
高端面試必備:一個Java物件佔用多大記憶體
阿新 • • 發佈:2020-12-29
這個問題一般會出現在稍微高階一點的 Java 面試環節。要求面試者不僅對 Java 基礎知識熟悉,更重要的是要了解記憶體模型。
#### Java 物件模型
HotSpot JVM 使用名為 oops (Ordinary Object Pointers) 的資料結構來表示物件。這些 oops 等同於本地 C 指標。 instanceOops 是一種特殊的 oop,表示 Java 中的物件例項。
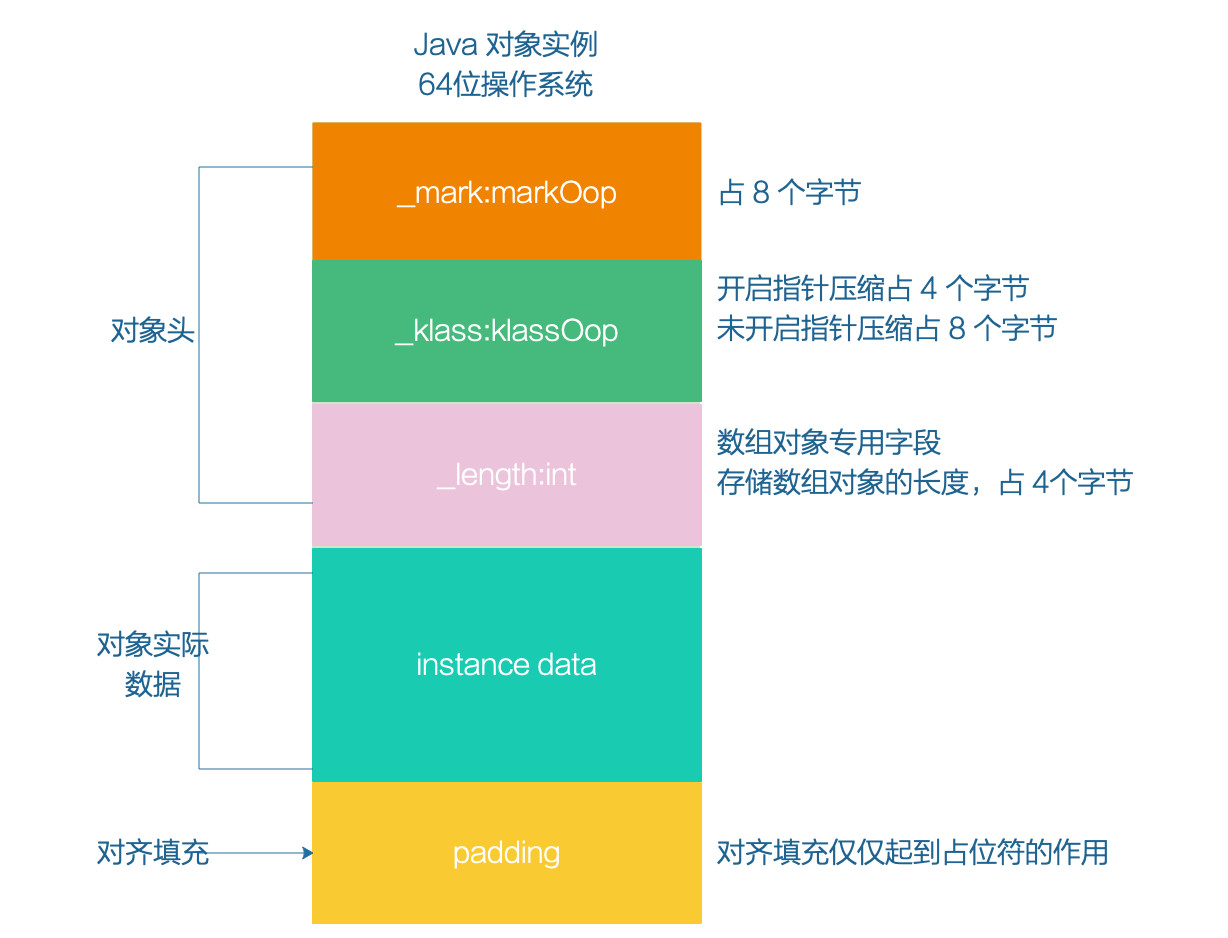
在 Hotspot VM 中,物件在記憶體中的儲存佈局分為 3 塊區域:
- 物件頭(Header)
- 例項資料(Instance Data)
- 對齊填充(Padding)
物件頭又包括三部分:MarkWord、元資料指標、陣列長度。
- MarkWord:用於儲存物件執行時的資料,好比 HashCode、鎖狀態標誌、GC分代年齡等。**這部分在 64 位作業系統下佔 8 位元組,32 位作業系統下佔 4 位元組。**
- 指標:物件指向它的類元資料的指標,虛擬機器通過這個指標來確定這個物件是哪一個類的例項。
這部分就涉及到指標壓縮的概念,**在開啟指標壓縮的狀況下佔 4 位元組,未開啟狀況下佔 8 位元組。**
- 陣列長度:這部分只有是陣列物件才有,**若是是非陣列物件就沒這部分。這部分佔 4 位元組。**
例項資料就不用說了,用於儲存物件中的各類型別的欄位資訊(包括從父類繼承來的)。
關於對齊填充,Java 物件的大小預設是按照 8 位元組對齊,也就是說 Java 物件的大小必須是 8 位元組的倍數。若是算到最後不夠 8 位元組的話,那麼就會進行對齊填充。
那麼為何非要進行 8 位元組對齊呢?這樣豈不是浪費了空間資源?
其實不然,由於 CPU 進行記憶體訪問時,一次定址的指標大小是 8 位元組,正好也是 L1 快取行的大小。如果不進行記憶體對齊,則可能出現跨快取行的情況,這叫做 **快取行汙染**。
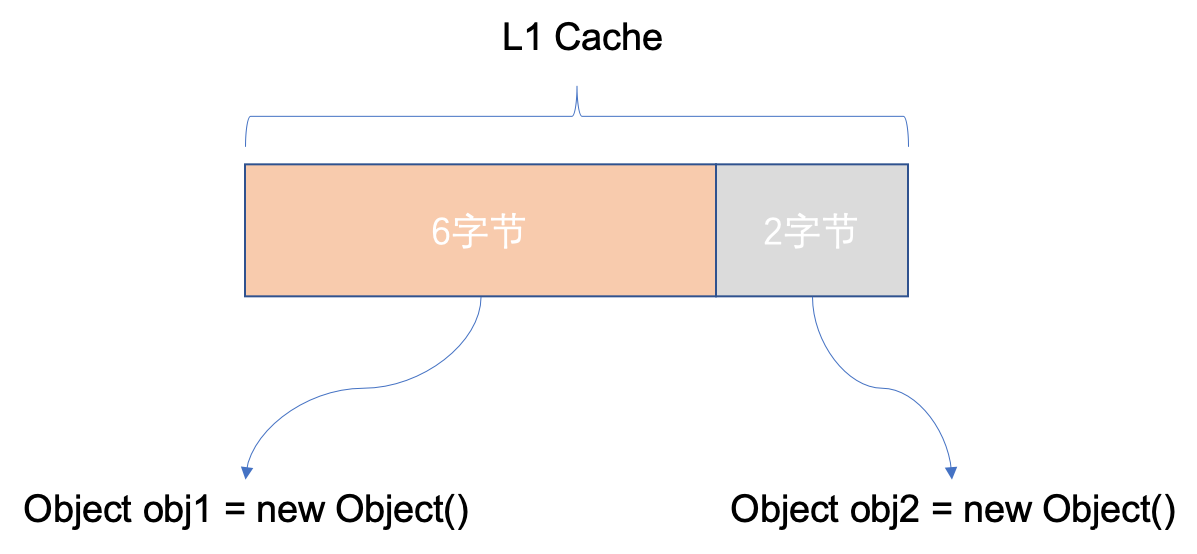
由於當 obj1 物件的欄位被修改後,那麼 CPU 在訪問 obj2 物件時,必須將其重新載入到快取行,因此**影響了程式執行效率**。
也就說,8位元組對齊,是為了效率的提高,以空間換時間的一種方案。固然你還能夠 16 位元組對齊,可是 8 位元組是最優選擇。
正如我們之前看到的,JVM 為物件進行填充,使其大小變為 8 個位元組的倍數。使用這些填充後,oops 中的最後三位始終為零。這是因為在二進位制中 8 的倍數的數字總是以 000 結尾。
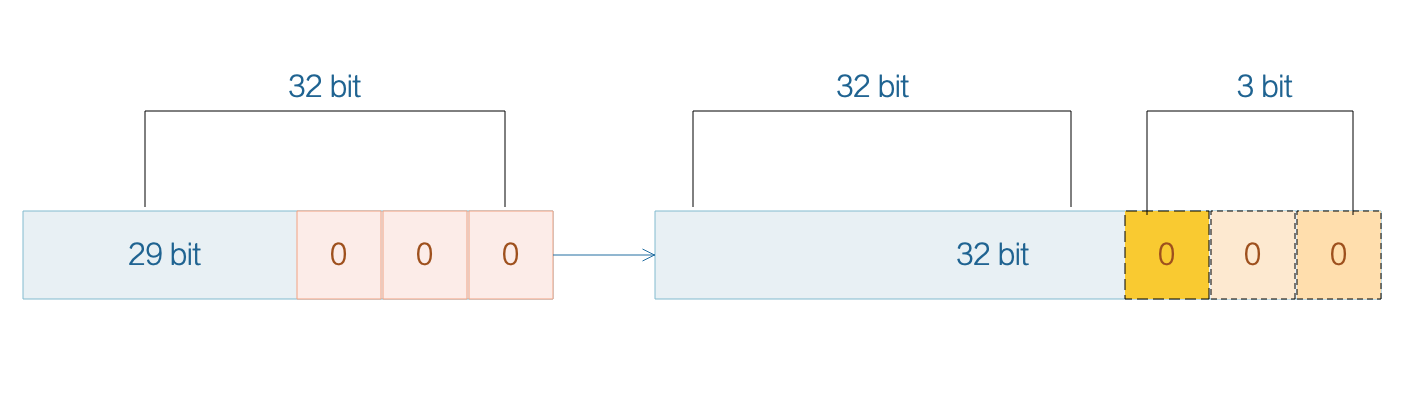
由於 JVM 已經知道最後三位始終為零,因此在堆中儲存那些零是沒有意義的。相反假設它們存在並存儲 3 個其他更重要的位,以此來模擬 35 位的記憶體地址。現在我們有一個帶有 3 個右移零的 32 位地址,所以我們將 35 位指標壓縮成 32 位指標。這意味著我們可以在不使用 64 位引用的情況下使用最多 32 GB :
(2^(32+3)=2^35=32 GB) 的堆空間。
當 JVM 需要在記憶體中找到一個物件時,它將指標向左移動 3 位。另一方面當堆載入指標時,JVM 將指標向右移動 3 位以丟棄先前新增的零。雖然這個操作需要 JVM 執行更多的計算以節省一些空間,不過對於大多數CPU來說,位移是一個非常簡單的操作。
要啟用 oop 壓縮,我們可以使用標誌 -*XX:+UseCompressedOops* 進行調整,只要最大堆大小小於 32 GB。當最大堆大小超過32 GB時,JVM將自動關閉 oop 壓縮。
當 Java 堆大小大於 32GB 時也可以使用壓縮指標。雖然預設物件對齊是 8 個位元組,但可以使用 -*XX*:*ObjectAlignmentInBytes* 配置位元組值。指定的值應為 2 的冪,並且必須在 8 和 256 的範圍內。
我們可以使用壓縮指標計算最大可能的堆大小,如下所示:
```
4 GB * ObjectAlignmentInBytes
```
例如,當物件對齊為 16 個位元組時,通過壓縮指標最多可以使用 64 GB 的堆空間。
#### 基本型別佔用儲存空間和指標壓縮
##### 基礎物件佔用儲存空間
Java 基礎物件在記憶體中佔用的空間如下:
| 型別 | 佔用空間(byte) |
| ------- | -------------- |
| boolean | 1 |
| byte | 1 |
| short | 2 |
| char | 2 |
| int | 4 |
| float | 4 |
| long | 8 |
| double | 8 |
另外,引用型別在 32 位系統上每個引用物件佔用 4 byte,在 64 位系統上每個引用物件佔用 8 byte。
對於 32 位系統,記憶體地址的寬度就是32位,這就意味著我們最大能獲取的記憶體空間是 `2^32(4 G)`位元組。在 64 位的機器中,理論上我們能獲取到的記憶體容量是 `2^64` 位元組。
當然這只是一個理論值,現實中因為有一堆有關硬體和軟體的因素限制,我們能得到的記憶體要少得多。比如說,Windows 7 Home Basic 64 位最大僅支援 8GB 記憶體、Home Premium 為 192GB,此外高階的Enterprise、Ultimate 等則支援支援 192GB 的最大記憶體。
因為系統架構限制,Windows 32位系統能夠識別的記憶體最大在 3.235GB 左右,也就是說 4GB 的記憶體條有 0.5GB 左右用不了。2GB 記憶體條或者 2GB+1GB 記憶體條用 32 位系統絲毫沒有影響。
現在一般都是使用 64 位的系統,雖然能支援更大的記憶體空間,但是也會有另一些問題。
像引用型別在 64 位系統上佔用 8 個位元組,那麼引用物件將會佔用更多的堆空間。從而加快了 GC 的發生。其次會降低CPU快取的命中率,快取大小是固定的,物件越大能快取的物件個數就越少。
**Java 中基礎資料型別是在棧上分配還是在堆上分配?**
我們繼續深究一下,基本資料類佔用記憶體大小是固定的,那具體是在哪分配的呢,是在堆還是棧還是方法區?大家不妨想想看! 要解答這個問題,首先要看這個資料型別在哪裡定義的,有以下三種情況。
- 如果在方法體內定義的,這時候就是在棧上分配的
- 如果是類的成員變數,這時候就是在堆上分配的
- 如果是類的靜態成員變數,在方法區上分配的
##### 指標壓縮
引用型別在 64 位系統上佔用 8 個位元組,雖然一個並不大,但是耐不住多。
所以為了解決這個問題,JDK 1.6 開始 64 bit JVM 正式支援了 **-XX:+UseCompressedOops (需要jdk1.6.0_14)** ,這個引數可以壓縮指標。
啟用 CompressOops 後,會壓縮的物件包括:
- 物件的全域性靜態變數(即類屬性);
- 物件頭資訊:64 位系統下,原生物件頭大小為 16 位元組,壓縮後為 12 位元組;
- 物件的引用型別:64 位系統下,引用型別本身大小為 8 位元組,壓縮後為 4 位元組;
- 物件陣列型別:64 位平臺下,陣列型別本身大小為 24 位元組,壓縮後 16 位元組。
當然壓縮也不是萬能的,針對一些特殊型別的指標 JVM是不會優化的。 比如:
- 指向非 Heap 的物件指標
- 區域性變數、傳參、返回值、NULL指標。
##### CompressedOops 工作原理
32 位內最多可以表示 4GB,64 位地址為 **堆的基地址 + 偏移量**,當堆記憶體 < 32GB 時候,在壓縮過程中,把 ***偏移量 / 8*** 後儲存到 32 位地址。在解壓再把 32 位地址放大 8 倍,所以啟用 CompressedOops 的條件是堆記憶體要在 *4GB \* 8=32GB* 以內。
JVM 的實現方式是,不再儲存所有引用,而是每隔 8 個位元組儲存一個引用。例如,原來儲存每個引用 0、1、2...,現在只儲存 0、8、16...。因此,指標壓縮後,並不是所有引用都儲存在堆中,而是以 8 個位元組為間隔儲存引用。
在實現上,堆中的引用其實還是按照 0x0、0x1、0x2... 進行儲存。只不過當引用被存入 64 位的暫存器時,JVM 將其左移 3 位(相當於末尾新增 3 個0),例如 0x0、0x1、0x2... 分別被轉換為 0x0、0x8、0x10。而當從暫存器讀出時,JVM 又可以右移 3 位,丟棄末尾的 0。(oop 在堆中是 32 位,在暫存器中是 35 位,2的 35 次方 = 32G。也就是說使用 32 位,來達到 35 位 oop 所能引用的堆記憶體空間)。
#### Java 物件到底佔用多大記憶體
前面我們分析了 Java 物件到底都包含哪些東西,所以現在我們可以開始剖析一個 Java 物件到底佔用多大記憶體。
由於現在基本都是 64 位的虛擬機器,所以後面的討論都是基於 64 位虛擬機器。 **首先記住公式,物件由 物件頭 + 例項資料 + padding 填充位元組組成,虛擬機器規範要求物件所佔記憶體必須是 8 的倍數,padding 就是幹這個的**。
上面說過物件頭由 Markword + 類指標kclass(該指標指向該型別在方法區的元型別) 組成。
**Markword**
Hotspot 虛擬機器文件 “oops/oop.hp” 有對 Markword 欄位的定義:
64 bits:
\--------
unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object)
JavaThread:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object)
*PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object)
size:64 ----------------------------------------------------->| (CMS free block)
這裡簡單解釋下這幾種 object:
- **normal object,初始 new 出來的物件都是這種狀態**
- **biased object,當某個物件被作為同步鎖物件時,會有一個偏向鎖,其實就是儲存了持有該同步鎖的執行緒 id,關於偏向鎖的知識這裡就不再贅述了,大家可以自行查閱相關資料。**
- **CMS promoted object 和 CMS free block 我也不清楚到底是啥,但是看名字似乎跟CMS 垃圾回收器有關,這裡我們也可以暫時忽略它們**
我們主要關注 normal object, 這種型別的 Object 的 Markword 一共是 8 個位元組(64位),其中 25 位暫時沒有使用,31 位儲存物件的 hash 值(注意這裡儲存的 hash 值對根據物件地址算出來的 hash 值,不是重寫 hashcode 方法裡面的返回值),中間有 1 位沒有使用,還有 4 位儲存物件的 age(分代回收中物件的年齡,超過 15 晉升入老年代),最後三位表示偏向鎖標識和鎖標識,主要就是用來區分物件的鎖狀態(未鎖定,偏向鎖,輕量級鎖,重量級鎖)
biased object 的物件頭 Markword 前 54 位來儲存持有該鎖的執行緒 id,這樣就沒有空間儲存 hashcode了,所以 **對於沒有重寫 hashcode 的物件,如果 hashcode 被計算過並存儲在物件頭中,則該物件作為同步鎖時,不會進入偏向鎖狀態,因為已經沒地方存偏向 thread id 了,所以我們在選擇同步鎖物件時,最好重寫該物件的 hashcode 方法,使偏向鎖能夠生效。**
我們來 new 一個空物件:
```java
class ObjA {
}
```
理論上一個空物件佔用記憶體大小隻有物件頭資訊,物件頭佔 12 個位元組。那麼 ObjA.class 應該佔用的儲存空間就是 12 位元組,考慮到 8 位元組的對齊填充,那麼會補上 4 位元組填充到 8 的 2倍,總共就是 16位元組。怎麼驗證我們的結論呢?JDK 提供了一個工具,JOL 全稱為 Java Object Layout,是分析 JVM 中物件佈局的工具,該工具大量使用了 Unsafe、JVMTI 來解碼佈局情況。下面我們就使用這個工具來獲取一個 Java 物件的大小。
首先引入 Maven 依賴:
```xml
org.openjdk.jol 0.14
```
我們來看使用:
```java
package com.trace.agent;
import org.openjdk.jol.info.ClassLayout;
import java.util.List;
/**
* @author rickiyang
* @date 2020-12-27
* @Desc TODO
*/
public class ObjSiZeTest {
public static void main(String[] args) {
ClassLayout classLayout = ClassLayout.parseInstance(new ObjA());
System.out.println(classLayout.toPrintable());
}
}
class ObjA {
}
```
輸出:
```java
com.trace.agent.ObjA object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 43 c1 00 f8 (01000011 11000001 00000000 11111000) (-134168253)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
```
從上面的結果能看到物件頭是 12 個位元組,還有 4 個位元組的 padding,一共 16 個位元組。我們的推測結果沒有錯。
接著看另一個案例:
```java
package com.trace.agent;
import org.openjdk.jol.info.ClassLayout;
/**
* @author rickiyang
* @date 2020-12-27
* @Desc TODO
*/
public class ObjSiZeTest {
public static void main(String[] args) {
ClassLayout classLayout = ClassLayout.parseInstance(new ObjA());
System.out.println(classLayout.toPrintable());
}
}
class ObjA {
private int i;
private double d;
private Integer io;
}
```
一共三個屬性:
int 型別佔 4 個位元組 ,double 型別佔 8 個位元組,Integer 是引用型別,64 位系統佔 4 個位元組。一共 16 個位元組。
加上物件頭 12 位元組,顯然不夠 8 的倍數,所以還得 4 位元組的填充,加起來就是 32 位元組
接著使用 JOL 來分析一下:
```java
com.trace.agent.ObjA object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 43 c1 00 f8 (01000011 11000001 00000000 11111000) (-134168253)
12 4 int ObjA.i 0
16 8 double ObjA.d 0.0
24 4 java.lang.Integer ObjA.io null
28 4 (loss due to the next object alignment)
Instance size: 32 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
```
一共 32 位元組。
