
技術基礎 | 改進版的Apache Cassandra客戶端請求路由
最近我們在客戶端的驅動程式中引入了一些變更,這些變更會影響傳入的請求在Apache Cassandra叢集內的分發方式。
新的預設負載均衡演算法即將隨驅動程式推出,這些演算法將有助於縮短長尾延遲,並提供更好的總體響應時間。
01 Cassandra中資料分割槽和資料複製的方式
Cassandra根據分割槽鍵(partition key)的值將資料分配至節點。每個分割槽鍵對應的分割槽有多個副本,從而確保可靠性和容錯能力。
複製策略決定了要把這些副本放置在哪些節點。整個叢集中的副本總數被稱為“複製因子(replication factor)”。例如,“複製因子為3”就表示在一個給定的資料中心或叢集中,每條資料有三個副本。
對於一個給定的查詢請求,驅動程式會選擇一個副本節點作為本次查詢的協調節點(coordinator),並負責滿足一致性級別(consistency level)的要求。
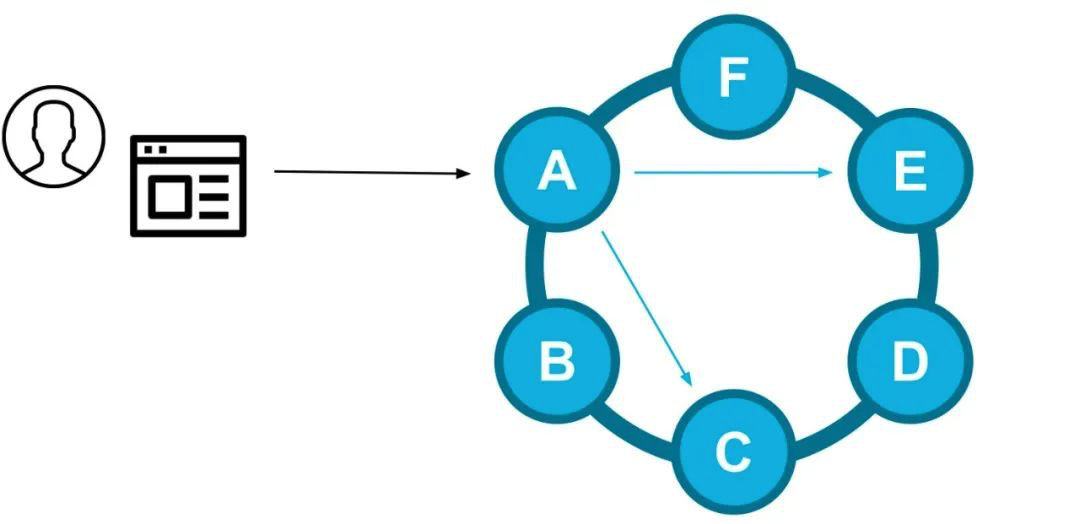
寫入路徑示例:客戶端驅動程式選擇了節點A,該節點A是某個給定的分割槽鍵的副本節點,它會作為本次請求的協調節點將資料傳送到其他副本節點(E和C)
02 客戶端是如何路由的
DataStax Drivers(DataStax的驅動程式)控制傳入的查詢請求將如何在叢集中分發。藉助叢集的元資料,DataStax Drivers可以知道哪些節點是某個給定分割槽鍵的副本節點。然後驅動程式會將查詢請求直接傳送到其中的一個副本節點,以避免額外的網路躍點(network hop)。
當複製因子大於1時,驅動程式會把收到的請求在不同的副本間保持平衡。以往,驅動程式常常以隨機的方式,從副本節點集(replica set)中為某個查詢選擇協調節點。
03 隨機選擇
鑑於微服務應用程式通常包含多個服務例項,我們必須將客戶端的驅動程式視為一種分散式的負載均衡器(n個客戶端將流量路由到m個節點)。隨機選擇是一種很好的分散式負載均衡器的演算法,因為它是無狀態的,不需要客戶端例項互相通訊之後生成統一的負載。
多個客戶端將多個請求分發到同一些節點
隨機選擇讓請求負載被均勻地分配(從數量的角度),但這些負載的分配卻不是公平的——因為隨機選擇沒有考慮請求的大小或複雜性,也沒考慮在伺服器節點的後臺可能正在處理的其他任務。
03 隨機選擇的二次方(The Power of Two Random Choices)
在分散式系統中,根據某個標識訊號就確定性地選擇某一個候選節點,這可能是很危險的——因為具有相同邏輯的多個客戶端,可能會將同一伺服器節點標識為最佳候選節點,並將所有流量導向到該節點。這會導致負載峰值,並有級聯失效(cascading failure)的風險。因此,具有一定程度的隨機性的演算法仍然是我們所需要的。
通過泰勒·麥克穆倫(Tyler McMullen)的演講,我們首此接觸到“隨機選擇的二次方(The Power of Two Random Choice)”這個演算法。在那之後,這個演算法已經被諸多負載均衡軟體(諸如Netflix的Zuul,Nginx和Haproxy之類的)實現,用於眾多的服務網格部署(service mesh deployment)中(比如Twitter)。
這個演算法的邏輯很簡單:相比試著根據某個標識訊號來選出那個絕對最佳的候選節點,“隨機選擇的二次方”這個演算法會讓你隨機選擇兩個候選節點,然後再在這兩者中選擇更好的那個,同時也避免了更糟的選擇。
我們有幾種不同的方法來識別哪個節點是最佳候選節點。過去,我們公開了一種使用時延資訊(LatencyAwarePolicy)作為標識訊號的方法。由於我們在路由資料庫請求時沒有考慮查詢的複雜性,因此聚合的節點時延資訊並不是伺服器例項的當前健康狀態的最佳指標。
例如,某個查詢可能由於需要整理合並大量資料而需要更長的時間,但是該伺服器可能仍有大量的空閒資源來處理其他查詢。另外,請求的響應時間是在收到響應之後才確定的,可是這已經不能反映伺服器的最新狀態了。
客戶端驅動例項會向節點發送請求,我們決定用正在處理中的請求數來選擇最佳候選節點。簡而言之,我們會隨機選擇兩個副本,然後選擇其中等待處理的請求較少的副本節點作為協調節點。
04 監測陳舊佇列
藉助我們對節點的行為模式的瞭解,我們發現了更多的改進空間。當節點正在進行壓實或垃圾回收(GC)時,它可能需要更長的時間來處理請求佇列中的專案。如果僅僅基於最短佇列的演算法,在負載增加的情況下,即使節點的請求佇列過時,客戶端驅動程式也可能會繼續向其路由流量。
例如,請考慮以下情形。
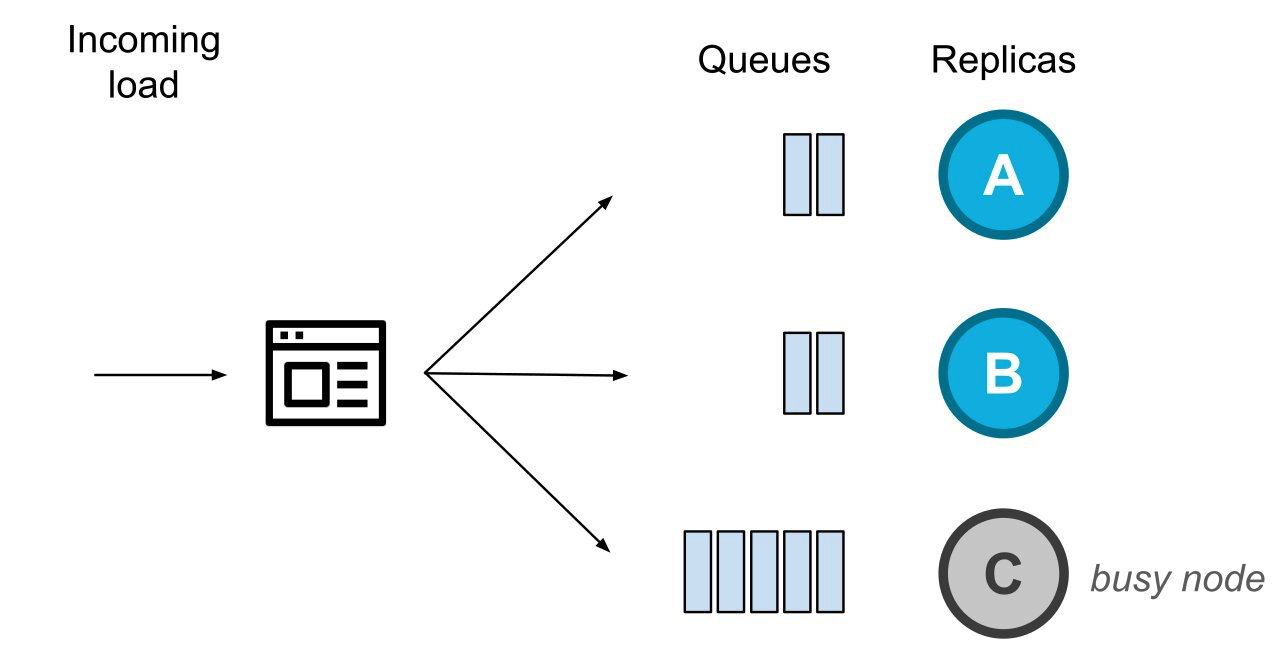
系統中有等待處理的請求,用佇列來表示
請求源源不斷而來,應用程式中的客戶端驅動程式例項在不斷地平衡傳送至三個副本節點請求。在某個時間點,節點C變得很忙(即一段時間不能處理請求)。其他正常的副本節點將繼續處理請求,如圖所示。
與此同時,系統傳入的負載正在增加,此時健康的副本節點們就會收到更多的待處理請求。
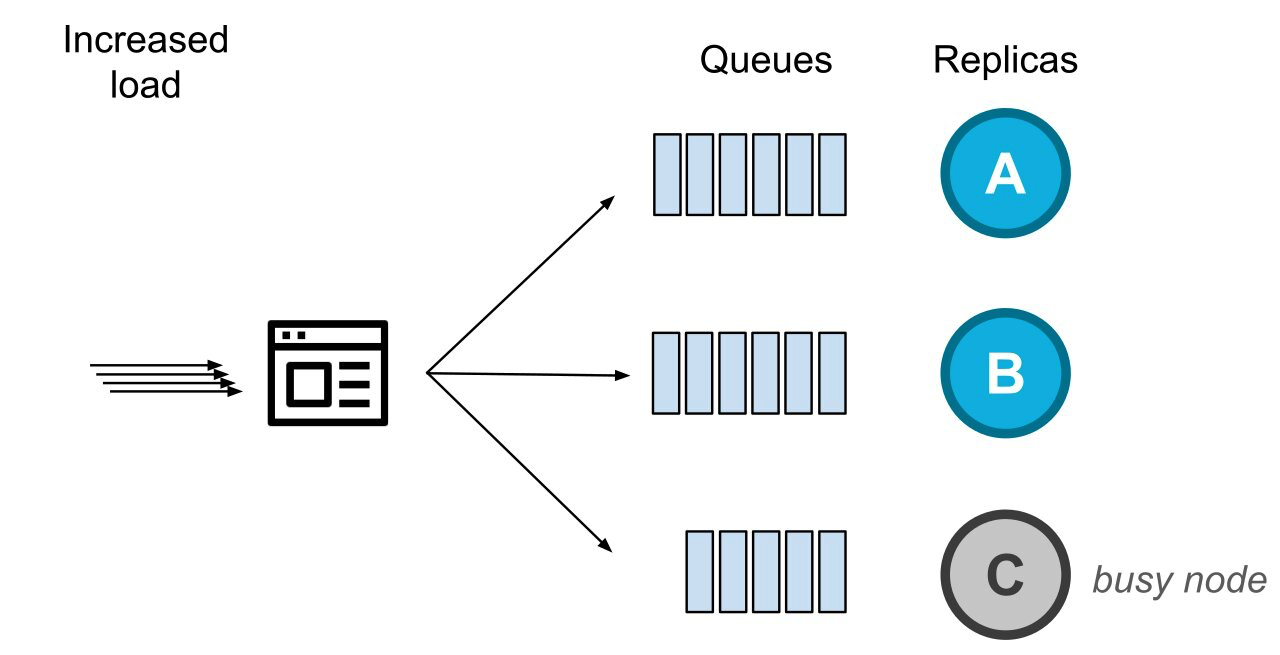
由於負載增加,健康的節點收到的待處理請求的數量增加了
在這種情況下,我們以前會將請求路由到那個無法以正常速度處理請求的節點(即上圖中的節點C)。
為了克服上述情況,我們引入了第二個指標:節點是否有待處理的請求(10+),並且在最近的幾百毫秒內還沒發回任何響應。這個指標並不作為”隨機選擇的二次方“的標識訊號,而是作為對副本節點的健康狀況進行的初步探測。
如果大多數副本節點是健康的,那麼不健康的副本節點將不會作為初始的協調節點(它們仍會被納入重試和投機性執行speculative execution的考慮範圍)。
為什麼把探測副本節點的健康狀況作為第一步?因為如果有大量節點是不健康的,則可能意味著該指標不適用於當前的工作負載、查詢類別或預計的延遲時間。這樣,我們確保不會根據一個在特定情況下並不適用的標識訊號做出錯誤的決定, 從而避免了讓情況變得更糟 。
05 總結
我們針對具有多個客戶端的一系列場景同時測試了這個新演算法,通過CPU burns(stress-ng)和人工網路延遲(tc)模擬了處於壓力下的節點,結果是該新演算法的效能優於所有其他方法。
作為示例,下圖按百分位分佈展現了延遲資料,在一些節點被CPU burns的情況下,對新演算法和隨機選擇演算法進行了比較。
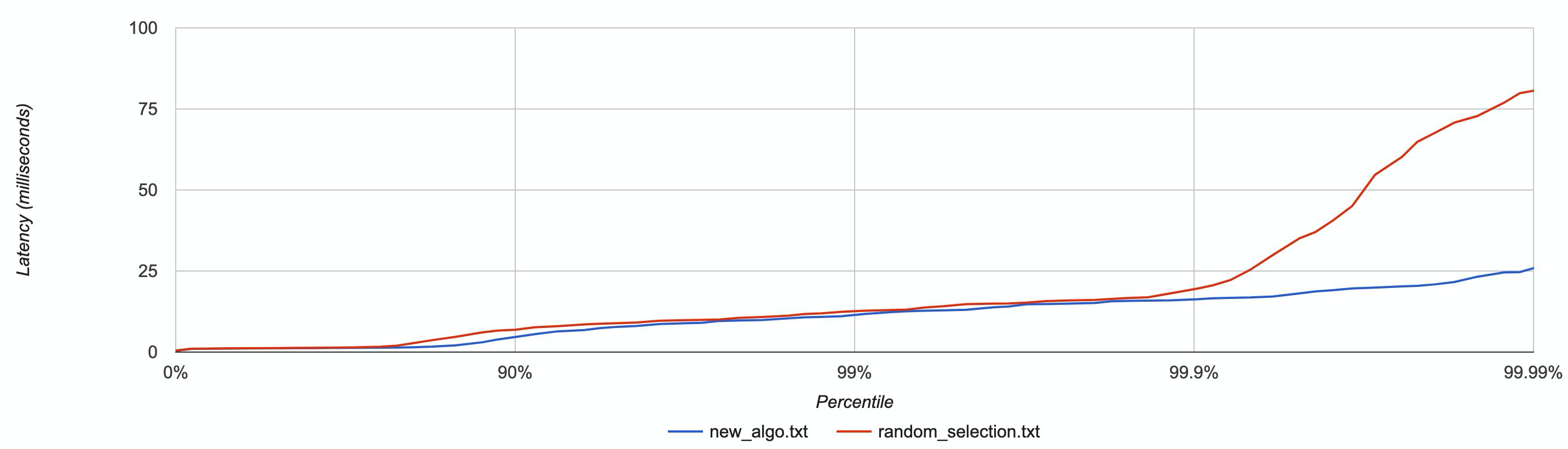 具有較低尾部延遲的新演算法(藍色)
具有較低尾部延遲的新演算法(藍色)
新的負載平衡演算法基於“隨機選擇的二次方”,再加上能夠躲開忙碌節點的邏輯判斷,即將成為DataStax Drivers新的預設設定。藉助簡單的邏輯判斷,這個新的演算法繞開了最差的候選節點,同時保證了流量分配有一定程度的隨機性。因而它能夠避免大家不希望看到的羊群效應,大大降低了尾部延遲時間。
我們將在所有的客戶端驅動程式中採用這種新演算法。Java和Node.js驅動程式從4.4版開始已經預設使用此演算法,其餘驅動程式也將很快跟