
被叢集節點負載不均所困擾?TKE 重磅推出全鏈路排程解決方案
阿新 • • 發佈:2021-01-22
# 引言
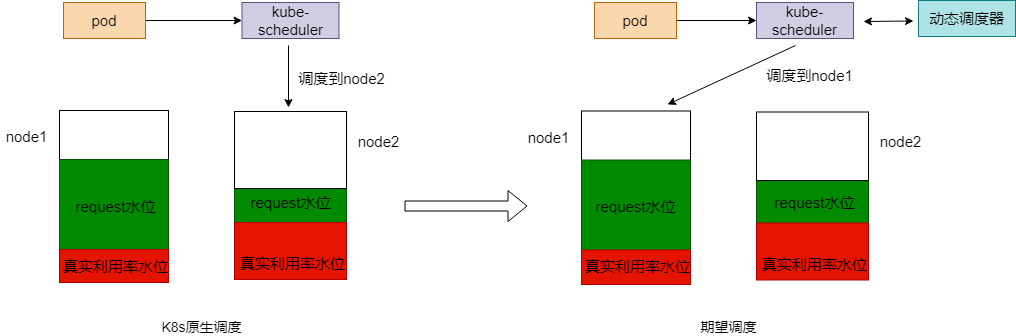
在 K8s 叢集運營過程中,常常會被節點 CPU 和記憶體的高使用率所困擾,既影響了節點上 Pod 的穩定執行,也會增加節點故障的機率。為了應對叢集節點高負載的問題,平衡各個節點之間的資源使用率,應該基於節點的實際資源利用率監控資訊,從以下兩個策略入手:
- 在 Pod 排程階段,應當優先將 Pod 排程到資源利用率低的節點上執行,不排程到資源利用率已經很高的節點上
- 在監控到節點資源率較高時,可以自動干預,遷移節點上的一些 Pod 到利用率低的節點上
為此,我們提供 **動態排程器 + Descheduler** 的方案來實現,目前在公有云 TKE 叢集內【元件管理】- 【排程】分類下已經提供這兩個外掛的安裝入口,文末還針對具體的客戶案例提供了最佳實踐的例子。
# 動態排程器
原生的 Kubernetes 排程器有一些很好的排程策略用來應對節點資源分配不均的問題,比如 BalancedResourceAllocation,但是存在一個問題是這樣的資源分配是靜態的,不能代表資源真實使用情況,節點的 **CPU/記憶體利用率** 經常處於不均衡的狀態。所以,需要有一種策略可以基於節點的實際資源利用率進行排程。動態排程器所做的就是這樣的工作。
## 技術原理
原生 K8s 排程器提供了 scheduler extender 機制來提供排程擴充套件的能力。相比修改原生 scheduler 程式碼新增策略,或者實現一個自定義的排程器,使用 scheduler extender 的方式侵入性更少,實現更加靈活。所以我們選擇基於 scheduler extender 的方式來新增基於節點的實際資源利用率進行排程的策略。
scheduler extender 可以在原生排程器的預選和優選階段加入自定義的邏輯,提供和原生排程器內部策略同樣的效果。
## 架構

- **node-annotator**:負責拉取 Prometheus 中的監控資料,定期同步到 Node 的 annotation 裡面,同時負責其他邏輯,如動態排程器排程有效性衡量指標,防止排程熱點等邏輯。
- **dynamic-scheduler**:負責 scheduler extender 的優選和預選介面邏輯實現,在預選階段過濾掉資源利用率高於閾值的節點,在優選階段優先選擇資源利用率低的節點進行排程。
## 實現細節
1. **動態排程器的策略在優選階段的權重如何配置?**
原生排程器的排程策略在優選階段有一個權重配置,每個策略的評分乘以權重得到該策略的總得分。對權重越高的策略,符合條件的節點越容易排程上。預設所有策略配置權重為 1,為了提升動態排程器策略的效果,我們把動態排程器優選策略的權重設定為 2。
2. **動態排程器如何防止排程熱點?**
在叢集中,如果出現一個新增的節點,為了防止新增的節點排程上過多的節點,我們會通過監聽排程器排程成功事件,獲取排程結果,標記每個節點過去一段時間的排程 Pod 數,比如 1min、5min、30min 內的排程 Pod 數量,衡量節點的熱點值然後補償到節點的優選評分中。
## 產品能力
### 元件依賴
元件依賴較少,僅依賴基礎的節點監控元件 node-exporter 和 Prometheus。Prometheus 支援託管和自建兩種方式,使用託管方式可以一鍵安裝動態排程器,而使用自建 Prometheus 也提供了監控指標配置方法。
### 元件配置
排程策略目前可以基於 CPU 和記憶體兩種資源利用率。
#### 預選階段

配置節點 5分鐘內 CPU 利用率、1小時內最大 CPU 利用率,5分鐘內平均記憶體利用率,1小時內最大記憶體利用率的閾值,超過了就會在預選階段過濾節點。
#### 優選階段

動態排程器優選階段的評分根據截圖中 6個指標綜合評分得出,6個指標各自的權重表示優選時更側重於哪個指標的值,使用 1h 和 1d 內最大利用率的意義是要記錄節點 1h 和 1d 內的利用率峰值,因為有的業務 Pod 的峰值週期可能是按照小時或者天,避免排程新的 Pod 時導致在峰值時間節點的負載進一步升高。
### 產品效果
為了衡量動態排程器對增強 Pod 排程到低負載節點的提升效果,結合排程器的實際排程結果,獲取所有排程到的節點在排程時刻的的 CPU/記憶體利用率以後統計以下幾個指標:
- **cpu_utilization_total_avg** :所有排程到的節點 CPU 利用率平均值。
- **memory_utilization_total_avg** :所有排程到的節點記憶體利用率平均值。
- **effective_dynamic_schedule_count** :有效排程次數,當排程到節點的 CPU 利用率小於當前所有節點 CPU 利用率的中位數,我們認為這是一次有效排程,effective_dynamic_schedule_count 加 0.5分,對記憶體也是同理。
- **total_schedule_count** :所有排程次數,每次新的排程累加1。
- **effective_schedule_ratio** :有效排程比率,即 effective_dynamic_schedule_count/total_schedule_count
下面是在同一叢集中不開啟動態排程和開啟動態排程各自執行一週的指標變化,可以看到對於叢集排程的增強效果。
| 指標 | 未開啟動態排程 | 開啟動態排程 |
| -------------------------------- | -------------- | ------------ |
| cpu_utilization_total_avg | 0.30 | 0.17 |
| memory_utilization_total_avg | 0.28 | 0.23 |
| effective_dynamic_schedule_count | 2160 | 3620 |
| total_schedule_count | 7860 | 7470 |
| effective_schedule_ratio | 0.273 | 0.486 |
# Descheduler
現有的叢集排程場景都是一次性排程,即一錘子買賣。後續出現節點 CPU 和記憶體利用率過高,也無法自動調整 Pod 的分佈,除非觸發節點的 eviction manager 後驅逐,或者人工干預。這樣在節點 CPU/記憶體利用率高時,影響了節點上所有 Pod 的穩定性,而且負載低的節點資源還被浪費。
針對此場景,借鑑 K8s 社群 Descheduler 重排程的設計思想,給出基於各節點 CPU/記憶體實際利用率進行驅逐的策略。
## 架構
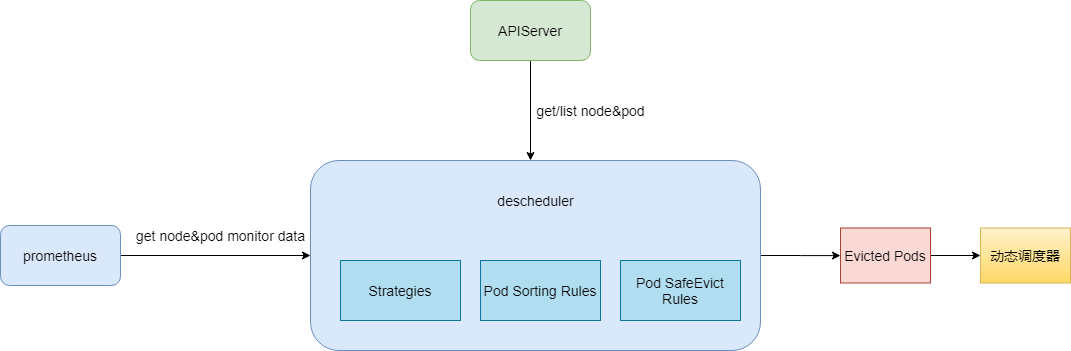
Descheduler 從 apiserver 中獲取 Node 和 Pod 資訊,從 Prometheus 中獲取 Node 和 Pod 監控資訊,然後經過Descheduler 的驅逐策略,驅逐 CPU/記憶體使用率高的節點上的 Pod ,同時我們加強了 Descheduler 驅逐 Pod 時的排序規則和檢查規則,確保驅逐 Pod 時服務不會出現故障。驅逐後的 Pod 經過動態排程器的排程會被排程到低水位的節點上,實現降低高水位節點故障率,提升整體資源利用率的目的。
## 產品能力
### 產品依賴
依賴基礎的節點監控元件 node-exporter 和Prometheus。Prometheus 支援託管和自建兩種方式,使用託管方式可以一鍵安裝 Descheduler,使用自建 Prometheus 也提供了監控指標配置方法。
### 元件配置
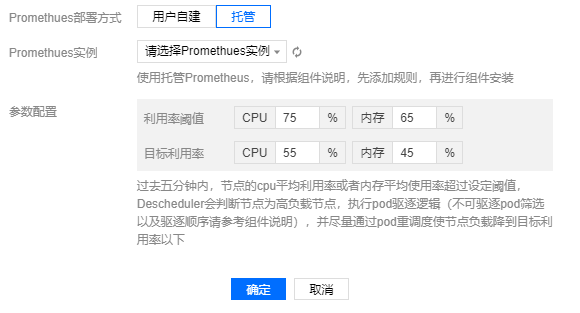
Descheduler 根據使用者配置的利用率閾值,超過閾值水位後開始驅逐 Pod ,使節點負載儘量降低到目標利用率水位以下。
### 產品效果
#### 通過 K8s 事件
通過 K8s 事件可以看到 Pod 被重排程的資訊,所以可以開啟叢集事件持久化功能來檢視 Pod 驅逐歷史。

#### 節點負載變化
在類似如下節點 CPU 使用率監控檢視內,可以看到在開始驅逐之後,節點的 CPU 利用率下降。

# 最佳實踐
## 叢集狀態
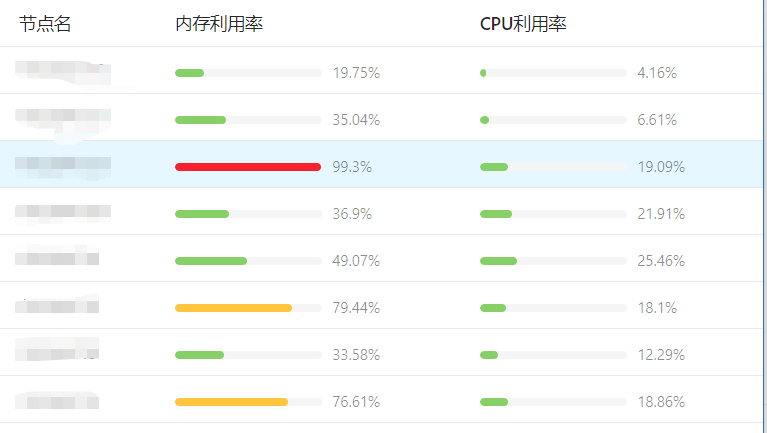
拿一個客戶的叢集為例,由於客戶的業務大多是記憶體消耗型的,所以更容易出現記憶體利用率很高的節點,各個節點的記憶體利用率也很不平均,未使用動態排程器之前的各個節點監控是這樣的:
## 動態排程器配置
配置預選和優選階段的引數如下:

在預選階段過濾掉 5分鐘內平均記憶體利用率超過 60%或者 1h內最大記憶體利用率超過 70%的節點,即 Pod 不會排程到這些這些節點上。
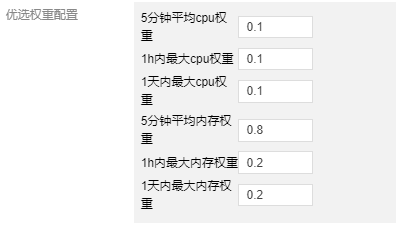
在優選階段將 5分鐘平均記憶體利用率權重配置為 0.8,1h 和1d 內最大記憶體利用率權重配置為 0.2、0.2,而將 CPU 的指標權重都配置為 0.1。這樣優選時更優先選擇排程到記憶體利用率低的節點上。
## Descheduler配置

配置 Descheduler 的引數如下,當節點記憶體利用率超過 80%這個閾值的時候,Descheduler 開始對節點上的 Pod 進行驅逐,儘量使節點記憶體利用率降低到目標值 60% 為止。
## 叢集優化後狀態
通過以上的配置,執行一段時間後,叢集內各節點的記憶體利用率資料如下,可以看到叢集節點的記憶體利用率分佈已經趨向於均衡:

>【騰訊雲原生】雲說新品、雲研新術、雲遊新活、雲賞資訊,掃碼關注同名公眾號,及時獲取更多幹貨!!
