
深入彙編指令理解Java關鍵字volatile
阿新 • • 發佈:2021-01-17
## volatile是什麼
volatile關鍵字是Java提供的一種輕量級同步機制。它能夠保證可見性和有序性,但是不能保證原子性
## 可見性
對於volatile的可見性,先看看這段程式碼的執行
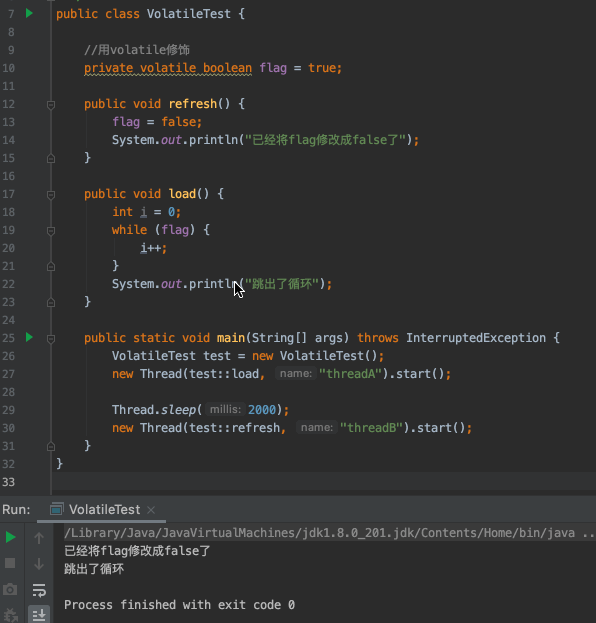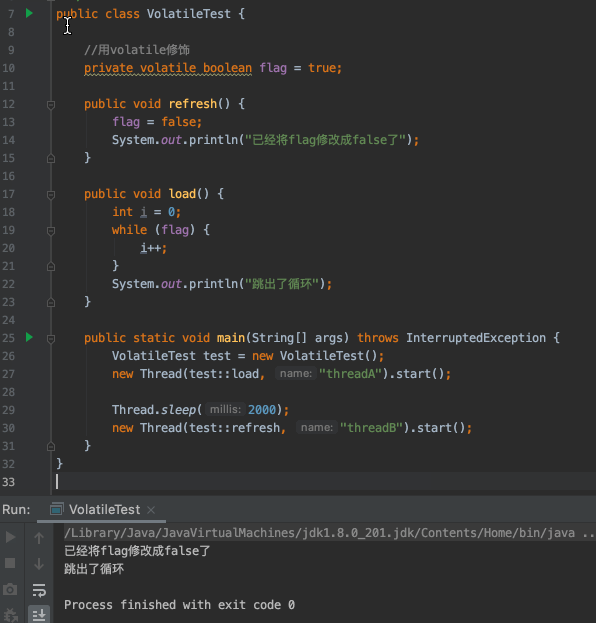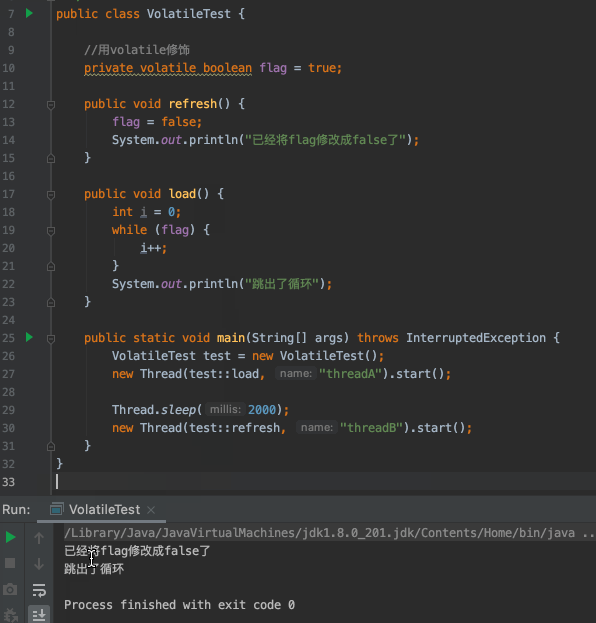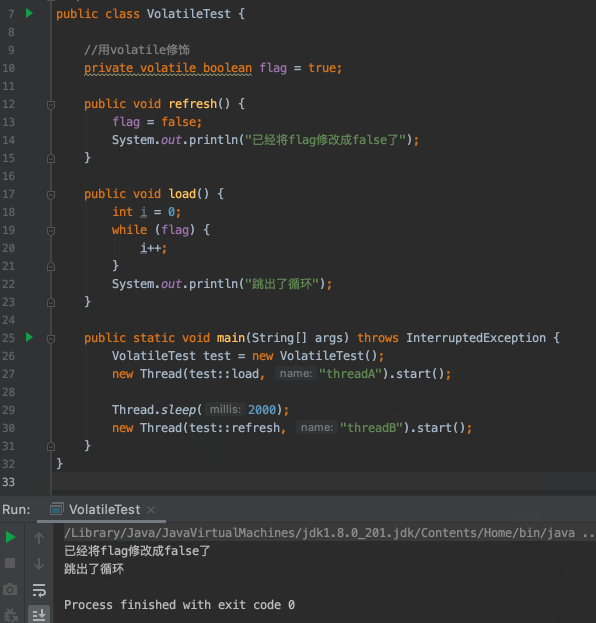
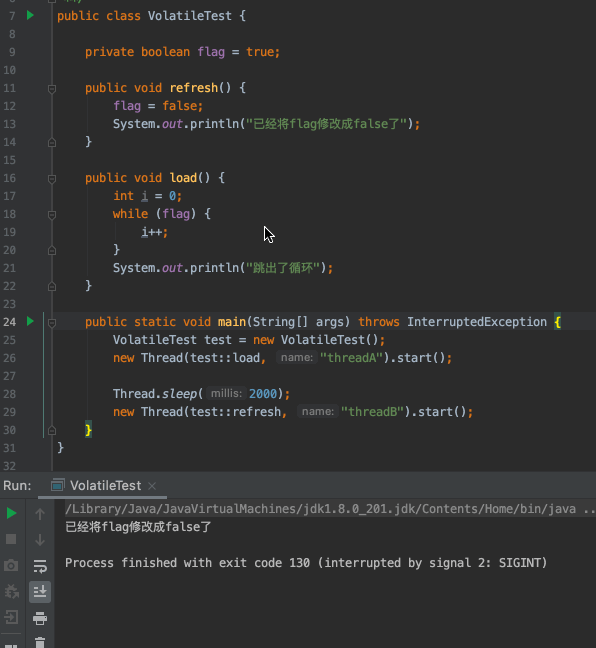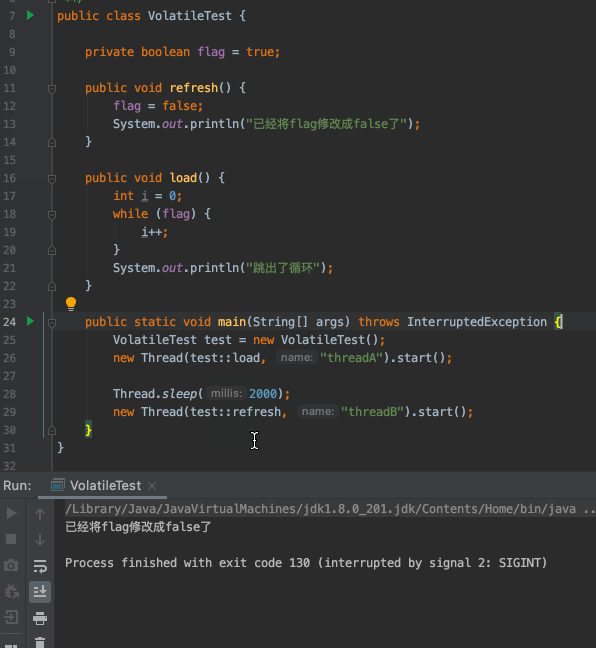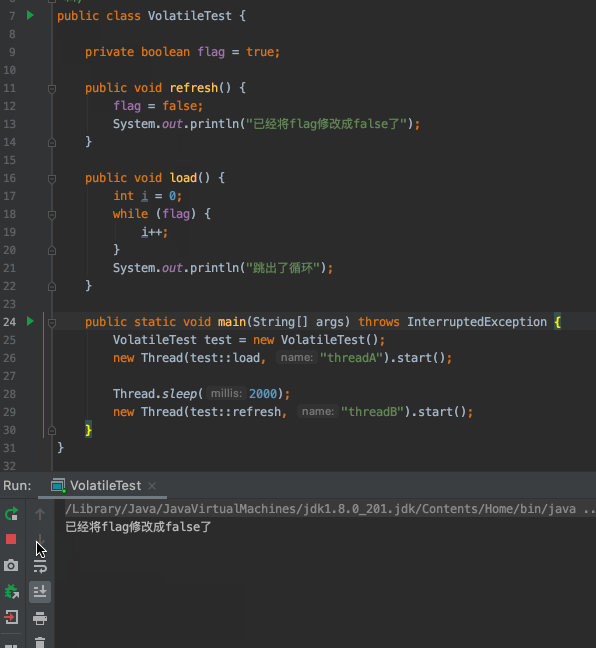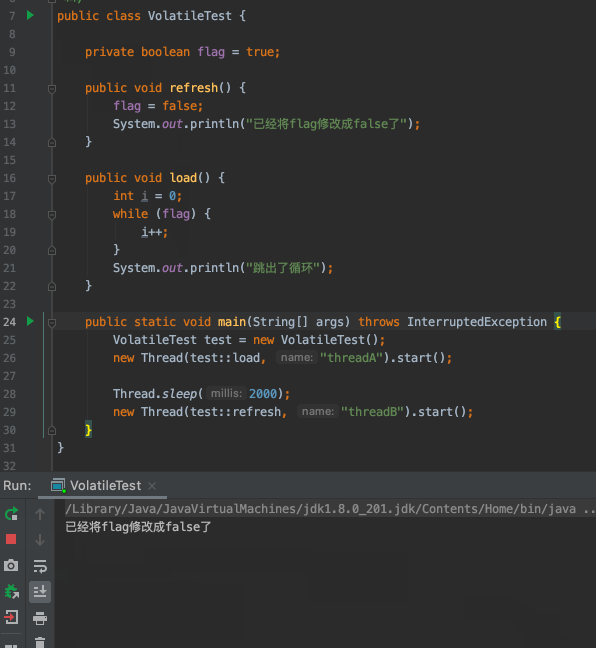 - `flag`預設為`true`
- 建立一個執行緒A去判斷`flag`是否為`true`,如果為`true`迴圈執行`i++`操作
- 兩秒後,建立另一個執行緒B將`flag`修改為`false`
- 執行緒A沒有感知到`flag`已經被修改成`false`了,不能跳出迴圈
這相當於啥呢?相當於你的女神和你說,你好好努力,年薪百萬了就嫁給你,你聽了之後,努力賺錢。3年之後,你年薪百萬了,回去找你女神,結果發現你女神結婚了,她結婚的訊息根本沒有告訴你!難不難受?
- `flag`預設為`true`
- 建立一個執行緒A去判斷`flag`是否為`true`,如果為`true`迴圈執行`i++`操作
- 兩秒後,建立另一個執行緒B將`flag`修改為`false`
- 執行緒A沒有感知到`flag`已經被修改成`false`了,不能跳出迴圈
這相當於啥呢?相當於你的女神和你說,你好好努力,年薪百萬了就嫁給你,你聽了之後,努力賺錢。3年之後,你年薪百萬了,回去找你女神,結果發現你女神結婚了,她結婚的訊息根本沒有告訴你!難不難受?
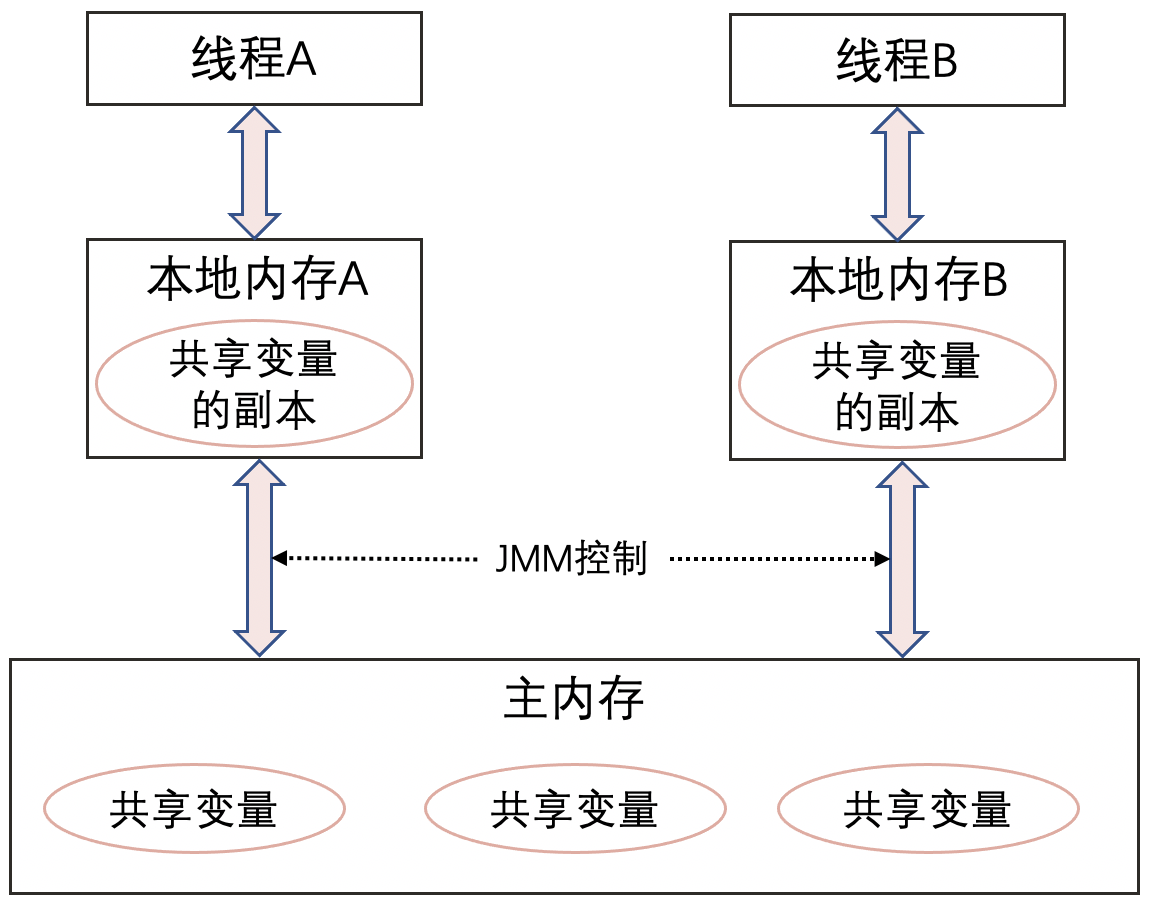
 女神結婚可以不告訴你,可是Java程式碼中的屬性都是存在記憶體中,一個執行緒的修改為什麼另一個執行緒為什麼不可見呢?這就不得不提到Java中的記憶體模型了,Java中的記憶體模型,簡稱JMM,JMM定義了執行緒和主記憶體之間的抽象關係,定義了執行緒之間的共享變數儲存在主記憶體中,每個執行緒都有一個私有的本地記憶體,本地記憶體中儲存了該執行緒以讀/寫共享變數的副本,它涵蓋了快取、寫緩衝區、暫存器以及其他的硬體和編譯器優化。
注意!JMM是一個遮蔽了不同作業系統架構的差異的抽象概念,只是一組Java規範。
女神結婚可以不告訴你,可是Java程式碼中的屬性都是存在記憶體中,一個執行緒的修改為什麼另一個執行緒為什麼不可見呢?這就不得不提到Java中的記憶體模型了,Java中的記憶體模型,簡稱JMM,JMM定義了執行緒和主記憶體之間的抽象關係,定義了執行緒之間的共享變數儲存在主記憶體中,每個執行緒都有一個私有的本地記憶體,本地記憶體中儲存了該執行緒以讀/寫共享變數的副本,它涵蓋了快取、寫緩衝區、暫存器以及其他的硬體和編譯器優化。
注意!JMM是一個遮蔽了不同作業系統架構的差異的抽象概念,只是一組Java規範。
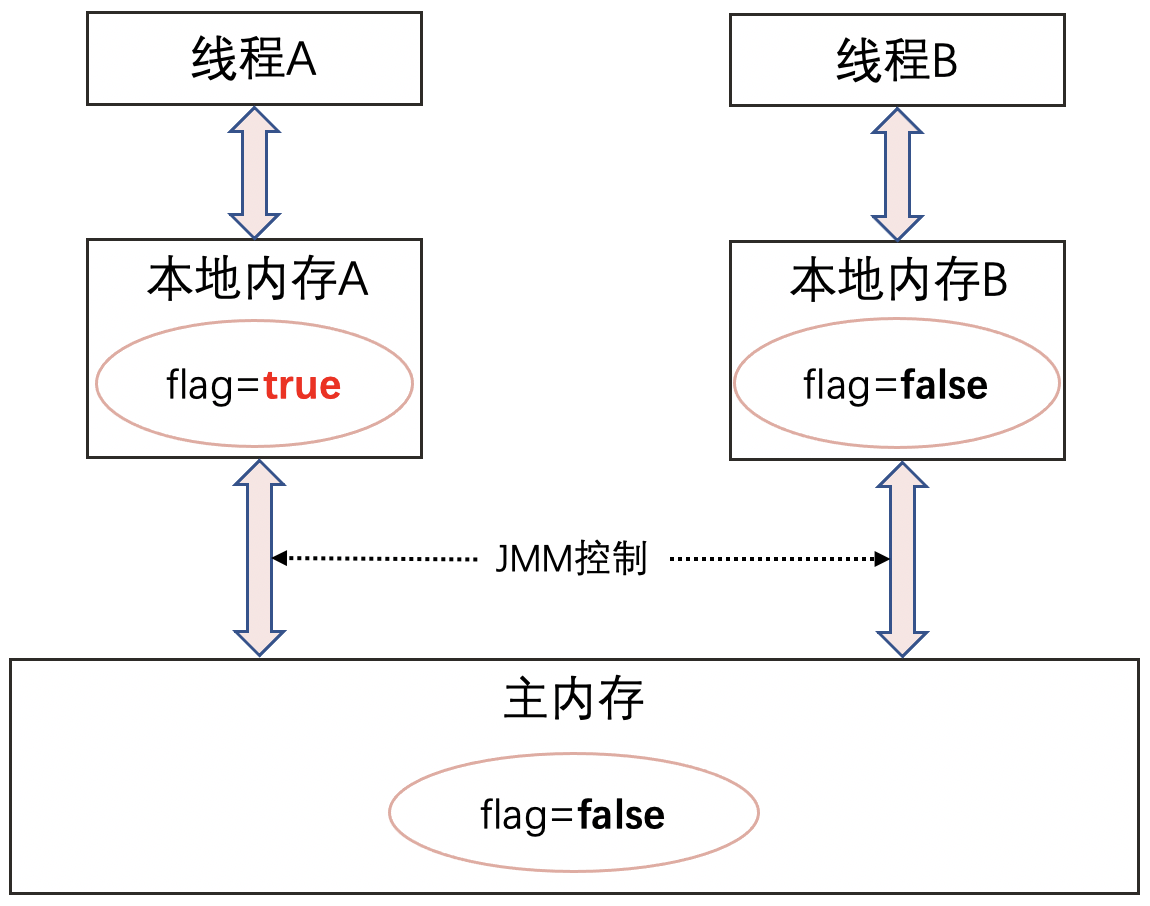 - 因為執行緒A複製了一份剛開始的`flage=true`到本地記憶體,之後執行緒A使用的`flag`都是這個複製到本地記憶體的flag。
- 執行緒B修改了`flag`之後,將flag的值重新整理到主記憶體,此時主記憶體的flag值變成了`false`。
- 執行緒A是不知道執行緒B修改了`flag`,一直用的是本地記憶體的`flag = true`。
那麼,如何才能讓執行緒A知道flag被修改了呢?或者說怎麼讓執行緒A本地記憶體中快取的flag無效,實現執行緒間可見呢?用volatile修飾flag就可以做到:
- 因為執行緒A複製了一份剛開始的`flage=true`到本地記憶體,之後執行緒A使用的`flag`都是這個複製到本地記憶體的flag。
- 執行緒B修改了`flag`之後,將flag的值重新整理到主記憶體,此時主記憶體的flag值變成了`false`。
- 執行緒A是不知道執行緒B修改了`flag`,一直用的是本地記憶體的`flag = true`。
那麼,如何才能讓執行緒A知道flag被修改了呢?或者說怎麼讓執行緒A本地記憶體中快取的flag無效,實現執行緒間可見呢?用volatile修飾flag就可以做到:
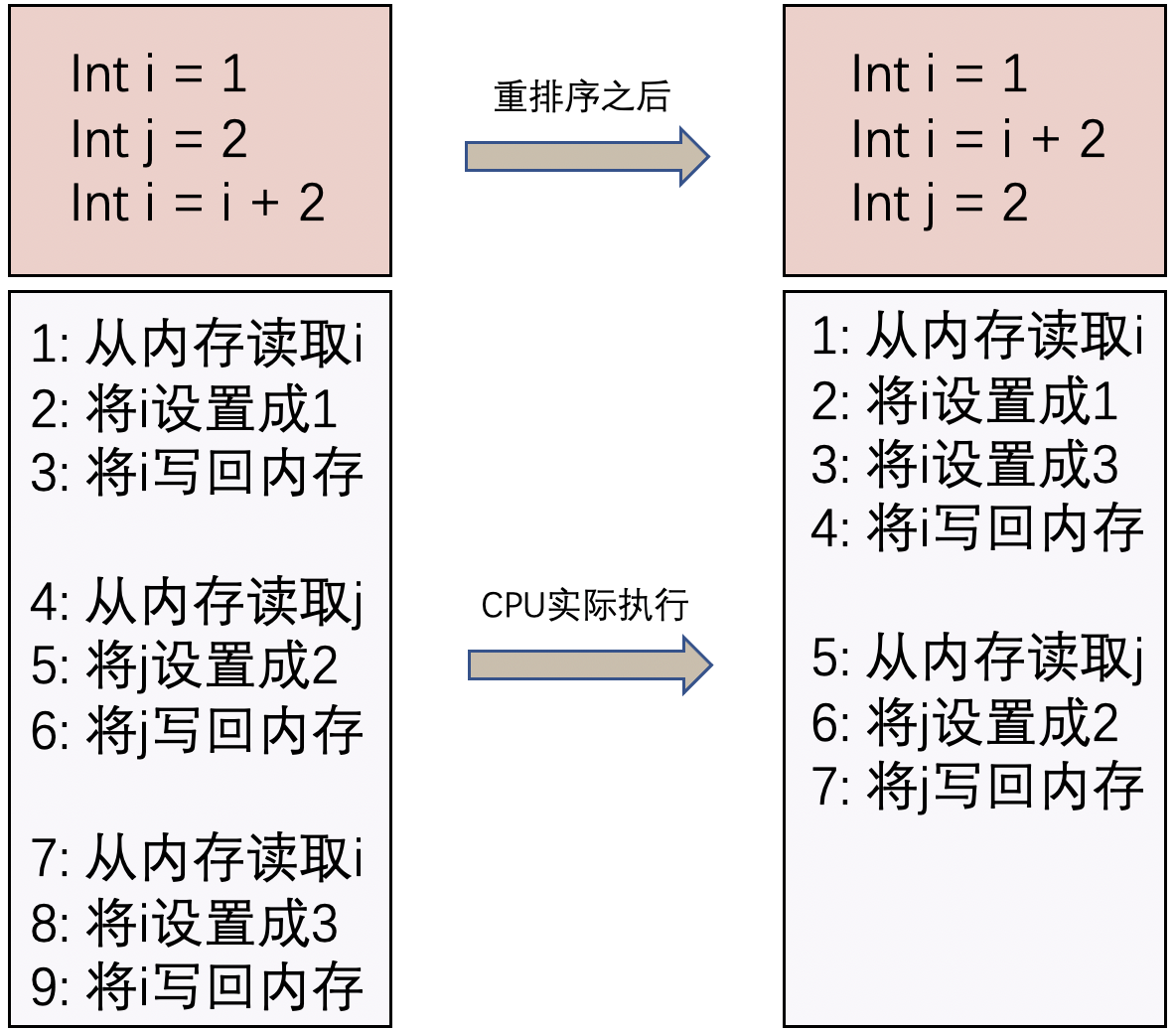 可以看到重排序之後CPU實際執行省略了一個讀取和寫回的操作,也就間接的提升了執行效率。
有一點必須強調的是,上圖的例子只是為了讓讀者更好的理解為什麼重排序能提升執行效率,實際上Java裡面的重排序並不是基於程式碼級別的,從程式碼到CPU執行之間還有很多個階段,CPU底層還有一些優化,實際上的執行流程可能並不是上圖的說的那樣。不必過於糾結於此。
重排序可以提高程式的執行效率,但是必須遵循as-if-serial語義。as-if-serial語義是什麼呢?簡單來說,就是不管你怎麼重排序,你必須保證不管怎麼重排序,單執行緒下程式的執行結果不能被改變。
## 有序性
上面我們已經介紹了Java有重排序情況,現在我們再來聊一聊volatile的有序性。
先看一個經典的面試題:為什麼DDL(double check lock)單例模式需要加volatile關鍵字?
可以看到重排序之後CPU實際執行省略了一個讀取和寫回的操作,也就間接的提升了執行效率。
有一點必須強調的是,上圖的例子只是為了讓讀者更好的理解為什麼重排序能提升執行效率,實際上Java裡面的重排序並不是基於程式碼級別的,從程式碼到CPU執行之間還有很多個階段,CPU底層還有一些優化,實際上的執行流程可能並不是上圖的說的那樣。不必過於糾結於此。
重排序可以提高程式的執行效率,但是必須遵循as-if-serial語義。as-if-serial語義是什麼呢?簡單來說,就是不管你怎麼重排序,你必須保證不管怎麼重排序,單執行緒下程式的執行結果不能被改變。
## 有序性
上面我們已經介紹了Java有重排序情況,現在我們再來聊一聊volatile的有序性。
先看一個經典的面試題:為什麼DDL(double check lock)單例模式需要加volatile關鍵字?
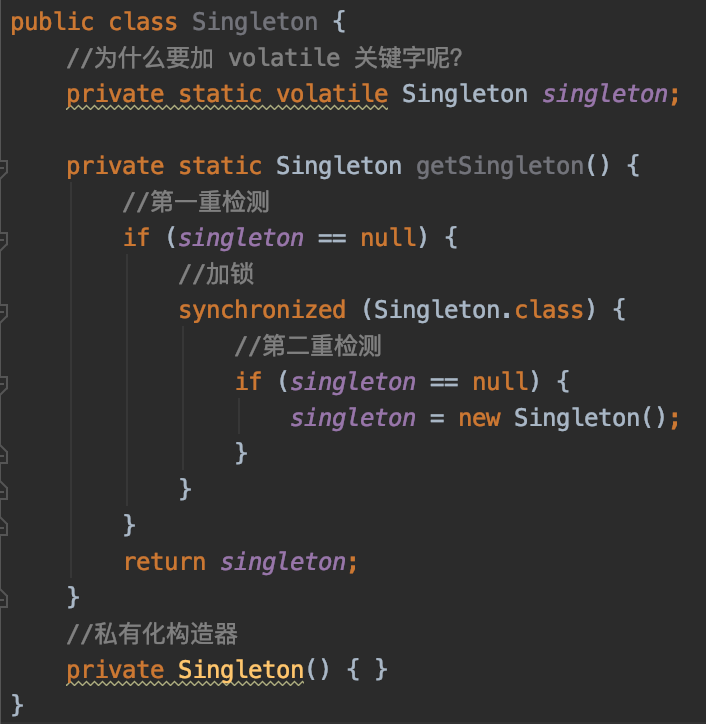
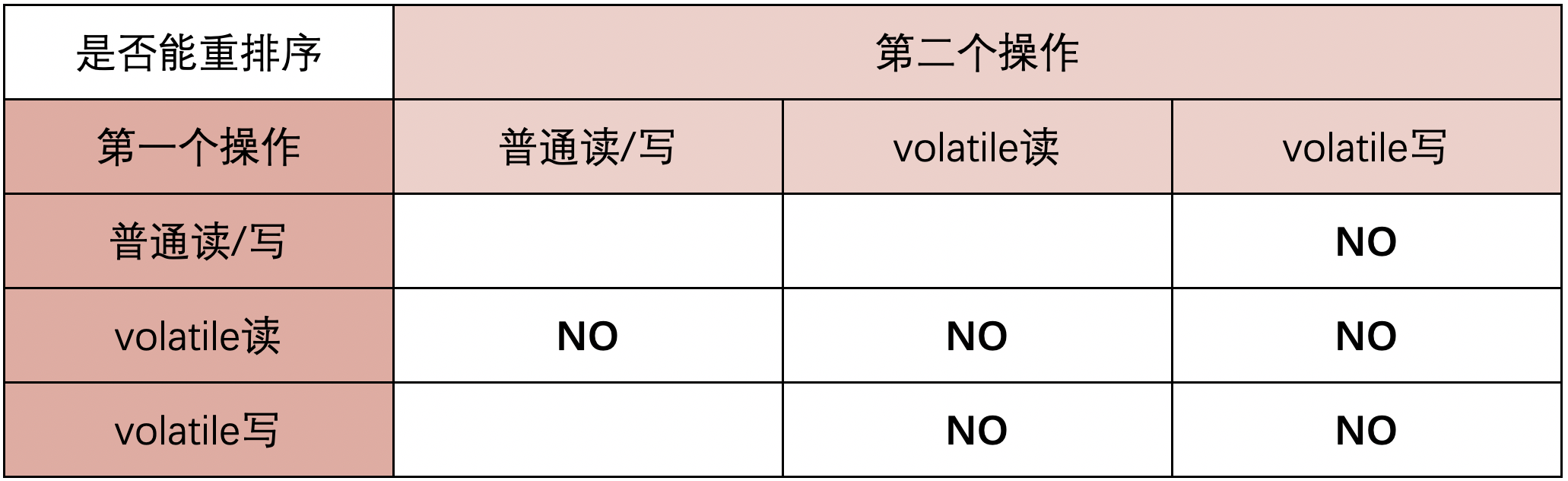 總結來說就是:
- 第二個操作是volatile寫,不管第一個操作是什麼都不會重排序
- 第一個操作是volatile讀,不管第二個操作是什麼都不會重排序
- 第一個操作是volatile寫,第二個操作是volatile讀,也不會發生重排序
如何保證這些操作不會發送重排序呢?就是通過插入記憶體屏障保證的,JMM層面的記憶體屏障分為讀(load)屏障和寫(Store)屏障,排列組合就有了四種屏障。對於volatile操作,JMM記憶體屏障插入策略:
- 在每個volatile寫操作的前面插入一個StoreStore屏障
- 在每個volatile寫操作的後面插入一個StoreLoad屏障
- 在每個volatile讀操作的後面插入一個LoadLoad屏障
- 在每個volatile讀操作的後面插入一個LoadStore屏障
總結來說就是:
- 第二個操作是volatile寫,不管第一個操作是什麼都不會重排序
- 第一個操作是volatile讀,不管第二個操作是什麼都不會重排序
- 第一個操作是volatile寫,第二個操作是volatile讀,也不會發生重排序
如何保證這些操作不會發送重排序呢?就是通過插入記憶體屏障保證的,JMM層面的記憶體屏障分為讀(load)屏障和寫(Store)屏障,排列組合就有了四種屏障。對於volatile操作,JMM記憶體屏障插入策略:
- 在每個volatile寫操作的前面插入一個StoreStore屏障
- 在每個volatile寫操作的後面插入一個StoreLoad屏障
- 在每個volatile讀操作的後面插入一個LoadLoad屏障
- 在每個volatile讀操作的後面插入一個LoadStore屏障
 上面的屏障都是JMM規範級別的,意思是,按照這個規範寫JDK能保證volatile修飾的記憶體區域的操作不會發送重排序。
在硬體層面上,也提供了一系列的記憶體屏障來提供一致性的能力。拿X86平臺來說,主要提供了這幾種記憶體屏障指令:
- lfence指令:在lfence指令前的讀操作當必須在lfence指令後的讀操作前完成,類似於讀屏障
- sfence指令:在sfence指令前的寫操作當必須在sfence指令後的寫操作前完成,類似於寫屏障
- mfence指令: 在mfence指令前的讀寫操作當必須在mfence指令後的讀寫操作前完成,類似讀寫屏障。
JMM規範需要加這麼多記憶體屏障,但實際情況並不需要加這麼多記憶體屏障。以我們常見的X86處理器為例,X86處理器不會對`讀-讀`、`讀-寫`和`寫-寫`操作做重排序,會省略掉這3種操作型別對應的記憶體屏障,僅會對`寫-讀`操作做重排序。所以volatile`寫-讀`操作只需要在volatile寫後插入StoreLoad屏障。在《The JSR-133 Cookbook for Compiler Writers》中,也很明確的指出了這一點:
上面的屏障都是JMM規範級別的,意思是,按照這個規範寫JDK能保證volatile修飾的記憶體區域的操作不會發送重排序。
在硬體層面上,也提供了一系列的記憶體屏障來提供一致性的能力。拿X86平臺來說,主要提供了這幾種記憶體屏障指令:
- lfence指令:在lfence指令前的讀操作當必須在lfence指令後的讀操作前完成,類似於讀屏障
- sfence指令:在sfence指令前的寫操作當必須在sfence指令後的寫操作前完成,類似於寫屏障
- mfence指令: 在mfence指令前的讀寫操作當必須在mfence指令後的讀寫操作前完成,類似讀寫屏障。
JMM規範需要加這麼多記憶體屏障,但實際情況並不需要加這麼多記憶體屏障。以我們常見的X86處理器為例,X86處理器不會對`讀-讀`、`讀-寫`和`寫-寫`操作做重排序,會省略掉這3種操作型別對應的記憶體屏障,僅會對`寫-讀`操作做重排序。所以volatile`寫-讀`操作只需要在volatile寫後插入StoreLoad屏障。在《The JSR-133 Cookbook for Compiler Writers》中,也很明確的指出了這一點:
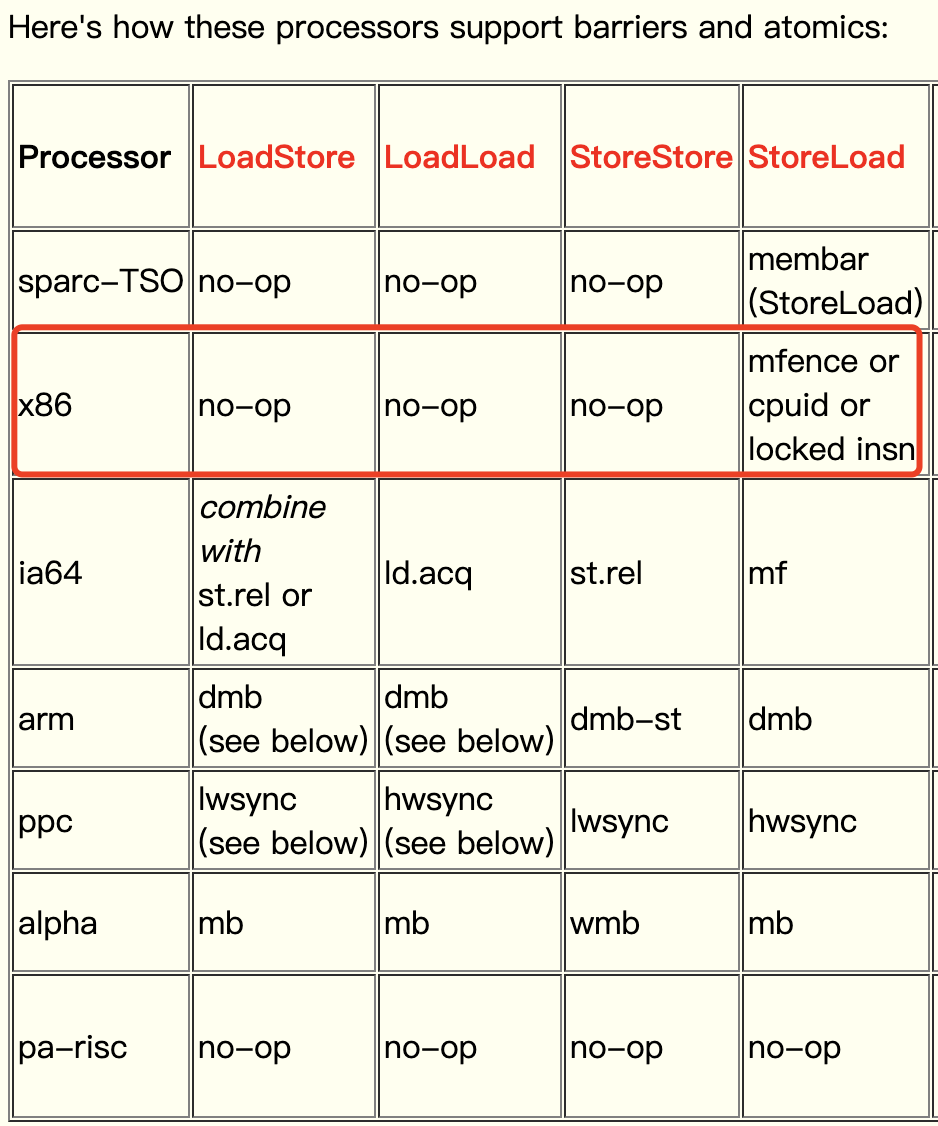 而在x86處理器中,有三種方法可以實現實現StoreLoad屏障的效果,分別為:
- mfence指令:上文提到過,能實現全能型屏障,具備lfence和sfence的能力。
- cpuid指令:cpuid操作碼是一個面向x86架構的處理器補充指令,它的名稱派生自CPU識別,作用是允許軟體發現處理器的詳細資訊。
- lock指令字首:匯流排鎖。lock字首只能加在一些特殊的指令前面。
實際上HotSpot關於volatile的實現就是使用的lock指令,只在volatile標記的地方加上帶lock字首指令操作,並沒有參照JMM規範的屏障設計而使用對應的mfence指令。
加上`-XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -Xcomp`JVM引數再次執行main方法,在列印的彙編碼中,我們也可以看到有一個`lock addl $0x0,(%rsp)`的操作。
而在x86處理器中,有三種方法可以實現實現StoreLoad屏障的效果,分別為:
- mfence指令:上文提到過,能實現全能型屏障,具備lfence和sfence的能力。
- cpuid指令:cpuid操作碼是一個面向x86架構的處理器補充指令,它的名稱派生自CPU識別,作用是允許軟體發現處理器的詳細資訊。
- lock指令字首:匯流排鎖。lock字首只能加在一些特殊的指令前面。
實際上HotSpot關於volatile的實現就是使用的lock指令,只在volatile標記的地方加上帶lock字首指令操作,並沒有參照JMM規範的屏障設計而使用對應的mfence指令。
加上`-XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -Xcomp`JVM引數再次執行main方法,在列印的彙編碼中,我們也可以看到有一個`lock addl $0x0,(%rsp)`的操作。
 在原始碼中也可以得到驗證:
在原始碼中也可以得到驗證:
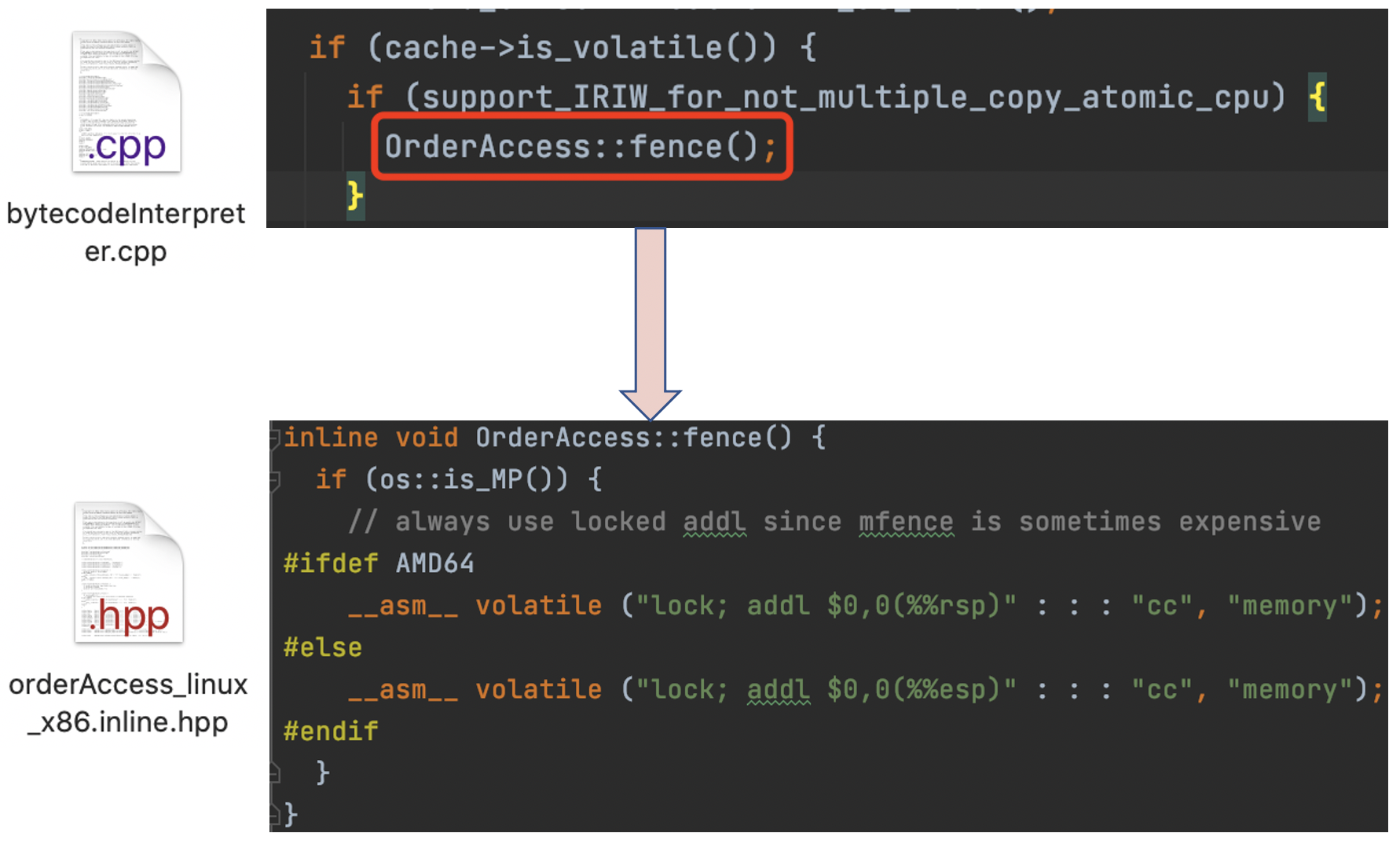 `lock addl $0x0,(%rsp)`後面的`addl $0x0,(%rsp)`其實是一個空操作。add是加的意思,0x0是16進位制的0,rsp是一種型別暫存器,合起來就是把暫存器的值加0,加0是不是等於什麼都沒有做?這段彙編碼僅僅是lock指令的一個載體而已。其實上文也有提到過,lock字首只能加在一些特殊的指令前面,add就是其中一個指令。
至於Hotspot為什麼要使用lock指令而不是mfence指令,按照我的理解,其實就是省事,實現起來簡單。因為lock功能過於強大,不需要有太多的考慮。而且lock指令優先鎖快取行,在效能上,lock指令也沒有想象中的那麼差,mfence指令更沒有想象中的好。所以,使用lock是一個性價比非常高的一個選擇。而且,lock也有對可見性的語義說明。
在《IA-32架構軟體開發人員手冊》的指令表中找到lock:
`lock addl $0x0,(%rsp)`後面的`addl $0x0,(%rsp)`其實是一個空操作。add是加的意思,0x0是16進位制的0,rsp是一種型別暫存器,合起來就是把暫存器的值加0,加0是不是等於什麼都沒有做?這段彙編碼僅僅是lock指令的一個載體而已。其實上文也有提到過,lock字首只能加在一些特殊的指令前面,add就是其中一個指令。
至於Hotspot為什麼要使用lock指令而不是mfence指令,按照我的理解,其實就是省事,實現起來簡單。因為lock功能過於強大,不需要有太多的考慮。而且lock指令優先鎖快取行,在效能上,lock指令也沒有想象中的那麼差,mfence指令更沒有想象中的好。所以,使用lock是一個性價比非常高的一個選擇。而且,lock也有對可見性的語義說明。
在《IA-32架構軟體開發人員手冊》的指令表中找到lock:
 我不打算在這裡深入闡述lock指令的實現原理和細節,這很容易陷入堆砌技術術語中,而且也超出了本文的範圍,有興趣的可以去看看《IA-32架構軟體開發人員手冊》。
我們只需要知道lock的這幾個作用就可以了:
- 確保後續指令執行的原子性。在Pentium及之前的處理器中,帶有lock字首的指令在執行期間會鎖住匯流排,使得其它處理器暫時無法通過匯流排訪問記憶體,很顯然,這個開銷很大。在新的處理器中,Intel使用快取鎖定來保證指令執行的原子性,快取鎖定將大大降低lock字首指令的執行開銷。
- 禁止該指令與前面和後面的讀寫指令重排序。
- 把寫緩衝區的所有資料重新整理到記憶體中。
總結來說,就是lock指令既保證了可見性也保證了原子性。
重要的事情再說一遍,是lock指令既保證了可見性也保證了原子性,和什麼緩衝一致性協議啊,MESI什麼的沒有一點關係。
為了不讓你把快取一致性協議和JMM混淆,在前面的文章中,我特意沒有提到過快取一致性協議,因為這兩者本不是一個維度的東西,存在的意義也不一樣,這一部分,我們下次再聊。
## 總結
全文重點是圍繞volatile的可見性和有序性展開的,其中花了不少的部分篇幅描述了一些計算機底層的概念,對於讀者來說可能過於無趣,但如果你能認真看完,我相信你或多或少也會有一點收穫。
不去深究,volatile只是一個普通的關鍵字。深入探討,你會發現volatile是一個非常重要的知識點。volatile能將軟體和硬體結合起來,想要徹底弄懂,需要深入到計算機的最底層。但如果你做到了。你對Java的認知一定會有進一步的提升。
只把眼光放在Java語言,似乎顯得非常侷限。發散到其他語言,C語言,C++裡面也都有volatile關鍵字。我沒有看過C語言,C++裡面volatile關鍵字是如何實現的,但我相信底層的原理一定是相通的。
## 寫在最後
本著對每一篇發出去的文章負責的原則,文中涉及知識理論,我都會盡量在官方文件和權威書籍找到並加以驗證。但即使這樣,我也不能保證文中每個點都是正確的,如果你發現錯誤之處,歡迎指出,我會對其修正。
創作不易,你的正反饋對我來說非常重要!點個贊,點個再看,點個關注甚至評論區傳送一條666都是對我最大的支援!
我是CoderW,一個普通的程式設計師。
謝謝你的閱讀,我們下期再見!
----
## 參考資料
- JSR-133: http://gee.cs.oswego.edu/dl/jmm/cookbook.html
- 《Java併發程式設計的藝術》
- 《深入理解Java虛擬機器》第三版
- 《IA-32+架構軟體開發人員
我不打算在這裡深入闡述lock指令的實現原理和細節,這很容易陷入堆砌技術術語中,而且也超出了本文的範圍,有興趣的可以去看看《IA-32架構軟體開發人員手冊》。
我們只需要知道lock的這幾個作用就可以了:
- 確保後續指令執行的原子性。在Pentium及之前的處理器中,帶有lock字首的指令在執行期間會鎖住匯流排,使得其它處理器暫時無法通過匯流排訪問記憶體,很顯然,這個開銷很大。在新的處理器中,Intel使用快取鎖定來保證指令執行的原子性,快取鎖定將大大降低lock字首指令的執行開銷。
- 禁止該指令與前面和後面的讀寫指令重排序。
- 把寫緩衝區的所有資料重新整理到記憶體中。
總結來說,就是lock指令既保證了可見性也保證了原子性。
重要的事情再說一遍,是lock指令既保證了可見性也保證了原子性,和什麼緩衝一致性協議啊,MESI什麼的沒有一點關係。
為了不讓你把快取一致性協議和JMM混淆,在前面的文章中,我特意沒有提到過快取一致性協議,因為這兩者本不是一個維度的東西,存在的意義也不一樣,這一部分,我們下次再聊。
## 總結
全文重點是圍繞volatile的可見性和有序性展開的,其中花了不少的部分篇幅描述了一些計算機底層的概念,對於讀者來說可能過於無趣,但如果你能認真看完,我相信你或多或少也會有一點收穫。
不去深究,volatile只是一個普通的關鍵字。深入探討,你會發現volatile是一個非常重要的知識點。volatile能將軟體和硬體結合起來,想要徹底弄懂,需要深入到計算機的最底層。但如果你做到了。你對Java的認知一定會有進一步的提升。
只把眼光放在Java語言,似乎顯得非常侷限。發散到其他語言,C語言,C++裡面也都有volatile關鍵字。我沒有看過C語言,C++裡面volatile關鍵字是如何實現的,但我相信底層的原理一定是相通的。
## 寫在最後
本著對每一篇發出去的文章負責的原則,文中涉及知識理論,我都會盡量在官方文件和權威書籍找到並加以驗證。但即使這樣,我也不能保證文中每個點都是正確的,如果你發現錯誤之處,歡迎指出,我會對其修正。
創作不易,你的正反饋對我來說非常重要!點個贊,點個再看,點個關注甚至評論區傳送一條666都是對我最大的支援!
我是CoderW,一個普通的程式設計師。
謝謝你的閱讀,我們下期再見!
----
## 參考資料
- JSR-133: http://gee.cs.oswego.edu/dl/jmm/cookbook.html
- 《Java併發程式設計的藝術》
- 《深入理解Java虛擬機器》第三版
- 《IA-32+架構軟體開發人員
- `flag`預設為`true`
- 建立一個執行緒A去判斷`flag`是否為`true`,如果為`true`迴圈執行`i++`操作
- 兩秒後,建立另一個執行緒B將`flag`修改為`false`
- 執行緒A沒有感知到`flag`已經被修改成`false`了,不能跳出迴圈
這相當於啥呢?相當於你的女神和你說,你好好努力,年薪百萬了就嫁給你,你聽了之後,努力賺錢。3年之後,你年薪百萬了,回去找你女神,結果發現你女神結婚了,她結婚的訊息根本沒有告訴你!難不難受?
女神結婚可以不告訴你,可是Java程式碼中的屬性都是存在記憶體中,一個執行緒的修改為什麼另一個執行緒為什麼不可見呢?這就不得不提到Java中的記憶體模型了,Java中的記憶體模型,簡稱JMM,JMM定義了執行緒和主記憶體之間的抽象關係,定義了執行緒之間的共享變數儲存在主記憶體中,每個執行緒都有一個私有的本地記憶體,本地記憶體中儲存了該執行緒以讀/寫共享變數的副本,它涵蓋了快取、寫緩衝區、暫存器以及其他的硬體和編譯器優化。
注意!JMM是一個遮蔽了不同作業系統架構的差異的抽象概念,只是一組Java規範。
- 因為執行緒A複製了一份剛開始的`flage=true`到本地記憶體,之後執行緒A使用的`flag`都是這個複製到本地記憶體的flag。
- 執行緒B修改了`flag`之後,將flag的值重新整理到主記憶體,此時主記憶體的flag值變成了`false`。
- 執行緒A是不知道執行緒B修改了`flag`,一直用的是本地記憶體的`flag = true`。
那麼,如何才能讓執行緒A知道flag被修改了呢?或者說怎麼讓執行緒A本地記憶體中快取的flag無效,實現執行緒間可見呢?用volatile修飾flag就可以做到:
可以看到重排序之後CPU實際執行省略了一個讀取和寫回的操作,也就間接的提升了執行效率。
有一點必須強調的是,上圖的例子只是為了讓讀者更好的理解為什麼重排序能提升執行效率,實際上Java裡面的重排序並不是基於程式碼級別的,從程式碼到CPU執行之間還有很多個階段,CPU底層還有一些優化,實際上的執行流程可能並不是上圖的說的那樣。不必過於糾結於此。
重排序可以提高程式的執行效率,但是必須遵循as-if-serial語義。as-if-serial語義是什麼呢?簡單來說,就是不管你怎麼重排序,你必須保證不管怎麼重排序,單執行緒下程式的執行結果不能被改變。
## 有序性
上面我們已經介紹了Java有重排序情況,現在我們再來聊一聊volatile的有序性。
先看一個經典的面試題:為什麼DDL(double check lock)單例模式需要加volatile關鍵字?
總結來說就是:
- 第二個操作是volatile寫,不管第一個操作是什麼都不會重排序
- 第一個操作是volatile讀,不管第二個操作是什麼都不會重排序
- 第一個操作是volatile寫,第二個操作是volatile讀,也不會發生重排序
如何保證這些操作不會發送重排序呢?就是通過插入記憶體屏障保證的,JMM層面的記憶體屏障分為讀(load)屏障和寫(Store)屏障,排列組合就有了四種屏障。對於volatile操作,JMM記憶體屏障插入策略:
- 在每個volatile寫操作的前面插入一個StoreStore屏障
- 在每個volatile寫操作的後面插入一個StoreLoad屏障
- 在每個volatile讀操作的後面插入一個LoadLoad屏障
- 在每個volatile讀操作的後面插入一個LoadStore屏障
上面的屏障都是JMM規範級別的,意思是,按照這個規範寫JDK能保證volatile修飾的記憶體區域的操作不會發送重排序。
在硬體層面上,也提供了一系列的記憶體屏障來提供一致性的能力。拿X86平臺來說,主要提供了這幾種記憶體屏障指令:
- lfence指令:在lfence指令前的讀操作當必須在lfence指令後的讀操作前完成,類似於讀屏障
- sfence指令:在sfence指令前的寫操作當必須在sfence指令後的寫操作前完成,類似於寫屏障
- mfence指令: 在mfence指令前的讀寫操作當必須在mfence指令後的讀寫操作前完成,類似讀寫屏障。
JMM規範需要加這麼多記憶體屏障,但實際情況並不需要加這麼多記憶體屏障。以我們常見的X86處理器為例,X86處理器不會對`讀-讀`、`讀-寫`和`寫-寫`操作做重排序,會省略掉這3種操作型別對應的記憶體屏障,僅會對`寫-讀`操作做重排序。所以volatile`寫-讀`操作只需要在volatile寫後插入StoreLoad屏障。在《The JSR-133 Cookbook for Compiler Writers》中,也很明確的指出了這一點:
而在x86處理器中,有三種方法可以實現實現StoreLoad屏障的效果,分別為:
- mfence指令:上文提到過,能實現全能型屏障,具備lfence和sfence的能力。
- cpuid指令:cpuid操作碼是一個面向x86架構的處理器補充指令,它的名稱派生自CPU識別,作用是允許軟體發現處理器的詳細資訊。
- lock指令字首:匯流排鎖。lock字首只能加在一些特殊的指令前面。
實際上HotSpot關於volatile的實現就是使用的lock指令,只在volatile標記的地方加上帶lock字首指令操作,並沒有參照JMM規範的屏障設計而使用對應的mfence指令。
加上`-XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -Xcomp`JVM引數再次執行main方法,在列印的彙編碼中,我們也可以看到有一個`lock addl $0x0,(%rsp)`的操作。
在原始碼中也可以得到驗證:
`lock addl $0x0,(%rsp)`後面的`addl $0x0,(%rsp)`其實是一個空操作。add是加的意思,0x0是16進位制的0,rsp是一種型別暫存器,合起來就是把暫存器的值加0,加0是不是等於什麼都沒有做?這段彙編碼僅僅是lock指令的一個載體而已。其實上文也有提到過,lock字首只能加在一些特殊的指令前面,add就是其中一個指令。
至於Hotspot為什麼要使用lock指令而不是mfence指令,按照我的理解,其實就是省事,實現起來簡單。因為lock功能過於強大,不需要有太多的考慮。而且lock指令優先鎖快取行,在效能上,lock指令也沒有想象中的那麼差,mfence指令更沒有想象中的好。所以,使用lock是一個性價比非常高的一個選擇。而且,lock也有對可見性的語義說明。
在《IA-32架構軟體開發人員手冊》的指令表中找到lock:
我不打算在這裡深入闡述lock指令的實現原理和細節,這很容易陷入堆砌技術術語中,而且也超出了本文的範圍,有興趣的可以去看看《IA-32架構軟體開發人員手冊》。
我們只需要知道lock的這幾個作用就可以了:
- 確保後續指令執行的原子性。在Pentium及之前的處理器中,帶有lock字首的指令在執行期間會鎖住匯流排,使得其它處理器暫時無法通過匯流排訪問記憶體,很顯然,這個開銷很大。在新的處理器中,Intel使用快取鎖定來保證指令執行的原子性,快取鎖定將大大降低lock字首指令的執行開銷。
- 禁止該指令與前面和後面的讀寫指令重排序。
- 把寫緩衝區的所有資料重新整理到記憶體中。
總結來說,就是lock指令既保證了可見性也保證了原子性。
重要的事情再說一遍,是lock指令既保證了可見性也保證了原子性,和什麼緩衝一致性協議啊,MESI什麼的沒有一點關係。
為了不讓你把快取一致性協議和JMM混淆,在前面的文章中,我特意沒有提到過快取一致性協議,因為這兩者本不是一個維度的東西,存在的意義也不一樣,這一部分,我們下次再聊。
## 總結
全文重點是圍繞volatile的可見性和有序性展開的,其中花了不少的部分篇幅描述了一些計算機底層的概念,對於讀者來說可能過於無趣,但如果你能認真看完,我相信你或多或少也會有一點收穫。
不去深究,volatile只是一個普通的關鍵字。深入探討,你會發現volatile是一個非常重要的知識點。volatile能將軟體和硬體結合起來,想要徹底弄懂,需要深入到計算機的最底層。但如果你做到了。你對Java的認知一定會有進一步的提升。
只把眼光放在Java語言,似乎顯得非常侷限。發散到其他語言,C語言,C++裡面也都有volatile關鍵字。我沒有看過C語言,C++裡面volatile關鍵字是如何實現的,但我相信底層的原理一定是相通的。
## 寫在最後
本著對每一篇發出去的文章負責的原則,文中涉及知識理論,我都會盡量在官方文件和權威書籍找到並加以驗證。但即使這樣,我也不能保證文中每個點都是正確的,如果你發現錯誤之處,歡迎指出,我會對其修正。
創作不易,你的正反饋對我來說非常重要!點個贊,點個再看,點個關注甚至評論區傳送一條666都是對我最大的支援!
我是CoderW,一個普通的程式設計師。
謝謝你的閱讀,我們下期再見!
----
## 參考資料
- JSR-133: http://gee.cs.oswego.edu/dl/jmm/cookbook.html
- 《Java併發程式設計的藝術》
- 《深入理解Java虛擬機器》第三版
- 《IA-32+架構軟體開發人員