
你說一下Redis為什麼快吧,怎麼實現高可用,還有持久化怎麼做的?
阿新 • • 發佈:2020-12-30
## 前言
作為Java程式設計師,在面試過程中,快取相關的問題是躲不掉的,肯定會問,例如快取一致性問題,快取雪崩、擊穿、穿透等。說到快取,那肯定少不了Redis,我在面試的時候也是被問了很多關於Redis相關的知識,但是Redis的功能太強大了,並不是一時半會兒能掌握好的,因為有些高階特性或是知識平時並不會用到。
所以回答的不好,人家就會覺得你對自己平時使用的工具都沒有了解,自然就涼涼了。其實很早就有這個打算,打算好好總結一下Redis的知識,但也是由於自己都沒有好好的瞭解Redis呢,所以一直沒有開始。這次準備慢慢的來總結。
## Redis為什麼這麼快
Redis是一個由C語言編寫的開源的,基於記憶體,支援多種資料結構可持久化的NoSQL資料庫。
它速度快主要是有以下幾個原因:
- **基於記憶體執行,效能高效;**
- **資料結構設計高效,例如String是由動態字元陣列構成,zset內部的跳錶;**
- **採用單執行緒,避免了執行緒的上下文切換,也避免了執行緒競爭產生的死鎖等問題;**
- **使用I/O多路複用模型,非阻塞IO;**
官網上給出單臺Redis的可以達到10w+的QPS的, 一臺伺服器上在使用Redis的時候單核的就夠了,但是目前伺服器都是多核CPU,要想不浪費資源,又能提交效率,可以在一臺伺服器上部署多個Redis例項。
## 高可用方案
雖然單臺Redis的的效能很好,但是Redis的單節點並不能保證它不會掛了啊,畢竟單節點的Redis是有上限的,而且人家單節點又要讀又要寫,小身板扛不住咋辦,所以為了保證高可用,一般都是做成叢集。
### 主從(Master-Slave)
Redis官方是支援主從同步的,而且還支援從從同步,從從同步也可以理解為主從同步,只不過從從同步的主節點是另一個主從的從節點。
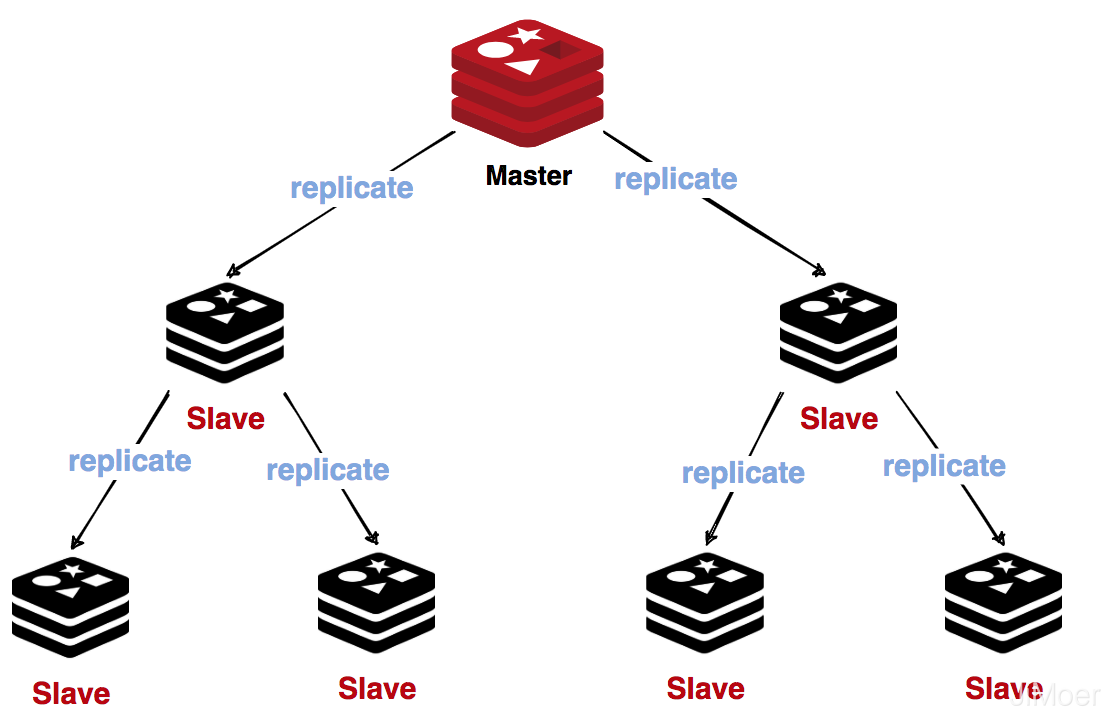
有了主從同步的叢集,那麼主節點就負責提供寫操作,而從節點就負責支援讀操作。
#### 那麼他們之間是如何進行資料同步的呢?
如果Slave(從節點)是第一次跟Master進行連線,
- **那麼會首先會向Master傳送同步請求`psync`;**
- **主節點接收到同步請求,開始fork主子程序開始進行全量同步,然後生成RDB檔案;**
- **這個時候主節點同時會將新的寫請求,儲存到快取區(buffer)中;**
- **從節點接收到RDB檔案後,先清空老資料,然後將RDB中資料載入到記憶體中;**
- **等到從節點將RDB檔案同步完成後再同步快取區中的寫請求。**
這裡有一點需要注意的就是,主節點的快取區是有限的,內部結構是一個環形陣列,當陣列被佔滿之後就會覆蓋掉最早之前的資料。
所以如果由於網路或是其他原因,造成快取區中的資料被覆蓋了,那麼當從節點處理完主節點的RDB檔案後,就不得不又要進行一全量的RDB檔案的複製,才能保證主從節點的資料一致。
如果不設定好合理的buffer區空間,是會造成一個RDB複製的死迴圈。
**當主從間的資料同步完成之後,後面主節點的每次寫操作就都會同步到從節點,這樣進行增量同步了。**
由於負載的不斷上升就導致了主從之間的延時變大,所以就有了上面我說的從從同步了,主節點先同步到一部分從節點,然後由從節點去同步其他的從節點。
>在Redis從2.8.18開始支援無盤複製,主節點通過套接字,一邊遍歷記憶體中的資料,一邊讓資料傳送給從節點,從節點和之前一樣,先將資料儲存在磁碟檔案中,然後再一次性載入。
>另外由於主從同步是非同步的,所以從Redis3.0之後出現了同步複製,就是通過wait命令來進行控制,wait命令有兩個引數,第一個是從庫數量,第二個是等待從庫的複製時間,如果第二個引數設定為0,那麼就是代表要等待所有從庫都複製完才去執行後面的命令。
但是這樣就會存在一個隱患,當網路異常後,wait命令會一直阻塞下去,導致Redis不可用。
### 哨兵(Sentinel)
哨兵可以監控Redis叢集的健康狀態,當主節點掛掉之後,選舉出新的主節點。客戶端在使用Redis的時候會先通過Sentinel來獲取主節點地址,然後再通過主節點來進行資料互動。當主節點掛掉之後,客戶端會再次向Sentinel獲取主節點,這樣客戶端就可以無感知的繼續使用了。
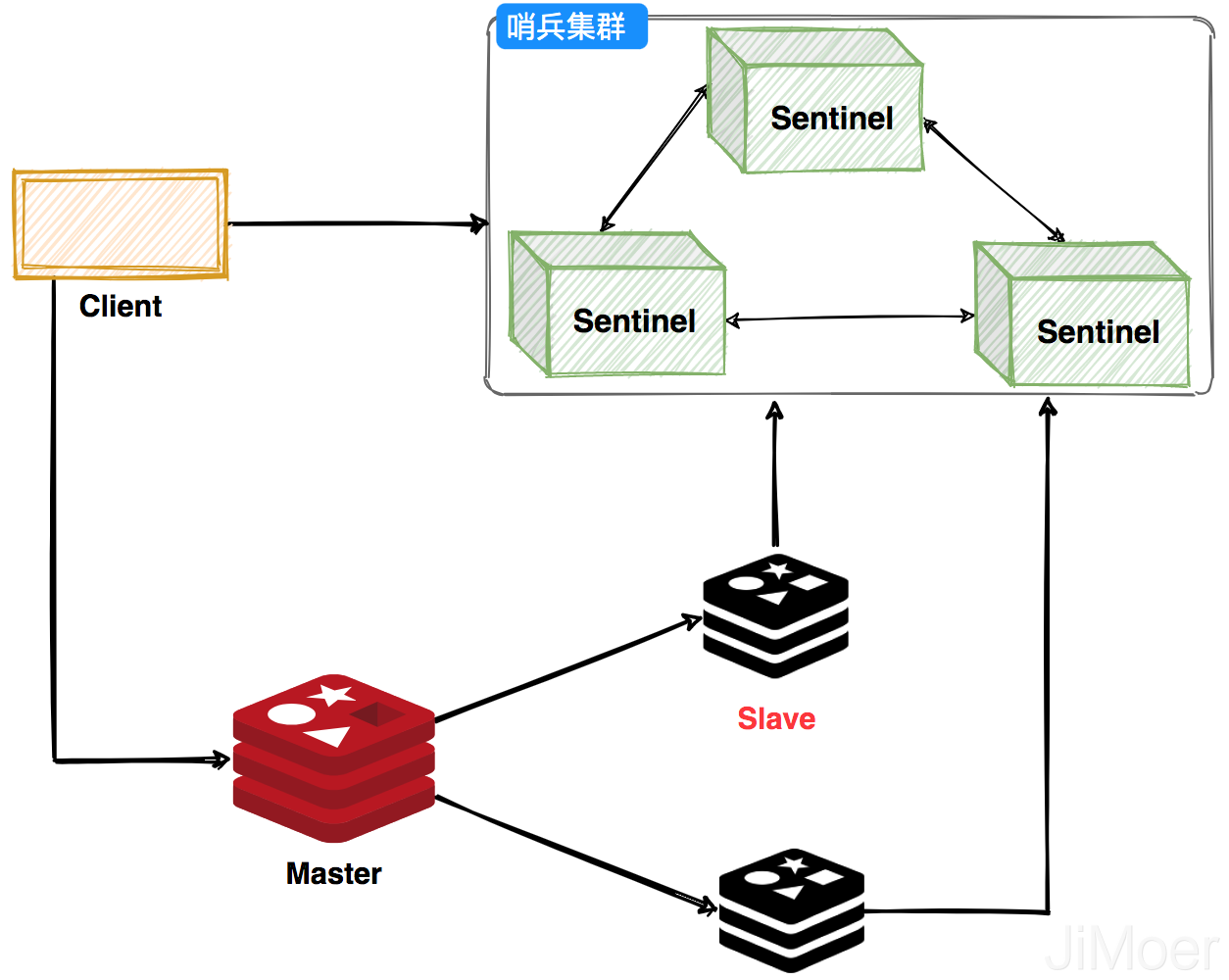
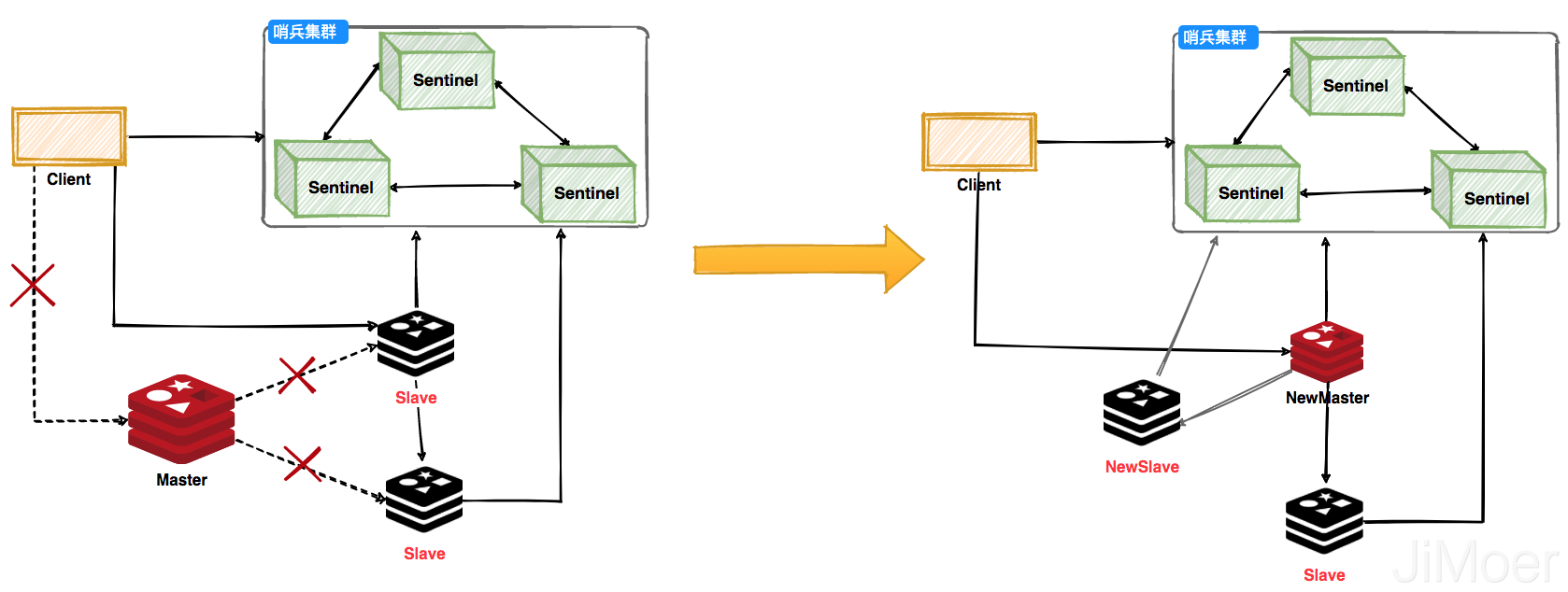
**哨兵叢集工作過程,主節點掛掉之後會選舉出新的主節點,然後監控掛掉的節點,當掛掉的節點恢復後,原先的主節點就會變成從節點,從新的主節點那裡建立主從關係。**
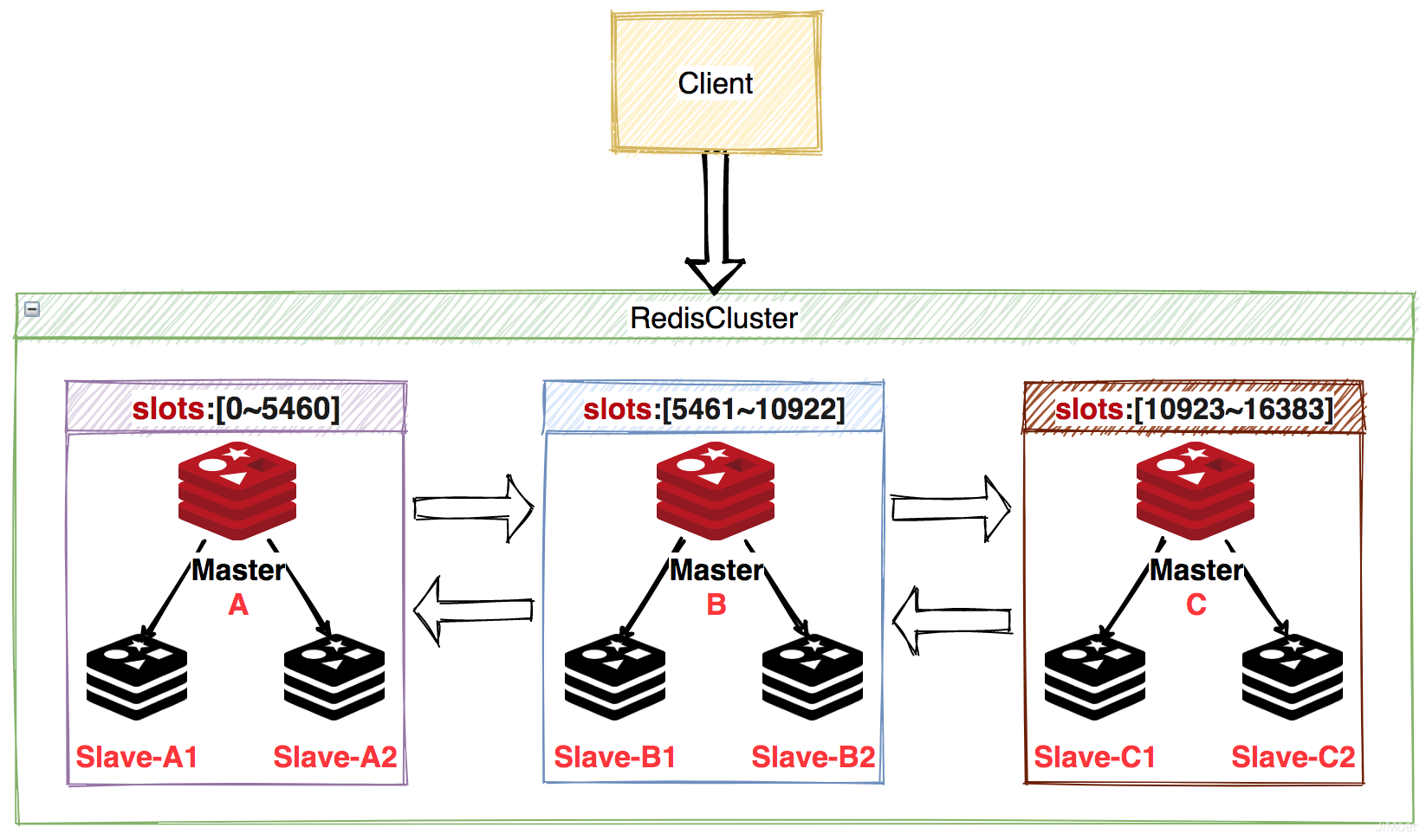
### 叢集分片(Redis Cluster)
Redis Cluster是Redis官方推薦的叢集模式,Redis Cluster將所有資料劃分到16384個槽(`slots`)中,每個節點負責一部分槽位的讀寫操作。
#### 儲存
Redis Cluster預設是通過CRC16演算法獲取到key的hash值,然後再對16384進行取餘(`CRC16(key)%16384`),獲取到的槽位在哪個節點負責的範圍內(**這裡一般是會有一個槽位和節點的對映表來進行快速定位節點的,通常使用bitmap來實現**),就儲存在哪個節點上。
#### 重定向
當Redis Cluster的客戶端在和叢集建立連線的時候,也會獲得一份槽位和節點的配置關係(**槽位和節點的對映表**),這樣當客戶端要查詢某個key時,可以直接定位到目標節點。
但是當客戶端傳送請求時,如果接收請求的節點發現該資料的槽位並不在當前節點上,那麼會返回`MOVED`指令將正確的槽位和節點資訊返回給客戶端,客戶接著請求正確的節點獲取資料。
一般客戶端在接收到`MOVED`指令後,也會更新自己本地的槽位和節點的對映表,這樣下次獲取資料時就可以直接命中了。這整個重定向的過程對客戶端是透明的。
#### 資料遷移
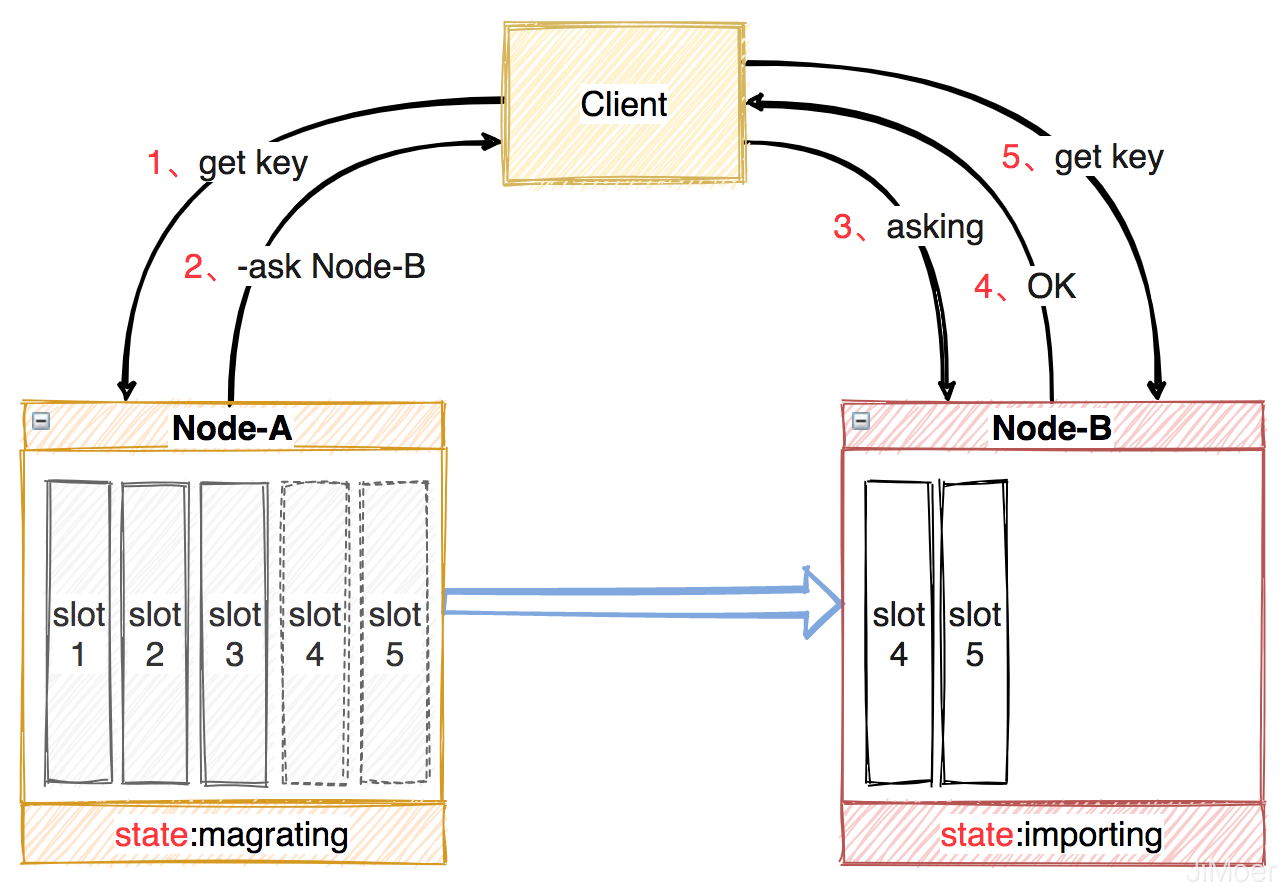
當叢集中新增節點或刪除節點後,節點間的資料遷移是按槽位為單位的,一個槽位一個槽位的遷移,當遷移時原節點狀態處於:`magrating`,目標節點處於:`importing`。
在遷移過程中,客戶端首先訪問舊節點,如果資料還在舊節點,那麼舊節點正常處理,如果不在舊節點,就會返回一個`-ASK + 目標節點地址`的指令,客戶端收到這個`-ASK`指令後,向目標節點執行一個`asking`指令(告訴新節點,必須處理客戶端這個資料),然後再向目標節點執行客戶端的訪問資料的指令。
#### 容錯
Redis Cluster可以為每個主節點設定多個從節點,當單個主節點掛掉後,叢集會自動將其中某個從節點提升為主節點,若沒有從節點,那麼叢集將處於不可用狀態。
Redis提供了一個引數:`cluster-require-full-coverage`,用來配置可以允許部分節點出問題後,還有其他節點在執行時可以正常提供服務。
另外一點比較特殊的是,Cluster中當一個節點發現某個其他節點出現失聯了,這個時候問題節點只是`PFail`(`Possibly`-可能下線),然後它會把這個失聯資訊廣播給其他節點,當一個節點接收到某個節點的失聯資訊達到叢集的大多數時,就可以將失聯節點標記為下線,然後將下線資訊廣播給其他節點。若失聯節點為主節點,那麼將立即對該節點進行主從切換。
>**Redis高可用就先說到這裡吧,後面其實還有Codis,但是目前Cluster逐漸流行起來了,Codis的競爭力逐漸被蠶食,而且對新版本的支援,更新的也比較慢,所以這裡就不說它了,感興趣的可以自己去了解一下,國人開源的Redis叢集模式Codis。**
## 持久化
Redis持久化的意義在於,當出現宕機問題後,能將資料恢復到快取中,它提供了兩種持久化機制:**一種是快照(RDB),一種是AOF日誌。**
快照是一次全量備份,而AOF是增量備份。快照是記憶體資料的二進位制序列化形式,儲存上非常緊湊,而AOF日誌記錄的是記憶體資料修改的指令記錄文字。
### 快照備份(RDB)
因為Redis是單執行緒的,所以在做快照持久化的時候,通常有兩個選擇,**save命令,會阻塞執行緒,直到備份完成**;bgsave會非同步的執行備份,其實是fork出了一個子程序,用子程序去執行快照持久化操作,將資料儲存在一個.rdb檔案中。
子程序剛剛產生的時候,是和父程序共享記憶體中的資料的,但是子程序做持久化時,是不會修改資料的,而父程序是要持續提供服務的,所以父程序就會持續的修改記憶體中的資料,這個時候父程序就會將記憶體中的資料,Copy出一份來進行修改。
父程序copy的資料是以資料頁為單位的(4k一頁),對那一頁資料進行修改就copy哪一頁的資料。
子程序由於資料沒有變化就會一直的去遍歷資料,程序持久化操作了,這就是隻保留了建立子程序的時候的快照。
那麼RDB是在什麼時候觸發的呢?
```bash
# save
save 60 10000
save 300 10
```
上這段配置就是在redis.conf檔案中配置的,第一個引數是時間單位是秒,第二個引數執行資料變化的次數。
意思就是說:**300秒之內至少發生10次寫操作、
60秒之內發生至少10000次寫操作,只要滿足任一條件,均會觸發bgsave**
### 增量日誌備份(AOF)
Redis在接收到客戶端請求指令後,會先進行校驗,校驗成功後,立即將指令儲存到AOF日誌檔案中,就是說,Redis是先記錄日誌,再執行命令。這樣即使命令還沒執行突然宕機了,通過AOF日誌檔案也是可以恢復的。
#### AOF重寫
AOF日誌檔案,隨著時間的推移,會越來越大,所以就需要進行重寫瘦身。AOF重寫的原理就是,**fork一個子程序,對記憶體進行遍歷,然後生成一系列的Redis指令,然後序列化到一個新的aof檔案中。然後再將遍歷記憶體階段的增量日誌,追加到新的aof檔案中,追加完成後立即替換舊的aof檔案,這樣就完成了AOF的瘦身重寫**。
#### fsync
因為AOF是一個寫檔案的IO操作,是比較耗時。所以AOF日誌並不是直接寫入到日誌檔案的,而是先寫到一個核心的快取中,然後通過非同步刷髒,來將資料儲存到磁碟的。
由於這個情況,就導致了會有還沒來得急刷髒然後就宕機了,導致資料丟失的風險。
所以Redis提供了一個配置,可以手動的來選擇刷髒的頻率。
- ==**always**==:每一條AOF記錄都立即同步到檔案,效能很低,但較為安全。
- ==**everysec**==:**每秒同步一次,效能和安全都比較中庸的方式,也是redis推薦的方式。如果遇到物理伺服器故障,可能導致最多1秒的AOF記錄丟失。**
- ==**no**==:Redis永不直接呼叫檔案同步,而是讓作業系統來決定何時同步磁碟。效能較好,但很不安全。
AOF預設是關閉的,需要在配置檔案中手動開啟。
```bash
# 只有在“yes”下,aof重寫/檔案同步等特性才會生效
appendonly yes
## 指定aof檔名稱
appendfilename appendonly.aof
## 指定aof操作中檔案同步策略,有三個合法值:always everysec no,預設為everysec
appendfsync everysec
## 在aof-rewrite期間,appendfsync是否暫緩檔案同步,"no"表示“不暫緩”,“yes”表示“暫緩”,預設為“no”
no-appendfsync-on-rewrite no
## aof檔案rewrite觸發的最小檔案尺寸(mb,gb),只有大於此aof檔案大於此尺寸是才會觸發rewrite,預設“64mb”,建議“512mb”
auto-aof-rewrite-min-size 64mb
```
### Redis4.0混合持久化
Redis4.0提供了一種新的持久化機制,就是RDB和AOF結合使用,將rdb檔案內容和aof檔案存在一起,AOF中儲存的不再是全部資料了,而是從RDB開始的到結束的增量日誌。
這樣在Redis恢復資料的時候,可以先假裝RDB檔案中的內容,然後在順序執行AOF日誌中指令,這樣就將Redis重啟時恢復資料的效率得到了大幅度提升。
## 結尾
恩,這次就先總結到這裡吧,後面會繼續總結Redis相關知識,LRU、LFU、記憶體淘汰策略,管道