
為了加快速度,Redis都做了哪些“變態”設計
阿新 • • 發佈:2021-01-18
# 前言
列表物件是 `Redis` 中 `5` 種基礎資料型別之一,在 `Redis 3.2` 版本之前,列表物件底層儲存結構有兩種:`linkedlist`(雙端列表)和 `ziplist`(壓縮列表),而在 `Redis 3.2` 版本之後,列表物件底層儲存結構只有一種:`quicklist`(快速列表),難道通過精心設計的 `ziplist` 最終被 `Redis` 拋棄了嗎?
# 列表物件
同字串物件一樣,列表物件到底使用哪一種資料結構來進行儲存也是通過編碼來進行區分:
| 編碼屬性 | 描述 | object encoding命令返回值 |
| ----------------------- | ------------------------------ | ------------------------- |
| OBJ_ENCODING_LINKEDLIST | 使用 `linkedlist` 實現列表物件 | linkedlist |
| OBJ_ENCODING_ZIPLIST | 使用 `ziplist` 實現列表物件 | ziplist |
| OBJ_ENCODING_QUICKLIST | 使用 `quicklist` 實現列表物件 | quicklist |
## linkedlist
`linkedlist` 是一個雙向列表,每個節點都會儲存指向上一個節點和指向下一個節點的指標。`linkedlist` 因為每個節點之間的空間是不連續的,所以可能會造成過多的記憶體空間碎片。
### linkedlist儲存結構
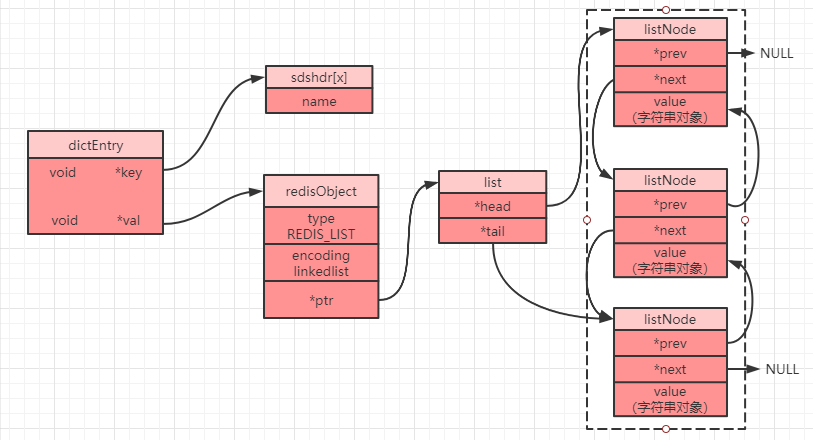
連結串列中每一個節點都是一個 `listNode` 物件(原始碼 `adlist.h` 內),不過需要注意的是,列表中的 `value` 其實也是一個字串物件,其他幾種資料型別其內部最終也是會巢狀字串物件,字串物件也是唯一一種會被其他物件引用的基本型別:
```c
typedef struct listNode {
struct listNode *prev;//前一個節點
struct listNode *next;//後一個節點
void *value;//值(字串物件)
} listNode;
```
然後會將其再進行封裝成為一個 `list` 物件(原始碼 `adlist.h` 內):
```c
typedef struct list {
listNode *head;//頭節點
listNode *tail;//尾節點
void *(*dup)(void *ptr);//節點值複製函式
void (*free)(void *ptr);//節點值釋放函式
int (*match)(void *ptr, void *key);//節點值對比函式
unsigned long len;//節點數量
} list;
```
`Redis` 中對 `linkedlist` 的訪問是以 `NULL` 值為終點的,因為 `head` 節點的 `prev` 節點為 `NULL`,`tail` 節點的 `next` 節點也為 `NULL`,所以從頭節點開始遍歷,當發現 `tail` 為 `NULL` 時,則可以認為已經到了列表末尾。
當我們設定一個列表物件時,在 `Redis 3.2` 版本之前我們可以得到如下儲存示意圖:
## ziplist
壓縮列表在前面已經介紹過,想要詳細瞭解的可以[點選這裡](https://www.cnblogs.com/lonely-wolf/p/14281136.html)。
## linkedlist 和 ziplist 的選擇
在 `Redis3.2` 之前,`linkedlist` 和 `ziplist` 兩種編碼可以進選擇切換,如果需要列表使用 `ziplist` 編碼進行儲存,則必須滿足以下兩個條件:
- 列表物件儲存的所有字串元素的長度都小於 `64` 位元組。
- 列表物件儲存的元素數量小於 `512` 個。
一旦不滿足這兩個條件的任意一個,則會使用 `linkedlist` 編碼進行儲存。
PS:這兩個條件可以通過引數 `list-max-ziplist-value` 和 `list-max-ziplist-entries` 進行修改。
這兩種列表能在特定的場景下發揮各自的作用,應該來說已經能滿足大部分需求了,然後 `Redis` 並不滿足於此,於是一場改革引發了,`quicklist` 橫空出世。
## quicklist
在 `Redis 3.2` 版本之後,為了進一步提升 `Redis` 的效能,列表物件統一採用 `quicklist` 來儲存列表物件。`quicklist`儲存了一個雙向列表,每個列表的節點是一個 `ziplist`,所以實際上 `quicklist` 並不是一個新的資料結構,它就是`linkedlist` 和 `ziplist` 的結合,然後被命名為快速列表。
### quicklist 內部儲存結構
`quicklist` 中每一個節點都是一個 `quicklistNode` 物件,其資料結構定義如下:
```c
typedef struct quicklistNode {
struct quicklistNode *prev;//前一個節點
struct quicklistNode *next;//後一個節點
unsigned char *zl;//當前指向的ziplist或者quicklistLZF
unsigned int sz;//當前ziplist佔用位元組
unsigned int count : 16;//ziplist中儲存的元素個數,16位元組(最大65535個)
unsigned int encoding : 2; //是否採用了LZF壓縮演算法壓縮節點 1:RAW 2:LZF
unsigned int container : 2; //儲存結構,NONE=1, ZIPLIST=2
unsigned int recompress : 1; //當前ziplist是否需要再次壓縮(如果前面被解壓過則為true,表示需要再次被壓縮)
unsigned int attempted_compress : 1;//測試用
unsigned int extra : 10; //後期留用
} quicklistNode;
```
然後各個 `quicklistNode` 就構成了一個快速列表 `quicklist`:
```c
typedef struct quicklist {
quicklistNode *head;//列表頭節點
quicklistNode *tail;//列表尾節點
unsigned long count;//ziplist中一共儲存了多少元素,即:每一個quicklistNode內的count相加
unsigned long len; //雙向連結串列的長度,即quicklistNode的數量
int fill : 16;//填充因子
unsigned int compress : 16;//壓縮深度 0-不壓縮
} quicklist;
```
根據這兩個結構,我們可以得到 `Redis 3.2` 版本之後的列表物件的一個儲存結構示意圖:

### quicklist 的 compress 屬性
`compress` 是用來表示壓縮深度,`ziplist` 除了記憶體空間是連續之外,還可以採用特定的 `LZF` 壓縮演算法來將節點進行壓縮儲存,從而更進一步的節省空間,壓縮深度可以通過引數 `list-compress-depth` 控制:
- 0:不壓縮(預設值)
- 1:首尾第1個元素不壓縮
- 2:首位前2個元素不壓縮
- 3:首尾前3個元素不壓縮
- 以此類推
注意:之所以採取這種壓縮兩端節點的方式是因為很多場景都是兩端的元素訪問率最高的,而中間元素訪問率相對較低,所以在實際使用時,我們可以根據自己的實際情況選擇是否進行壓縮,以及具體的壓縮深度。
### quicklistNode 的 zl 指標
`zl` 指標預設指向了 `ziplist`,上面提到 `quicklistNode` 中有一個 `sz` 屬性記錄了當前 `ziplist` 佔用的位元組,不過這僅僅限於當前節點沒有被壓縮(通過`LZF` 壓縮演算法)的情況,如果當前節點被壓縮了,那麼被壓縮節點的 `zl` 指標會指向另一個物件 `quicklistLZF`,而不會直接指向 `ziplist`。`quicklistLZF` 是一個 `4+N` 位元組的結構:
```c
typedef struct quicklistLZF {
unsigned int sz;// LZF大小,佔用4位元組
char compressed[];//被壓縮的內容,佔用N位元組
} quicklistLZF;
```
### quicklist 對比原始兩種編碼的改進
`quicklist` 同樣採用了 `linkedlist` 的雙端列表特性,然後 `quicklist` 中的每個節點又是一個 `ziplist`,所以`quicklist` 就是綜合平衡考慮了 `linkedlist` 容易產生空間碎片的問題和 `ziplist` 的讀寫效能兩個維度而設計出來的一種資料結構。使用 `quicklist` 需要注意以下 `2` 點:
- 如果 `ziplist` 中的 `entry` 個數過少,最極端情況就是隻有 `1` 個 `entry` 的壓縮列表,那麼此時 `quicklist` 就相當於退化成了一個普通的 `linkedlist`。
- 如果 `ziplist` 中的 `entry` 過多,那麼也會導致一次性需要申請的記憶體空間過大(`ziplist` 空間是連續的),而且因為 `ziplist` 本身的就是以時間換空間,所以會過多 `entry` 也會影響到列表物件的讀寫效能。
`ziplist` 中的 `entry` 個數可以通過引數 `list-max-ziplist-size` 來控制:
```java
list-max-ziplist-size 1
```
注意:這個引數可以配置正數也可以配置負數。正數表示限制每個節點中的 `entry` 數量,如果是負數則只能為 `-1~-5`,其代表的含義如下:
- -1:每個 `ziplist` 最多隻能為 `4KB`
- -2:每個 `ziplist` 最多隻能為 `8KB`
- -3:每個 `ziplist` 最多隻能為 `16KB`
- -4:每個 `ziplist` 最多隻能為 `32KB`
- -5:每個 `ziplist` 最多隻能為 `64KB`
## 列表物件常用操作命令
- lpush key value1 value2:將一個或者多個 `value` 插入到列表 `key` 的頭部,`key` 不存在則建立 `key`(`value2` 在`value1` 之後)。
- lpushx key value1 value2:將一個或者多個 `value` 插入到列表 `key` 的頭部,`key` 不存在則不做任何處理(`value2` 在`value1` 之後)。
- lpop key:移除並返回 `key` 值的列表頭元素。
- rpush key value1 value2:將一個或者多個 `value` 插入到列表 `key` 的尾部,`key` 不存在則建立 `key`(`value2` 在`value1` 之後)。
- rpushx key value1 vaue2:將一個或者多個 `value` 插入到列表 `key` 的尾部,`key` 不存在則不做任何處理(`value2` 在`value1` 之後)。
- rpop key:移除並返回列表 `key` 的尾元素。
- llen key:返回列表 `key` 的長度。
- lindex key index:返回列表 `key` 中下標為 `index` 的元素。`index` 為正數(從 `0` 開始)表示從隊頭開始算,`index` 為負數(從-1開始)則表示從隊尾開始算。
- lrange key start stop:返回列表 `key` 中下標 `[start,end]` 之間的元素。
- lset key index value:將 `value` 設定到列表 `key` 中指定 `index` 位置,`key` 不存在或者 `index` 超出範圍則會報錯。
- ltrim key start end:擷取列表中 `[start,end]` 之間的元素,並替換原列表儲存。
瞭解了操作列表物件的常用命令,我們就可以來驗證下前面提到的列表物件的型別和編碼了,在測試之前為了防止其他 `key` 值的干擾,我們先執行 `flushall` 命令清空 `Redis` 資料庫。
接下來依次輸入命令:
- `lpush name zhangsan`
- `type name`
- `object encoding name`

可以看到,通過 `type` 命令輸出的是 `list`,說明當前 `name` 存的是一個列表物件,並且編碼是 `quicklist`(示例中用的是 `5.0.5` 版本)。
# 總結
本文主要介紹了 `Redis` 中 `5` 種常用資料型別中的 列表物件,並介紹了底層的儲存結構 `quicklist`,並分別對舊版本的兩種底層資料 `linkedlist` 和 `ziplist` 進行了分析對比得出了為什麼 `Redis` 最終要採用 `quicklist` 來儲存列表