
微服務過載保護原理與實戰
阿新 • • 發佈:2020-12-16
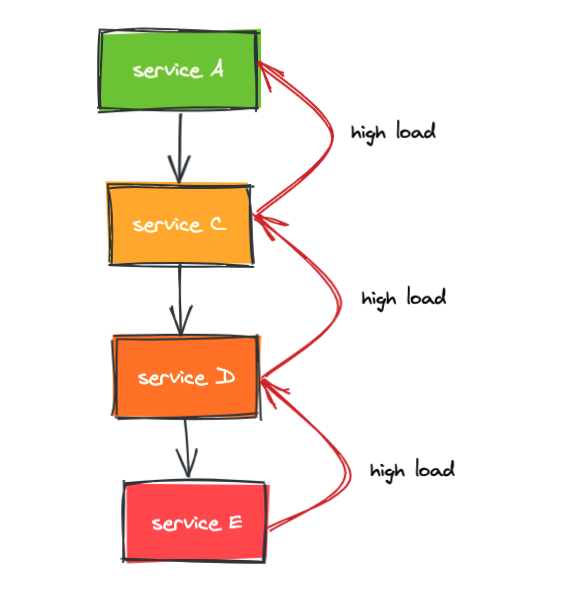
在微服務中由於服務間相互依賴很容易出現連鎖故障,連鎖故障可能是由於整個服務鏈路中的某一個服務出現故障,進而導致系統的其他部分也出現故障。例如某個服務的某個例項由於過載出現故障,導致其他例項負載升高,從而導致這些例項像多米諾骨牌一樣一個個全部出現故障,這種連鎖故障就是所謂的雪崩現象
比如,服務A依賴服務C,服務C依賴服務D,服務D依賴服務E,當服務E過載會導致響應時間變慢甚至服務不可用,這個時候呼叫方D會出現大量超時連線資源被大量佔用得不到釋放,進而資源被耗盡導致服務D也過載,從而導致服務C過載以及整個系統雪崩
 某一種資源的耗盡可以導致高延遲、高錯誤率或者相應資料不符合預期的情況發生,這些的確是在資源耗盡時應該出現的情況,在負載不斷上升直到過載時,伺服器不可能一直保持完全的正常。而CPU資源的不足導致的負載上升是我們工作中最常見的,如果CPU資源不足以應對請求負載,一般來說所有的請求都會變慢,CPU負載過高會造成一系列的副作用,主要包括以下幾項:
- 正在處理的(in-flight) 的請求數量上升
- 伺服器逐漸將請求佇列填滿,意味著延遲上升,同時佇列會用更多的記憶體
- 執行緒卡住,無法處理請求
- cpu死鎖或者請求卡主
- rpc服務呼叫超時
- cpu的快取效率下降
由此可見防止伺服器過載的重要性不言而喻,而防止伺服器過載又分為下面幾種常見的策略:
- 提供降級結果
- 在過載情況下主動拒絕請求
- 呼叫方主動拒絕請求
- 提前進行壓測以及合理的容量規劃
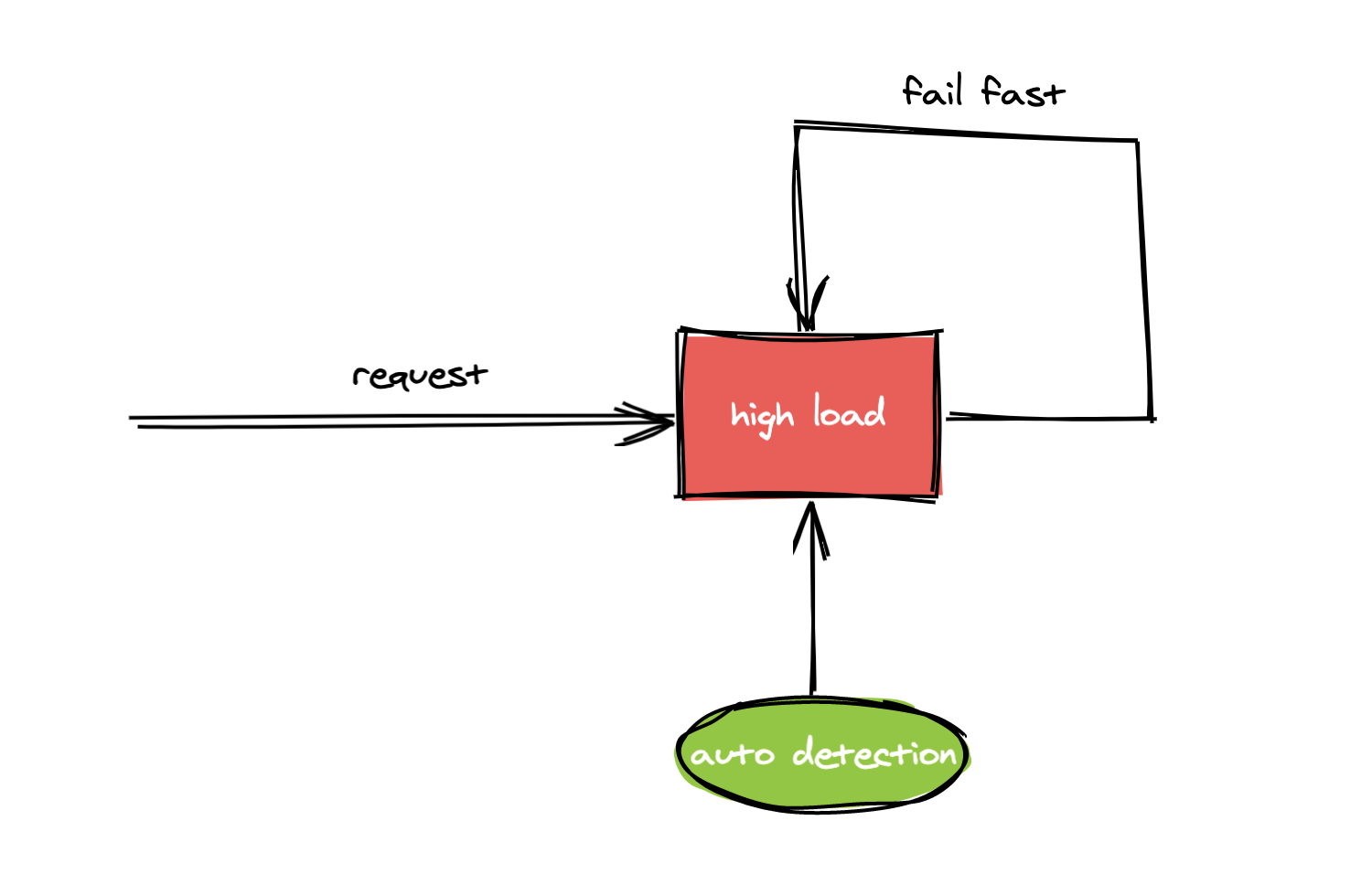
今天我們主要討論的是第二種防止伺服器過載的方案,即在過載的情況下主動拒絕請求,下面我統一使用”過載保護“來表述,過載保護的大致原理是當探測到伺服器已經處於過載時則主動拒絕請求不進行處理,一般做法是快速返回error
某一種資源的耗盡可以導致高延遲、高錯誤率或者相應資料不符合預期的情況發生,這些的確是在資源耗盡時應該出現的情況,在負載不斷上升直到過載時,伺服器不可能一直保持完全的正常。而CPU資源的不足導致的負載上升是我們工作中最常見的,如果CPU資源不足以應對請求負載,一般來說所有的請求都會變慢,CPU負載過高會造成一系列的副作用,主要包括以下幾項:
- 正在處理的(in-flight) 的請求數量上升
- 伺服器逐漸將請求佇列填滿,意味著延遲上升,同時佇列會用更多的記憶體
- 執行緒卡住,無法處理請求
- cpu死鎖或者請求卡主
- rpc服務呼叫超時
- cpu的快取效率下降
由此可見防止伺服器過載的重要性不言而喻,而防止伺服器過載又分為下面幾種常見的策略:
- 提供降級結果
- 在過載情況下主動拒絕請求
- 呼叫方主動拒絕請求
- 提前進行壓測以及合理的容量規劃
今天我們主要討論的是第二種防止伺服器過載的方案,即在過載的情況下主動拒絕請求,下面我統一使用”過載保護“來表述,過載保護的大致原理是當探測到伺服器已經處於過載時則主動拒絕請求不進行處理,一般做法是快速返回error
某一種資源的耗盡可以導致高延遲、高錯誤率或者相應資料不符合預期的情況發生,這些的確是在資源耗盡時應該出現的情況,在負載不斷上升直到過載時,伺服器不可能一直保持完全的正常。而CPU資源的不足導致的負載上升是我們工作中最常見的,如果CPU資源不足以應對請求負載,一般來說所有的請求都會變慢,CPU負載過高會造成一系列的副作用,主要包括以下幾項:
- 正在處理的(in-flight) 的請求數量上升
- 伺服器逐漸將請求佇列填滿,意味著延遲上升,同時佇列會用更多的記憶體
- 執行緒卡住,無法處理請求
- cpu死鎖或者請求卡主
- rpc服務呼叫超時
- cpu的快取效率下降
由此可見防止伺服器過載的重要性不言而喻,而防止伺服器過載又分為下面幾種常見的策略:
- 提供降級結果
- 在過載情況下主動拒絕請求
- 呼叫方主動拒絕請求
- 提前進行壓測以及合理的容量規劃
今天我們主要討論的是第二種防止伺服器過載的方案,即在過載的情況下主動拒絕請求,下面我統一使用”過載保護“來表述,過載保護的大致原理是當探測到伺服器已經處於過載時則主動拒絕請求不進行處理,一般做法是快速返回error