
深入理解原子操作的本質
阿新 • • 發佈:2021-01-23
原文地址:[https://blog.fanscore.cn/p/34/](https://blog.fanscore.cn/p/34/)
# 引言
本文以go1.14 darwin/amd64中的原子操作為例,探究原子操作的彙編實現,引出`LOCK`**指令字首**、**可見性**、**MESI協議**、**Store Buffer**、**Invalid Queue**、**記憶體屏障**,通過對CPU體系結構的探究,從而理解以上概念,並在最終給出一些事實。
# Go中的原子操作
我們以`atomic.CompareAndSwapInt32`為例,它的函式原型是:
```
func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool)
```
對應的彙編程式碼為:
```
// sync/atomic/asm.s 24行
TEXT ·CompareAndSwapInt32(SB),NOSPLIT,$0
JMP runtime∕internal∕atomic·Cas(SB)
```
通過跳轉指令JMP跳轉到了`runtime∕internal∕atomic·Cas(SB)`,由於架構的不同對應的彙編程式碼也不同,我們看下amd64平臺對應的程式碼:
```
// runtime/internal/atomic/asm_amd64.s 17行
TEXT runtime∕internal∕atomic·Cas(SB),NOSPLIT,$0-17
MOVQ ptr+0(FP), BX // 將函式第一個實參即addr載入到BX暫存器
MOVL old+8(FP), AX // 將函式第二個實參即old載入到AX暫存器
MOVL new+12(FP), CX // // 將函式第一個實參即new載入到CX暫存器
LOCK // 本文關鍵指令,下面會詳述
CMPXCHGL CX, 0(BX) // 把AX暫存器中的內容(即old)與BX暫存器中地址資料(即addr)指向的資料做比較如果相等則把第一個運算元即CX中的資料(即new)賦值給第二個運算元
SETEQ ret+16(FP) // SETEQ與CMPXCHGL配合使用,在這裡如果CMPXCHGL比較結果相等則設定本函式返回值為1,否則為0(16(FP)是返回值即swapped的地址)
RET // 函式返回
```
從上面程式碼中可以看到本文的關鍵:`LOCK`。它實際是一個指令字首,它後面必須跟`read-modify-write`指令,比如:`ADD, ADC, AND, BTC, BTR, BTS, CMPXCHG, CMPXCH8B, CMPXCHG16B, DEC, INC, NEG, NOT, OR, SBB, SUB, XOR, XADD, XCHG`。
# LOCK實現原理
在早期CPU上LOCK指令會鎖匯流排,即其他核心不能再通過匯流排與記憶體通訊,從而實現該核心對記憶體的獨佔。
這種做法雖然解決了問題但是效能太差,所以在Intel P6 CPU(P6是一個架構,並非具體CPU)引入一個優化:如果資料已經快取在CPU cache中,則鎖快取,否則還是鎖匯流排。
# Cache Coherency
[CPU Cache與False Sharing](https://blog.fanscore.cn/p/25/) 一文中詳細介紹了CPU快取的結構,CPU快取帶來了一致性問題,舉個簡單的例子:
```
// 假設CPU0執行了該函式
var a int = 0
go func fnInCpu0() {
time.Sleep(1 * time.Second)
a = 1 // 2. 在CPU1載入完a之後CPU0僅修改了自己核心上的cache但是沒有同步給CPU1
}()
// CPU1執行了該函式
go func fnInCpu1() {
fmt.Println(a) // 1. CPU1將a載入到自己的cache,此時a=0
time.Sleep(3 * time.Second)
fmt.Println(a) // 3. CPU1從cache中讀到a=0,但此時a已經被CPU0修改為0了
}()
```
上例中由於CPU沒有保證快取的一致性,導致了兩個核心之間的同一資料不可見從而程式出現了問題,所以CPU必須保證快取的一致性,下面將介紹CPU是如何通過**MESI協議**做到快取一致的。
MESI是以下四種cacheline狀態的簡稱:
* M(Modified):此狀態為該cacheline被該核心修改,並且保證不會在其他核心的cacheline上
* E(Exclusive):標識該cacheline被該核心獨佔,其他核心上沒有該行的副本。該核心可直接修改該行而不用通知其他核心。
* S(Share):該cacheline存在於多個核心上,但是沒有修改,當前核心不能直接修改,修改該行必須與其他核心協商。
* I(Invaild):該cacheline無效,cacheline的初始狀態,說明要麼不在快取中,要麼內容已過時。
核心之間協商通訊需要以下訊息機制:
* Read: CPU發起資料讀取請求,請求中包含資料的地址
* Read Response: Read訊息的響應,該訊息有可能是記憶體響應的,有可能是其他核心響應的(即該地址存在於其他核心上cacheline中,且狀態為Modified,這時必須返回最新資料)
* Invalidate: 核心通知其他核心將它們自己核心上對應的cacheline置為Invalid
* Invalidate ACK: 其他核心對Invalidate通知的響應,將對應cacheline置為Invalid之後發出該確認訊息
* Read Invalidate: 相當於Read訊息+Invalidate訊息,即當前核心要讀取資料並修改該資料。
* Write Back: 寫回,即將Modified的資料寫回到低一級儲存器中,寫回會盡可能地推遲記憶體更新,只有當替換演算法要驅逐更新過的塊時才寫回到低一級儲存器中。
### 手畫狀態轉移圖
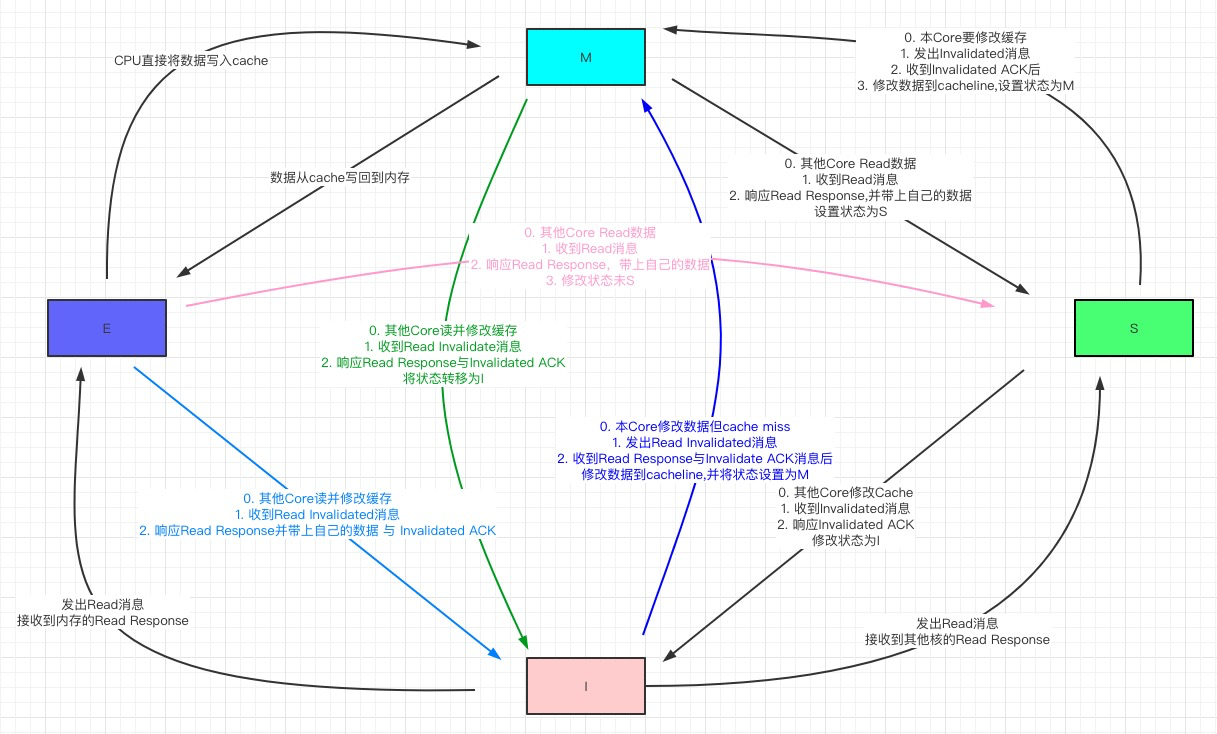
> 這裡有個存疑的地方:CPU從記憶體中讀到資料I狀態是轉移到S還是E,查資料時兩種說法都有。個人認為應該是E,因為這樣另外一個核心要載入副本時只需要去當前核心上取就行了不需要讀記憶體,效能會更高些,如果你有不同看法歡迎在評論區交流。
### 一些規律
1. CPU在修改cacheline時要求其他持有該cacheline副本的核心失效,並通過`Invalidate ACK`來接收反饋
2. cacheline為M意味著記憶體上的資料不是最新的,最新的資料在該cacheline上
3. 資料在cacheline時,如果狀態為E,則直接修改;如果狀態為S則需要廣播`Invalidate`訊息,收到`Invalidate ACK`後修改狀態為M;如果狀態為I(包括cache miss)則需要發出`Read Invalidate`
# Store Buffer
當CPU要修改一個S狀態的資料時需要發出Invalidate訊息並等待ACK才寫資料,這個過程顯然是一個同步過程,但這對於對計算速度要求極高的CPU來說顯然是不可接受的,必須對此優化。
因此我們考慮在CPU與cache之間加一個buffer,CPU可以先將資料寫入到這個buffer中併發出訊息,然後它就可以去做其他事了,待訊息響應後再從buffer寫入到cache中。但這有個明顯的邏輯漏洞,考慮下這段程式碼:
```
a = 1
b = a + 1
```
假設a初始值為0,然後CPU執行`a=1`,資料被寫入Store Buffer還沒有落地就緊接著執行了`b=a+1`,這時由於a還沒有修改落地,因此CPU讀到的還是0,最終計算出來b=1。
為了解決這個明顯的邏輯漏洞,又提出了**Store Forwarding**:CPU可以把Buffer讀出來傳遞(forwarding)給下面的讀取操作,而不用去cache中讀。
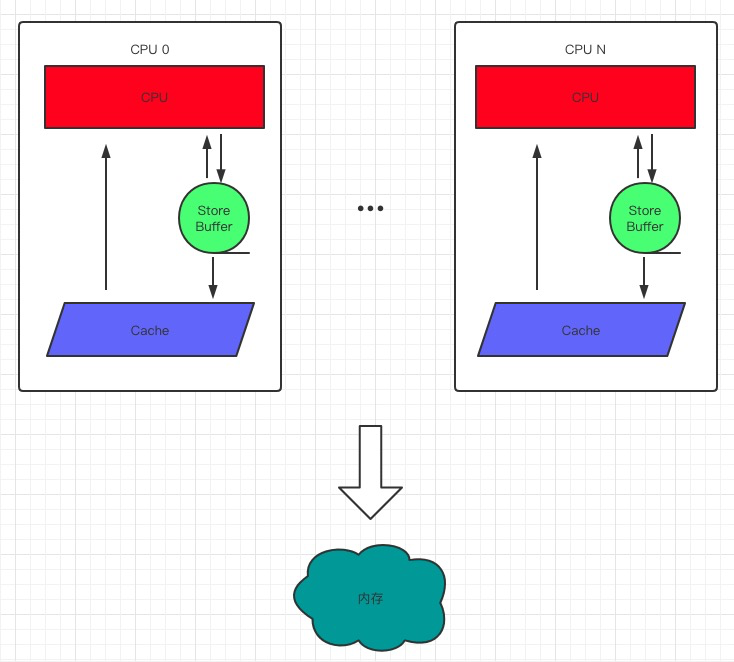
這倒是解決了上面的漏洞,但是還存在另外一個問題,我們看下面這段程式碼:
```
a = 0
flag = false
func runInCpu0() {
a = 1
flag = true
}
func runInCpu1() {
while (!flag) {
continue
}
print(a)
}
```
對於上面的程式碼我們假設有如下執行步驟:
1. 假定當前a存在於cpu1的cache中,flag存在於cpu0的cache中,狀態均為E。
2. cpu1先執行while(!flag),由於flag不存在於它的cache中,所以它發出Read flag訊息
3. cpu0執行a=1,它的cache中沒有a,因此它將a=1寫入Store Buffer,併發出Invalidate a訊息
4. cpu0執行flag=true,由於flag存在於它的cache中並且狀態為E,所以將flag=true直接寫入到cache,狀態修改為M
5. cpu0接收到Read flag訊息,將cache中的flag=true發回給cpu1,狀態修改為S
6. cpu1收到cpu0的Read Response:flat=true,結束while(!flag)迴圈
7. cpu1列印a,由於此時a存在於它的cache中a=0,所以打印出來了0
8. cpu1此時收到Invalidate a訊息,將cacheline狀態修改為I,但為時已晚
9. cpu0收到Invalidate ACK,將Store Buffer中的資料a=1刷到cache中
從程式碼角度看,我們的程式碼好像變成了
```
func runInCpu0() {
flag = true
a = 1
}
```
好像是被重新排序了,這其實是一種 **偽重排序**,必須提出新的辦法來解決上面的問題
# 寫屏障
CPU從軟體層面提供了 **寫屏障(write memory barrier)** 指令來解決上面的問題,linux將CPU寫屏障封裝為smp_wmb()函式。寫屏障解決上面問題的方法是先將當前Store Buffer中的資料刷到cache後再執行屏障後面的寫入操作。
> SMP: Symmetrical Multi-Processing,即多處理器。
這裡你可能好奇上面的問題是硬體問題,CPU為什麼不從硬體上自己解決問題而要求軟體開發者通過指令來避免呢?其實很好回答:CPU不能為了這一個方面的問題而拋棄Store Buffer帶來的巨大效能提升,就像CPU不能因為分支預測錯誤會損耗效能增加功耗而放棄分支預測一樣。
還是以上面的程式碼為例,前提保持不變,這時我們加入寫屏障:
```
a = 0
flag = false
func runInCpu0() {
a = 1
smp_wmb()
flag = true
}
func runInCpu1() {
while (!flag) {
continue
}
print(a)
}
```
當cpu0執行flag=true時,由於Store Buffer中有a=1還沒有刷到cache上,所以會先將a=1刷到cache之後再執行flag=true,當cpu1讀到flag=true時,a也就=1了。
> 有文章指出CPU還有一種實現寫屏障的方法:CPU將當前store buffer中的條目打標,然後將屏障後的“寫入操作”也寫到Store Buffer中,cpu繼續幹其他的事,當被打標的條目全部刷到cache中,之後再刷後面的條目。
# Invalid Queue
上文通過寫屏障解決了偽重排序的問題後,還要思考另一個問題,那就是Store Buffer size是有限的,當Store Buffer滿了之後CPU還是要卡住等待Invalidate ACK。Invalidate ACK耗時的主要原因是CPU需要先將自己cacheline狀態修改I後才響應ACK,如果一個CPU很繁忙或者處於S狀態的副本特別多,可能所有CPU都在等它的ACK。
CPU優化這個問題的方式是搞一個Invalid Queue,CPU先將Invalidate訊息放到這個佇列中,接著就響應Invalidate ACK。然而這又帶來了新的問題,還是以上面的程式碼為例
```
a = 0
flag = false
func runInCpu0() {
a = 1
smp_wmb()
flag = true
}
func runInCpu1() {
while (!flag) {
continue
}
print(a)
}
```
我們假設a在CPU0和CPU1中,且狀態均為S,flag由CPU0獨佔
1. CPU0執行a=1,因為a狀態為S,所以它將a=1寫入Store Buffer,併發出Invalidate a訊息
2. CPU1執行while(!flag),由於其cache中沒有flag,所以它發出Read flag訊息
3. CPU1收到CPU0的Invalidate a訊息,並將此訊息寫入了Invalid Queue,接著就響應了Invlidate ACK
4. CPU0收到CPU1的Invalidate ACK後將a=1刷到cache中,並將其狀態修改為了M
5. CPU0執行到smp_wmb(),由於Store Buffer此時為空所以就往下執行了
6. CPU0執行flag=true,因為flag狀態為E,所以它直接將flag=true寫入到cache,狀態被修改為了M
7. CPU0收到了Read flag訊息,因為它cache中有flag,因此它響應了Read Response,並將狀態修改為S
8. CPU1收到Read flag Response,此時flag=true,所以結束了while迴圈
9. CPU1列印a,由於a存在於它的cache中且狀態為S,所以直接將cache中的a打印出來了,此時a=0,這顯然發生了錯誤。
10. CPU1這時才處理Invalid Queue中的訊息將a狀態修改為I,但為時已晚
為了解決上面的問題,CPU提出了讀屏障指令,linux將其封裝為了smp_rwm()函式。放到我們的程式碼中就是這樣:
```
...
func runInCpu1() {
while (!flag) {
continue
}
smp_rwm()
print(a)
}
```
當CPU執行到smp_rwm()時,會將Invalid Queue中的資料處理完成後再執行屏障後面的讀取操作,這就解決了上面的問題了。
除了上面提到的讀屏障和寫屏障外,還有一種全屏障,它其實是讀屏障和寫屏障的綜合體,兼具兩種屏障的作用,在linux中它是smp_mb()函式。
文章開始提到的LOCK指令其實兼具了記憶體屏障的作用。
# 幾個問題
### 問題1: CPU採用MESI協議實現快取同步,為什麼還要LOCK
答:
1. MESI協議只維護快取一致性,與可見性有關,與原子性無關。一個非原子性的指令需要加上lock字首才能保證原子性。
### 問題2: 一條彙編指令是原子性的嗎
1. `read-modify-write 記憶體`的指令不是原子性的,以`INC mem_addr`為例,我們假設資料已經快取在了cache上,指令的執行需要先將資料從cache讀到執行單元中,再執行+1,然後寫回到cache。
2. 對於沒有對齊的記憶體,讀取記憶體可能需要多次讀取,這不是原子性的。(在某些CPU上讀取未對齊的記憶體是不被允許的)
3. 其他未知原因...
### 問題3: Go中的原子讀
我們看一個讀取8位元組資料的例子,直接看golang `atomic.LoadUint64()`彙編:
```
// uint64 atomicload64(uint64 volatile* addr);
1. TEXT runtime∕internal∕atomic·Load64(SB), NOSPLIT, $0-12
2. MOVL ptr+0(FP), AX // 將第一個引數載入到AX暫存器
3. TESTL $7, AX // 判斷記憶體是否對齊
4. JZ 2(PC) // 跳到這條指令的下兩條處,即跳轉到第6行
5. MOVL 0, AX // crash with nil ptr deref 引用0x0地址會觸發錯誤
6. MOVQ (AX), M0 // 將記憶體地址指向的資料載入到M0暫存器
7. MOVQ M0, ret+4(FP) // 將M0暫存器中資料(即記憶體指向的位置)給返回值
8. EMMS // 清除M0暫存器
9. RET
```
第3行TESTL指令對兩個運算元按位與,如果結果為0,則將ZF設定為1,否則為0。所以這一行其實是判斷傳進來的記憶體地址是不是8的整數倍。
第4行JZ指令判斷如果ZF即零標誌位為1則執行跳轉到第二個運算元指定的位置,結合第三行就是如果傳入的記憶體地址是8的整數倍,即記憶體已對齊,則跳轉到第6行,否則繼續往下執行。
關於記憶體對齊可以看下我這篇文章:[理解記憶體對齊](https://blog.fanscore.cn/p/24/) 。
雖然MOV指令是原子性的,但是彙編中貌似沒有加入記憶體屏障,那Golang是怎麼實現可見性的呢?我這裡也並沒有完全的理解,不過大概意思是Golang的atomic會保證順序一致性。
### 問題4:Go中的原子寫
仍然以寫一個8位元組資料的操作為例,直接看golang `atomic.LoadUint64()`彙編:
```
TEXT runtime∕internal∕atomic·Store64(SB), NOSPLIT, $0-16
MOVQ ptr+0(FP), BX
MOVQ val+8(FP), AX
XCHGQ AX, 0(BX)
RET
```
雖然沒有LOCK指令,但XCHGQ指令具有LOCK的效果,所以還是原子性而且可見的。
# 總結
這篇文章花費了我大量的時間與精力,主要原因是剛開始覺得原子性只是個小問題,但是隨著不斷的深入挖掘,翻閱無數資料,才發現底下潛藏了無數的坑,面對浩瀚的計算機世界,深感自己的渺小與無知。
[](https://imgchr.com/i/s70KdH)
由於精力原因本文還有一些很重要的點沒有講到,比如acquire/release 語義等等。
另外客觀講本文問題很多,較真的話可能會對您造成一定的困擾,這裡表示抱歉,建議您可以將本文作為您研究計算機底層架構的一個契機,自行研究這方面的技術。
# 參考資料
* [記憶體屏障的來歷](https://zhuanlan.zhihu.com/p/125549632)
* [MESI協議 - 維基百科,自由的百科全書](https://zh.wikipedia.org/wiki/MESI%E5%8D%8F%E8%AE%AE)
* [c++ - Does golang atomic.Load have a acquire semantics? - Stack Overflow](https://stackoverflow.com/questions/55787091/does-golang-atomic-load-have-a-acquire-semantics)
* [golang-notes/memory_barrier.md at master · cch123/golang-notes · GitHub](https://github.com/cch123/golang-notes/blob/master/memory_bar