
中介軟體面試專題:kafka高頻面試問題


開篇介紹
大家好,近期會整理一些Java高頻面試題分享給小夥伴,也希望看到的小夥伴在找工作過程中能夠用得到!本章節主要針對Java一些訊息中介軟體高頻面試題進行分享。
Q1:
什麼是訊息和批次?
訊息,Kafka裡的資料單元,也就是我們一般訊息中介軟體裡的訊息的概念。訊息由位元組陣列組成。訊息還可以包含鍵,用以對訊息選取分割槽。
為了提高效率,訊息被分批寫入Kafka。
批次,就是一組訊息,這些訊息屬於同一個主題和分割槽。如果只傳遞單個訊息,會導致大量的網路開銷,把訊息分成批次傳輸可以減少這開銷。但是,這個需要權衡,批次裡包含的訊息越多,單位時間內處理的訊息就越多,單個訊息的傳輸時間就越長。如果進行壓縮,可以提升資料的傳輸和儲存能力,但需要更多的計算處理。
Q2:
什麼是主題和分割槽?
Kafka的訊息用主題進行分類,主題下可以被分為若干個分割槽。分割槽本質上是個提交日誌,有新訊息,這個訊息就會以追加的方式寫入分割槽,然後用先入先出的順序讀取。
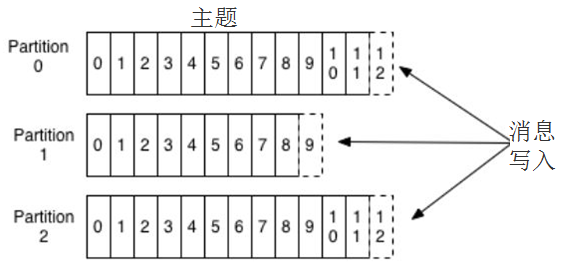
但是因為主題會有多個分割槽,所以在整個主題的範圍內,是無法保證訊息的順序的,單個分割槽則可以保證。
Kafka通過分割槽來實現資料冗餘和伸縮性,因為分割槽可以分佈在不同的伺服器上,那就是說一個主題可以跨越多個伺服器。
前面我們說Kafka可以看成一個流平臺,很多時候,我們會把一個主題的資料看成一個流,不管有多少個分割槽。
Q3:
Kafka中的ISR、AR代表什麼?ISR的伸縮指的什麼?
-
ISR :In-Sync Replicas 副本同步佇列
-
AR :Assigned Replicas 所有副本
ISR是由leader維護,follower從leader同步資料有一些延遲(包括 延遲時間replica.lag.time.max.ms 和 延遲條數replica.lag.max.message 兩個維度,當前最新的版本0.10.x中只支援 replica.lag.time.max.ms 這個維度),任意一個超過閾值都會把follower剔除出ISR,存入OSR(Outof-Sync Replicas)列表,新加入的follower也會先存放在OSR中。
注:AR = ISR + OSR
Q4:
Broker 和 叢集
一個獨立的Kafka伺服器叫Broker。broker的主要工作是,接收生產者的訊息,設定偏移量,提交訊息到磁碟儲存;為消費者提供服務,響應請求,返回訊息。在合適的硬體上,單個broker可以處理上千個分割槽和每秒百萬級的訊息量。
多個broker可以組成一個叢集。每個叢集中broker會選舉出一個叢集控制器。控制器會進行管理,包括將分割槽分配給broker和監控broker。
叢集裡,一個分割槽從屬於一個broker,這個broker被稱為首領。但是分割槽可以被分配給多個broker,這個時候會發生分割槽複製。
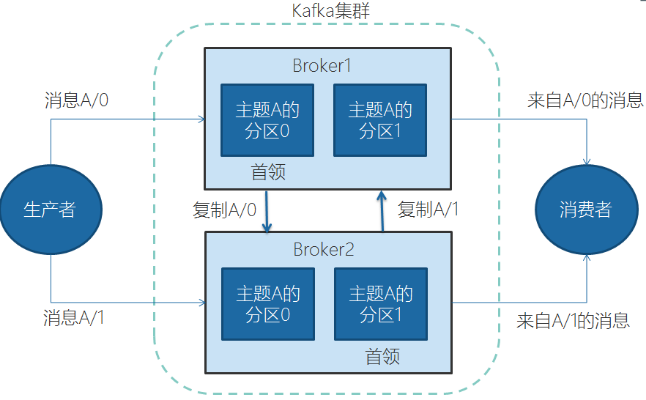
分割槽複製帶來的好處是,提供了訊息冗餘。一旦首領broker失效,其他broker可以接管領導權。當然相關的消費者和生產者都要重新連線到新的首領上。
Q5:
kafka中的zookeeper起到什麼作用?
zookeeper是一個分散式的協調元件,早期版本的kafaka用zk做 meta資訊儲存 , consumer的消費狀態 , group的管理 以及 offset 的值。
考慮到zk本身的一些因素以及整個架構較大概率存在單點問題,新版本中逐漸弱化了zookeeper的作用。新的consumer使用了kafka內部的 group coordination 協議,也減少了對zookeeper的依賴。
Q6:
kafka follower如何與leader資料同步?
kafka的複製機制既不是完全的同步複製,也不是單純的非同步複製。
完全同步複製要求 All Alive Follower 都複製完,這條訊息才會被認為commit,這種複製方式極大的影響了吞吐率。
一步複製方式下,Follower非同步的從Leader複製資料,資料只要被Leader寫入log就被認為已經commit,這種情況下,如果leader掛掉,會丟失資料;
kafka使用 ISR 的方式很好的均衡了確保資料不丟失以及吞吐率。Follower可以批量的從Leader複製資料,而且Leader充分利用磁碟順序讀以及 send file(zero copy) 機制,這樣極大的提高複製效能,內部批量寫磁碟,大幅減少了Follower與Leader的訊息量差。
Q7:
kafka中的訊息是否會丟失和重複消費?
訊息傳送:
kafka訊息傳送有兩種方式:同步(sync)和非同步(async);
預設是同步方式,可通過 producer.type 屬性進行配置;
kafka通過配置 request.required.acks 屬性來確認訊息的生產。
-
0:表示不進行訊息接收是否成功的確認;
-
1:表示當Leader接收成功時確認;
-
-1:表示Leader和Follower都接收成功時確認;
綜上所述,有6種訊息產生的情況,訊息丟失的場景有:
-
acks=0,不和kafka叢集進行訊息接收確認,則當網路異常、緩衝區滿了等情況時,訊息可能丟失;
-
acks=1、同步模式下,只有Leader確認接收成功後但掛掉了,副本沒有同步,資料可能丟失;
訊息消費:
kafka訊息消費有兩個consumer介面, Low-level API 和 High-level API :
-
Low-level API:消費者自己維護offset等值,可以實現對kafka的完全控制;
-
High-level API:封裝了對parition 和 offset 的管理,使用簡單;
如果使用高階介面High-level API,可能存在一個問題就是當訊息消費者從叢集中把訊息取出來,並提交了新的訊息offset值後,還沒來得及消費就掛掉了,那麼下次再消費時之前沒消費成功的訊息就"詭異"的消失了;
解決方案:
1 針對訊息丟失:同步模式下,確認機制設定為-1,即讓訊息寫入Leader 和 Follower之後再確認訊息傳送成功;非同步模式下,為防止緩衝區滿,可以在配置檔案設定不限制阻塞超時時間,當緩衝區滿時讓生產者一直處於阻塞狀態。
2 針對訊息重複:將訊息的唯一標識儲存到外部介質中,每次消費時判斷是否處理過即可。
Q8:
kafka為什麼不支援讀寫分離?
在kafka中,生產者寫入訊息、消費者讀取訊息的操作都是與Leader副本進行互動的,從而實現的是一種主寫主讀的生產消費模型。
kafka並不支援主寫從讀,因為主寫從讀有2個很明顯的缺點:
-
資料一致性問題:資料從主節點轉到從節點必然會有一個延時的時間視窗,這個時間視窗會導致主從節點之間的資料不一致。某一時刻,在主節點和從節點中A資料的值都為X,之後將主節點中A的值修改為Y,那麼在這個變更通知到從節點之前,應用讀取從節點中的A資料的值並不為最新的Y值,由此便產生了資料不一致的問題。
-
延時問題:類似Redis這種元件,資料從寫入主節點到同步至從節點的過程中需要經歷 網路→主節點記憶體→網路→從節點記憶體 這幾個階段,整個過程會耗費一定的時間。而在kafka中,主從同步會比Redis更加耗時,它需要經歷 網路→主節點記憶體→主節點磁碟→網路→從節點記憶體→從節點磁碟 這幾個階段。對延時敏感的應用而言,主寫從讀的功能場景並不太適用。
點關注、不迷路
如果覺得文章不錯,歡迎關注、點贊、收藏,你們的支援是我創作的動力,感謝大家。
如果文章寫的有問題,請不要吝嗇,歡迎留言指出,我會及時核查修改。
如果你還想更加深入的瞭解我,可以私信我。每天8:00準時推送技術文章,讓你的上班路不在孤獨,而且每月還有送書活動,助你提升硬實力!