
訊息佇列之kafka
阿新 • • 發佈:2021-01-24
[訊息佇列之activeMQ](https://www.cnblogs.com/pluto-charon/p/14225896.html)
[訊息佇列之RabbitMQ](https://www.cnblogs.com/pluto-charon/p/14288765.html)
## 1.kafka介紹
kafka是由scala語言開發的一個多分割槽,多副本的並且居於zookeeper協調的分散式的釋出-訂閱訊息系統。具有高吞吐、可持久化、可水平擴充套件、支援流處理等特性;能夠支撐海量資料的資料傳遞;並且將訊息持久化到磁碟中,並對訊息建立了備份保證了資料的安全。kafka在保證了較高的處理速度的同時,又能保證資料處理的低延遲和資料的零丟失。
kafka的特性:
1. 高吞吐量,低延遲:kafka每秒可以處理幾十萬條訊息,延遲最低大概毫秒,每個主題可以分為多個分割槽,消費組對分割槽進行消費操作
2. 可擴充套件性:支援熱擴充套件
3. 永續性,可靠性:訊息被持久化到本地磁碟,並且支援資料備份
4. 容錯性:允許叢集中節點失敗,如副本的數量為n,則允許n-1個節點失敗
5. 高併發:允許上千個客戶端同時讀寫
6. 可伸縮性:kafka在執行期間可以輕鬆的擴充套件或者收縮;可以擴充套件一個kafka主題來包含更多的分割槽
kafka的主要應用場景:
- 訊息處理
- 網站跟蹤
- 指標儲存
- 日誌聚合
- 流式處理
- 事件朔源
基本流程:
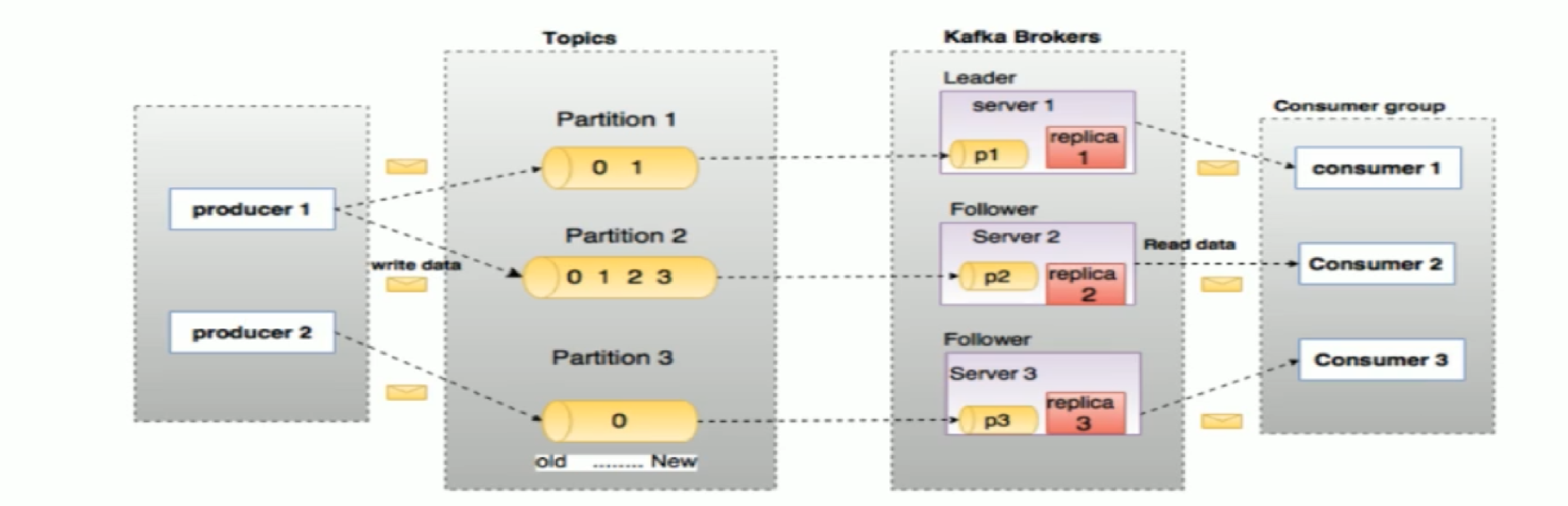
kafka的關鍵角色:
- **Producer:**生產者即資料的釋出者,該角色將訊息釋出到kafka的topic中
- **Consumer:**消費者,可以從broker中讀取資料
- **Consumer Group:**每個Consumer屬於一個特定的Consumer Group(可為每個Consumer指定group name,若不指定group name則屬於預設的group)
- **Topic:**劃分資料的所屬類的一個類別屬性
- **Partition:**topic中的資料分割為一個或多個partition,每個topic中至少含有一個partition
- **Partition offset:**每條訊息都有一個當前partition下的唯一的64位元組的offset,它指名了這條訊息的起始位置
- **Replicas of Partition:**副本,是一個分割槽的備份
- **Broker:**kafka叢集中包含一個或多個伺服器 ,伺服器的節點稱為broker
- **Leader:**每個partition由多個副本,其中有且僅有一個作為leader,leader是當前負責資料的讀寫的partition
- **Follower:**Follower跟隨Leader,所有的寫請求都是通過leader路由,資料變更會廣播到所有的follower上,follower與leader的資料保持同步
- **AR:**分割槽中所有的副本統稱為AR
- **ISR:**所有與leader部分保持一定程度的副本組成ISR
- **OSR:**與leader副本同步滯後過多的副本
- **HW:**高水位,標識了一個特定的offset,消費者只能拉去到這個offset之前的訊息
- **LEO:**即日誌末端位移,記錄了該副本底層日誌中的下一條訊息的位移值
## 2.kafka的安裝
安裝kafka的前提是安裝zookeeper以及jdk環境。我這裡安裝的版本是jdk1.8.0_20,kafka_2.11-1.0.0,zookeeper-3.4.14。kafka與jdk的版本一定要對應。我之前用的kafka_2.12_2.3.0,就不行
1.將kafka的檔案上傳到home目錄下並解壓縮到/usr/local目錄下
```shell
root@localhost home]# tar -xvzf kafka_2.11-1.0.0.tgz -C /usr/local
```
2.進入kafka的config
```shell
[root@localhost local]# cd /usr/local/kafka_2.11-1.0.0/config
```
3.編輯server.properties檔案
```yaml
# 如果是叢集環境中,則每個broker.id要設定為不同
broker.id=0
# 將下面這一行開啟,這相當於kafka對外提供服務的入口
listeners=PLAINTEXT://192.168.189.150:9092
# 日誌儲存位置:log.dirs=/tmp/kafka_logs 改為
log.dirs=/usr/local/kafka_2.11-1.0.0/logs
# 修改zookeeper的地址
zookeeper.connect=192.168.189.150:2181
# 修改zookeeper的連線超時時長,預設為6000(可能會超時)
zookeeper.connection.timeout.ms=10000
```
3.啟動zookeeper
因為我是配置的zookeeper叢集,所以需要將三臺zookeeper都啟動。只啟動單臺伺服器zookeeper在選舉的時候將不可進行(當整個叢集超過半數機器宕機,zookeeper會認為叢集處於不可用狀態)
```shell
[root@localhost ~]# zkServer.sh start
# 檢視狀態
[root@localhost ~]# zkServer.sh status
```
4.啟動kafka
```shell
[root@localhost kafka_2.11-1.0.0]# bin/kafka-server-start.sh config/server.properties
# 也可以使用後臺啟動的方式,如果不使用後臺啟動,則在啟動後操作需要新開一個窗口才能操作
[root@localhost kafka_2.11-1.0.0]# bin/kafka-server-start.sh -daemon config/server.properties
```
5.建立一個主題
```shell
# --zookeeper: 指定了kafka所連線的zookeeper的服務地址
# --partitions: 指定了分割槽的個數
# --replication-factor: 指定了副本因子
[root@localhost kafka_2.11-1.0.0]# bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic charon --partitions 2 --replication-factor 1
Created topic "charon".
```
6.展示所有的主題(驗證建立的主題是否有問題)
```shell
[root@localhost kafka_2.11-1.0.0]# bin/kafka-topics.sh --zookeeper localhost:2181 --list
charon
```
7.檢視某個主題的詳情
```shell
[root@localhost kafka_2.11-1.0.0]# bin/kafka-topics.sh --zookeeper localhost:2181 --describe --topic charon
Topic:charon PartitionCount:2 ReplicationFactor:1 Configs:
Topic: charon Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: charon Partition: 1 Leader: 0 Replicas: 0 Isr: 0
```
8.新開一個視窗啟動消費者接收訊息.
--bootstrap-server:指定連線kafka叢集的地址,9092是kafka服務的埠。因為我的配置檔案中配置的是具體地址,所以需要寫明具體地址。否則會報 **[Producer clientId=console-producer] Connection to node -1 could not be established. Broker may not be available.**的錯
```shell
[root@localhost kafka_2.11-1.0.0]# bin/kafka-console-consumer.sh --bootstrap-server 192.168.189.150:9092 --topic charon
```
9.新開一個視窗啟動生產者產生訊息
--bootstrap-server:指定連線kafka叢集的地址,9092是kafka服務的埠。因為我的配置檔案中配置的是地址。
```shell
[root@localhost kafka_2.11-1.0.0]# bin/kafka-console-producer.sh --broker-list 192.168.189.150:9092 --topic charon
```
10.產生訊息並消費訊息
```shell
# 生產者生產訊息
>hello charon good evening
# 消費者這邊接收到的訊息
hello charon good evening
```
當然上面這種方式,只有在同一個網段才能實現。
## 3.生產者和消費者
kafka生產流程:
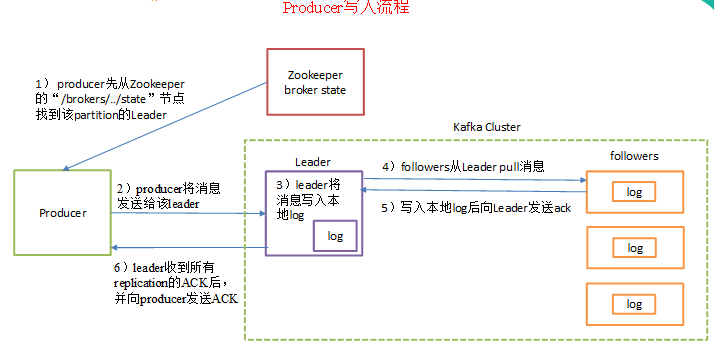
1)producer先從zookeeper的 "/brokers/.../state"節點找到該partition的leader
2)producer將訊息傳送給該leader
3)leader將訊息寫入本地log
4)followers從leader pull訊息,寫入本地log後向leader傳送ACK
5)leader收到所有ISR中的replication的ACK後,增加HW(high watermark,最後commit 的offset)並向producer傳送ACK
消費組:
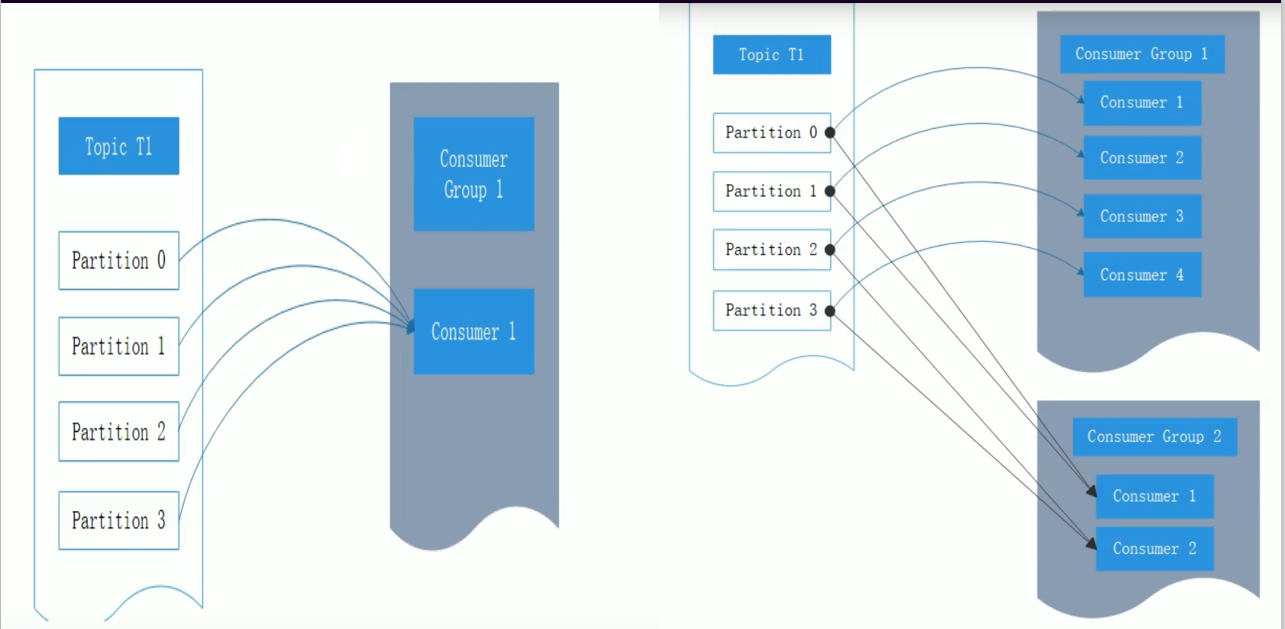
kafka消費者是消費組的一部分,當多個消費者形成一個消費組來消費主題的時候,每個消費者都會收到來自不同分割槽的訊息。假如消費者都在同一個消費者組裡面,則是工作-佇列模型。假如消費者在不同的消費組裡面,則是釋出-訂閱模型。
當單個消費者無法跟上資料的生成速度時,就可以增加更多的消費者來分擔負載,每個消費者只處理部分分割槽的訊息,從而實現單個應用程式的橫向伸縮。但是千萬不要讓消費者的數量少於分割槽的數量,因為此時會有多餘的消費者空閒。
當有多個應用程式都需要從kafka獲取訊息時,讓每個應用程式對應一個消費者組,從而使每個應用程式都能獲取一個或多個topic的全部訊息。每個消費者對應一個執行緒,如果要在同一個消費者組中執行多個消費者,需要讓每個消費者執行在自己的執行緒中。
## 4.程式碼實踐
1.新增依賴:
```xml
```
生產者程式碼:
```java
package kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
/**
* @className: Producer
* @description: kafka的生產者
* @author: charon
* @create: 2021-01-18 08:52
*/
public class Producer {
/**topic*/
private static final String topic = "charon";
public static void main(String[] args) {
// 配置kafka的屬性
Properties properties = new Properties();
// 設定地址
properties.put("bootstrap.servers","192.168.189.150:9092");
// 設定應答型別,預設值為0。(0:生產者不會等待kafka的響應;1:kafka的leader會把這條訊息寫到本地日誌檔案中,但不會等待叢集中其他機器的成功響應;
// -1(all):leader會等待所有的follower同步完成,確保訊息不會丟失,除非kafka叢集中的所有機器掛掉,保證可用性)
properties.put("acks","all");
// 設定重試次數,大於0,客戶端會在訊息傳送失敗是重新發送
properties.put("reties",0);
// 設定批量大小,當多條訊息需要傳送到同一個分割槽時,生產者會嘗試合併網路請求,提交效率
properties.put("batch.size",10000);
// 生產者設定序列化方式,預設為:org.apache.kafka.common.serialization.StringSerializer
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 建立生產者
KafkaProducer producer = new KafkaProducer(properties);
for (int i = 0; i < 5; i++) {
String message = "hello,charon message "+ i ;
producer.send(new ProducerRecord(topic,message));
System.out.println("生產者傳送訊息:" + message);
}
producer.close();
}
}
```
消費者程式碼:
```java
package kafka;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Arrays;
import java.util.List;
import java.util.Properties;
/**
* @className: Consumer
* @description: kafka的消費者
* @author: charon
* @create: 2021-01-18 08:53
*/
public class Consumer implements Runnable{
/**topic*/
private static final String topic = "charon";
/**kafka消費者*/
private static KafkaConsumer kafkaConsumer;
/**消費訊息*/
private static Consume