
Kafka超詳細學習筆記【概念理解,安裝配置】
阿新 • • 發佈:2020-12-26
[toc]
> 官方文件:[http://kafka.apache.org/23/documentation.html#introduction](http://kafka.apache.org/23/documentation.html#introduction)
>
> 中文文件:[https://kafka.apachecn.org/](https://kafka.apachecn.org/)
## 本篇要點
1. 介紹kafka的特性、概念、API及專業術語。
2. 介紹Windows環境下kafka的安裝配置,啟動測試。
3. Java客戶端連線kafka的案例演示。
## Kafka介紹
Apache Kafka 是一個分散式流處理平臺:`distributed streaming platform`。
### 作為流處理平臺的三種特性
1. 可釋出和訂閱訊息(流),這與訊息佇列或企業訊息系統類似。
2. 以容錯(故障轉移)的方式儲存訊息(流)。
3. 提供實時的流處理。
### 主要應用
kafka主要應用於兩大類應用:
1. 構建實時的流資料通道,可靠地獲取系統和應用程式之間的資料。
2. 構建實時流的應用程式,對資料流進行轉換或反應。
### 四個核心API
1. Producer API:釋出訊息到一個或多個topic主題上。
2. Consumer API:訂閱一個或多個topic,處理產生的訊息。
3. Streams API:流處理器,從一個或多個topic消費輸入流,併產生一個輸出流到一個或多個輸出topic,有效地將輸入流轉換到輸出流。
4. Connector API:可構建或執行可重用地生產者或消費者,將topic連線到現有地應用程式或資料系統。
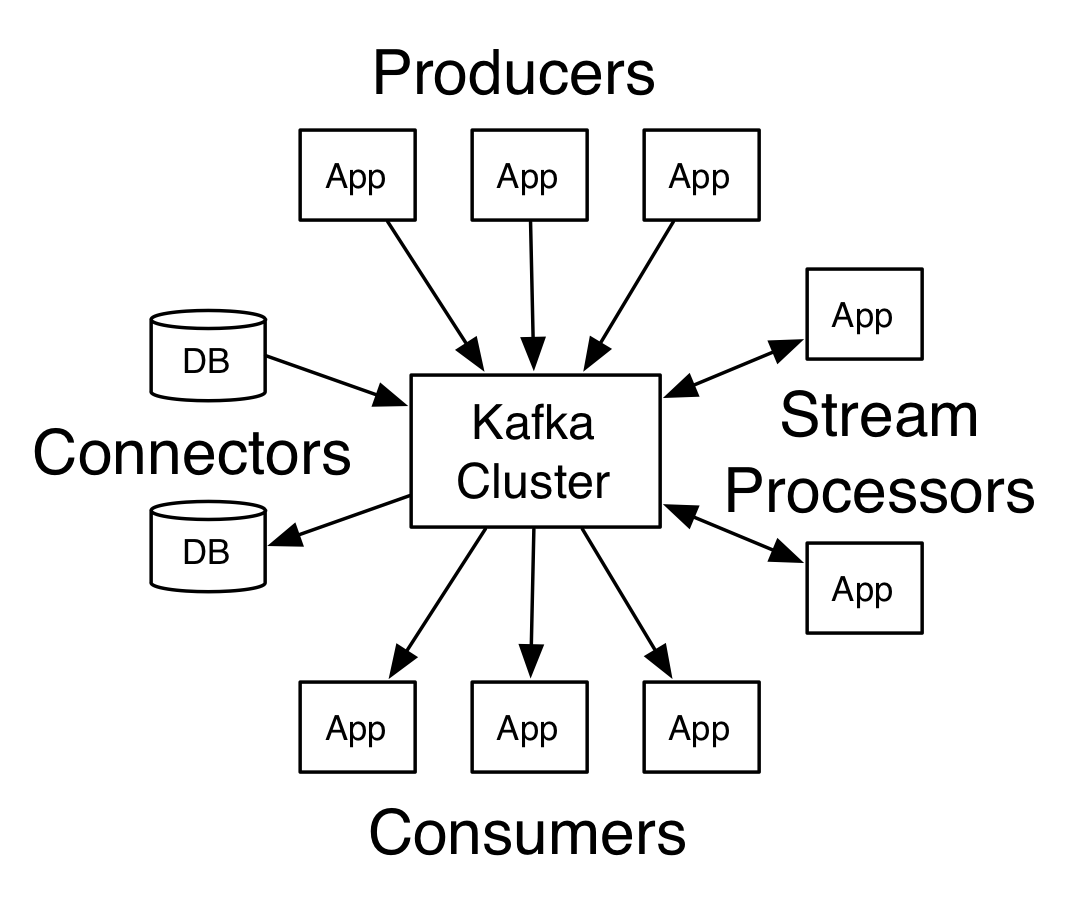
### 基本術語
Topic:kafka將訊息分類,每一類的訊息都有一個主題topic。
Producer:生產者,釋出訊息的物件。
Consumer:消費者,訂閱訊息的物件。
Broker:代理,已釋出的訊息儲存在一組伺服器中,稱之為kafka叢集,叢集中每個伺服器都是一個代理(broker)。消費者可以訂閱一個或多個主題,並從broker上拉取資料,從而消費這些已釋出的訊息。
Partition:Topic物理上的分組,**一個Topic可以分為多個partition,每個partition都是一個順序的、不可變的訊息佇列,且可以持續新增**。Partition中的每條訊息都會被分配一個有序的序列號,稱為偏移量(offset),因此每個分割槽中偏移量都是唯一的。
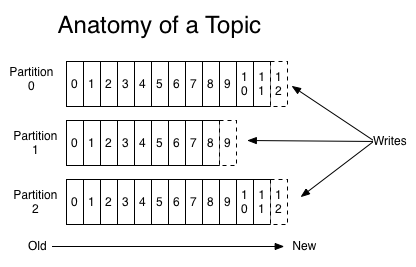
Consumer Group:每個Consumer屬於一個特定的Consumer Group,這是kafka用來實現一個Topic訊息的廣播【傳送給所有的consumer的**釋出訂閱式**訊息模型】和單播【傳送給任意一個consumer**佇列**訊息模型】的手段。一個topic可以有多個consumer group。
- 如果要實現廣播,只要每個consumer有獨立的consumer group就可以,此時就是釋出訂閱模型。
- 如果要實現單播,只要所有的consumer在同一個consumer group中就可以,此時就是佇列模型。
> **關於Consumer group的補充**:一般來說,我們可以建立一些consumer group作為邏輯上的訂閱者,每個組中包含數目不等的consumer,一個組內的多個消費者可以用來擴充套件效能和容錯。
>
> **關於partition分割槽的補充**:
>
> 1、【負載均衡】處理更多的訊息,不受單臺伺服器的限制。
>
> 2、【順序保證】kafka不能保證並行的時候訊息的有序性,但是可以保證一個partition分割槽之中,訊息只能由消費者組中的唯一一個消費者處理,以保證一個分割槽的訊息先後順序。
>
> 如下圖:2個kafka叢集託管4個分割槽(p0-p3),2個消費者組,組A有2個消費者例項,組B有4個消費者例項。
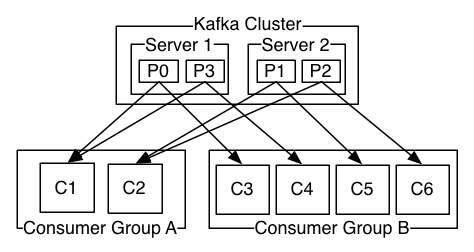
> 關於偏移量的補充:kafka叢集將會保持所有的訊息,直到他們過期,無論他們是否被消費。當消費者消費訊息時,偏移量offset將會線性增加,但是**消費者其實可以控制實際的偏移量,可以重置偏移量為更早的位置,意為著重新讀取訊息**,且不會影響其他消費者對此log的處理。

## 快速開始
### 安裝配置Zookeeper
Kafka的安裝配置啟動需要依賴於Zookeeper,Zookeeper的安裝配置可以參考我的前一篇文章。
當然,其實你下載kafka之後,就自動已經集成了Zookeeper,你可以通過修改配置,啟動內建的zookeeper。
> 關於使用內建的Zookeeper還是自己安裝的Zookeeper的區別,可以看看這篇文章:[https://segmentfault.com/q/1010000021110446](https://segmentfault.com/q/1010000021110446)
### 下載kafka
下載地址:[http://kafka.apache.org/downloads](http://kafka.apache.org/downloads)
下載二進位制版本【Binary downloads】,下載完成之後,解壓到合適的目錄下。
筆者目錄為:`D:\dev\kafka_2.11-2.3.1`。
### 配置檔案
進入`config`目錄下,找到`server.properties`檔案並修改如下:
```properties
log.dirs=D:\\dev\\kafka_2.11-2.3.1\\config\\kafka-logs
zookeeper.connect=localhost:2182 # 預設埠是2181,這裡修改為2182
```
找到`zookeeper.properties`檔案,修改如下:
```properties
dataDir=D:\\softs\\zookeeper-3.4.13\\datas
dataLogDir=D:\\softs\\zookeeper-3.4.13\\logs
clientPort=2182
```
### Windows的命令
在bin目錄下存放著所有可以使用的命令列指令,Linux和Windows的存放目錄需要注意:
### 啟動Zookeeper
```shell
D:\dev\kafka_2.11-2.3.1> .\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
```

### 啟動Kafka
```shell
D:\dev\kafka_2.11-2.3.1> .\bin\windows\kafka-server-start.bat .\config\server.properties
```

## 進行測試
### 建立topic
建立1個分割槽1個副本,topic為test-topic
```shell
D:\dev\kafka_2.11-2.3.1>.\bin\windows\kafka-topics.bat --create --zookeeper localhost:2182 --replication-factor 1 --partitions 1 --topic test-topic
Created topic test-topic.
```
### 檢視topic
```shell
D:\dev\kafka_2.11-2.3.1>.\bin\windows\kafka-topics.bat --list --zookeeper localhost:2182
test-topic
```
### 生產者
```shell
D:\dev\kafka_2.11-2.3.1>.\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic test-topic
```
### 消費者
```shell
D:\dev\kafka_2.11-2.3.1>.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test-topic --from-beginning
```
### 生產者與消費者訊息傳遞
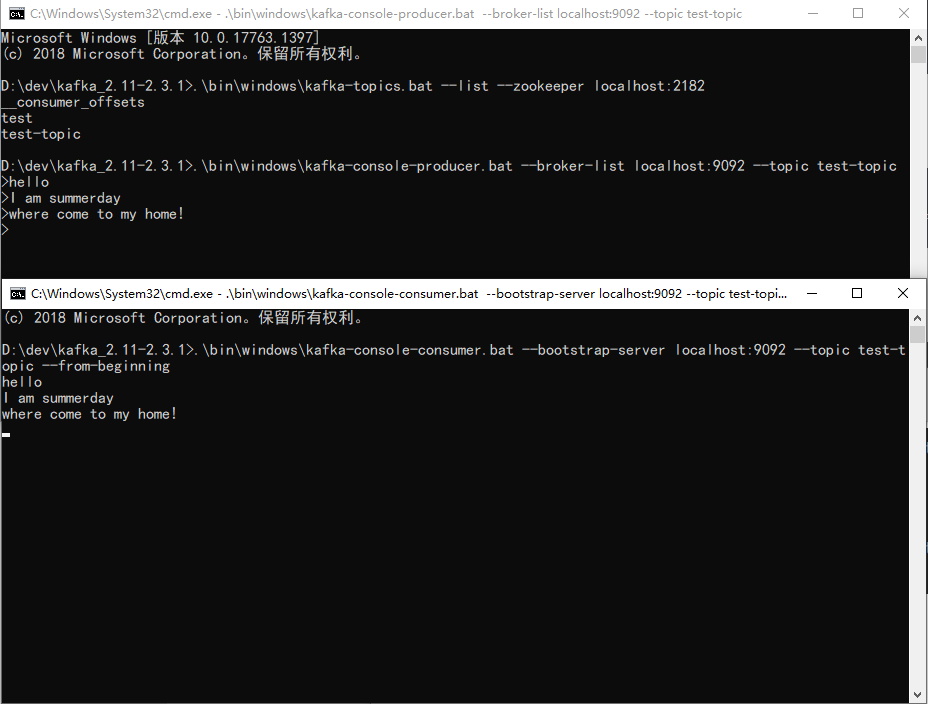
### 刪除topic
如果kafka啟動時載入的配置檔案中 server.properties 中沒有配置delete.topic.enable=true,則此刪除非真正刪除,而是僅僅將topic標記為marked for deletion
```shell
D:\dev\kafka_2.11-2.3.1>.\bin\windows\kafka-topics.bat --delete --zookeeper localhost:2182 --topic test-topic
Topic test-topic is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
```
### 登入內建的zookeeper客戶端
```shell
D:\dev\kafka_2.11-2.3.1\bin\windows>zookeeper-shell.bat localhost:2182
Connecting to localhost:2182
Welcome to ZooKeeper!
JLine support is disabled
```
### 物理刪除topic
```shell
ls /brokers
[ids, topics, seqid]
ls /brokers/topics
[test, test-topic, __consumer_offsets]
rmr /brokers/topics/test-topic # 物理刪除 test-topic
ls /brokers/topics
[test, __consumer_offsets]
```
## Java客戶端使用
### 引入依賴
```xml
org.apache.kafka 2.6.0
```
### 生產者
```java
public class ProducerExample {
public static void main(String[] args) {
Map props = new HashMap<>();
props.put("zk.connect", "localhost:2182");
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer producer = new KafkaProducer<>(props);
String topic = "test";
for (int i = 1; i <= 100; i++) {
// send方法是非同步的 , 返回Future物件,如果呼叫get(),將阻塞,直到相關請求完成並返回訊息的metadata或丟擲異常
producer.send(new ProducerRecord<>(topic, "key" + i, "msg" + i * 100));
}
// 生產者的傳衝空間池保留尚未傳送到伺服器的訊息,後臺I/O執行緒負責將這些訊息轉換程請求傳送到叢集
// 如果使用後不關閉生產者,將會丟失這些訊息。
producer.close();
}
}
```
- zk.connect:設定zookeeper的地址。
- bootstrap.servers:用於建立與 kafka 叢集連線的 host/port 組。
- acks:判斷是不是成功傳送,指定`all`將會阻塞訊息,這種設定效能最低,但是是最可靠的。
- retries:如果請求失敗,生產者會自動重試,我們指定是0次,如果啟用重試,則會有重複訊息的可能性。
- batch.size:(生產者)快取每個分割槽未傳送的訊息。快取的大小是通過 `batch.size` 配置指定的。值較大的話將會產生更大的批。並需要更多的記憶體(因為每個“活躍”的分割槽都有1個緩衝區)。
- linger.ms:預設緩衝可立即傳送,即便緩衝空間還沒有滿,但是,如果你想減少請求的數量,可以設定linger.ms大於0。這將指示生產者傳送請求之前等待一段時間,希望更多的訊息填補到未滿的批中。這類似於TCP的演算法,例如上面的程式碼段,可能100條訊息在一個請求傳送,因為我們設定了linger(逗留)時間為1毫秒,然後,如果我們沒有填滿緩衝區,這個設定將增加1毫秒的延遲請求以等待更多的訊息。需要注意的是,在高負載下,相近的時間一般也會組成批,即使是 `linger.ms=0`。在不處於高負載的情況下,如果設定比0大,以少量的延遲代價換取更少的,更有效的請求。
- buffer.memory:控制生產者可用的快取總量,如果訊息傳送速度比其傳輸到伺服器的快,將會耗盡這個快取空間。當快取空間耗盡,其他傳送呼叫將被阻塞,阻塞時間的閾值通過`max.block.ms`設定,之後它將丟擲一個TimeoutException。
- key.serializer:用於序列化。
- value.serializer:用於序列化。
### 消費者
```java
public class ConsumerSample {
public static void main(String[] args) {
String topic = "test";// topic name
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "testGroup1");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
Consumer consumer = new KafkaConsumer(props);
// 訂閱多個主題
consumer.subscribe(Arrays.asList(topic));
while (true) {
// 訂閱一組topic之後,呼叫poll時,消費者將自動加入到組中。
// 只要持續呼叫poll,消費者將一直保持可用,並繼續從分配的分割槽中接收訊息。
// 消費者向伺服器定時傳送心跳,如果在session.timeout.ms配置的時間內無法傳送心跳,被視為死亡,分割槽將重新分配
ConsumerRecords records = consumer.poll(100);
for (ConsumerRecord record : records)
System.out.printf("*****************partition = %d, offset = %d, key = %s, value = %s%n", record.partition(), record.offset(), record.key(), record.value());
}
}
}
```
- bootstrap.servers:用於建立與 kafka 叢集連線的 host/port 組。
- group.id:消費者的組名,組名相同的消費者被視為同一個消費組。
- enable.auto.commit:設定Consumer 的 offset 是否自動提交。
- auto.commit.interval.ms:上面屬性設定為true,由本屬性設定自動提交 offset 到 zookeeper 的時間間隔,時間是毫秒
- key.deserializer:用於反序列化。
- value.deserializer:用於反序列化。
Kafka通過程序池瓜分訊息並處理訊息,這些程序可以在同一臺機器執行,也可以分佈到多臺機器上,以增加可擴充套件型和容錯性,相同的`group.id`的消費者將視為同一個消費者組。
組中的每個消費者都通過`subscribe API`動態的訂閱一個topic列表。kafka將已訂閱topic的訊息傳送到每個消費者組中。並通過平衡分割槽在消費者分組中所有成員之間來達到平均。因此每個分割槽恰好地分配1個消費者(一個消費者組中)。所有如果一個topic有4個分割槽,並且一個消費者分組有隻有2個消費者。那麼每個消費者將消費2個分割槽。
消費者組的成員是動態維護的:如果一個消費者故障。分配給它的分割槽將重新分配給同一個分組中其他的消費者。同樣的,如果一個新的消費者加入到分組,將從現有消費者中移一個給它。這被稱為`重新平衡分組`。
### 啟動Zookeeper和kafka
建立topic
```shell
D:\dev\kafka_2.11-2.3.1>.\bin\windows\kafka-topics.bat --create --zookeeper localhost:2182 --replication-factor 1 --partitions 1 --topic test
```
啟動zookeeper
```shell
D:\dev\kafka_2.11-2.3.1>.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
```
啟動kafka
```shell
D:\dev\kafka_2.11-2.3.1>.\bin\windows\kafka-server-start.bat .\config\server.properties
```
### 測試
先啟動消費者ConsumerExample,再啟動生產者ProducerExample,觀察控制檯。
## 總結
- kafka作為一個訊息系統,它設計了partition分割槽,提供了負載均衡能力,保證了訊息分割槽內的順序。
- kafka擁有消費者組的概念,很好地實現釋出訂閱和佇列式的訊息模型。
- kafka作為一個儲存系統,高效能,低延遲。
- kafka能夠提供實時的流處理,提供強大的StreamsAPI,而不是簡單的讀寫和儲存。
## 參考閱讀
- [http://kafka.apache.org/23/documentation.html#introduction](http://kafka.apache.org/23/documentation.html#introduction)
- [https://kafka.apachecn.org/](https://kafka.apachecn.org/)
- [芋道原始碼:訊息佇列kafka](http://www.iocoder.cn/Kafka/yuliu/doc/)
- [無名:kafka生產者Java客戶端](https://www.orchome.com/303)
- [半獸人 kafka命令大全](https://www.orchome.