conf
2 directories, 5 files
```
### 搭建Redis主從伺服器
redis目錄下的`docker-compose.yml`內容如下。
```yaml
version: '3'
services:
master:
image: redis
container_name: redis-master
ports:
- 6380:6379
slave1:
image: redis
container_name: redis-slave-1
ports:
- 6381:6379
command: redis-server --slaveof redis-master 6379
slave2:
image: redis
container_name: redis-slave-2
ports:
- 6382:6379
command: redis-server --slaveof redis-master 6379
```
> 以上的命令,簡單解釋一下slaveof
>
> 就是讓兩個slave節點去複製container_name為redis-master的節點,這樣就組成了一個簡單的3個節點的主從架構
然後用命令列進入當前目錄,直接敲命令`docker-compose up`即可,剩下的事情交給docker-compose去做就好,它會把我們所需要的節點全部啟動起來。
此時我們還需要拿到剛剛我們啟動的master節點的IP,簡要步驟如下:
1. 通過`docker ps`找到對應的master節點的containerID
```
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9f682c199e9b redis "docker-entrypoint.s…" 3 seconds ago Up 2 seconds 0.0.0.0:6381->6379/tcp redis-slave-1
2572ab587558 redis "docker-entrypoint.s…" 3 seconds ago Up 2 seconds 0.0.0.0:6382->6379/tcp redis-slave-2
f70a9d9809bc redis "docker-entrypoint.s…" 3 seconds ago Up 2 seconds 0.0.0.0:6380->6379/tcp redis-master
```
也就是`f70a9d9809bc`。
2. 通過`docker inspect f70a9d9809bc`,拿到對應容器的IP,在NetworkSettings -> Networks -> IPAddress欄位。
然後把這個值給記錄下來,此處我的值為`172.28.0.3`。
### 搭建Sentinel叢集
sentinel目錄下的`docker-compose.yml`內容如下。
```yaml
version: '3'
services:
sentinel1:
image: redis
container_name: redis-sentinel-1
ports:
- 26379:26379
command: redis-sentinel /usr/local/etc/redis/sentinel.conf
volumes:
- ./sentinel1.conf:/usr/local/etc/redis/sentinel.conf
sentinel2:
image: redis
container_name: redis-sentinel-2
ports:
- 26380:26379
command: redis-sentinel /usr/local/etc/redis/sentinel.conf
volumes:
- ./sentinel2.conf:/usr/local/etc/redis/sentinel.conf
sentinel3:
image: redis
container_name: redis-sentinel-3
ports:
- 26381:26379
command: redis-sentinel /usr/local/etc/redis/sentinel.conf
volumes:
- ./sentinel3.conf:/usr/local/etc/redis/sentinel.conf
networks:
default:
external:
name: redis_default
```
> 同樣在這裡解釋一下命令
>
> redis-sentinel 命令讓 redis 以 sentinel 的模式啟動,本質上就是一個執行在特殊模式的 redis 伺服器。
>
> 和 redis-server 的區別在於,他們分別載入了不同的命令表,sentinel 中無法執行各種redis中特有的 set get操作。
建立三份一模一樣的檔案,分別命名為sentinel1.conf、sentinel2.conf和sentinel3.conf。其內容如下:
```
port 26379
dir "/tmp"
sentinel deny-scripts-reconfig yes
sentinel monitor mymaster 172.28.0.3 6379 2
sentinel config-epoch mymaster 1
sentinel leader-epoch mymaster 1
```
可以看到,我們對於sentinel的配置檔案中,`sentinel monitor mymaster 172.28.0.3 6379 2`表示讓它去監聽名為`mymaster`的master節點,注意此處的IP一定要是你自己master節點的IP,然後最後面的`2`就是我們之前提到的`quorum`。
然後命令列進入名為sentinel的目錄下,敲`docker-compose up`即可。至此,Sentinel叢集便啟動了起來。
### 手動模擬master掛掉
然後我們需要手動模擬master掛掉,來驗證我們搭建的Sentinel叢集是否可以正常的執行故障轉移。
命令列進入名為redis的目錄下,敲入如下命令。
```
docker-compose pause master
```
此時就會將master容器給暫停執行,讓我們等待**10秒**之後,就可以看到sentinel這邊輸出瞭如下的日誌。
```
redis-sentinel-2 | 1:X 07 Dec 2020 01:58:05.459 # +sdown master mymaster 172.28.0.3 6379
......
......
......
redis-sentinel-1 | 1:X 07 Dec 2020 01:58:06.932 # +switch-master mymaster 172.28.0.3 6379 172.28.0.2 6379
```
> 得得得,你幹什麼就甩一堆日誌檔案上來?湊字數?你這樣鬼能看懂?
的確,光從日誌檔案一行一行的看,就算是我自己過兩週再來看,也是一臉懵逼。日誌檔案完整了描述了整個Sentinel叢集從開始執行故障轉移到最終執行完成的所有細節,但是在這裡直接放出來不方便大家的理解。
所以為了讓大家能夠更加直觀的瞭解這個過程,我簡單的把過程抽象了成了一張圖,大家看圖結合日誌,應該能夠更容易理解。

裡面關鍵的步驟步驟的相關解釋我也一併放入了圖片中。
最終的結果就是,master已經從我們最開始的`172.28.0.3`切換到了`172.28.0.2`,後者則是原來的slave節點之一。此時我們也可以連線到`172.28.0.2`這個容器裡去,通過命令來看一下其現在的情況。
```
role:master
connected_slaves:1
slave0:ip=172.28.0.4,port=6379,state=online,offset=18952,lag=0
master_replid:f0bf5d1c843ec3ab005c5ac2b864f7ffdc6a8217
master_replid2:72c43e1f9c05d4b08bea6bf9b2549997587e261c
master_repl_offset:18952
second_repl_offset:16351
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:18952
```
可以看到,現在的`172.28.0.2`這個節點的角色已經變成了**master**,與其相連線的slave節點只有1個,因為現在的**原master**還沒有啟動起來,總共存活的只有2個例項。
### 原master重啟啟動
接下來我們模擬原master重新啟動,來看一下會發什麼什麼。
還是通過命令列進入到名為redis的本地目錄,通過`docker-compose unpause master`來模擬原master故障恢復之後的上線。同樣我們連線到原master的機器上去。
```
$ docker exec -it f70a9d9809bc1e924a5be0135888067ad3eb16552f9eaf82495e4c956b456cd9 /bin/sh; exit
# redis-cli
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:172.28.0.2
master_port:6379
master_link_status:up
......
```
master斷線重連之後,角色也變成了新的master(也就是`172.28.0.2`這個節點)的一個slave。
然後我們也可以通過再看一下新master節點的replication情況作證。
```
# Replication
role:master
connected_slaves:2
slave0:ip=172.28.0.4,port=6379,state=online,offset=179800,lag=0
slave1:ip=172.28.0.3,port=6379,state=online,offset=179800,lag=1
......
```
原master短線重連之後,其**connected_slaves**變成了2,且**原master**`172.28.0.3`被清晰的標註為了slave1,同樣與我們開篇和圖中所講的原理相符合。
> 好了,以上就是本篇部落格的全部內容
>
> 歡迎微信關注「SH的全棧筆記」,檢視更多相關的文章
> 往期文章
> - [Redis基礎—剖析基礎資料結構及其用法](https://mp.weixin.qq.com/s/Pje0emTqS4S_IbtbVY9S5w)
> - [Redis基礎—瞭解Redis是如何做資料持久化的](https://mp.weixin.qq.com/s/m7WEAC6juUYnA5yyKgR4uA)
> - [跟隨槓精的視角一起來了解Redis的主從複製](https://mp.weixin.qq.com/s/VJTBmAB-A1aRT9DR6v5gow)
> - [WebAssembly完全入門——瞭解wasm的前世今生](https://mp.weixin.qq.com/s/KGubO4ARo8IEBqzJ8t6GzA)
> - [淺談JVM與垃圾回收](https://mp.weixin.qq.com/s/1JVETSgjTrV-JjB
如果哨兵所在的那臺機器由於機房斷電啊,光纖被挖啊等極端情況整個掛掉了,那麼另一臺哨兵即使發現了master故障之後想要執行故障轉移,但是它無法得到任何**其餘哨兵節點**的同意,此時也**永遠**無法執行故障轉移,那Sentinel豈不是成了一個擺設?
所以我們需要至少3個節點,來保證Sentinel叢集自身的高可用。當然,這三個Sentinel節點肯定都推薦部署到**不同的**機器上,如果所有的Sentinel節點都部署到了同一臺機器上,那當這臺機器掛了,整個Sentinel也就不復存在了。
### quorum&majority
> 大部分?大哥這可是要上生產環境,大部分這個數量未免也太敷衍了,咱就不能專業一點?
前面提到的`大部分`哨兵同意涉及到兩個引數,一個叫`quorum`,如果Sentinel叢集有`quorum`個哨兵認為master宕機了,就**客觀**的認為master宕機了。另一個叫`majority`...
> 等等等等,不是已經有了一個叫什麼quorum的嗎?為什麼還需要這個majority?
你能不能等我把話說完...
`quorum`剛剛講過了,其作用是判斷master是否處於宕機的狀態,僅僅是一個**判斷**作用。而我們在實際的生產中,不是說只**判斷**master宕機就完了, 我們不還得執行**故障轉移**,讓叢集正常工作嗎?
同理,當哨兵叢集開始進行故障轉移時,如果有`majority`個哨兵同意進行故障轉移,才能夠最終選出一個哨兵節點,執行故障轉移操作。
### 主觀宕機&客觀宕機
> 你剛剛是不是提到了**客觀宕機**?笑死,難不成還有主觀宕機這一說?

Sentinel中認為一個節點掛了有兩種型別:
- Subjective Down,簡稱**sdown**,主觀的認為master宕機
- Objective Down,簡稱**odown**,客觀的認為master宕機
當一個Sentinel節點與其監控的Redis節點A進行通訊時,發現連線不上,此時這個哨兵節點就會**主觀**的認為這個Redis資料A節點sdown了。為什麼是**主觀**?我們得先知道什麼叫主觀
> 未經分析推算,下結論、決策和行為反應,暫時不能與其他不同看法的物件仔細商討,稱為*主觀*。
簡單來說,因為有可能**只是**當前的Sentinel節點和這個A節點的網路通訊有問題,其餘的Sentinel節點仍然可以和A正常的通訊。
通知呼叫的客戶端master發生了變化
通知其餘的原slave節點,去複製Sentinel選舉出來的新的master節點
如果此時原來的master又重新恢復了,Sentinel也會讓其去複製新的master節點。成為一個新的slave節點。
## 硬核教程
> 硬核教程旨在用最快速的方法,讓你在本地體驗Redis主從架構和Sentinel叢集的搭建,並體驗整個故障轉移的過程。
### 前置要求
1. 安裝了docker
2. 安裝了docker-compose
### 準備compose檔案
首先需要準備一個目錄,然後分別建立兩個子目錄。如下。
```bash
$ tree .
.
├── redis
│ └── docker-compose.yml
└── sentinel
├── docker-compose.yml
├── sentinel1.conf
├── sentinel2.conf
└── sentinel3.conf
2 directories, 5 files
```
### 搭建Redis主從伺服器
redis目錄下的`docker-compose.yml`內容如下。
```yaml
version: '3'
services:
master:
image: redis
container_name: redis-master
ports:
- 6380:6379
slave1:
image: redis
container_name: redis-slave-1
ports:
- 6381:6379
command: redis-server --slaveof redis-master 6379
slave2:
image: redis
container_name: redis-slave-2
ports:
- 6382:6379
command: redis-server --slaveof redis-master 6379
```
> 以上的命令,簡單解釋一下slaveof
>
> 就是讓兩個slave節點去複製container_name為redis-master的節點,這樣就組成了一個簡單的3個節點的主從架構
然後用命令列進入當前目錄,直接敲命令`docker-compose up`即可,剩下的事情交給docker-compose去做就好,它會把我們所需要的節點全部啟動起來。
此時我們還需要拿到剛剛我們啟動的master節點的IP,簡要步驟如下:
1. 通過`docker ps`找到對應的master節點的containerID
```
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9f682c199e9b redis "docker-entrypoint.s…" 3 seconds ago Up 2 seconds 0.0.0.0:6381->6379/tcp redis-slave-1
2572ab587558 redis "docker-entrypoint.s…" 3 seconds ago Up 2 seconds 0.0.0.0:6382->6379/tcp redis-slave-2
f70a9d9809bc redis "docker-entrypoint.s…" 3 seconds ago Up 2 seconds 0.0.0.0:6380->6379/tcp redis-master
```
也就是`f70a9d9809bc`。
2. 通過`docker inspect f70a9d9809bc`,拿到對應容器的IP,在NetworkSettings -> Networks -> IPAddress欄位。
然後把這個值給記錄下來,此處我的值為`172.28.0.3`。
### 搭建Sentinel叢集
sentinel目錄下的`docker-compose.yml`內容如下。
```yaml
version: '3'
services:
sentinel1:
image: redis
container_name: redis-sentinel-1
ports:
- 26379:26379
command: redis-sentinel /usr/local/etc/redis/sentinel.conf
volumes:
- ./sentinel1.conf:/usr/local/etc/redis/sentinel.conf
sentinel2:
image: redis
container_name: redis-sentinel-2
ports:
- 26380:26379
command: redis-sentinel /usr/local/etc/redis/sentinel.conf
volumes:
- ./sentinel2.conf:/usr/local/etc/redis/sentinel.conf
sentinel3:
image: redis
container_name: redis-sentinel-3
ports:
- 26381:26379
command: redis-sentinel /usr/local/etc/redis/sentinel.conf
volumes:
- ./sentinel3.conf:/usr/local/etc/redis/sentinel.conf
networks:
default:
external:
name: redis_default
```
> 同樣在這裡解釋一下命令
>
> redis-sentinel 命令讓 redis 以 sentinel 的模式啟動,本質上就是一個執行在特殊模式的 redis 伺服器。
>
> 和 redis-server 的區別在於,他們分別載入了不同的命令表,sentinel 中無法執行各種redis中特有的 set get操作。
建立三份一模一樣的檔案,分別命名為sentinel1.conf、sentinel2.conf和sentinel3.conf。其內容如下:
```
port 26379
dir "/tmp"
sentinel deny-scripts-reconfig yes
sentinel monitor mymaster 172.28.0.3 6379 2
sentinel config-epoch mymaster 1
sentinel leader-epoch mymaster 1
```
可以看到,我們對於sentinel的配置檔案中,`sentinel monitor mymaster 172.28.0.3 6379 2`表示讓它去監聽名為`mymaster`的master節點,注意此處的IP一定要是你自己master節點的IP,然後最後面的`2`就是我們之前提到的`quorum`。
然後命令列進入名為sentinel的目錄下,敲`docker-compose up`即可。至此,Sentinel叢集便啟動了起來。
### 手動模擬master掛掉
然後我們需要手動模擬master掛掉,來驗證我們搭建的Sentinel叢集是否可以正常的執行故障轉移。
命令列進入名為redis的目錄下,敲入如下命令。
```
docker-compose pause master
```
此時就會將master容器給暫停執行,讓我們等待**10秒**之後,就可以看到sentinel這邊輸出瞭如下的日誌。
```
redis-sentinel-2 | 1:X 07 Dec 2020 01:58:05.459 # +sdown master mymaster 172.28.0.3 6379
......
......
......
redis-sentinel-1 | 1:X 07 Dec 2020 01:58:06.932 # +switch-master mymaster 172.28.0.3 6379 172.28.0.2 6379
```
> 得得得,你幹什麼就甩一堆日誌檔案上來?湊字數?你這樣鬼能看懂?
的確,光從日誌檔案一行一行的看,就算是我自己過兩週再來看,也是一臉懵逼。日誌檔案完整了描述了整個Sentinel叢集從開始執行故障轉移到最終執行完成的所有細節,但是在這裡直接放出來不方便大家的理解。
所以為了讓大家能夠更加直觀的瞭解這個過程,我簡單的把過程抽象了成了一張圖,大家看圖結合日誌,應該能夠更容易理解。

裡面關鍵的步驟步驟的相關解釋我也一併放入了圖片中。
最終的結果就是,master已經從我們最開始的`172.28.0.3`切換到了`172.28.0.2`,後者則是原來的slave節點之一。此時我們也可以連線到`172.28.0.2`這個容器裡去,通過命令來看一下其現在的情況。
```
role:master
connected_slaves:1
slave0:ip=172.28.0.4,port=6379,state=online,offset=18952,lag=0
master_replid:f0bf5d1c843ec3ab005c5ac2b864f7ffdc6a8217
master_replid2:72c43e1f9c05d4b08bea6bf9b2549997587e261c
master_repl_offset:18952
second_repl_offset:16351
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:18952
```
可以看到,現在的`172.28.0.2`這個節點的角色已經變成了**master**,與其相連線的slave節點只有1個,因為現在的**原master**還沒有啟動起來,總共存活的只有2個例項。
### 原master重啟啟動
接下來我們模擬原master重新啟動,來看一下會發什麼什麼。
還是通過命令列進入到名為redis的本地目錄,通過`docker-compose unpause master`來模擬原master故障恢復之後的上線。同樣我們連線到原master的機器上去。
```
$ docker exec -it f70a9d9809bc1e924a5be0135888067ad3eb16552f9eaf82495e4c956b456cd9 /bin/sh; exit
# redis-cli
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:172.28.0.2
master_port:6379
master_link_status:up
......
```
master斷線重連之後,角色也變成了新的master(也就是`172.28.0.2`這個節點)的一個slave。
然後我們也可以通過再看一下新master節點的replication情況作證。
```
# Replication
role:master
connected_slaves:2
slave0:ip=172.28.0.4,port=6379,state=online,offset=179800,lag=0
slave1:ip=172.28.0.3,port=6379,state=online,offset=179800,lag=1
......
```
原master短線重連之後,其**connected_slaves**變成了2,且**原master**`172.28.0.3`被清晰的標註為了slave1,同樣與我們開篇和圖中所講的原理相符合。
> 好了,以上就是本篇部落格的全部內容
>
> 歡迎微信關注「SH的全棧筆記」,檢視更多相關的文章
> 往期文章
> - [Redis基礎—剖析基礎資料結構及其用法](https://mp.weixin.qq.com/s/Pje0emTqS4S_IbtbVY9S5w)
> - [Redis基礎—瞭解Redis是如何做資料持久化的](https://mp.weixin.qq.com/s/m7WEAC6juUYnA5yyKgR4uA)
> - [跟隨槓精的視角一起來了解Redis的主從複製](https://mp.weixin.qq.com/s/VJTBmAB-A1aRT9DR6v5gow)
> - [WebAssembly完全入門——瞭解wasm的前世今生](https://mp.weixin.qq.com/s/KGubO4ARo8IEBqzJ8t6GzA)
> - [淺談JVM與垃圾回收](https://mp.weixin.qq.com/s/1JVETSgjTrV-JjB