
分散式事務瞭解嗎?你們的多個服務間資料一致性解決方案是什麼?
阿新 • • 發佈:2020-12-21
## 前言
看標題就知道,這個又是個在面試中被問到的問題。這個問題其實是在我上次換工作的時候面試被問到過幾次,之前也沒在意過,覺得這個東西可能比較深奧,我直接說不理解吧。但是隨著Java開發這個行業越來越卷,這次換工作一定要做好充足的準備。把之前落下的坑都填好,再出去受虐(面試)。
## 什麼是分散式事務
我們都知道本地事務是有四個特性的:**原子性(atomicity)**、**一致性(consistency)**、**隔離性(isolation)**和**永續性(durability)**。
本地事務的ACID一般都是靠關係型資料庫來完成的,非關係型資料庫一般也可以考資料庫來實現,redis這種不能回滾的弱事務除外。
==**但是在分散式系統中一次操作由多個服務協同完成,這種一次事務操作涉及多個系統通過網路協同完成的過程稱為分散式事務。**==
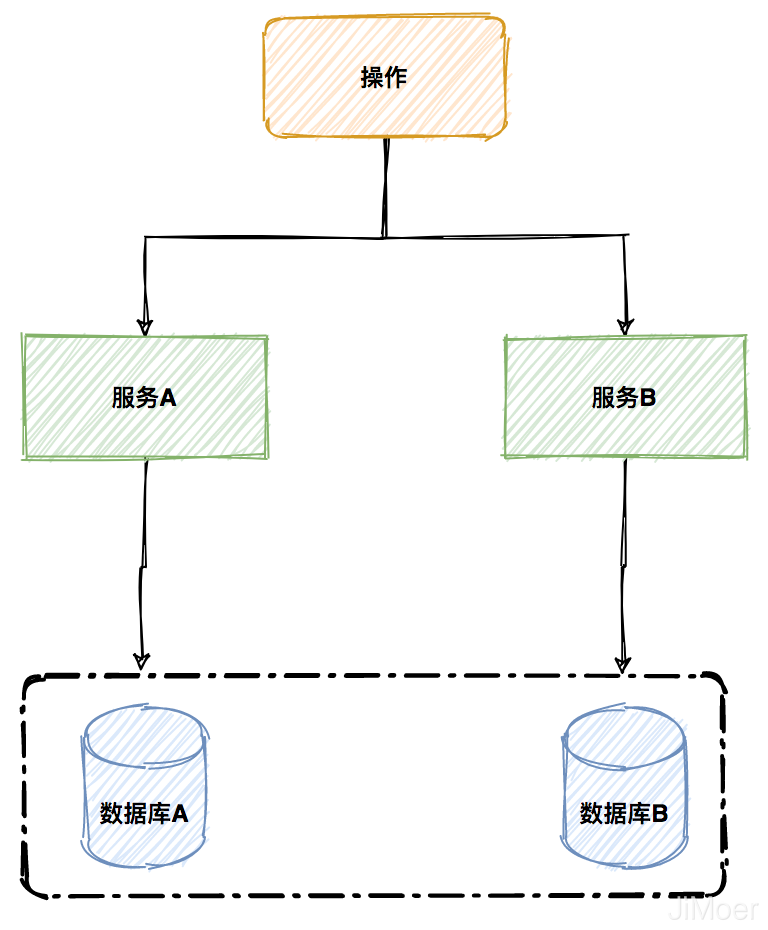
多個服務之間的可以是同一個資料庫,也可以是多個數據庫。
另外如果是在同一個服務中,使用了多個數據源連線了不同的資料庫,當一個事務需要操作多個數據源的時候也是屬於分散式事務。
## CAP
CAP理論是目前分散式系統中的處理分散式事務的理論基礎。主要是在目前分散式系統中都無法同時滿足如下三個屬性:
- **一致性(Consistency)**:==多個服務的資料需要保持在同一時刻的資料一致性。==
- **可用性(Availability)**:==指單個系統提供的服務需要一直保持可用狀態,對於每一個請求,都能及時的響應,超時或不無響應則認為系統不可用。==
- **分割槽容錯性(Partition Tolerance)**:==分散式系統再遇到任何網路分割槽故障時,仍能夠保證對外提供滿足一致性和可用性的服務,除非整個網路環境發生故障。==
在分散式系統中。一個服務最多隻能保證上面其中任何兩個屬性,並不能同時滿足。
在保證分割槽容錯性的時候並不能保證資料的一致性和服務的可用性。如果要提高服務的可用性,就要增加多個結點,雖然節點越多可用性越好,但是資料一致性就會越差。
這樣在分散式系統設計中,同時滿足“一致性”、“可用性”和“分割槽容錯性”幾乎是不可能的。
### CAP應用組合
- **【CA】放棄分割槽容錯性**:放棄分割槽容錯性,也要保證網路可用,最簡單的做法就是將所有資料都放在同一個節點上,雖然這樣無法保證100%系統不出錯,但至少不會出現由於網路分割槽帶來的負面影響。
- **【CP】放棄可用性**:放棄可用性,是指一但遇到網路分割槽或其他系統問題時,那受到影響的服務需要等待一定時間,應用等待期間系統無法對外提供正常服務。即短時間內不可用。
- **【AP】放棄一致性**:所謂的放棄一致性,其實並不是完全的不需要一致性,而是放棄強一致性,保證了資料最終一致性。
### BASE理論
在分散式系統中,往往追求的是可比性,一般重要程度比一致性高。所以就又出現了另一個理論,就是BASE理論,是對CAP理論的一個擴充。
- **Base Availability(基本可用);**
- **Soft state(軟狀態);**
- **Eventually consistent(最終一致性);**
BASE理論是對CAP理論中的一致性和可用性的一種權衡的結果,主要思想就是:無法做到強一致,但每個應用可以根據自身業務的特點,採用適當的方式來使系統達到最終的一致性。
## 分散式事務的解決方案
分散式事務的解決方案,目前市面上是有幾類的方式的。
- **2PC(兩階段提交)、3PC(三階段提交);**
- **TCC方案;**
- **本地訊息表;**
- **可靠訊息最終一致性方案;**
- **最大努力通知方案;**
### 2PC(兩階段提交)
兩階段提交主要是將提交事務和執行事務分為了兩步。
第一階段:事務協調器通知參與者準備提交事務,參與者準備成功之後向協調者返回成功,若有一個參與者返回的是準備不成功,那麼事務執行失敗。
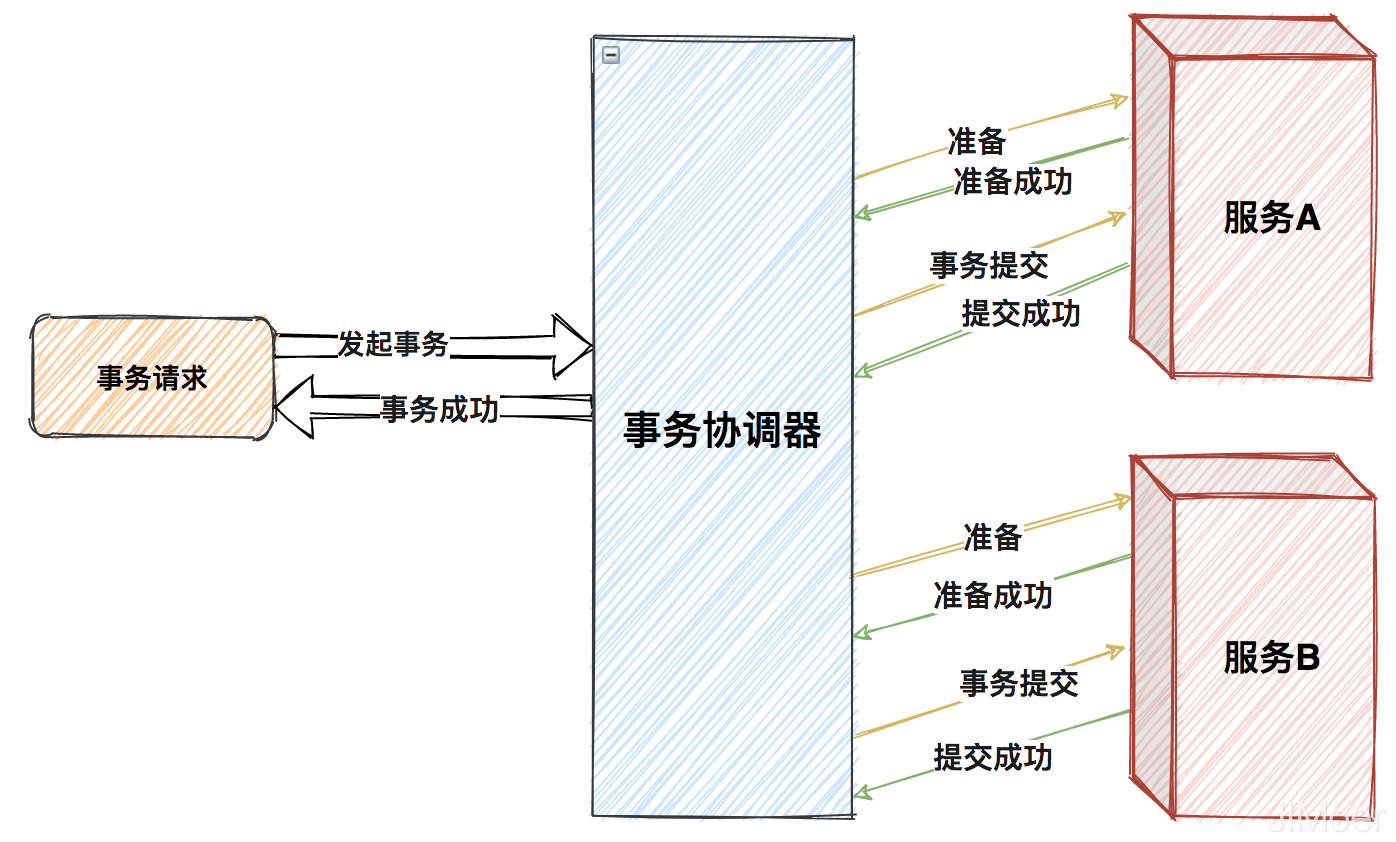
第二階段:事務協調器根據各個參與者的第一階段的返回結果,發起最終提交事務的請求,若有一個參與者提交失敗,則所有參與者都執行回滾,事務執行失敗。
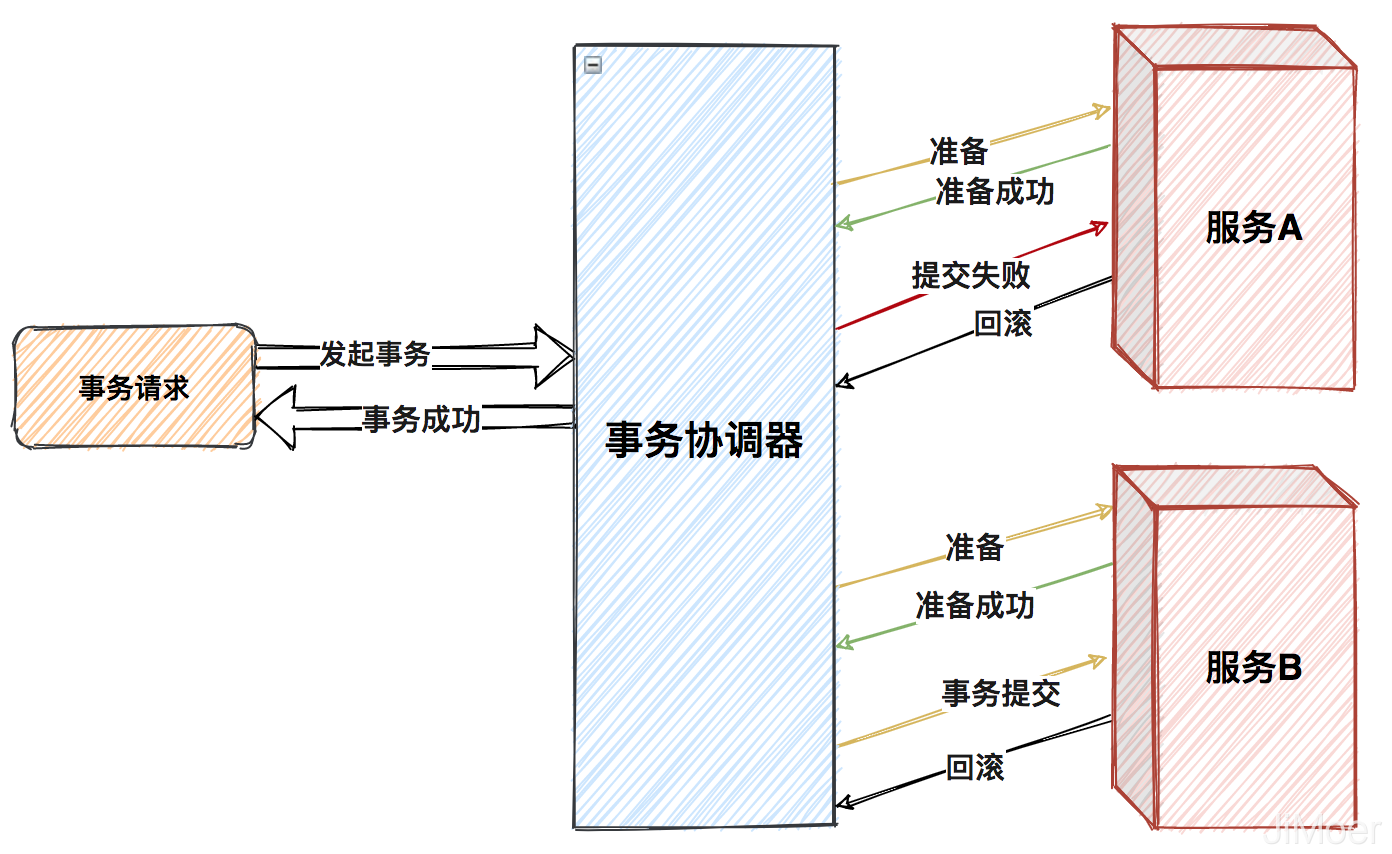
這種屬於強一致性的實現,因為在多個服務間的事務執行過程中,有可能第一個服務的事務已經提交了,第二服務提交失敗了,雖然說可以讓第二個服務的事務回滾但是第一個服務有可能事務已經執行完成了,無法進行回滾了。所以多數情況下是將第二個服務其實是進行重試提交,然後直到重試成功為止,重試到一定次數後仍沒有成功就需要預警出來人工干預了。
兩階段提交是一種儘量保證強一致性的分散式事務,因此它是同步阻塞的,而同步阻塞就導致長時間鎖定資源問題,所以總體而言效率低,並且存在單點故障的問題(有可能協調者掛,也有可能協調者和其中的某個服務掛了,協調者就不清楚掛了的那個服務到底是執行沒執行事務了),所以在極端情況下還是存在資料不一致的風險。
另外就是2PC其實更適合這種多資料來源的情況,並且資料來源都是關係型資料庫。這樣可以讓兩個資料庫中的事務都同時處於prepare階段,提交的時候兩個資料庫中的事務一起commit。
### 3PC(三階段提交)
3PC其實就是比較2PC多了一個預提交階段,3PC的第一階段做的事情其實是詢問參與者是否有條件執行事務,主要目的就是檢查一下是否都可用。第二階段才是和2PC的第一階段一樣呢。
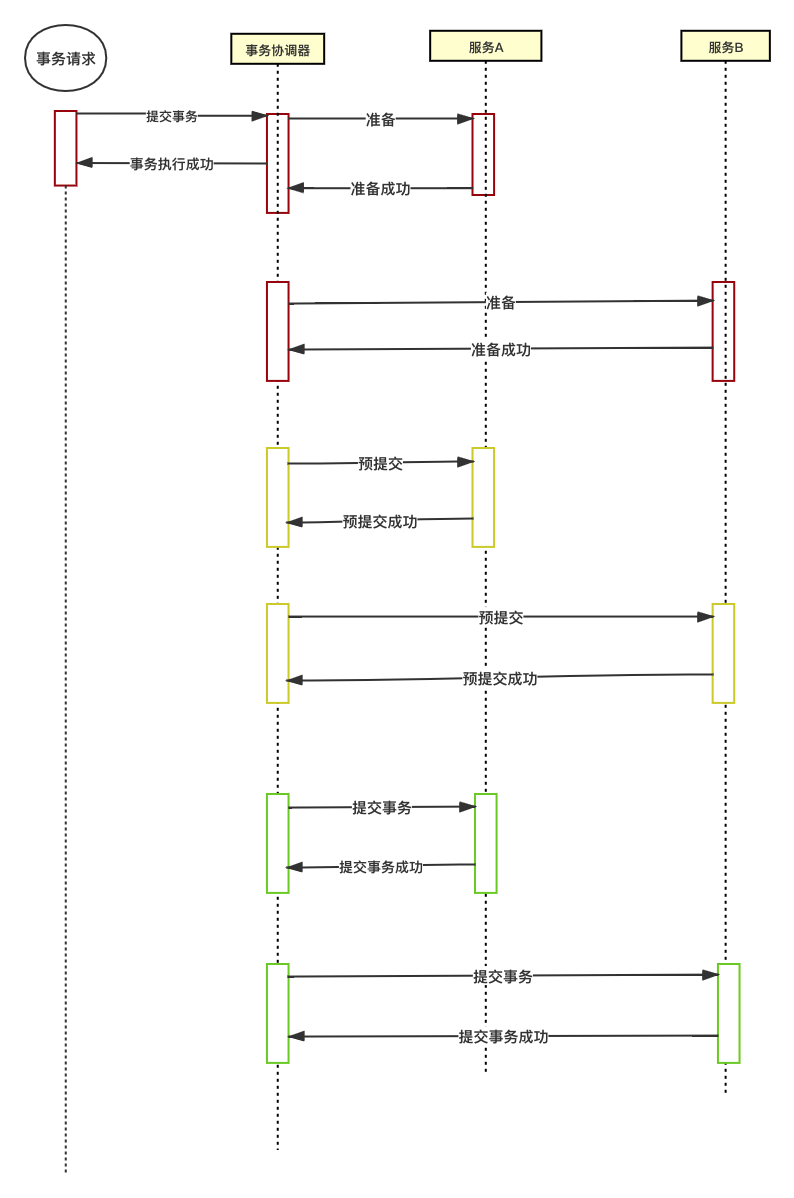
3PC出現的目的是為了解決,2PC階段協調組和參與者都掛了之後新選舉的協調者不知道當前應該提交還是應該回滾的問題。
如果新的協調者來的時候發現一個參與者處於預提交或提交階段,代表以及過了,所有參與者的確認階段,這樣就直接提交事務就可以了。
所以說新出現的預提交階段目的是為了讓協調者知道,每個參與者目前都是什麼階段,後面該如何同步各個參與者的狀態。
但是3PC還是不能保證,當協調者和某個參與者都掛了的時候,重新連線上的參與者是否已經執行了事務。
### TCC
TCC和上面的兩種方案對比更像是 ,分散式服務之間的事務解決方案。應用面更廣一些。
TCC的全稱是指:**Try、Confirm、Cancel**
- **Try**:對事務參與者的資源的鎖定與預留。
- **Confirm**:這個階段是在各個參與者服務中執行真正的事務操作。
- **Cancel**:如果任何一個服務的業務方法執行出錯,那麼這裡就需要進行補償,就是對已經執行的業務執行回滾操作。
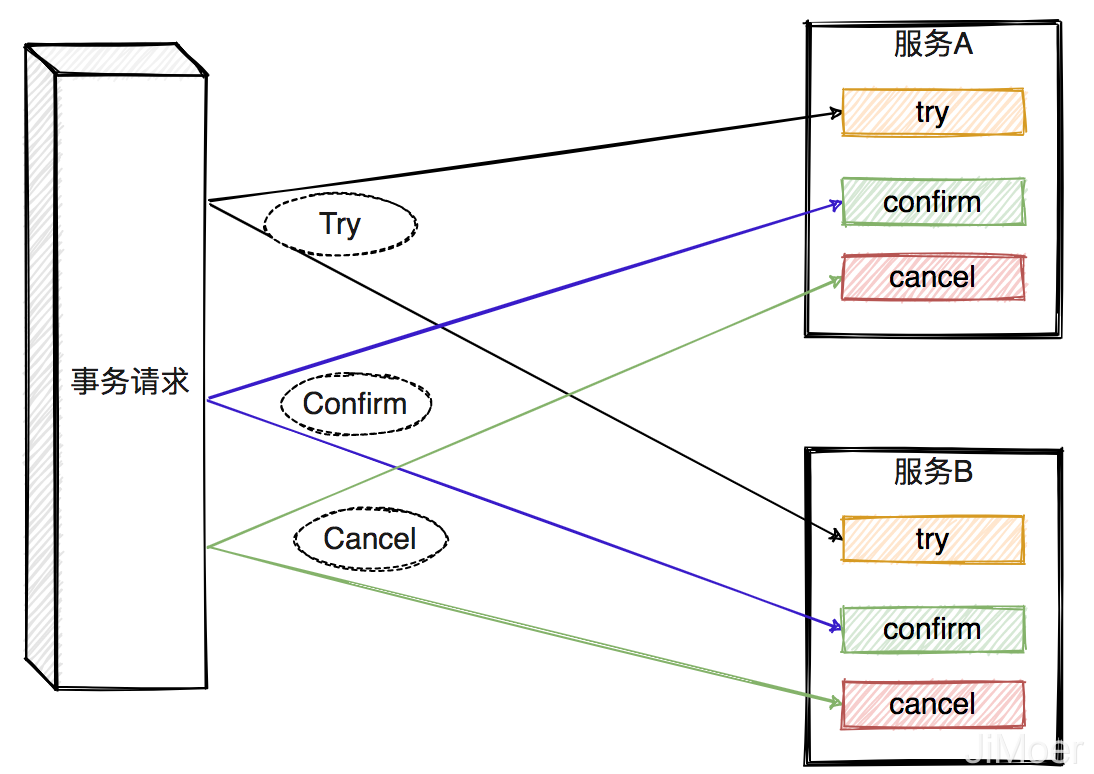
這種方式比較繁瑣,每一次事務都要定義三個操作,try-confirm-cancel。而且TCC對業務的侵入性比較大,每個業務都要寫相應得到撤銷方法。而且如果撤銷方法有不成功的情況,還有保證冪等。
但是還是有場景使用的,想一些涉及到支付、交易等這種強一致性,但又是多個服務的場景,使用TCC時比較合理的。這樣能嚴格保證分散式事務要麼都成功,要麼都失敗回滾。
### 本地訊息表
本地訊息表的思想主要是依靠各個服務之間的本地事務來保證的。
就是在服務的本地建立一張訊息表,一般是在資料庫中。
**當執行分散式事務的時候執行完本地操作後,在本地的訊息表中插入一條資料。**
**然後將訊息傳送到MQ中,下一個服務接收到訊息後執行本地操作,操作成功後更新訊息表中的狀態。**
**如果下一個服務執行失敗了,那麼訊息表中的狀態是不會變的,這樣就靠定時任務去刷訊息表來進行重試,但是這樣需要保證被重試的服務是冪等的,這樣就保證最終資料一致。**
### 可靠訊息
可靠訊息實際上指的是靠訊息中介軟體來實現分散式事務。
比如A公司的RocketMQ就用訊息中介軟體實現了分散式事務。
例如A系統會先發一個prepared訊息到MQ中,訊息傳送成功了,再執行本地事務,本地事務執行成功了告訴MQ事務執行成功了。否則傳送回滾訊息。
B系統接收到prepared訊息後開始執行本地事務,事務執行成功了,也是告訴MQ傳送執行成功。
MQ 會自動定時輪詢所有 prepared 訊息回撥你的介面,問你,這個訊息是不是本地事務處理失敗了,所有沒傳送確認的訊息,是繼續重試還是回滾?一般來說這裡你就可以查下資料庫看之前本地事務是否執行,如果回滾了,那麼這裡也回滾吧。這個就是避免可能本地事務執行成功了,而確認訊息卻傳送失敗了。
**這個時候就需要自己實現反查介面。**
如果這個方案裡,要是系統 B 的事務失敗了咋辦?重試咯,自動不斷重試直到成功,如果實在是不行,要麼就是針對重要的資金類業務進行回滾,比如 B 系統本地回滾後,想辦法通知系統 A 也回滾;或者是傳送報警由人工來手工回滾和補償。
### 最大努力通知
最大努力通知,其實也算是一種最終一致性的方案。
主要是當A系統執行完本地事務後,傳送訊息給MQ,然後去讓B系統執行事務操作,如果B系統執行完成了,就消費訊息,若B系統執行失敗了,則執行重試,重試多次直到成功。若達到一定次數後還沒成功就只能人工干預了。
## 總結
可靠訊息那部分是因為我沒有用過RocketMQ,所以並沒有認真寫,因為我目前在的是騰訊系的公司所以。。。
總結一下面試的時候如果被問到這個問題怎麼辦,其實就是根據實際的業務場景來看,像涉及到交易,訂單等這種強一致性的場景,可以使用TCC,雖然說對也侵入性大,但是最終目的是很好的保證了。
還有就是對於時效性要求不是很強的,我覺得的最大努力通知也可以的。
最後說一下我們的目前使用的方案;
也算是最大努力通知的一種吧,當在一個web服務中,呼叫多個服務時,如何保證多個服務執行時資料一致性的。
**當事務請求呼叫服務A時,如果服務A的操作執行失敗了,那麼直接事務執行失敗。**
**如果執行服務A的事務成功了,但是執行服務B的事務失敗了,那麼我們會先將失敗的請求落地(請求引數和被呼叫方資訊入到訊息表),然後將請求拋到訊息佇列中去進行重試,通過訊息佇列的ACK機制,保證我們重試訊息最終可以被消費成功。**
**主要重試次數是3次,每次的重試的時間間隔不一樣,重試三次之後如果訊息還沒有被ACK,那麼就直接傳送預警通知給開發人員,進行人工干預。**
**如果傳送消費失敗了,我們還有定時任務去定時刷我們的資料庫裡的訊息表,來保證訊息一定會被髮送。**
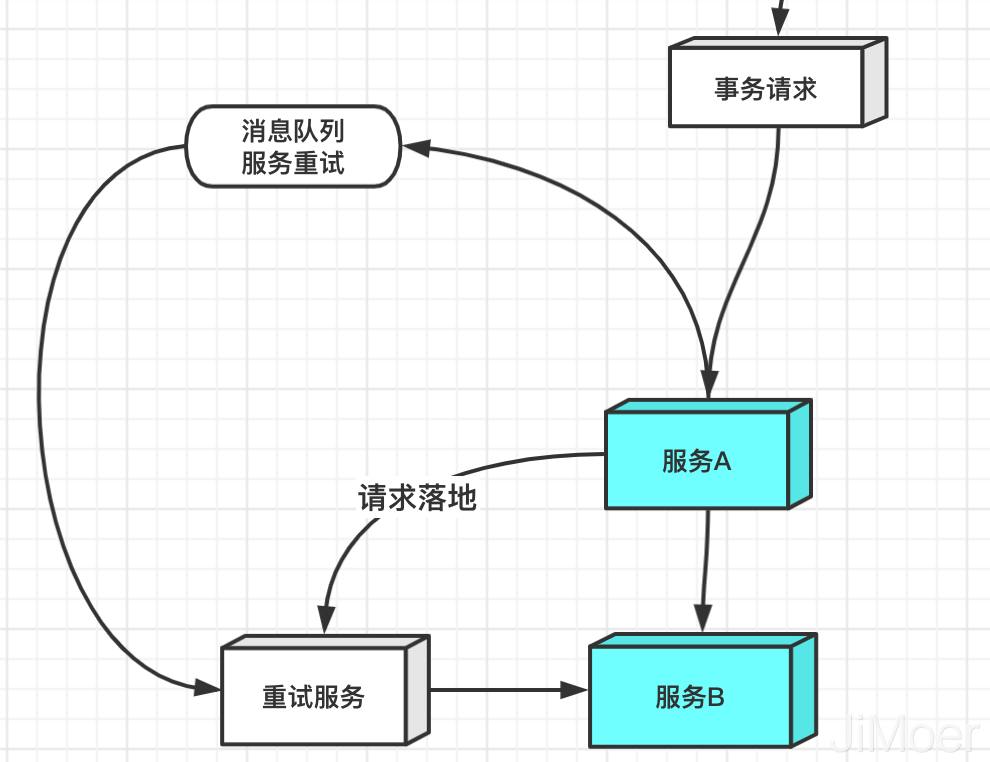
另外在真實涉及到支付,訂單交易的場景時,我們主要也是使用類似TCC的方式來保證的。
說是類似是因為,我們只有CC。要麼成功,要麼不成功,就直接呼叫回撤介面進行