
寫了一個慢介面,年終妥妥的325
阿新 • • 發佈:2021-01-07
一個專案要想抗住越大的壓力,那麼每個API都得在最短的時間內響應,這樣吞吐量才高。
在很多時候,開發壓根沒有去做過優化,等到某天壓力上來時,系統就扛不住了。
**舉一個最常見的例子:**
大家上班都會做地鐵(土豪可以開車哈)吧,地鐵都有固定的幾個入口,每個入口有幾個固定的閘機可以掃碼進入。
如果每個人掃碼進站的時間都控制在2秒內,那麼一個閘機一分鐘可以過30個人。如果有一個人他在那磨蹭半天,花了20秒,也就是這個閘機這一分鐘只能過21個人,吞吐量立馬就下降了。
這種生活中的案例在程式的世界中也是同樣適用的,而且是一個原理,只要有一個慢介面,就會影響整體的效能。總的來說就是隊友都要很給力,不要有Pig隊友。
**下面看真實案例:**
正在划水看美女的時候,突然收到告警,有幾個介面響應時間超長,高達幾十秒。慌得一批,估計哪裡又出問題了。
趕緊上Cat看看詳情情況,商品服務的一個RPC介面響應太慢了,而且也沒啥呼叫量,淚奔。。。

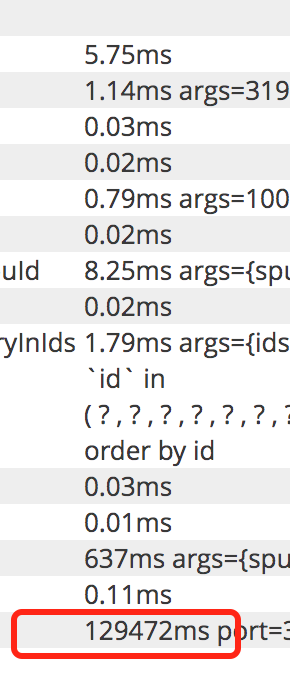
仔細看其實並不是有很長的耗時操作,但是整體耗時卻很長,肯定是請求被阻塞了。
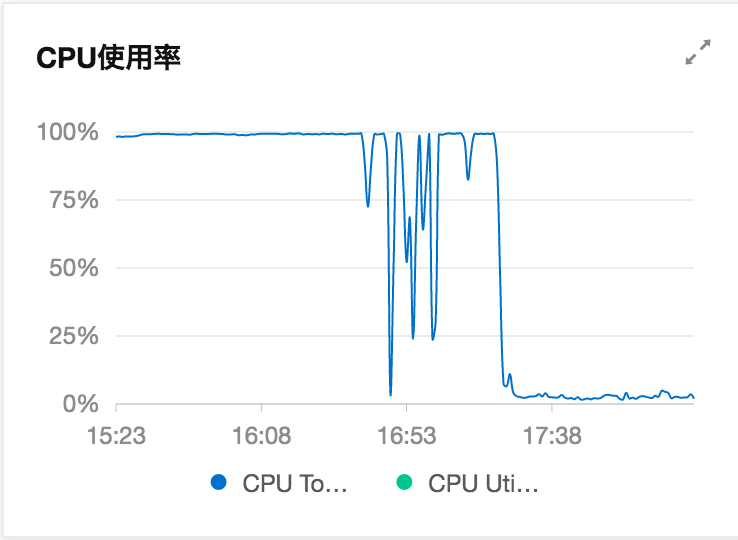
然後去看對應機器的監控,發現CPU很高,幾乎100%的狀態。
看了下GC情況,也挺正常的,後面看了執行緒池的情況才發現原因。
上面只是表面現象,告警的時候是有幾個慢介面的,排查的時候就選了第一個在看,忽略了其他的介面,以為是同一個問題。
真正慢的是另一個慢介面被Job大量呼叫了,服務執行緒都被打滿了。導致其他介面很慢。
優化方案:
* 定時任務時間調整,儘量在凌晨執行
* 單獨提供一個服務,只對Job提供服務,連從庫,影響降到最小
* 對慢介面進行效能優化
關於作者:尹吉歡,簡單的技術愛好者,《Spring Cloud 微服務-全棧技術與案例解析》, 《Spring Cloud 微服務 入門 實戰與進階》作者, 公眾號 猿天地 發起人。
有收穫,不要吝嗇你的點贊。
PS:對於Job型別的介面呼叫,大家會做隔離?限流?時間調整?文末留言討論討