
我叫你不要重試,你非得重試。這下玩壞了吧?

批評一下
前幾天和一個讀者聊天,聊到了 Dubbo 。
他說他之前遇到了一個 Dubbo 的坑。
我問發生甚麼事兒了?
然後他給我描述了一下前因後果,總結起來就八個字吧:超時之後,自動重試。
對此我就表達了兩個觀點。
讀者對於使用框架的不熟悉,不知道 Dubbo 還有自動重試這回事。 是關於 Dubbo 這個自動重試功能,我覺得出發點很好,但是設計的不好。
第一個沒啥說的,學藝不精,繼續深造。
主要說說第二個。
有一說一,作為一個使用 Dubbo 多年的使用者,根據我的使用經驗我覺得 Dubbo 提供重試功能的想法是很好的,但是它錯就錯在不應該進行自動重試。
大部分情況下,我都會手動設定為 retries=0。
作為一個框架,當然可以要求使用者在充分了解相關特性的情況下再去使用,其中就包含需要了解它的自動重試的功能。
但是,是否需要進行重試,應該是由使用者自行決定的,框架或者工具類,不應該主動幫使用者去做這件事。
等等,這句話說的有點太絕對了。我改一下。

是否需要進行重試,應該是由使用者經過場景分析後自行決定的,框架或者工具類,不應該介入到業務層面,幫使用者去做這件事。
本文就拿出兩個大家比較熟悉的例子,來進行一個簡單的對比。
第一個例子就是 Dubbo 預設的叢集容錯策略 Failover Cluster,即失敗自動切換。
第二個例子就是 apache 的 HttpClient。
一個是框架,一個是工具類,它們都支援重試,且都是預設開啟了重試的。
但是從我的使用感受說來,Dubbo 的自動重試介入到了業務中,對於使用者是有感知的。HttpClient 的自動重試是網路層面的,對於使用者是無感知的。
但是,必須要再次強調的一點是:
Dubbo 在官網上宣告的清清楚楚的,預設自動重試,通常用於讀操作。
如果你使用不當導致資料錯誤,這事你不能怪官方,只能說這個設計有利有弊。

Dubbo重試幾次
都說 Dubbo 會自動重試,那麼是重試幾次呢?
先直接看個例子,演示一下。
首先看看介面定義:
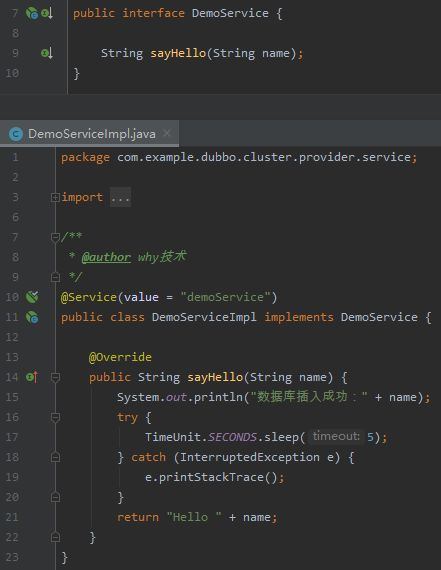
可以看到在介面實現裡面,我睡眠了 5s ,目的是模擬介面超時的情況。
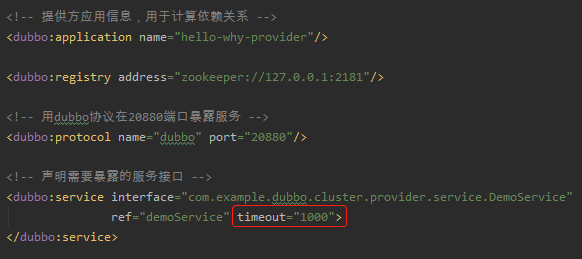
服務端的 xml 檔案裡面是這樣配置的,超時時間設定為了 1000ms:
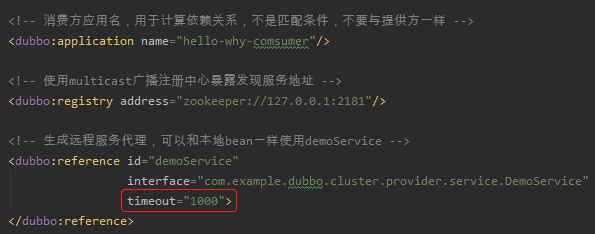
客戶端的 xml 檔案是這樣配置的,超時時間也設定為了 1000ms:
然後我們在單元測試裡面模擬遠端呼叫一次:
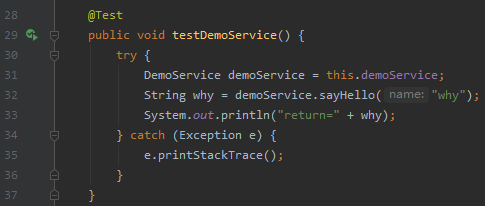
這就是一個原生態的 Dubbo Demo 專案。由於我們超時時間是 1000ms,即 1s,但介面處理需要 5s,所以呼叫必定會超時。
那麼 Dubbo 預設的叢集容錯策略(Failover Cluster),到底會重試幾次,跑一下測試用例,一眼就能看出來:

你看這個測試用例的時間,跑了 3 s 226 ms,你先記住這個時間,我等下再說。
我們先關注重試次數。
有點看不太清楚,我把關鍵日誌單獨拿出來給大家看看:

從日誌可以出,客戶端重試了 3 次。最後一次重試的開始時間是:2020-12-11 22:41:05.094。
我們看看服務端的輸出:
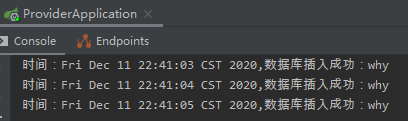
我就呼叫一次,這裡資料庫插入三次。涼涼。

而且你關注一下請求時間,每隔 1s 來一個請求。
我這裡一直強調時間是為什麼呢?
因為這裡有一個知識點:1000ms 的超時時間,是一次呼叫的時間,而不是整個重試請求(三次)的時間。
之前面試的時候,有人問過我這個關於時間的問題。所以我就單獨寫一下。
然後我們把客戶端的 xml 檔案改造一下,指定 retries=0:
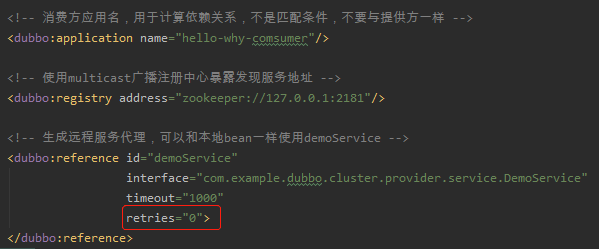
再次呼叫:

可以看到,只進行了一次呼叫。
到這裡,我們還是把 Dubbo 當個黑盒在用。測試出來了它的自動重試次數是 3 次,可以通過 retries 引數進行指定。
接下來,我們扒一扒原始碼。
FailoverCluster原始碼
原始碼位於org.apache.dubbo.rpc.cluster.support.FailoverClusterInvoker中:
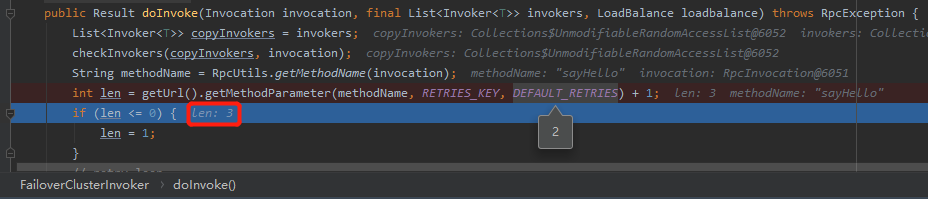
通過原始碼,我們可以知道預設的重試次數是2次:
等等,不對啊,前面剛剛說的是 3 次,怎麼一轉眼就是 2 次了呢?
你別急啊。

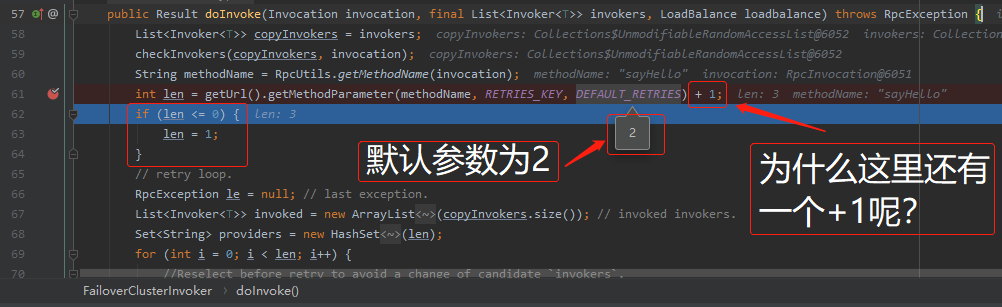
你看第 61 行的最後還有一個 "+1" 呢?
你想一想。我們想要在介面呼叫失敗後,重試 n 次,這個 n 就是 DEFAULT_RETRIES ,預設為 2 。那麼我們總的呼叫次數就是 n+1 次了。
所以這個 "+1" 是這樣來的,很小的一個知識點,送給大家。
另外圖中標記了紅色五角星★的地方,第62到64行。也是很關鍵的地方。對於 retries 引數,在官網上的描述是這樣的:
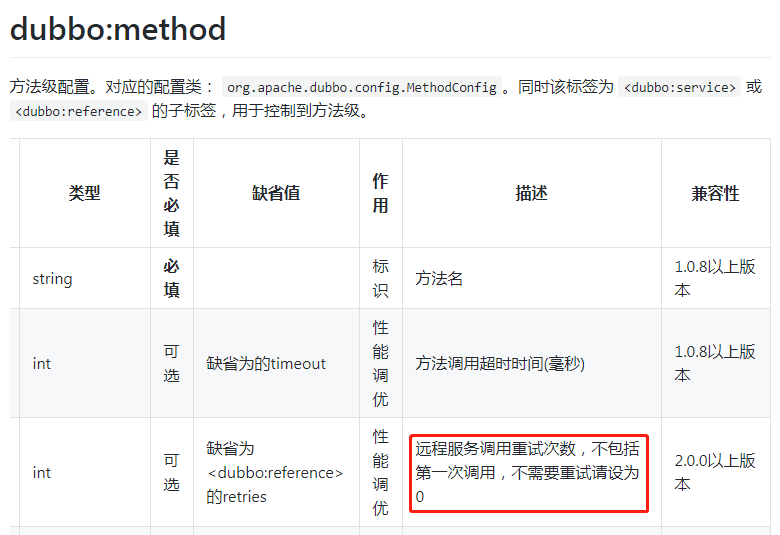
不需要重試,請設為 0 。我們前面分析了,當設定為 0 的時候,只會呼叫一次。
但是我也看見過retries配置為 -1 的。-1+1=0。呼叫0次明顯是一個錯誤的含義。但是程式也正常執行,且只調用一次。
這就是標記了紅色五角星的地方的功勞了。
防禦性程式設計。哪怕你設定為 -10000 也只會呼叫一次。
下面這個圖片是我對 doInvoke 方法進行一個全面的解讀,基本上每一行主要的程式碼都加了註釋,可以點開大圖檢視:
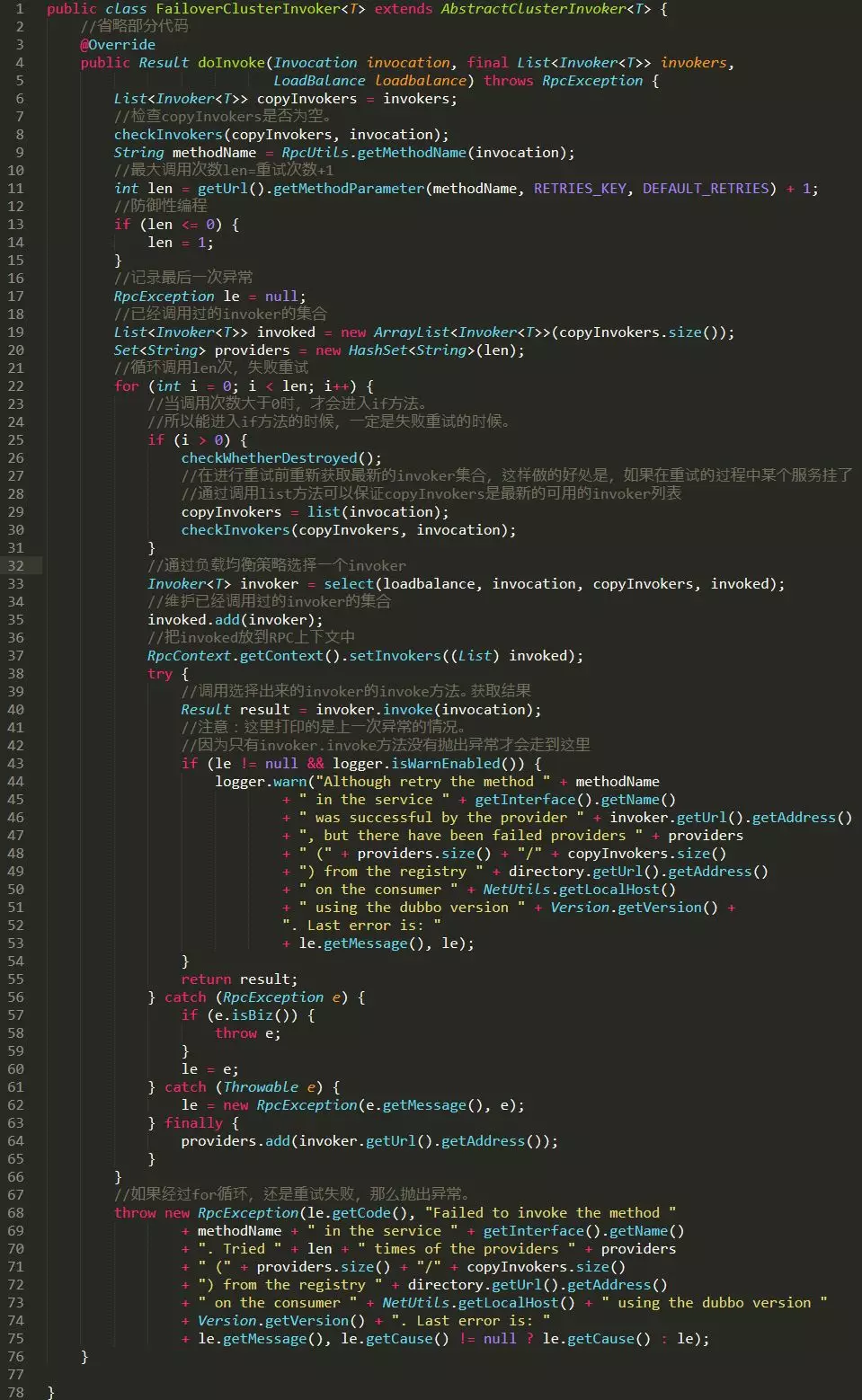
如上所示,FailoverClusterInvoker 的 doInvoke 方法主要的工作流程是:
首先是獲取重試次數,然後根據重試次數進行迴圈呼叫,在迴圈體內,如果失敗,則進行重試。 在迴圈體內,首先是呼叫父類 AbstractClusterInvoker 的 select 方法,通過負載均衡元件選擇一個 Invoker,然後再通過這個 Invoker 的 invoke 方法進行遠端呼叫。 如果失敗了,記錄下異常,並進行重試。
注意一個細節:在進行重試前,重新獲取最新的 invoker 集合,這樣做的好處是,如果在重試的過程中某個服務掛了,可以通過呼叫 list 方法保證 copyInvokers 是最新的可用的 invoker 列表。
整個流程大致如此,不是很難理解。
HttpClient 使用樣例
接下來,我們看看 apache 的 HttpClients 中的重試是怎麼回事。
也就是這個類:org.apache.http.impl.client.HttpClients。
首先,廢話少說,弄個 Demo 跑一下。
先看 Controller 的邏輯:
@RestController
public class TestController {
@PostMapping(value = "/testRetry")
public void testRetry() {
try {
System.out.println("時間:" + new Date() + ",資料庫插入成功");
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
同樣是睡眠 5s,模擬超時的情況。
HttpUtils 封裝如下:
public class HttpPostUtils {
public static String retryPostJson(String uri) throws Exception {
HttpPost post = new HttpPost(uri);
RequestConfig config = RequestConfig.custom()
.setConnectTimeout(1000)
.setConnectionRequestTimeout(1000)
.setSocketTimeout(1000).build();
post.setConfig(config);
String responseContent = null;
CloseableHttpResponse response = null;
CloseableHttpClient client = null;
try {
client = HttpClients.custom().build();
response = client.execute(post, HttpClientContext.create());
if (response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
responseContent = EntityUtils.toString(response.getEntity(), Consts.UTF_8.name());
}
} finally {
if (response != null) {
response.close();
}
if (client != null){
client.close();
}
}
return responseContent;
}
}
先解釋一下其中的三個設定為 1000ms 的引數:
connectTimeout:客戶端和伺服器建立連線的timeout
connectionRequestTimeout:從連線池獲取連線的timeout
socketTimeout:客戶端從伺服器讀取資料的timeout
大家都知道一次http請求,抽象來看,必定會有三個階段
一:建立連線 二:資料傳送 三:斷開連線
當建立連線的操作,在規定的時間內(ConnectionTimeOut )沒有完成,那麼此次連線就宣告失敗,丟擲 ConnectTimeoutException。
後續的 SocketTimeOutException 就一定不會發生。
當連線建立起來後,才會開始進行資料傳輸,如果資料在規定的時間內(SocketTimeOut)沒有傳輸完成,則丟擲 SocketTimeOutException。如果傳輸完成,則斷開連線。
測試 Main 方法程式碼如下:
public class MainTest {
public static void main(String[] args) {
try {
String returnStr = HttpPostUtils.retryPostJson("http://127.0.0.1:8080/testRetry/");
System.out.println("returnStr = " + returnStr);
} catch (Exception e) {
e.printStackTrace();
}
}
}
首先我們不啟動服務,那麼根據剛剛的分析,客戶端和伺服器建立連線會超時,則丟擲 ConnectTimeoutException 異常。
直接執行 main 方法,結果如下:
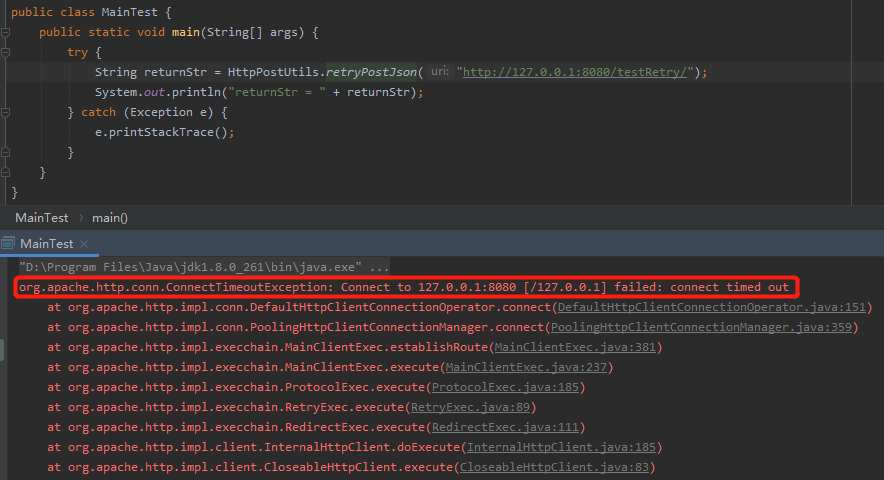
符合我們的預期。
現在我們把 Controller 介面啟動起來。
由於我們的 socketTimeout 設定的時間是 1000ms,而接口裡面進行了 5s 的睡眠。
根據剛剛的分析,客戶端從伺服器讀取資料肯定會超時,則丟擲 SocketTimeOutException 異常。
Controller 介面啟動起來後,我們執行 main 方法輸出如下:
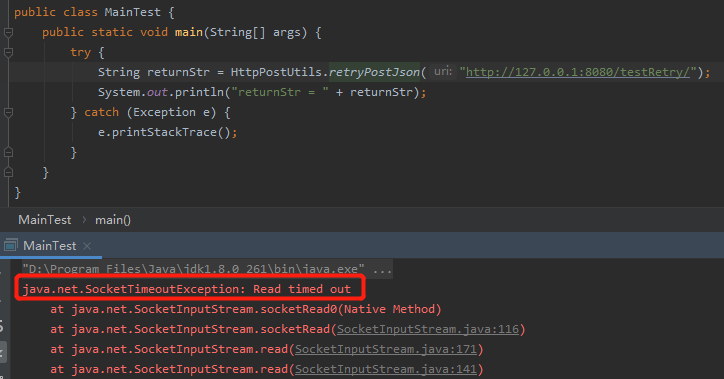
這個時候,其實介面是呼叫成功了,只是客戶端沒有拿到返回。
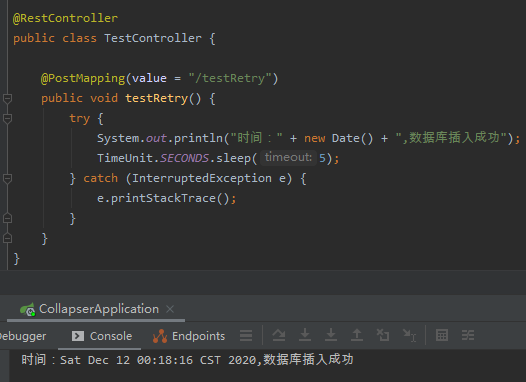
這個情況和我們前面說的 Dubbo 的情況一樣,超時是針對客戶端的。
即使客戶端超時了,服務端的邏輯還是會繼續執行,把此次請求處理完成。
執行結果確實丟擲了 SocketTimeOutException 異常,符合預期。
但是,說好的重試呢?
HttpClient 的重試
在 HttpClients 裡面,其實也是有重試的功能,且和 Dubbo 一樣,預設是開啟的。
但是我們這裡為什麼兩種異常都沒有進行重試呢?
如果它可以重試,那麼預設重試幾次呢?
我們帶著疑問,還是去原始碼中找找答案。
答案就藏在這個原始碼中,org.apache.http.impl.client.DefaultHttpRequestRetryHandler。
DefaultHttpRequestRetryHandler 是 Apache HttpClients 的預設重試策略。
從它的構造方法可以看出,其預設重試 3 次:
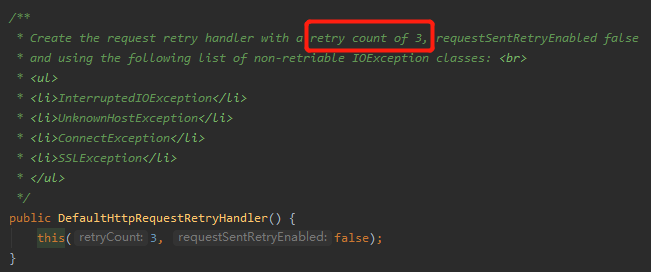
該構造方法的 this 呼叫的是這個方法:
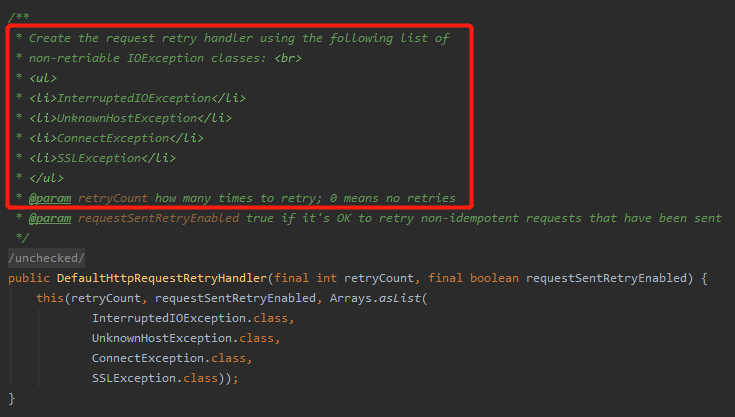
從該構造方法的註釋和程式碼可以看出,對於這四類異常是不會進行重試的:
一:InterruptedIOException 二:UnknownHostException 三:ConnectException 四:SSLException
而我們前面說的 ConnectTimeoutException 和 SocketTimeOutException 都是繼承自 InterruptedIOException 的:
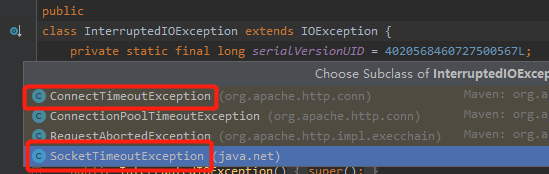
我們關閉 Controller 介面,然後打上斷點看一下:
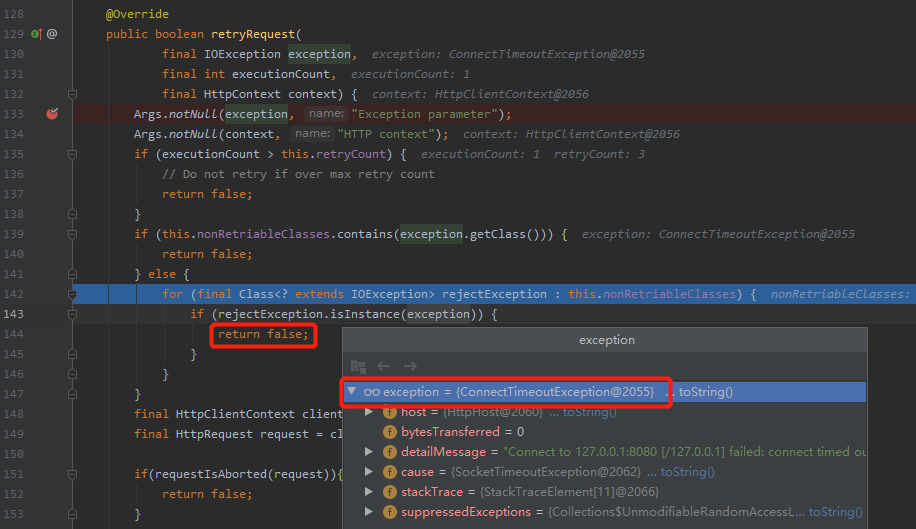
可以看到,經過 if 判斷,會返回 false ,則不會發起重試。
為了模擬重試的情況,我們就得改造一下 HttpPostUtils ,來一個自定義 HttpRequestRetryHandler:
public class HttpPostUtils {
public static String retryPostJson(String uri) throws Exception {
HttpRequestRetryHandler httpRequestRetryHandler = new HttpRequestRetryHandler() {
@Override
public boolean retryRequest(IOException exception, int executionCount, HttpContext context) {
System.out.println("開始第" + executionCount + "次重試!");
if (executionCount > 3) {
System.out.println("重試次數大於3次,不再重試");
return false;
}
if (exception instanceof ConnectTimeoutException) {
System.out.println("連線超時,準備進行重新請求....");
return true;
}
HttpClientContext clientContext = HttpClientContext.adapt(context);
HttpRequest request = clientContext.getRequest();
boolean idempotent = !(request instanceof HttpEntityEnclosingRequest);
if (idempotent) {
return true;
}
return false;
}
};
HttpPost post = new HttpPost(uri);
RequestConfig config = RequestConfig.custom()
.setConnectTimeout(1000)
.setConnectionRequestTimeout(1000)
.setSocketTimeout(1000).build();
post.setConfig(config);
String responseContent = null;
CloseableHttpResponse response = null;
CloseableHttpClient client = null;
try {
client = HttpClients.custom().setRetryHandler(httpRequestRetryHandler).build();
response = client.execute(post, HttpClientContext.create());
if (response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
responseContent = EntityUtils.toString(response.getEntity(), Consts.UTF_8.name());
}
} finally {
if (response != null) {
response.close();
}
if (client != null) {
client.close();
}
}
return responseContent;
}
}
在我們的自定義 HttpRequestRetryHandler 裡面,對於 ConnectTimeoutException ,我進行了放行,讓請求可以重試。
當我們不啟動 Controller 介面時,程式會自動重試 3 次:
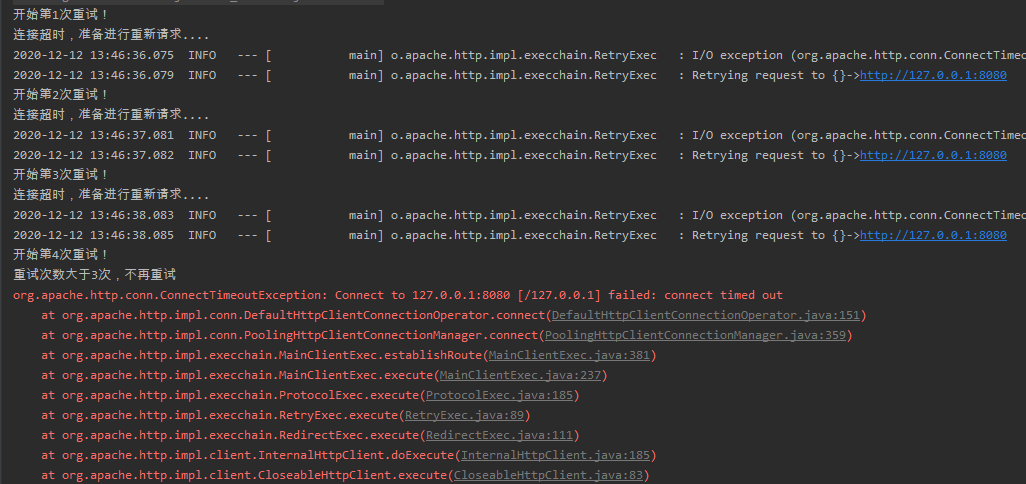
上面給大家演示了 Apache HttpClients 的預設重試策略。上面的程式碼大家可以直接拿出來執行一下。
如果想知道整個呼叫流程,可以在 debug 的模式下看呼叫鏈路:
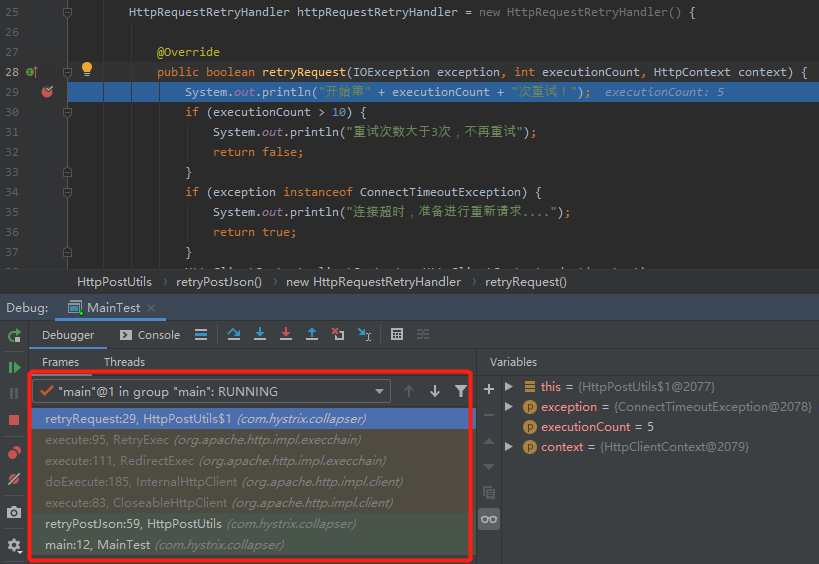
HttpClients 的自動重試,同樣是預設開啟的,但是我們在使用過程中是無感知的。
因為它的重試條件也是比較苛刻的,針對網路層面的重試,沒有侵入到業務中。
謹慎謹慎再謹慎。
對於需要重試的功能,我們在開發過程中一定要謹慎謹慎再謹慎。

比如 Dubbo 的預設重試,我覺得它的出發點是為了保證服務的高可用。
正常來說我們的微服務至少都有兩個節點。當其中一個節點不提供服務的時候,叢集容錯策略就會去自動重試另外一臺。
但是對於服務呼叫超時的情況,Dubbo 也認為是需要重試的,這就相當於侵入到業務裡面了。
前面我們說了服務呼叫超時是針對客戶端的。即使客戶端呼叫超時了,服務端還是在正常執行這次請求。
所以官方文件中才說“通常用於讀操作”:
http://dubbo.apache.org/zh/docs/v2.7/user/examples/fault-tolerent-strategy/

讀操作,含義是預設冪等。所以,當你的介面方法不是冪等時請記得設定 retries=0。
這個東西,我給你舉一個實際的場景。
假設你去呼叫了微信支付介面,但是呼叫超時了。
這個時候你怎麼辦?
直接重試?請你回去等通知吧。
肯定是呼叫查詢介面,判斷當前這個請求對方是否收到了呀,從而進行進一步的操作吧。
對於 HttpClients,它的自動重試沒有侵入到業務之中,而是在網路層面。
所以絕大部分情況下,我們系統對於它的自動重試是無感的。
甚至需要我們在程式裡面去實現自動重試的功能。
由於你的改造是在最底層的 HttpClients 方法,這個時候你要注意的一個點:你要分辨出來,這個請求異常後是否支援重試。
不能直接無腦重試。
對於重試的框架,大家可以去了解一下 Guava-Retry 和 Spring-Retry。
奇聞異事
我知道大家最喜歡的就是這個環節了。

看一下 FailoverClusterInvoker 的提交記錄:
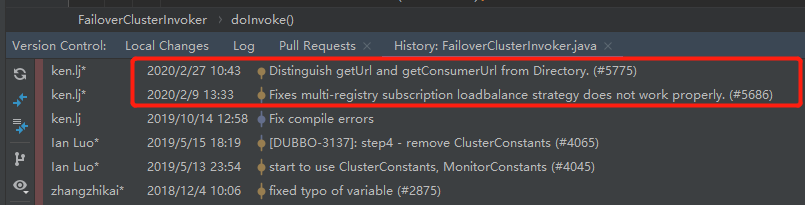
2020 年提交了兩次。時間間隔還挺短的。
2 月 9 日的提交,是針對編號為 5686 的 issue 進行的修復。
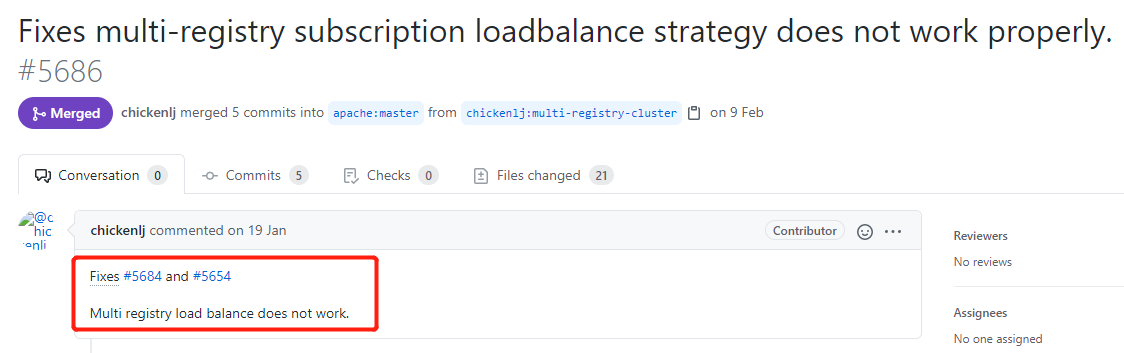
而在這個 issue 裡面,針對編號為 5684 和 5654 進行了修復:
https://github.com/apache/dubbo/issues/5654
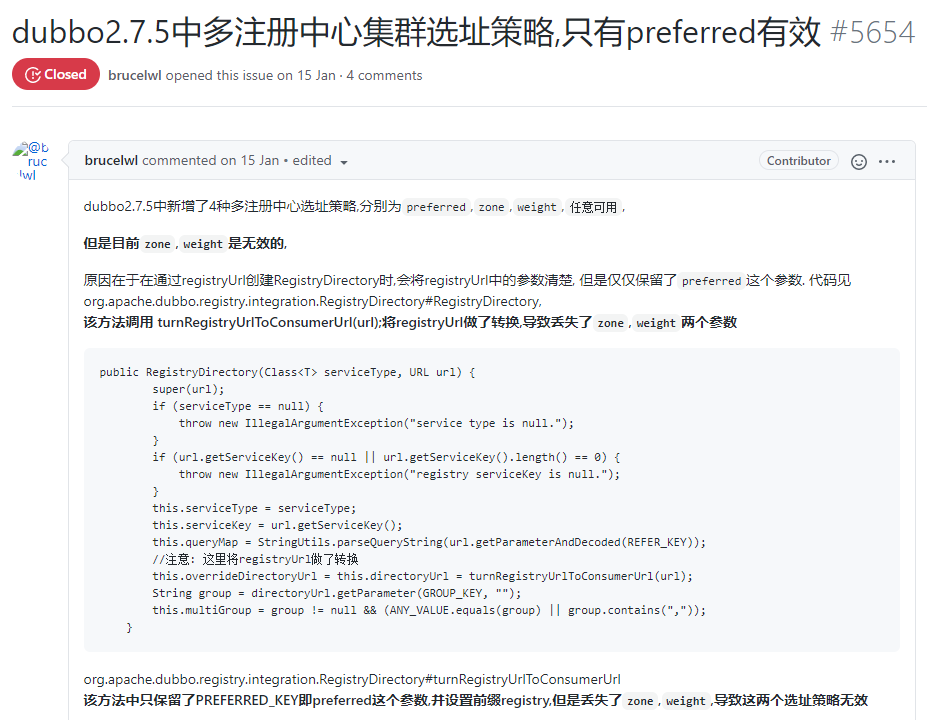
它們都指向了一個問題:
多註冊中心的負載均衡不生效。
官方對這個問題修復了之後,馬上就帶來另外一個大問題:
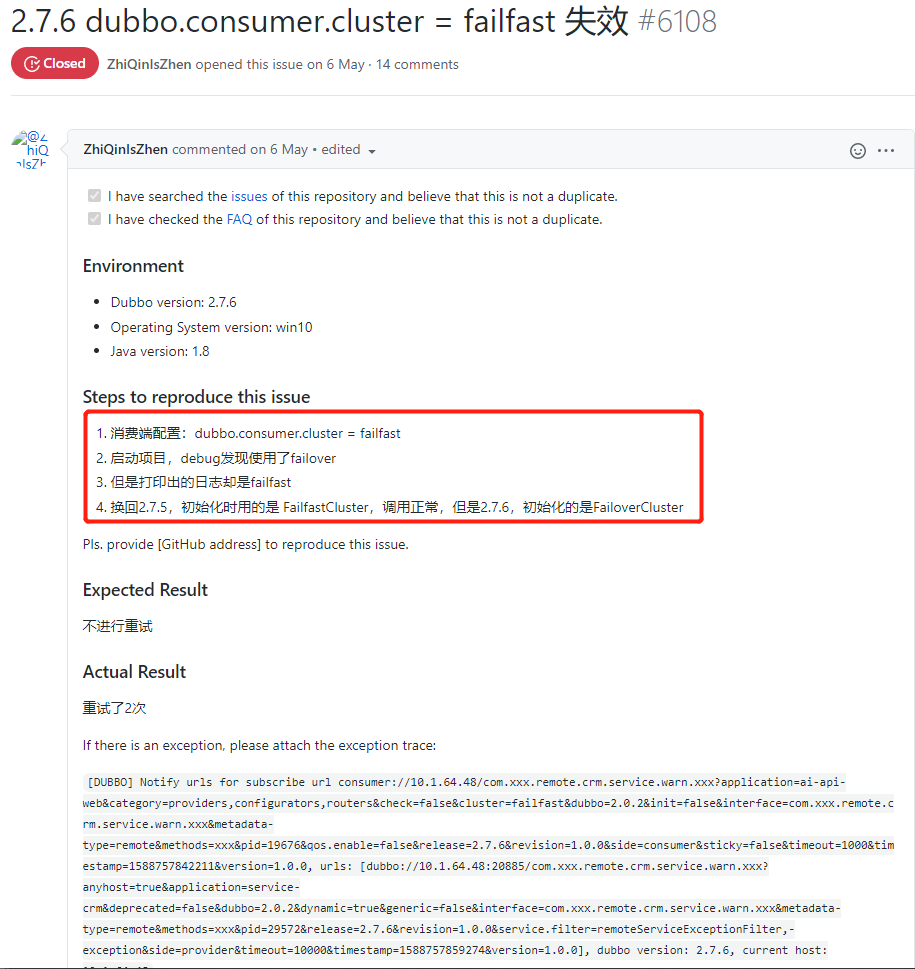
2.7.6 版本里面 failfast 負載均衡策略失效了。
你想,我知道我一個介面不能失敗重試,所以我故意改成了 failfast 策略。
但是實際框架用的還是 failover,進行了重試 2 次?

而實際情況更加糟糕, 2.7.6 版本里面負載均衡策略只支援 failover 了。
這玩意就有點坑了。
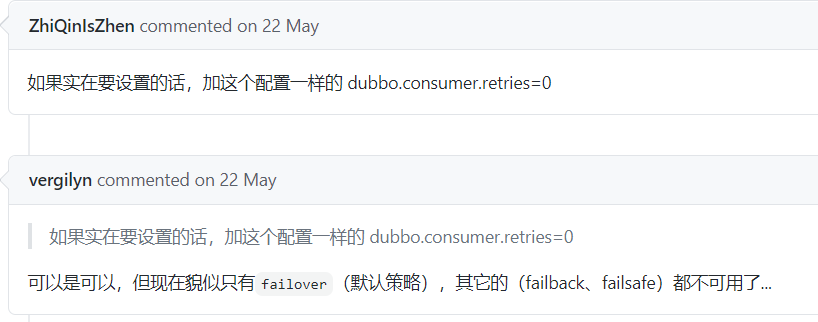
而這個 bug 一直到 2.7.8 版本才修復好。
所以,如果你使用的 Dubbo 版本是 2.7.5 或者 2.7.6 版本。一定要注意一下,是否用了其他的叢集容錯策略。如果用了,實際上是沒有生效的。
可以說,這確實是一個比較大的 bug。
但是開源專案,共同維護。
我們當然知道 Dubbo 不是一個完美的框架,但我們也知道,它的背後有一群知道它不完美,但是仍然不言乏力、不言放棄的工程師。
他們在努力改造它,讓它趨於完美。
我們作為使用者,我們少一點"吐槽",多一點鼓勵,提出實質性的建議。
只有這樣我才能驕傲的說,我們為開源世界貢獻了一點點的力量,我們相信它的明天會更好。
向開源致敬,向開源工程師致敬。
總之,牛逼。
好了,這次的文章就到這裡了。
才疏學淺,難免會有紕漏,如果你發現了錯誤的地方,可以提出來,我對其加以修改。
感謝您的閱讀,我堅持原創,十分歡迎並感謝您的關注。
我是 why,一個被程式碼耽誤的文學創作者,一個又暖又有料的四川好男人。
還有,歡迎關注我呀。
