
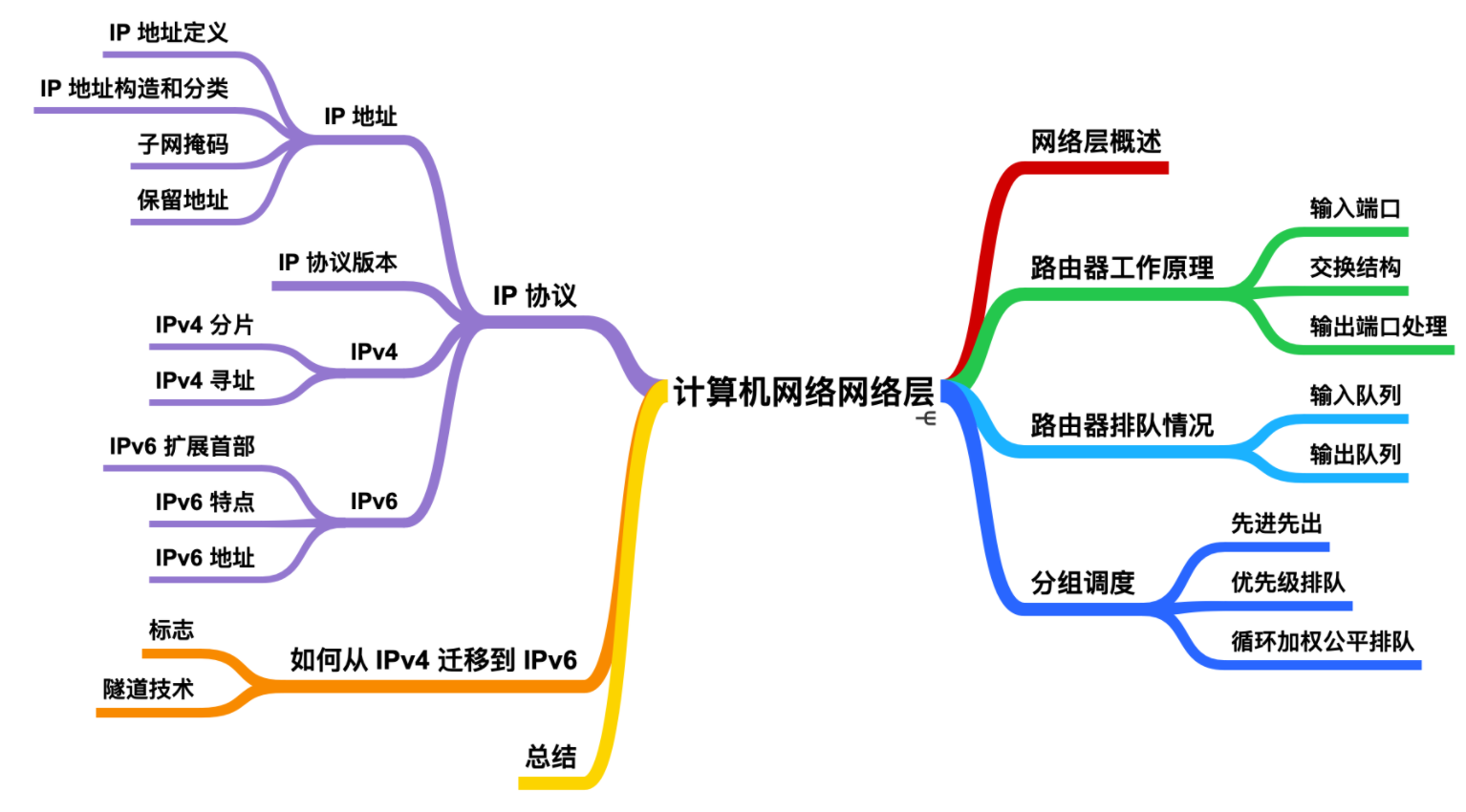
我畫了 40 張圖就是為了讓你搞懂計算機網路層
阿新 • • 發佈:2021-01-04
> 我把自己以往的文章彙總成為了 Github ,歡迎各位大佬 star
> https://github.com/crisxuan/bestJavaer
前面我們學習了運輸層如何為客戶端和伺服器輸送資料的,提供程序端到端的通訊。那麼下面我們將學習網路層實際上是怎樣實現主機到主機的通訊服務的。**幾乎每個端系統都有網路層這一部分**。所以,網路層必然是很複雜的。下面我將花費大量篇幅來介紹一下計算機網路層的知識。
## 網路層概述
網路層是 OSI 參考模型的第三層,它位於傳輸層和鏈路層之間,網路層的主要目的是實現兩個端系統之間透明的資料傳輸。

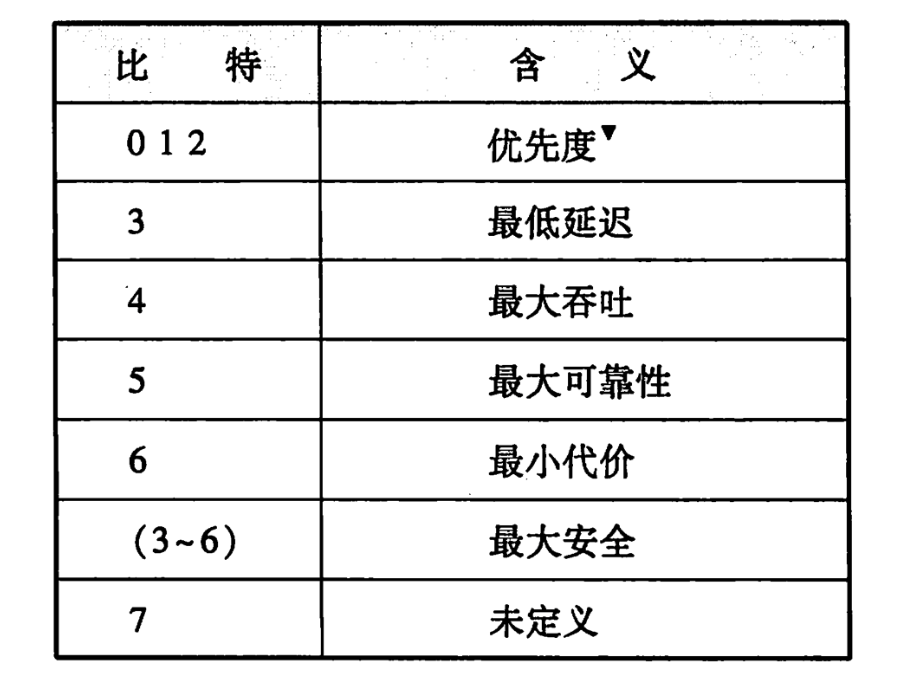 * `擁塞通告(Explicit Congestion Notification,ECN)` 佔用 2 bit,它允許在不丟棄報文的同時通知對方網路擁塞的發生。ECN 是一種可選的功能,僅當兩端都支援並希望使用,且底層網路支援時才被使用。 最開始 DSCP 和 ECN 統稱為 TOS,也就是區分服務,但是後來被細化為了 DSCP 和 ECN。
* `資料報長度(Total Length)` 佔用 16 bit,這 16 位是包括在資料在內的總長度,理論上資料報的總長度為 2 的 16 次冪 - 1,最大長度是 65535 位元組,但是實際上資料報很少有超過 1500 位元組的。IP 規定所有主機都必須支援最小 576 位元組的報文,但大多數現代主機支援更大的報文。當下層的資料鏈路協議的`最大傳輸單元(MTU)`欄位的值小於 IP 報文長度時,報文就必須被分片。
* `識別符號(Identification)` 佔用 16 bit,這個欄位用來標識所有的分片,因為分片不一定會按序到達,所以到達目標主機的所有分片會進行重組,每產生一個數據報,計數器加1,並賦值給此欄位。
* `標誌(Flags)` 佔用 3 bit,標誌用於控制和識別分片,這 3 位分別是
* 0 位:保留,必須為0;
* 1 位:`禁止分片(Don’t Fragment,DF)`,當 DF = 0 時才允許分片;
* 2 位:`更多分片(More Fragment,MF)`,MF = 1 代表後面還有分片,MF = 0 代表已經是最後一個分片。
如果 DF 標誌被設定為 1 ,但是路由要求必須進行分片,那麼這條資料報回丟棄
* `分片偏移(Fragment Offset)` 佔用 13 位,它指明瞭每個分片相對於原始報文開頭的偏移量,以 8 位元組作單位。
* `存活時間(Time To Live,TTL)` 佔用 8 位,存活時間避免報文在網際網路中`迷失`,比如陷入路由環路。存活時間以秒為單位,但小於一秒的時間均向上取整到一秒。在現實中,這實際上成了一個跳數計數器:報文經過的每個路由器都將此欄位減 1,當此欄位等於 0 時,報文不再向下一跳傳送並被丟棄,這個欄位最大值是 255。
* `協議(Protocol)` 佔用 8 位,這個欄位定義了報文資料區使用的協議。協議內容可以在 https://www.iana.org/assignments/protocol-numbers/protocol-numbers.xhtml 官網上獲取。
* `首部校驗和(Header Checksum)` 佔用 16 位,首部校驗和會對欄位進行糾錯檢查,在每一跳中,路由器都要重新計算出的首部檢驗和並與此欄位進行比對,如果不一致,此報文將會被丟棄。
* `源地址(Source address)` 佔用 32 位,它是 IPv4 地址的構成條件,源地址指的是資料報的傳送方
* `目的地址(Destination address)`佔用 32 位,它是 IPv4 地址的構成條件,目標地址指的是資料報的接收方
* `選項(Options)` 是附加欄位,選項欄位佔用 1 - 40 個位元組不等,一般會跟在目的地址之後。如果首部長度 > 5,就應該考慮選項欄位。
* `資料` 不是首部的一部分,因此並不被包含在首部檢驗和中。
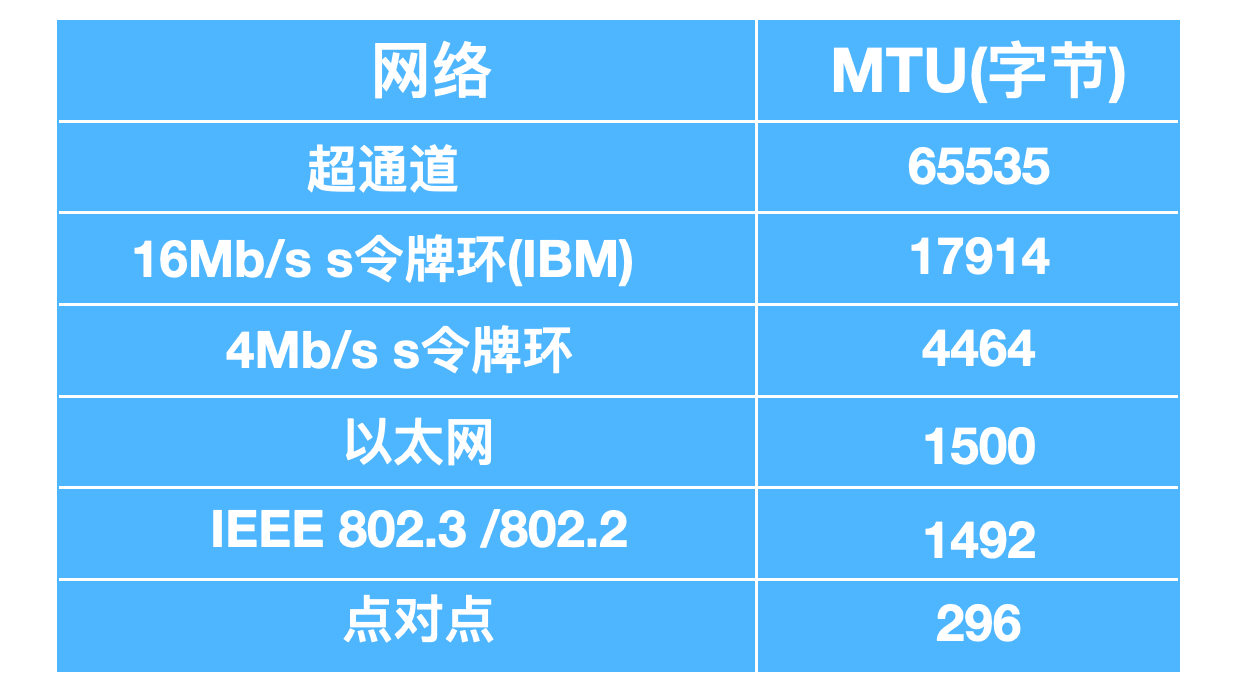
在 IP 傳送的過程中,每個資料報的大小是不同的,每個鏈路層協議能承載的網路層分組也不一樣,有的協議能夠承載大資料報,有的卻只能承載很小的資料報,不同的鏈路層能夠承載的資料報大小如下。
#### IPv4 分片
一個鏈路層幀能承載的最大資料量叫做`最大傳輸單元(Maximum Transmission Unit, MTU)`,每個 IP 資料報封裝在鏈路層幀中從一臺路由器傳到下一臺路由器。因為每個鏈路層所支援的最大 MTU 不一樣,當資料報的大小超過 MTU 後,會在鏈路層進行分片,每個資料報會在鏈路層單獨封裝,每個較小的片都被稱為 `片(fragement)`。
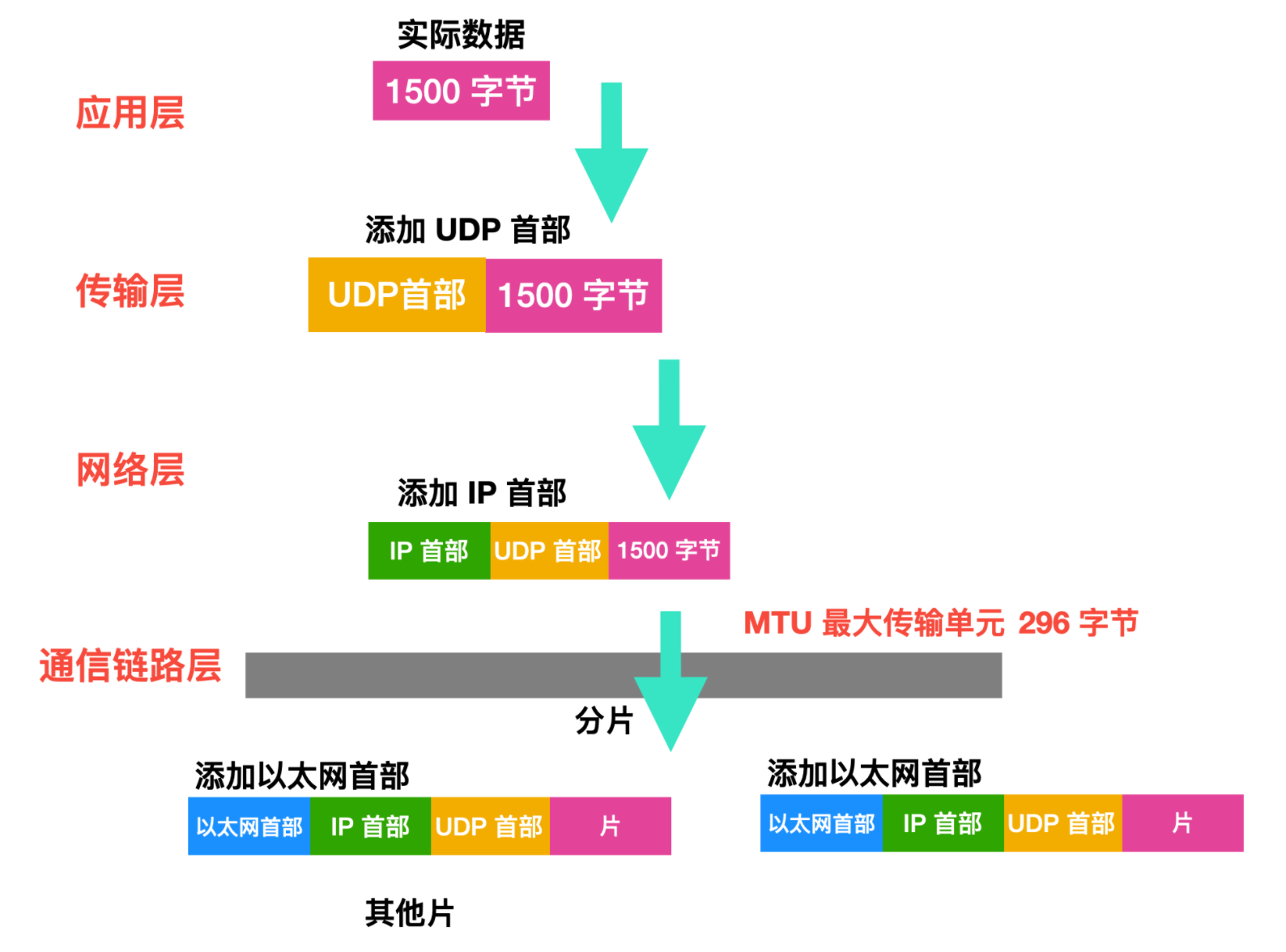
每個片在到達目的地後會進行重組,準確的來說是在運輸層之前會進行重組,TCP 和 UDP 都會希望傳送完整的、未分片的報文,出於效能的原因,分片重組不會在路由器中進行,而是會在目標主機中進行重組。
當目標主機收到從傳送端傳送過來的資料報後,它需要確定這些資料報中的分片是否是由源資料報分片傳遞過來的,如果是的話,還需要確定何時收到了分片中的`最後一片`,並且這些片會如何拼接一起成為資料報。
針對這些潛在的問題,IPv4 設計者將 **標識、標誌和片偏移**放在 IP 資料報首部中。當生成一個數據報時,傳送主機會為該資料報設定源和目的地址的同時貼上`標識號`。傳送主機通常將它傳送的每個資料報的標識 + 1。當某路由器需要對一個數據報分片時,形成的每個資料報具有初始資料報的**源地址、目標地址和標識號**。當目的地從同一傳送主機收到一系列資料報時,它能夠檢查資料報的標識號以確定哪些資料是由源資料報傳送過來的。由於 IP 是一種不可靠的服務,分片可能會在網路中丟失,鑑於這種情況,通常會把分片的最後一個位元設定為 0 ,其他分片設定為 1,同時使用偏移欄位指定分片應該在資料報的哪個位置。
#### IPv4 定址
IPv4 支援三種不同型別的定址模式,分別是
* 單播定址模式:在這種模式下,資料只發送到一個目的地的主機。
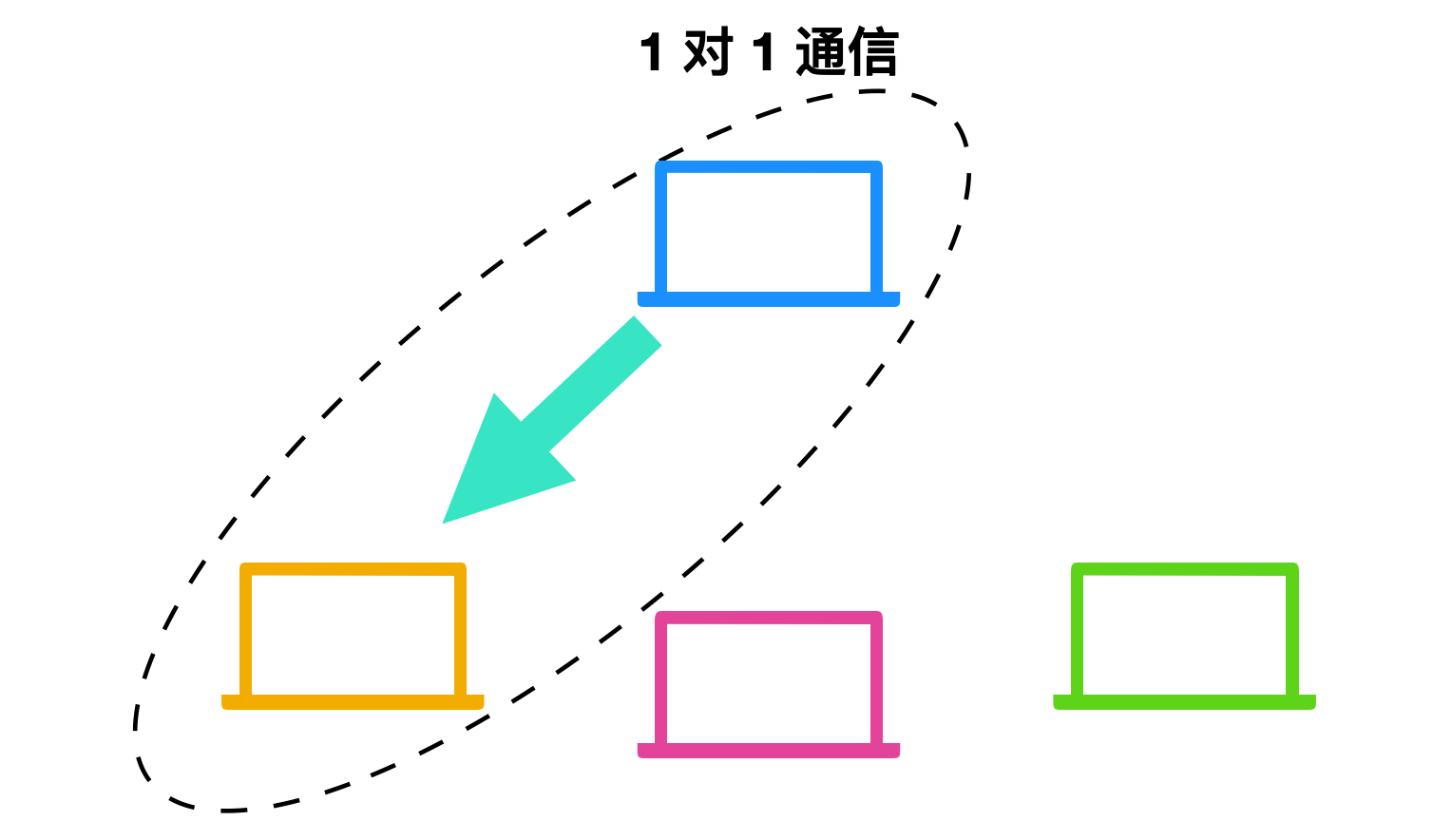
* 廣播定址模式:在此模式下,資料包將被定址到網段中的所有主機。這裡客戶端傳送一個數據包,由所有伺服器接收:
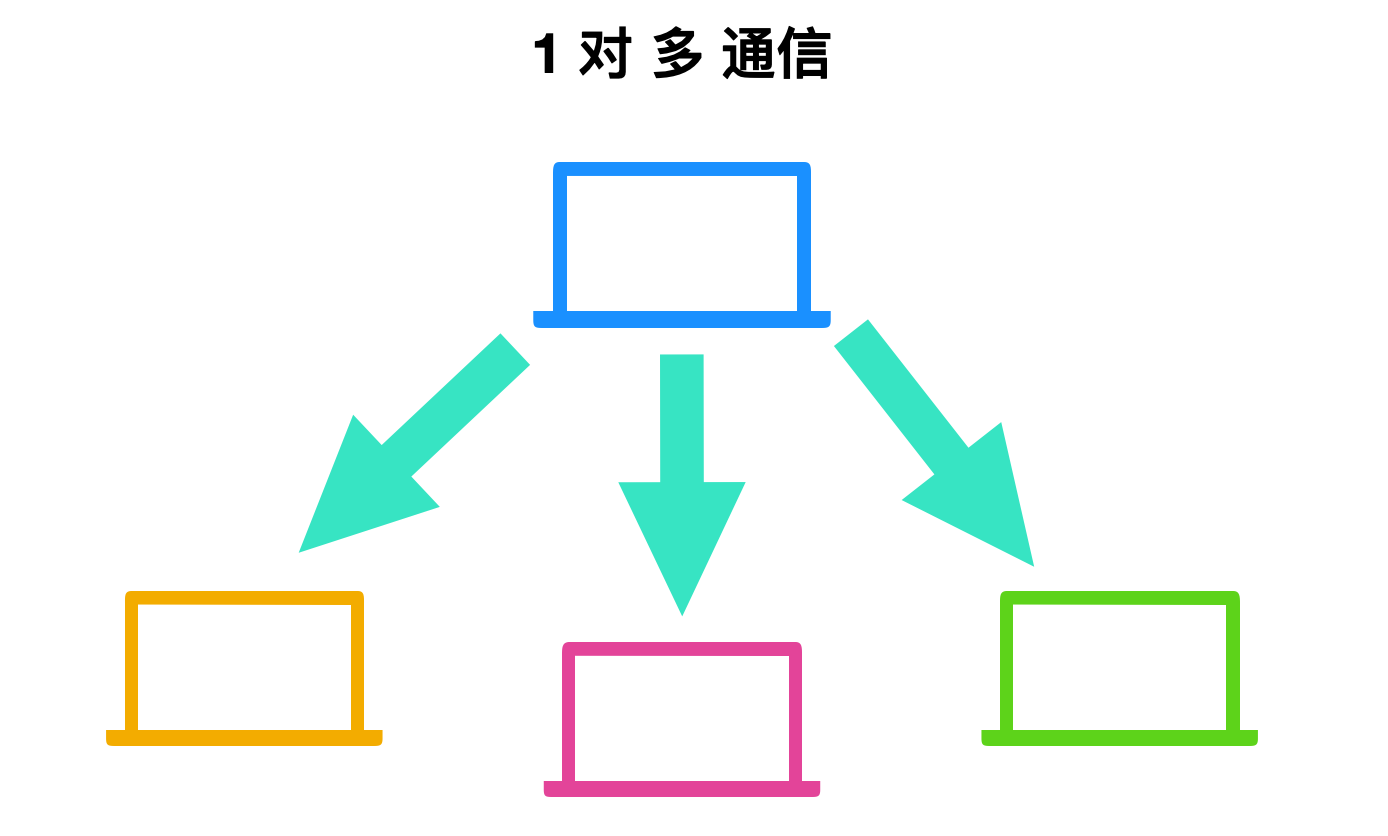
* 組播定址模式:此模式是前兩種模式的混合,即傳送的資料包既不指向單個主機也不指定段上的所有主機
### IPv6
隨著端系統接入的越來越多,IPv4 已經無法滿足分配了,所以,IPv6 應運而生,IPv6 就是為了解決 IPv4 的地址耗盡問題而被標準化的網際協議。IPv4 的地址長度為 4 個 8 位元組,即 32 位元, 而 IPv6 的地址長度是原來的四倍,也就是 128 位元,一般寫成 8 個 16 位位元組。
從 IPv4 切換到 IPv6 及其耗時,需要將網路中所有的主機和路由器的 IP 地址進行設定,在網際網路不斷普及的今天,替換所有的 IP 是一個工作量及其龐大的任務。我們後面會說。
我們先來看一下 IPv6 的地址是怎樣的
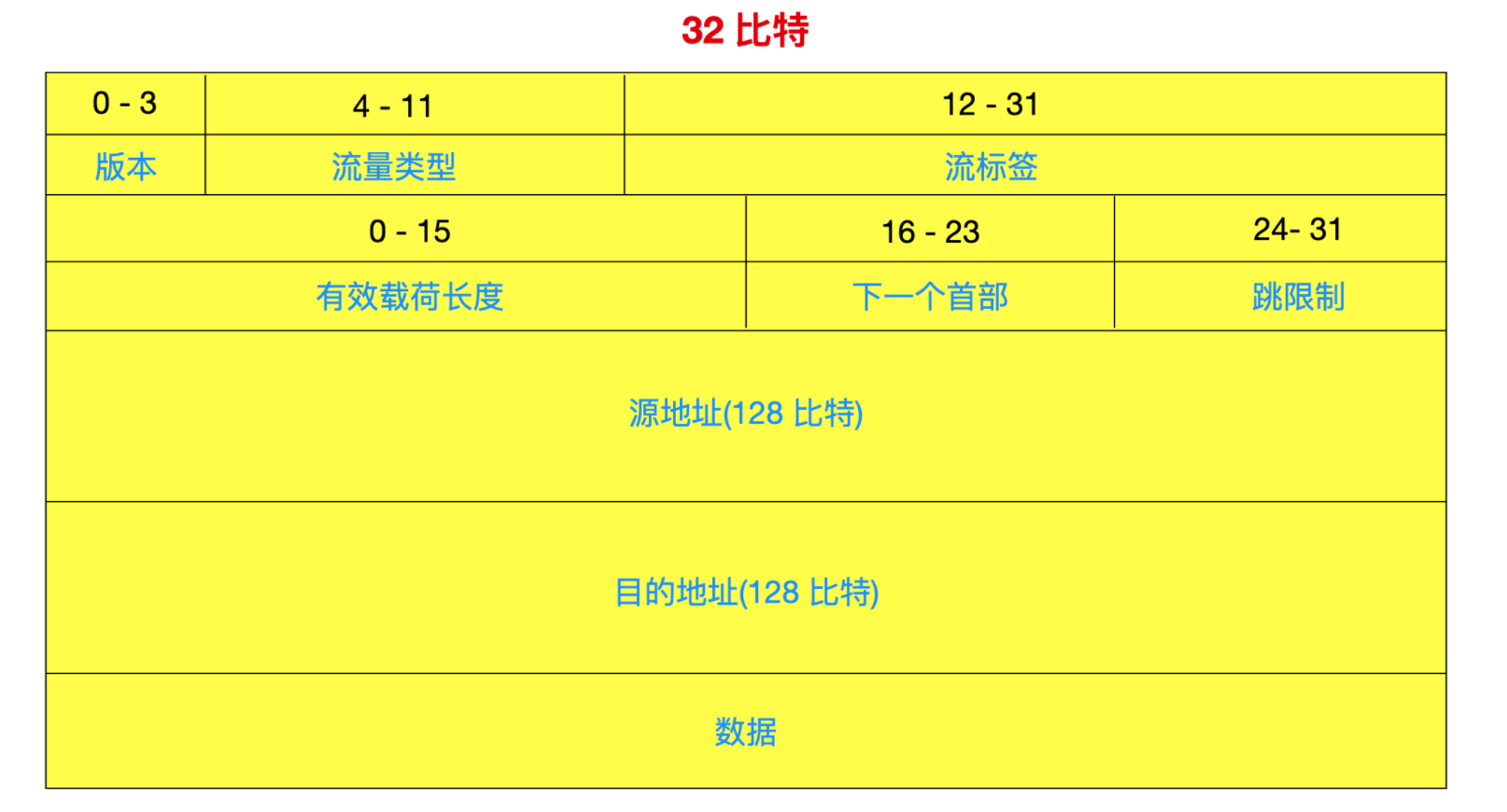
* `版本`與 IPv4 一樣,版本號由 4 bit 構成,IPv6 版本號的值為 6。
* `流量型別(Traffic Class)` 佔用 8 bit,它就相當於 IPv4 中的服務型別(Type Of Service)。
* `流標籤(Flow Label)` 佔用 20 bit,這 20 位元用於標識一條資料報的流,能夠對一條流中的某些資料報給出優先權,或者它能夠用來對來自某些應用的資料報給出更高的優先權,只有流標籤、源地址和目標地址一致時,才會被認為是一個流。
* `有效載荷長度(Payload Length)` 佔用 16 bit,這 16 位元值作為一個無符號整數,它給出了在 IPv6 資料報中跟在鼎昌 40 位元組資料報首部後面的位元組數量。
* `下一個首部(Next Header)` 佔用 8 bit,它用於標識資料報中的內容需要交付給哪個協議,是 TCP 協議還是 UDP 協議。
* `跳限制(Hop Limit)` 佔用 8 bit,這個欄位與 IPv4 的 TTL 意思相同。資料每經過一次路由就會減 1,減到 0 則會丟棄資料。
* `源地址(Source Address)` 佔用 128 bit (8 個 16 位 ),表示傳送端的 IP 地址。
* `目標地址(Destination Address)` 佔用 128 bit (8 個 16 位 ),表示接收端 IP 地址。
可以看到,相較於 IPv4 ,IPv6 取消了下面幾個欄位
* **識別符號、標誌和位元偏移**:IPv6 不允許在中間路由器上進行分片和重新組裝。這種操作只能在端系統上進行,IPv6 將這個功能放在端系統中,加快了網路中的轉發速度。
* **首部校驗和**:因為在運輸層和資料鏈路執行了報文段完整性校驗工作,IP 設計者大概覺得在網路層中有首部校驗和比較多餘,所以去掉了。**IP 更多專注的是快速處理分組資料**。
* **選項欄位**:選項欄位不再是標準 IP 首部的一部分了,但是它並沒有消失,而是可能出現在 IPv6 的擴充套件首部,也就是下一個首部中。
#### IPv6 擴充套件首部
IPv6 首部長度固定,無法將選項欄位加入其中,取而代之的是 IPv6 使用了`擴充套件首部`
擴充套件首部通常介於 IPv6 首部與 TCP/UDP 首部之間,在 IPv4 中可選長度固定為 40 位元組,在 IPv6 中沒有這樣的限制。IPv6 的擴充套件首部可以是任意長度。擴充套件首部中還可以包含擴充套件首部協議和下一個擴充套件欄位。
IPv6 首部中沒有標識和標誌欄位,**對 IP 進行分片時,需要使用到擴充套件首部**。
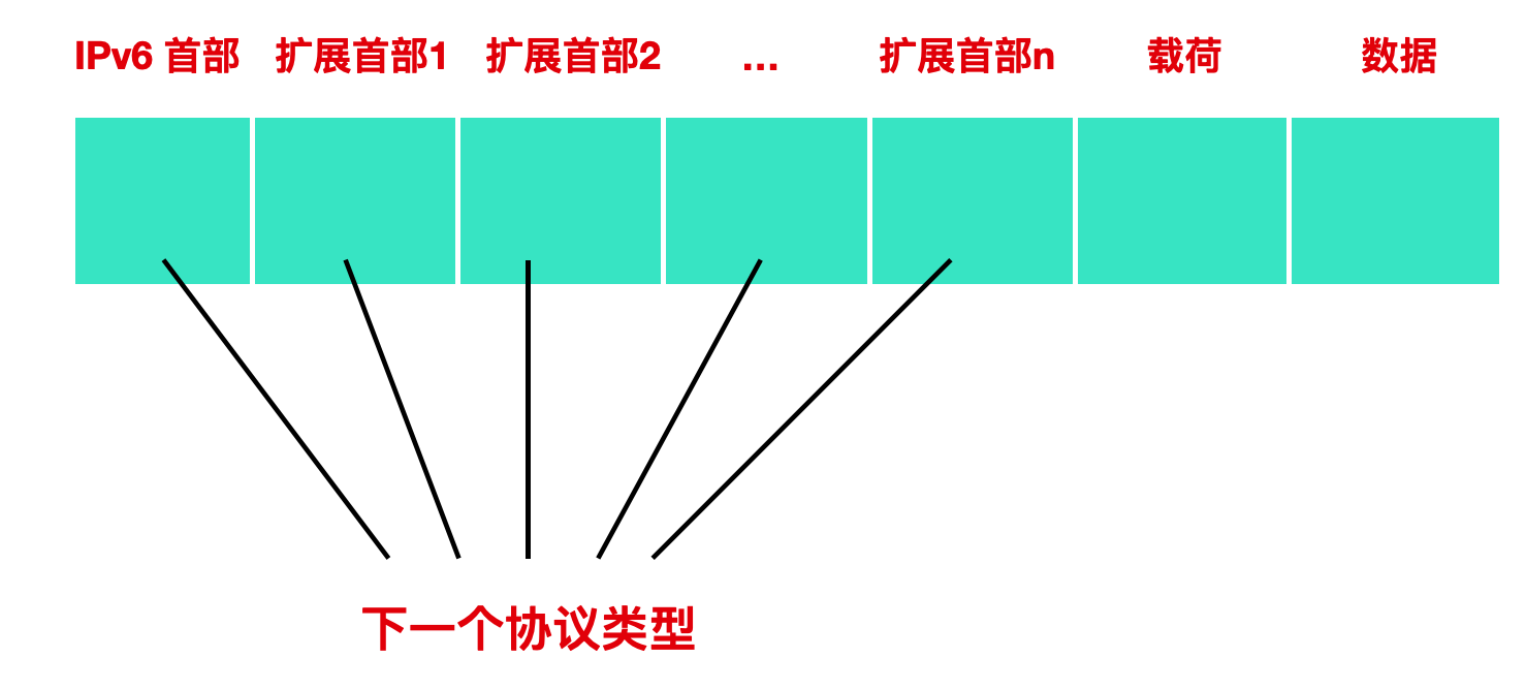
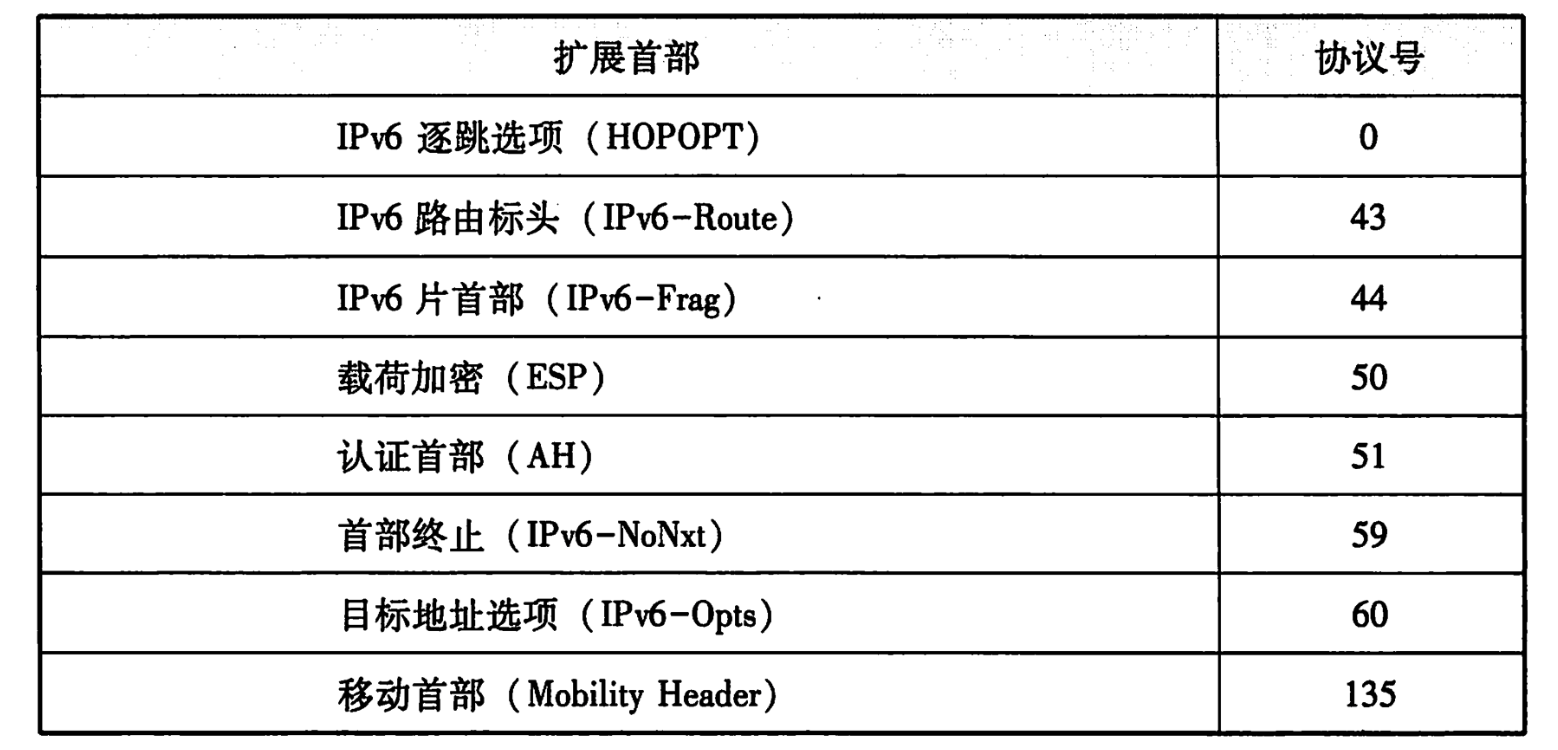
具體的擴充套件首部表如下所示
下面我們來看一下 IPv6 都有哪些特點
#### IPv6 特點
IPv6 的特點在 IPv4 中得以實現,但是即便實現了 IPv4 的作業系統,也未必實現了 IPv4 的所有功能。而 IPv6 卻將這些功能大眾化了,也就表明這些功能在 IPv6 已經進行了實現,這些功能主要有
* **地址空間變得更大**:這是 IPv6 最主要的一個特點,即支援更大的地址空間。
* **精簡報文結構**: IPv6 要比 IPv4 精簡很多,IPv4 的報文長度不固定,而且有一個不斷變化的選項欄位;IPv6 報文段固定,並且將選項欄位,分片的欄位移到了 IPv6 擴充套件頭中,這就極大的精簡了 IPv6 的報文結構。
* **實現了自動配置**:IPv6 支援其主機裝置的**狀態和無狀態**自動配置模式。這樣,沒有 `DHCP 伺服器`不會停止跨段通訊。
* **層次化的網路結構**: IPv6 不再像 IPv4 一樣按照 A、B、C等分類來劃分地址,而是通過 IANA -> RIR -> ISP 這樣的順序來分配的。IANA 是國際網際網路號碼分配機構,RIR 是區域網際網路註冊管理機構,ISP 是一些運營商(例如電信、移動、聯通)。
* **IPSec**:IPv6 的擴充套件報頭中有一個認證報頭、封裝安全淨載報頭,這兩個報頭是 IPsec 定義的。通過這兩個報頭網路層自己就可以實現端到端的安全,而無需像 IPv4 協議一樣需要其他協議的幫助。
* **支援任播**:IPv6 引入了一種新的定址方式,稱為任播定址。
#### IPv6 地址
我們知道,IPv6 地址長度為 128 位,他所能表示的範圍是 2 ^ 128 次冪,這個數字非常龐大,幾乎涵蓋了你能想到的所有主機和路由器,那麼 IPv6 該如何表示呢?
一般我們將 128 位元的 IP 地址以每 16 位元為一組,並用 `:` 號進行分隔,如果出現連續的 0 時還可以將 0 省略,並用 `::` 兩個冒號隔開,記住,一個 IP 地址只允許出現一次兩個連續的冒號。
下面是一些 IPv6 地址的示例
* 二進位制數表示

* 用十六進位制數表示

* 出現兩個冒號的情況
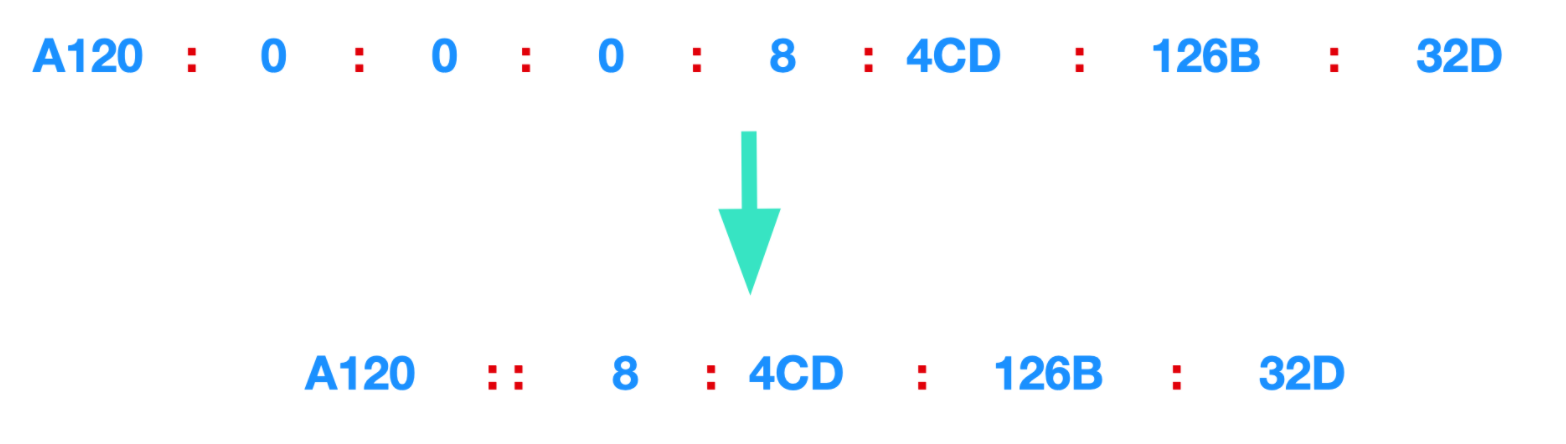
如上圖所示,A120 和 4CD 中間的 0 被 :: 所取代了。
## 如何從 IPv4 遷移到 IPv6
我們上面聊了聊 IPv4 和 IPv6 的報文格式、報文含義是什麼、以及 IPv4 和 IPv6 的特徵分別是什麼,看完上面的內容,你已經知道了 IPv4 現在馬上就變的不夠用了,而且隨著 IPv6 的不斷髮展和引用,雖然新型的 IPv6 可以做到`向後相容`,即 IPv6 可以收發 IPv4 的資料報,但是**已經部署的具有 IPv4 能力的系統卻不能夠處理 IPv6 資料報**。所以 IPv4 噬需遷移到 IPv6,遷移並不意味著將 IPv4 替換為 IPv6。這僅意味著同時啟用 IPv6 和 IPv4。
>那麼現在就有一個問題了,IPv4 如何遷移到 IPv6 呢?這就是我們接下來討論的重點。
### 標誌
最簡單的方式就是設定一個標誌日,指定某個時間點和日期,此時全球的因特網機器都會在這時關機從 IPv4 遷移到 IPv6 。上一次重大的技術遷移是在 35 年前,但是很顯然,不用我過多解釋,這種情況肯定是 `不行的`。影響不可估量不說,如何保證全球人類都能知道如何設定自己的 IPv6 地址?一個設計數十億臺機器的標誌日現在是想都不敢想的。
### 隧道技術
現在已經在實踐中使用的從 IPv4 遷移到 IPv6 的方法是 `隧道技術(tunneling)`。
>什麼是隧道技術呢?
隧道技術是一種使用網際網路絡的基礎設施在網路之間的傳輸資料的方式,使用隧道傳遞的資料可以是不同協議的資料幀或包。使用隧道技術所遵從的協議叫做`隧道協議(tunneling protocol)`。隧道協議會將這些協議的資料幀或包封裝在新的包頭中傳送。新的包頭提供了路由資訊,從而使封裝的負載資料能夠通過網際網路絡進行傳遞。
使用隧道技術一般都會建一個`隧道`,建隧道的依據如下:
比如兩個 IPv6 節點(下方 B、E)要使用 IPv6 資料報進行互動,但是它們是經由兩個 IPv4 的路由器進行互聯的。那麼我們就需要將 IPv6 節點和 IPv4 路由器組成一個隧道,如下圖所示

藉助於隧道,在隧道傳送端的 IPv6 節點可將整個 IPv6 資料報放到一個 IPv4 資料報的`資料(有效載荷)` 欄位中,於是,IPv4 資料報的地址被設定為指向隧道接收端的 IPv6 的節點,比如上面的 E 節點。然後再發送給隧道中的第一個節點 C,如下所示
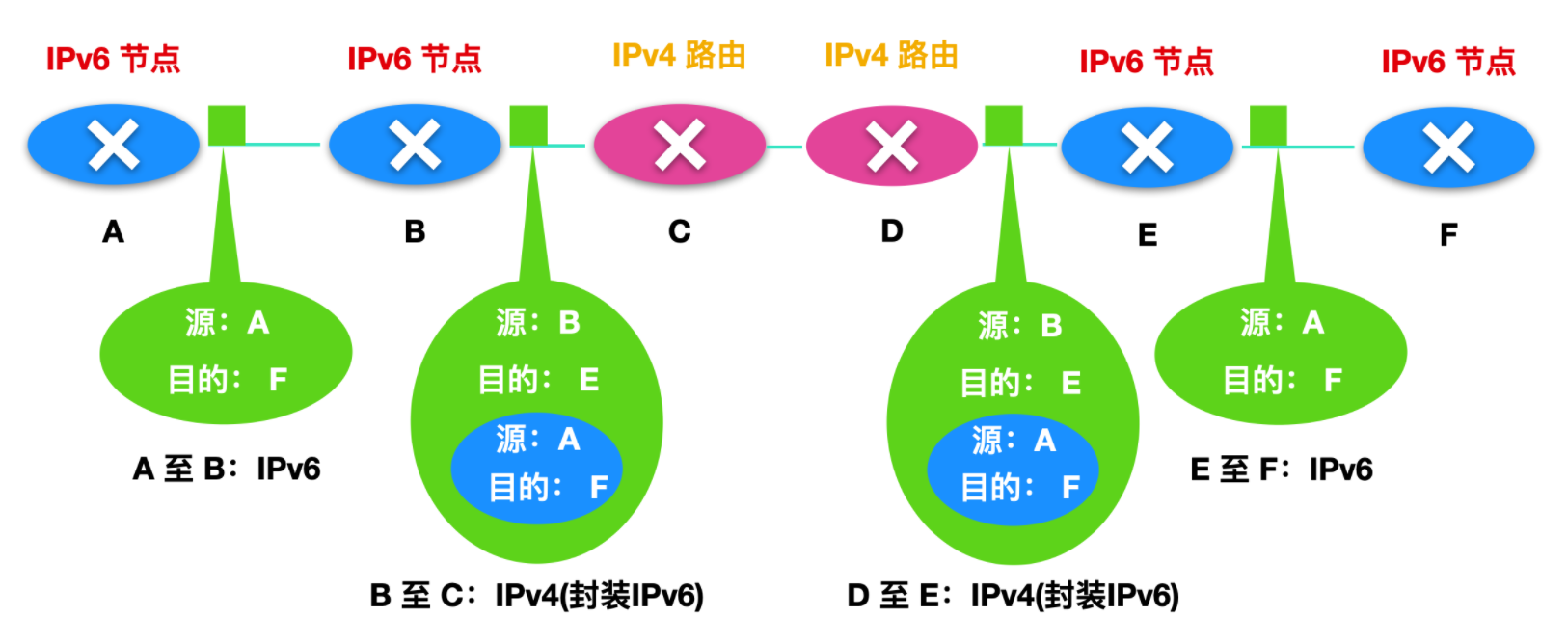
隧道中間的 IPv4 提供路由,路由器不知道這個 IPv4 內部包含一個指向 IPv6 的地址。隧道接收端的 IPv6 節點收到 IPv4 資料報,會確定這個 IPv4 資料報含有一個 IPv6 資料報,通過觀察資料報長度和資料得知。然後取出 IPv6 資料報,再為 IPv6 提供路由,就好像兩個節點直接相連傳輸資料報一樣。
## 總結
這篇文章是計算機網路系列的連載文章,這篇我們主要探討了網路層的相關知識、路由器的內部構造、路由器如何實現轉發的,IP 協議相關內容:包括 IP 地址、IPv4 和 IPv6 的相關內容,最後我們探討了如何使 IPv4 遷移到 IPv6 。
**另外,新增我的微信 becomecxuan,加入每日一題群,每天一道面試題分享,更多內容請參見我的 Github,[成為最好的 bestJavaer](https://github.com/crisxuan/bestJavaer/blob/master/network/computer-internet.md)
**我自己肝了六本 PDF,微信搜尋「程式設計師cxuan」關注公眾號後,在後臺回覆 cxuan ,領取全部 PDF,這些 PDF 如下**
[六本 PDF 連結](https://s3.ax1x.com/2020/11/30/DgOK6f.png)

* `擁塞通告(Explicit Congestion Notification,ECN)` 佔用 2 bit,它允許在不丟棄報文的同時通知對方網路擁塞的發生。ECN 是一種可選的功能,僅當兩端都支援並希望使用,且底層網路支援時才被使用。 最開始 DSCP 和 ECN 統稱為 TOS,也就是區分服務,但是後來被細化為了 DSCP 和 ECN。
* `資料報長度(Total Length)` 佔用 16 bit,這 16 位是包括在資料在內的總長度,理論上資料報的總長度為 2 的 16 次冪 - 1,最大長度是 65535 位元組,但是實際上資料報很少有超過 1500 位元組的。IP 規定所有主機都必須支援最小 576 位元組的報文,但大多數現代主機支援更大的報文。當下層的資料鏈路協議的`最大傳輸單元(MTU)`欄位的值小於 IP 報文長度時,報文就必須被分片。
* `識別符號(Identification)` 佔用 16 bit,這個欄位用來標識所有的分片,因為分片不一定會按序到達,所以到達目標主機的所有分片會進行重組,每產生一個數據報,計數器加1,並賦值給此欄位。
* `標誌(Flags)` 佔用 3 bit,標誌用於控制和識別分片,這 3 位分別是
* 0 位:保留,必須為0;
* 1 位:`禁止分片(Don’t Fragment,DF)`,當 DF = 0 時才允許分片;
* 2 位:`更多分片(More Fragment,MF)`,MF = 1 代表後面還有分片,MF = 0 代表已經是最後一個分片。
如果 DF 標誌被設定為 1 ,但是路由要求必須進行分片,那麼這條資料報回丟棄
* `分片偏移(Fragment Offset)` 佔用 13 位,它指明瞭每個分片相對於原始報文開頭的偏移量,以 8 位元組作單位。
* `存活時間(Time To Live,TTL)` 佔用 8 位,存活時間避免報文在網際網路中`迷失`,比如陷入路由環路。存活時間以秒為單位,但小於一秒的時間均向上取整到一秒。在現實中,這實際上成了一個跳數計數器:報文經過的每個路由器都將此欄位減 1,當此欄位等於 0 時,報文不再向下一跳傳送並被丟棄,這個欄位最大值是 255。
* `協議(Protocol)` 佔用 8 位,這個欄位定義了報文資料區使用的協議。協議內容可以在 https://www.iana.org/assignments/protocol-numbers/protocol-numbers.xhtml 官網上獲取。
* `首部校驗和(Header Checksum)` 佔用 16 位,首部校驗和會對欄位進行糾錯檢查,在每一跳中,路由器都要重新計算出的首部檢驗和並與此欄位進行比對,如果不一致,此報文將會被丟棄。
* `源地址(Source address)` 佔用 32 位,它是 IPv4 地址的構成條件,源地址指的是資料報的傳送方
* `目的地址(Destination address)`佔用 32 位,它是 IPv4 地址的構成條件,目標地址指的是資料報的接收方
* `選項(Options)` 是附加欄位,選項欄位佔用 1 - 40 個位元組不等,一般會跟在目的地址之後。如果首部長度 > 5,就應該考慮選項欄位。
* `資料` 不是首部的一部分,因此並不被包含在首部檢驗和中。
在 IP 傳送的過程中,每個資料報的大小是不同的,每個鏈路層協議能承載的網路層分組也不一樣,有的協議能夠承載大資料報,有的卻只能承載很小的資料報,不同的鏈路層能夠承載的資料報大小如下。

#### IPv4 分片
一個鏈路層幀能承載的最大資料量叫做`最大傳輸單元(Maximum Transmission Unit, MTU)`,每個 IP 資料報封裝在鏈路層幀中從一臺路由器傳到下一臺路由器。因為每個鏈路層所支援的最大 MTU 不一樣,當資料報的大小超過 MTU 後,會在鏈路層進行分片,每個資料報會在鏈路層單獨封裝,每個較小的片都被稱為 `片(fragement)`。

每個片在到達目的地後會進行重組,準確的來說是在運輸層之前會進行重組,TCP 和 UDP 都會希望傳送完整的、未分片的報文,出於效能的原因,分片重組不會在路由器中進行,而是會在目標主機中進行重組。
當目標主機收到從傳送端傳送過來的資料報後,它需要確定這些資料報中的分片是否是由源資料報分片傳遞過來的,如果是的話,還需要確定何時收到了分片中的`最後一片`,並且這些片會如何拼接一起成為資料報。
針對這些潛在的問題,IPv4 設計者將 **標識、標誌和片偏移**放在 IP 資料報首部中。當生成一個數據報時,傳送主機會為該資料報設定源和目的地址的同時貼上`標識號`。傳送主機通常將它傳送的每個資料報的標識 + 1。當某路由器需要對一個數據報分片時,形成的每個資料報具有初始資料報的**源地址、目標地址和標識號**。當目的地從同一傳送主機收到一系列資料報時,它能夠檢查資料報的標識號以確定哪些資料是由源資料報傳送過來的。由於 IP 是一種不可靠的服務,分片可能會在網路中丟失,鑑於這種情況,通常會把分片的最後一個位元設定為 0 ,其他分片設定為 1,同時使用偏移欄位指定分片應該在資料報的哪個位置。
#### IPv4 定址
IPv4 支援三種不同型別的定址模式,分別是
* 單播定址模式:在這種模式下,資料只發送到一個目的地的主機。

* 廣播定址模式:在此模式下,資料包將被定址到網段中的所有主機。這裡客戶端傳送一個數據包,由所有伺服器接收:

* 組播定址模式:此模式是前兩種模式的混合,即傳送的資料包既不指向單個主機也不指定段上的所有主機

### IPv6
隨著端系統接入的越來越多,IPv4 已經無法滿足分配了,所以,IPv6 應運而生,IPv6 就是為了解決 IPv4 的地址耗盡問題而被標準化的網際協議。IPv4 的地址長度為 4 個 8 位元組,即 32 位元, 而 IPv6 的地址長度是原來的四倍,也就是 128 位元,一般寫成 8 個 16 位位元組。
從 IPv4 切換到 IPv6 及其耗時,需要將網路中所有的主機和路由器的 IP 地址進行設定,在網際網路不斷普及的今天,替換所有的 IP 是一個工作量及其龐大的任務。我們後面會說。
我們先來看一下 IPv6 的地址是怎樣的

* `版本`與 IPv4 一樣,版本號由 4 bit 構成,IPv6 版本號的值為 6。
* `流量型別(Traffic Class)` 佔用 8 bit,它就相當於 IPv4 中的服務型別(Type Of Service)。
* `流標籤(Flow Label)` 佔用 20 bit,這 20 位元用於標識一條資料報的流,能夠對一條流中的某些資料報給出優先權,或者它能夠用來對來自某些應用的資料報給出更高的優先權,只有流標籤、源地址和目標地址一致時,才會被認為是一個流。
* `有效載荷長度(Payload Length)` 佔用 16 bit,這 16 位元值作為一個無符號整數,它給出了在 IPv6 資料報中跟在鼎昌 40 位元組資料報首部後面的位元組數量。
* `下一個首部(Next Header)` 佔用 8 bit,它用於標識資料報中的內容需要交付給哪個協議,是 TCP 協議還是 UDP 協議。
* `跳限制(Hop Limit)` 佔用 8 bit,這個欄位與 IPv4 的 TTL 意思相同。資料每經過一次路由就會減 1,減到 0 則會丟棄資料。
* `源地址(Source Address)` 佔用 128 bit (8 個 16 位 ),表示傳送端的 IP 地址。
* `目標地址(Destination Address)` 佔用 128 bit (8 個 16 位 ),表示接收端 IP 地址。
可以看到,相較於 IPv4 ,IPv6 取消了下面幾個欄位
* **識別符號、標誌和位元偏移**:IPv6 不允許在中間路由器上進行分片和重新組裝。這種操作只能在端系統上進行,IPv6 將這個功能放在端系統中,加快了網路中的轉發速度。
* **首部校驗和**:因為在運輸層和資料鏈路執行了報文段完整性校驗工作,IP 設計者大概覺得在網路層中有首部校驗和比較多餘,所以去掉了。**IP 更多專注的是快速處理分組資料**。
* **選項欄位**:選項欄位不再是標準 IP 首部的一部分了,但是它並沒有消失,而是可能出現在 IPv6 的擴充套件首部,也就是下一個首部中。
#### IPv6 擴充套件首部
IPv6 首部長度固定,無法將選項欄位加入其中,取而代之的是 IPv6 使用了`擴充套件首部`
擴充套件首部通常介於 IPv6 首部與 TCP/UDP 首部之間,在 IPv4 中可選長度固定為 40 位元組,在 IPv6 中沒有這樣的限制。IPv6 的擴充套件首部可以是任意長度。擴充套件首部中還可以包含擴充套件首部協議和下一個擴充套件欄位。
IPv6 首部中沒有標識和標誌欄位,**對 IP 進行分片時,需要使用到擴充套件首部**。

具體的擴充套件首部表如下所示

下面我們來看一下 IPv6 都有哪些特點
#### IPv6 特點
IPv6 的特點在 IPv4 中得以實現,但是即便實現了 IPv4 的作業系統,也未必實現了 IPv4 的所有功能。而 IPv6 卻將這些功能大眾化了,也就表明這些功能在 IPv6 已經進行了實現,這些功能主要有
* **地址空間變得更大**:這是 IPv6 最主要的一個特點,即支援更大的地址空間。
* **精簡報文結構**: IPv6 要比 IPv4 精簡很多,IPv4 的報文長度不固定,而且有一個不斷變化的選項欄位;IPv6 報文段固定,並且將選項欄位,分片的欄位移到了 IPv6 擴充套件頭中,這就極大的精簡了 IPv6 的報文結構。
* **實現了自動配置**:IPv6 支援其主機裝置的**狀態和無狀態**自動配置模式。這樣,沒有 `DHCP 伺服器`不會停止跨段通訊。
* **層次化的網路結構**: IPv6 不再像 IPv4 一樣按照 A、B、C等分類來劃分地址,而是通過 IANA -> RIR -> ISP 這樣的順序來分配的。IANA 是國際網際網路號碼分配機構,RIR 是區域網際網路註冊管理機構,ISP 是一些運營商(例如電信、移動、聯通)。
* **IPSec**:IPv6 的擴充套件報頭中有一個認證報頭、封裝安全淨載報頭,這兩個報頭是 IPsec 定義的。通過這兩個報頭網路層自己就可以實現端到端的安全,而無需像 IPv4 協議一樣需要其他協議的幫助。
* **支援任播**:IPv6 引入了一種新的定址方式,稱為任播定址。
#### IPv6 地址
我們知道,IPv6 地址長度為 128 位,他所能表示的範圍是 2 ^ 128 次冪,這個數字非常龐大,幾乎涵蓋了你能想到的所有主機和路由器,那麼 IPv6 該如何表示呢?
一般我們將 128 位元的 IP 地址以每 16 位元為一組,並用 `:` 號進行分隔,如果出現連續的 0 時還可以將 0 省略,並用 `::` 兩個冒號隔開,記住,一個 IP 地址只允許出現一次兩個連續的冒號。
下面是一些 IPv6 地址的示例
* 二進位制數表示

* 用十六進位制數表示

* 出現兩個冒號的情況

如上圖所示,A120 和 4CD 中間的 0 被 :: 所取代了。
## 如何從 IPv4 遷移到 IPv6
我們上面聊了聊 IPv4 和 IPv6 的報文格式、報文含義是什麼、以及 IPv4 和 IPv6 的特徵分別是什麼,看完上面的內容,你已經知道了 IPv4 現在馬上就變的不夠用了,而且隨著 IPv6 的不斷髮展和引用,雖然新型的 IPv6 可以做到`向後相容`,即 IPv6 可以收發 IPv4 的資料報,但是**已經部署的具有 IPv4 能力的系統卻不能夠處理 IPv6 資料報**。所以 IPv4 噬需遷移到 IPv6,遷移並不意味著將 IPv4 替換為 IPv6。這僅意味著同時啟用 IPv6 和 IPv4。
>那麼現在就有一個問題了,IPv4 如何遷移到 IPv6 呢?這就是我們接下來討論的重點。
### 標誌
最簡單的方式就是設定一個標誌日,指定某個時間點和日期,此時全球的因特網機器都會在這時關機從 IPv4 遷移到 IPv6 。上一次重大的技術遷移是在 35 年前,但是很顯然,不用我過多解釋,這種情況肯定是 `不行的`。影響不可估量不說,如何保證全球人類都能知道如何設定自己的 IPv6 地址?一個設計數十億臺機器的標誌日現在是想都不敢想的。
### 隧道技術
現在已經在實踐中使用的從 IPv4 遷移到 IPv6 的方法是 `隧道技術(tunneling)`。
>什麼是隧道技術呢?
隧道技術是一種使用網際網路絡的基礎設施在網路之間的傳輸資料的方式,使用隧道傳遞的資料可以是不同協議的資料幀或包。使用隧道技術所遵從的協議叫做`隧道協議(tunneling protocol)`。隧道協議會將這些協議的資料幀或包封裝在新的包頭中傳送。新的包頭提供了路由資訊,從而使封裝的負載資料能夠通過網際網路絡進行傳遞。
使用隧道技術一般都會建一個`隧道`,建隧道的依據如下:
比如兩個 IPv6 節點(下方 B、E)要使用 IPv6 資料報進行互動,但是它們是經由兩個 IPv4 的路由器進行互聯的。那麼我們就需要將 IPv6 節點和 IPv4 路由器組成一個隧道,如下圖所示

藉助於隧道,在隧道傳送端的 IPv6 節點可將整個 IPv6 資料報放到一個 IPv4 資料報的`資料(有效載荷)` 欄位中,於是,IPv4 資料報的地址被設定為指向隧道接收端的 IPv6 的節點,比如上面的 E 節點。然後再發送給隧道中的第一個節點 C,如下所示

隧道中間的 IPv4 提供路由,路由器不知道這個 IPv4 內部包含一個指向 IPv6 的地址。隧道接收端的 IPv6 節點收到 IPv4 資料報,會確定這個 IPv4 資料報含有一個 IPv6 資料報,通過觀察資料報長度和資料得知。然後取出 IPv6 資料報,再為 IPv6 提供路由,就好像兩個節點直接相連傳輸資料報一樣。
## 總結
這篇文章是計算機網路系列的連載文章,這篇我們主要探討了網路層的相關知識、路由器的內部構造、路由器如何實現轉發的,IP 協議相關內容:包括 IP 地址、IPv4 和 IPv6 的相關內容,最後我們探討了如何使 IPv4 遷移到 IPv6 。
**另外,新增我的微信 becomecxuan,加入每日一題群,每天一道面試題分享,更多內容請參見我的 Github,[成為最好的 bestJavaer](https://github.com/crisxuan/bestJavaer/blob/master/network/computer-internet.md)
**我自己肝了六本 PDF,微信搜尋「程式設計師cxuan」關注公眾號後,在後臺回覆 cxuan ,領取全部 PDF,這些 PDF 如下**
[六本 PDF 連結](https://s3.ax1x.com/2020/11/30/DgOK6f.png)

* `擁塞通告(Explicit Congestion Notification,ECN)` 佔用 2 bit,它允許在不丟棄報文的同時通知對方網路擁塞的發生。ECN 是一種可選的功能,僅當兩端都支援並希望使用,且底層網路支援時才被使用。 最開始 DSCP 和 ECN 統稱為 TOS,也就是區分服務,但是後來被細化為了 DSCP 和 ECN。
* `資料報長度(Total Length)` 佔用 16 bit,這 16 位是包括在資料在內的總長度,理論上資料報的總長度為 2 的 16 次冪 - 1,最大長度是 65535 位元組,但是實際上資料報很少有超過 1500 位元組的。IP 規定所有主機都必須支援最小 576 位元組的報文,但大多數現代主機支援更大的報文。當下層的資料鏈路協議的`最大傳輸單元(MTU)`欄位的值小於 IP 報文長度時,報文就必須被分片。
* `識別符號(Identification)` 佔用 16 bit,這個欄位用來標識所有的分片,因為分片不一定會按序到達,所以到達目標主機的所有分片會進行重組,每產生一個數據報,計數器加1,並賦值給此欄位。
* `標誌(Flags)` 佔用 3 bit,標誌用於控制和識別分片,這 3 位分別是
* 0 位:保留,必須為0;
* 1 位:`禁止分片(Don’t Fragment,DF)`,當 DF = 0 時才允許分片;
* 2 位:`更多分片(More Fragment,MF)`,MF = 1 代表後面還有分片,MF = 0 代表已經是最後一個分片。
如果 DF 標誌被設定為 1 ,但是路由要求必須進行分片,那麼這條資料報回丟棄
* `分片偏移(Fragment Offset)` 佔用 13 位,它指明瞭每個分片相對於原始報文開頭的偏移量,以 8 位元組作單位。
* `存活時間(Time To Live,TTL)` 佔用 8 位,存活時間避免報文在網際網路中`迷失`,比如陷入路由環路。存活時間以秒為單位,但小於一秒的時間均向上取整到一秒。在現實中,這實際上成了一個跳數計數器:報文經過的每個路由器都將此欄位減 1,當此欄位等於 0 時,報文不再向下一跳傳送並被丟棄,這個欄位最大值是 255。
* `協議(Protocol)` 佔用 8 位,這個欄位定義了報文資料區使用的協議。協議內容可以在 https://www.iana.org/assignments/protocol-numbers/protocol-numbers.xhtml 官網上獲取。
* `首部校驗和(Header Checksum)` 佔用 16 位,首部校驗和會對欄位進行糾錯檢查,在每一跳中,路由器都要重新計算出的首部檢驗和並與此欄位進行比對,如果不一致,此報文將會被丟棄。
* `源地址(Source address)` 佔用 32 位,它是 IPv4 地址的構成條件,源地址指的是資料報的傳送方
* `目的地址(Destination address)`佔用 32 位,它是 IPv4 地址的構成條件,目標地址指的是資料報的接收方
* `選項(Options)` 是附加欄位,選項欄位佔用 1 - 40 個位元組不等,一般會跟在目的地址之後。如果首部長度 > 5,就應該考慮選項欄位。
* `資料` 不是首部的一部分,因此並不被包含在首部檢驗和中。
在 IP 傳送的過程中,每個資料報的大小是不同的,每個鏈路層協議能承載的網路層分組也不一樣,有的協議能夠承載大資料報,有的卻只能承載很小的資料報,不同的鏈路層能夠承載的資料報大小如下。

#### IPv4 分片
一個鏈路層幀能承載的最大資料量叫做`最大傳輸單元(Maximum Transmission Unit, MTU)`,每個 IP 資料報封裝在鏈路層幀中從一臺路由器傳到下一臺路由器。因為每個鏈路層所支援的最大 MTU 不一樣,當資料報的大小超過 MTU 後,會在鏈路層進行分片,每個資料報會在鏈路層單獨封裝,每個較小的片都被稱為 `片(fragement)`。

每個片在到達目的地後會進行重組,準確的來說是在運輸層之前會進行重組,TCP 和 UDP 都會希望傳送完整的、未分片的報文,出於效能的原因,分片重組不會在路由器中進行,而是會在目標主機中進行重組。
當目標主機收到從傳送端傳送過來的資料報後,它需要確定這些資料報中的分片是否是由源資料報分片傳遞過來的,如果是的話,還需要確定何時收到了分片中的`最後一片`,並且這些片會如何拼接一起成為資料報。
針對這些潛在的問題,IPv4 設計者將 **標識、標誌和片偏移**放在 IP 資料報首部中。當生成一個數據報時,傳送主機會為該資料報設定源和目的地址的同時貼上`標識號`。傳送主機通常將它傳送的每個資料報的標識 + 1。當某路由器需要對一個數據報分片時,形成的每個資料報具有初始資料報的**源地址、目標地址和標識號**。當目的地從同一傳送主機收到一系列資料報時,它能夠檢查資料報的標識號以確定哪些資料是由源資料報傳送過來的。由於 IP 是一種不可靠的服務,分片可能會在網路中丟失,鑑於這種情況,通常會把分片的最後一個位元設定為 0 ,其他分片設定為 1,同時使用偏移欄位指定分片應該在資料報的哪個位置。
#### IPv4 定址
IPv4 支援三種不同型別的定址模式,分別是
* 單播定址模式:在這種模式下,資料只發送到一個目的地的主機。

* 廣播定址模式:在此模式下,資料包將被定址到網段中的所有主機。這裡客戶端傳送一個數據包,由所有伺服器接收:

* 組播定址模式:此模式是前兩種模式的混合,即傳送的資料包既不指向單個主機也不指定段上的所有主機

### IPv6
隨著端系統接入的越來越多,IPv4 已經無法滿足分配了,所以,IPv6 應運而生,IPv6 就是為了解決 IPv4 的地址耗盡問題而被標準化的網際協議。IPv4 的地址長度為 4 個 8 位元組,即 32 位元, 而 IPv6 的地址長度是原來的四倍,也就是 128 位元,一般寫成 8 個 16 位位元組。
從 IPv4 切換到 IPv6 及其耗時,需要將網路中所有的主機和路由器的 IP 地址進行設定,在網際網路不斷普及的今天,替換所有的 IP 是一個工作量及其龐大的任務。我們後面會說。
我們先來看一下 IPv6 的地址是怎樣的

* `版本`與 IPv4 一樣,版本號由 4 bit 構成,IPv6 版本號的值為 6。
* `流量型別(Traffic Class)` 佔用 8 bit,它就相當於 IPv4 中的服務型別(Type Of Service)。
* `流標籤(Flow Label)` 佔用 20 bit,這 20 位元用於標識一條資料報的流,能夠對一條流中的某些資料報給出優先權,或者它能夠用來對來自某些應用的資料報給出更高的優先權,只有流標籤、源地址和目標地址一致時,才會被認為是一個流。
* `有效載荷長度(Payload Length)` 佔用 16 bit,這 16 位元值作為一個無符號整數,它給出了在 IPv6 資料報中跟在鼎昌 40 位元組資料報首部後面的位元組數量。
* `下一個首部(Next Header)` 佔用 8 bit,它用於標識資料報中的內容需要交付給哪個協議,是 TCP 協議還是 UDP 協議。
* `跳限制(Hop Limit)` 佔用 8 bit,這個欄位與 IPv4 的 TTL 意思相同。資料每經過一次路由就會減 1,減到 0 則會丟棄資料。
* `源地址(Source Address)` 佔用 128 bit (8 個 16 位 ),表示傳送端的 IP 地址。
* `目標地址(Destination Address)` 佔用 128 bit (8 個 16 位 ),表示接收端 IP 地址。
可以看到,相較於 IPv4 ,IPv6 取消了下面幾個欄位
* **識別符號、標誌和位元偏移**:IPv6 不允許在中間路由器上進行分片和重新組裝。這種操作只能在端系統上進行,IPv6 將這個功能放在端系統中,加快了網路中的轉發速度。
* **首部校驗和**:因為在運輸層和資料鏈路執行了報文段完整性校驗工作,IP 設計者大概覺得在網路層中有首部校驗和比較多餘,所以去掉了。**IP 更多專注的是快速處理分組資料**。
* **選項欄位**:選項欄位不再是標準 IP 首部的一部分了,但是它並沒有消失,而是可能出現在 IPv6 的擴充套件首部,也就是下一個首部中。
#### IPv6 擴充套件首部
IPv6 首部長度固定,無法將選項欄位加入其中,取而代之的是 IPv6 使用了`擴充套件首部`
擴充套件首部通常介於 IPv6 首部與 TCP/UDP 首部之間,在 IPv4 中可選長度固定為 40 位元組,在 IPv6 中沒有這樣的限制。IPv6 的擴充套件首部可以是任意長度。擴充套件首部中還可以包含擴充套件首部協議和下一個擴充套件欄位。
IPv6 首部中沒有標識和標誌欄位,**對 IP 進行分片時,需要使用到擴充套件首部**。

具體的擴充套件首部表如下所示

下面我們來看一下 IPv6 都有哪些特點
#### IPv6 特點
IPv6 的特點在 IPv4 中得以實現,但是即便實現了 IPv4 的作業系統,也未必實現了 IPv4 的所有功能。而 IPv6 卻將這些功能大眾化了,也就表明這些功能在 IPv6 已經進行了實現,這些功能主要有
* **地址空間變得更大**:這是 IPv6 最主要的一個特點,即支援更大的地址空間。
* **精簡報文結構**: IPv6 要比 IPv4 精簡很多,IPv4 的報文長度不固定,而且有一個不斷變化的選項欄位;IPv6 報文段固定,並且將選項欄位,分片的欄位移到了 IPv6 擴充套件頭中,這就極大的精簡了 IPv6 的報文結構。
* **實現了自動配置**:IPv6 支援其主機裝置的**狀態和無狀態**自動配置模式。這樣,沒有 `DHCP 伺服器`不會停止跨段通訊。
* **層次化的網路結構**: IPv6 不再像 IPv4 一樣按照 A、B、C等分類來劃分地址,而是通過 IANA -> RIR -> ISP 這樣的順序來分配的。IANA 是國際網際網路號碼分配機構,RIR 是區域網際網路註冊管理機構,ISP 是一些運營商(例如電信、移動、聯通)。
* **IPSec**:IPv6 的擴充套件報頭中有一個認證報頭、封裝安全淨載報頭,這兩個報頭是 IPsec 定義的。通過這兩個報頭網路層自己就可以實現端到端的安全,而無需像 IPv4 協議一樣需要其他協議的幫助。
* **支援任播**:IPv6 引入了一種新的定址方式,稱為任播定址。
#### IPv6 地址
我們知道,IPv6 地址長度為 128 位,他所能表示的範圍是 2 ^ 128 次冪,這個數字非常龐大,幾乎涵蓋了你能想到的所有主機和路由器,那麼 IPv6 該如何表示呢?
一般我們將 128 位元的 IP 地址以每 16 位元為一組,並用 `:` 號進行分隔,如果出現連續的 0 時還可以將 0 省略,並用 `::` 兩個冒號隔開,記住,一個 IP 地址只允許出現一次兩個連續的冒號。
下面是一些 IPv6 地址的示例
* 二進位制數表示

* 用十六進位制數表示

* 出現兩個冒號的情況

如上圖所示,A120 和 4CD 中間的 0 被 :: 所取代了。
## 如何從 IPv4 遷移到 IPv6
我們上面聊了聊 IPv4 和 IPv6 的報文格式、報文含義是什麼、以及 IPv4 和 IPv6 的特徵分別是什麼,看完上面的內容,你已經知道了 IPv4 現在馬上就變的不夠用了,而且隨著 IPv6 的不斷髮展和引用,雖然新型的 IPv6 可以做到`向後相容`,即 IPv6 可以收發 IPv4 的資料報,但是**已經部署的具有 IPv4 能力的系統卻不能夠處理 IPv6 資料報**。所以 IPv4 噬需遷移到 IPv6,遷移並不意味著將 IPv4 替換為 IPv6。這僅意味著同時啟用 IPv6 和 IPv4。
>那麼現在就有一個問題了,IPv4 如何遷移到 IPv6 呢?這就是我們接下來討論的重點。
### 標誌
最簡單的方式就是設定一個標誌日,指定某個時間點和日期,此時全球的因特網機器都會在這時關機從 IPv4 遷移到 IPv6 。上一次重大的技術遷移是在 35 年前,但是很顯然,不用我過多解釋,這種情況肯定是 `不行的`。影響不可估量不說,如何保證全球人類都能知道如何設定自己的 IPv6 地址?一個設計數十億臺機器的標誌日現在是想都不敢想的。
### 隧道技術
現在已經在實踐中使用的從 IPv4 遷移到 IPv6 的方法是 `隧道技術(tunneling)`。
>什麼是隧道技術呢?
隧道技術是一種使用網際網路絡的基礎設施在網路之間的傳輸資料的方式,使用隧道傳遞的資料可以是不同協議的資料幀或包。使用隧道技術所遵從的協議叫做`隧道協議(tunneling protocol)`。隧道協議會將這些協議的資料幀或包封裝在新的包頭中傳送。新的包頭提供了路由資訊,從而使封裝的負載資料能夠通過網際網路絡進行傳遞。
使用隧道技術一般都會建一個`隧道`,建隧道的依據如下:
比如兩個 IPv6 節點(下方 B、E)要使用 IPv6 資料報進行互動,但是它們是經由兩個 IPv4 的路由器進行互聯的。那麼我們就需要將 IPv6 節點和 IPv4 路由器組成一個隧道,如下圖所示

藉助於隧道,在隧道傳送端的 IPv6 節點可將整個 IPv6 資料報放到一個 IPv4 資料報的`資料(有效載荷)` 欄位中,於是,IPv4 資料報的地址被設定為指向隧道接收端的 IPv6 的節點,比如上面的 E 節點。然後再發送給隧道中的第一個節點 C,如下所示

隧道中間的 IPv4 提供路由,路由器不知道這個 IPv4 內部包含一個指向 IPv6 的地址。隧道接收端的 IPv6 節點收到 IPv4 資料報,會確定這個 IPv4 資料報含有一個 IPv6 資料報,通過觀察資料報長度和資料得知。然後取出 IPv6 資料報,再為 IPv6 提供路由,就好像兩個節點直接相連傳輸資料報一樣。
## 總結
這篇文章是計算機網路系列的連載文章,這篇我們主要探討了網路層的相關知識、路由器的內部構造、路由器如何實現轉發的,IP 協議相關內容:包括 IP 地址、IPv4 和 IPv6 的相關內容,最後我們探討了如何使 IPv4 遷移到 IPv6 。
**另外,新增我的微信 becomecxuan,加入每日一題群,每天一道面試題分享,更多內容請參見我的 Github,[成為最好的 bestJavaer](https://github.com/crisxuan/bestJavaer/blob/master/network/computer-internet.md)
**我自己肝了六本 PDF,微信搜尋「程式設計師cxuan」關注公眾號後,在後臺回覆 cxuan ,領取全部 PDF,這些 PDF 如下**
[六本 PDF 連結](https://s3.ax1x.com/2020/11/30/DgOK6f.png)
