
【原創】Linux虛擬化KVM-Qemu分析(八)之virtio初探
阿新 • • 發佈:2021-01-25
# 背景
- `Read the fucking source code!` --By 魯迅
- `A picture is worth a thousand words.` --By 高爾基
說明:
1. KVM版本:5.9.1
2. QEMU版本:5.0.0
3. 工具:Source Insight 3.5, Visio
# 概述
- 從本文開始將研究一下virtio;
- 本文會從一個網絡卡虛擬化的例子來引入virtio,並從大體架構上進行介紹,有個巨集觀的認識;
- 細節的闡述後續的文章再跟進;
# 1. 網絡卡
## 1.1 網絡卡工作原理
先來看一下網絡卡的架構圖(以Intel的82540為例):
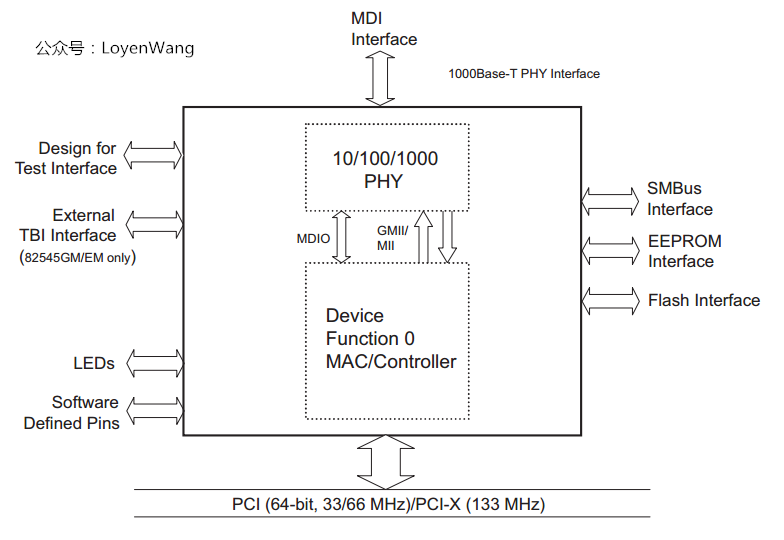
- OSI模型,將網路通訊中的資料流劃分為7層,最底下兩層為物理層和資料鏈路層,對應到網絡卡上就是`PHY`和`MAC控制器`;
- `PHY`:對應物理層,負責通訊裝置與網路媒介(網線)之間的互通,它定義傳輸的光電訊號、線路狀態等;
- `MAC控制器`:對應資料鏈路層,負責網路定址、錯誤偵測和改錯等;
- `PHY`和`MAC`通過`MII/GMII(Media Independent Interface)`和`MDIO(Management Data Input/output)`相連;
- `MII/GMII(Gigabit MII)`:由`IEEE`定義的乙太網行業標準,與媒介無關,包含資料介面和管理介面,用於網路資料傳輸;
- `MDIO`介面,也是由`IEEE`定義,一種簡單的序列介面,通常用於控制收發器,並收集狀態資訊等;
- 網絡卡通過PCI介面接入到PCI匯流排中,CPU可以通過訪問BAR空間來獲取資料包,也有網絡卡直接掛在記憶體總線上;
- 網絡卡還有一顆EEPROM晶片,用於記錄廠商ID、網絡卡的MAC地址、配置資訊等;
我們主要關心它的資料流,所以,看看它的工作原理吧:
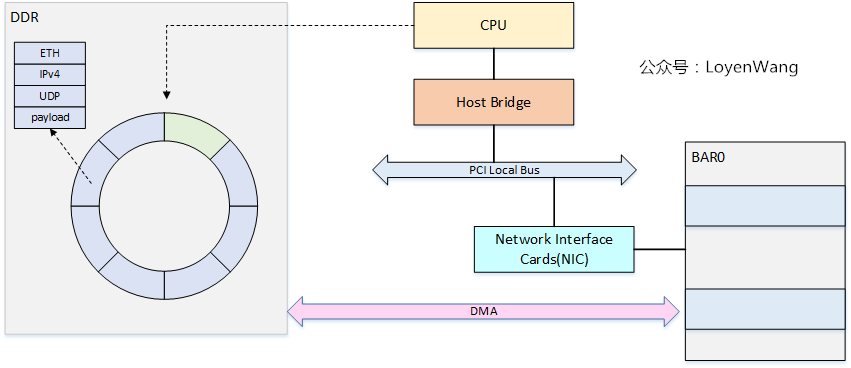
- 網路包的接收與傳送,都是典型的`生產者-消費者`模型,簡單來說,CPU會在記憶體中維護兩個`ring-buffer`,分別代表`RX`和`TX`,`ring-buffer`中存放的是描述符,描述符裡包含了一個網路包的資訊,包括了網路包地址、長度、狀態等資訊;
- `ring-buffer`有頭尾兩個指標,傳送端為:`TDH(Transmit Descriptor Head)和TDT(Transmit Descriptor Tail)`,同理,接收端為:`RDH(Receive Descriptor Head)和RDT(Receive Descriptor Tail)`,在資料傳輸時,由CPU和網絡卡來分開更新頭尾指標的值,這也就是生產者更新尾指標,消費者更新頭指標,永遠都是消費者追著生產者跑,`ring-buffer`也就能轉起來了;
- 資料的傳輸,使用DMA來進行搬運,CPU的拷貝顯然是一種低效的選擇。在之前PCI系列分析文章中分析過,PCI裝置有自己的BAR空間,可以通過DMA在BAR空間和DDR空間內進行搬運;
## 1.2 Linux網絡卡驅動
在網絡卡資料流圖中,我們也基本看到了網絡卡驅動的影子,驅動與網絡卡之間是非同步通訊:
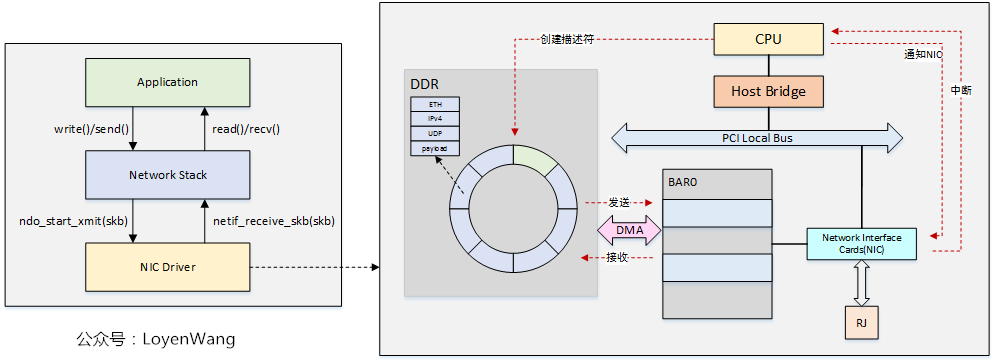
- 驅動程式負責硬體的初始化,以及TX和RX的`ring-buffer`的建立及初始化;
- `ndo_start_xmit`負責將網路包通過驅動程式傳送出去,`netif_receive_skb`負責通過驅動程式接收網路包資料;
- 資料通過`struct sk_buff`來儲存;
- 傳送資料時,CPU負責準備TX網路包資料以及描述符資源,更新TDT指標,並通知NIC可以進行資料傳送了,當資料傳送完畢後NIC通過中斷訊號通知CPU進行下一個包的處理;
- 接收資料時,CPU負責準備RX的描述符資源,接收資料後,NIC通過中斷通知CPU,驅動程式通過排程核心執行緒來處理網路包資料,處理完成後進行下一包的接收;
# 2. 網絡卡全虛擬化
## 2.1 全虛擬化方案
全虛擬化方案,通過軟體來模擬網絡卡,Qemu+KVM的方案如下圖:
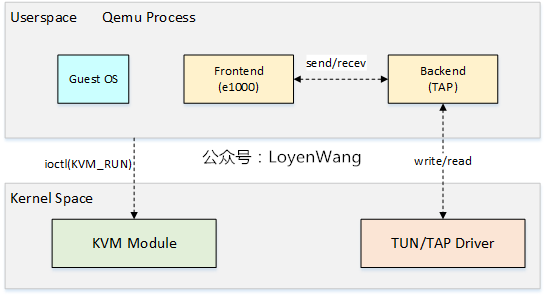
- Qemu中,裝置的模擬稱為前端,比如`e1000`,前端與後端通訊,後端再與底層通訊,我們來分別看看傳送和接收處理的流程;
- 傳送:
1. Guest OS在準備好網路包資料以及描述符資源後,通過寫`TDT`暫存器,觸發VM的異常退出,由KVM模組接管;
2. KVM模組返回到Qemu後,Qemu會檢查VM退出的原因,比如檢查到`e1000`暫存器訪問出錯,因而觸發`e1000前端`工作;
3. Qemu能訪問Guest OS中的地址內容,因而`e1000前端`能獲取到Guest OS記憶體中的網路包資料,傳送給後端,後端再將網路包資料傳送給TUN/TAP驅動,其中TUN/TAP為虛擬網路裝置;
4. 資料傳送完成後,除了更新`ring-buffer`的指標及描述符狀態資訊外,KVM模組會模擬TX中斷;
5. 當再次進入VM時,Guest OS看到的是資料已經發送完畢,同時還需要進行中斷處理;
6. Guest OS跑在vCPU執行緒中,傳送資料時相當於會打算它的執行,直到處理完後再恢復回來,也就是一個嚴格的同步處理過程;
- 接收:
1. 當TUN/TAP有網路包資料時,可以通過讀取TAP檔案描述符來獲取;
2. Qemu中的I/O執行緒會被喚醒並觸發後端處理,並將資料傳送給`e1000前端`;
3. `e1000`前端將資料拷貝到Guest OS的實體記憶體中,並模擬RX中斷,觸發VM的退出,並由KVM模組接管;
4. KVM模組返回到Qemu中進行處理後,並最終重新進入Guest OS的執行中斷處理;
5. 由於有I/O執行緒來處理接收,能與vCPU執行緒做到並行處理,這一點與傳送不太一樣;
## 2.2 弊端
- Guest OS去操作暫存器的時候,會觸發VM退出,涉及到KVM和Qemu的處理,並最終再次進入VM,overhead較大;
- 不管是在Host還是Guest中,中斷處理的開銷也很大,中斷涉及的暫存器訪問也較多;
- 軟體模擬的方案,吞吐量效能也比較低,時延較大;
所以,讓我們大聲喊出本文的主角吧!
# 3. 網絡卡半虛擬化
在進入主題前,先思考幾個問題:
1. 全虛擬化下Guest可以重用驅動、網路協議棧等,但是在軟體全模擬的情況下,我們是否真的需要去訪問暫存器嗎(比如中斷處理),真的需要模擬網絡卡的自協商機制以及EEPROM等功能嗎?
2. 是否真的需要模擬大量的硬體控制暫存器,而這些暫存器在軟體看來毫無意義?
3. 是否真的需要生產者/消費者模型的通知機制(暫存器訪問、中斷)?
## 3.1 virtio
網絡卡的工作過程是一個生產者消費者模型,但是在前文中可以看出,在全虛擬化狀態下存在一些弊端,一個更好的生產者消費者模型應該遵循以下原則:
1. 暫存器只被生產者使用去通知消費者`ring-buffer`有資料(消費者可以繼續消費),而不再被用作儲存狀態資訊;
2. 中斷被消費者用來通知生產者`ring-buffer`是非滿狀態(生產者可以繼續生產);
3. 生產者和消費者的狀態資訊應該儲存在記憶體中,這樣讀取狀態資訊時不需要VM退出,減少overhead;
4. 生產者和消費者跑在不同的執行緒中,可以並行執行,並且儘可能多的處理任務;
5. 非必要情況下,相互之間的通知應該避免使用;
6. 忙等待(比如輪詢)不是一個可以接受的通用解決方案;
基於上述原則,我們來看看從特殊到一般的過程:
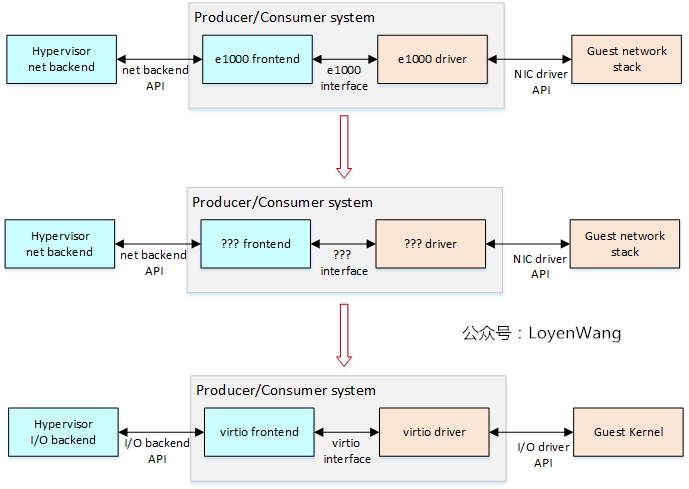
- 第一行是針對網絡卡的實現,第二行更進一步的抽象,第三行是通用的解決方案了,對I/O操作的虛擬化通用支援;
所以,在virtio的方案下,網絡卡的虛擬化看上去就是下邊這個樣子了:

- Hypervisor和Guest都需要實現virtio,這也就意味著Guest的裝置驅動知道自己本身執行在VM中;
- virtio的目標是高效能的裝置虛擬化,已經形成了規範來定義標準的訊息傳遞API,用於驅動和Hypervisor之間的傳遞,不同的驅動和前端可以使用相同的API;
- virtio驅動(比如圖中的virtio-net driver)的工作是將OS-specific的訊息轉換成virtio格式的訊息,而對端(virtio-net frontend)則是做相反的工作;
virtio的資料傳遞使用`scatter-gather list(sg-list)`:
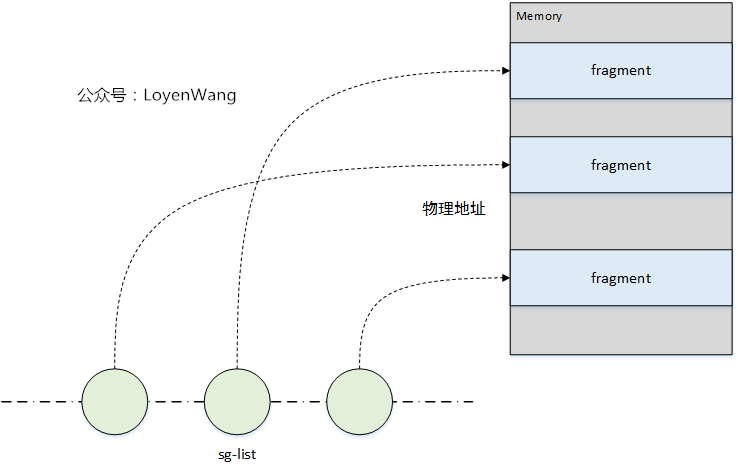
- sg-list是概念上的(物理)地址和長度對的連結串列,通常作為陣列來實現;
- 每個sg-list描述一個多塊的buffer,消費者用它來作為輸入或輸出操作;
virtio的核心是`virtqueue(VQ)`的抽象:
- VQ是佇列,sg-list會被Guest的驅動放置到VQ中,以供Hypervisor來消費;
- 輸出sg-list用於向Hypervisor來發送資料,而輸入sg-list用於接收Hypervisor的資料;
- 驅動可以使用一個或多個`virqueue`;
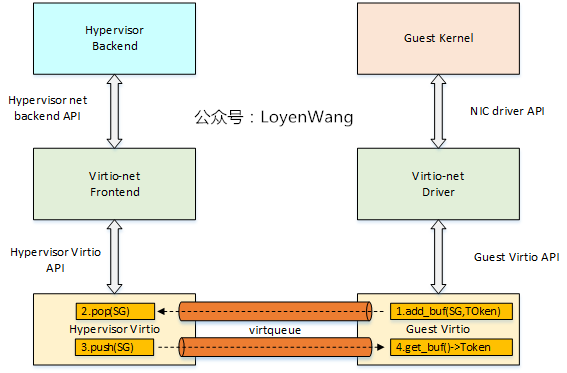
1. 當Guest的驅動產生一個sg-list時,呼叫`add_buf(SG, Token)`入列;
2. Hypervisor進行出列操作,並消費sg-list,並將sg-list push回去;
3. Guest通過`get_buf()`進行清理工作;
上圖說的是資料流方向,那麼事件的通知機制如下:
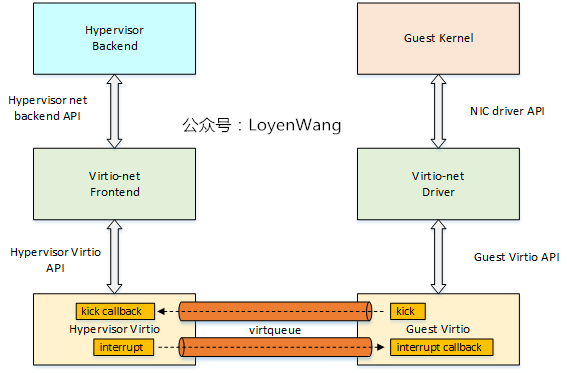
- 當Guest驅動想要Hypervisor消費sg-list時,通過VQ的`kick`來進行通知;
- 當Hypervisor通知Guest驅動已經消費完了,通過`interupt`來進行通知;
大體的資料流和控制流講完了,細節實現後續再跟進了。
## 3.2 半虛擬化方案
那麼,半虛擬化框架下的網絡卡虛擬化資料流是啥樣的呢?
- 傳送

- 接收

相信你應該對virtio有個大概的瞭解了,好了,收工。
# 參考
`《Virtio networking: A case study of I/O paravirtualization》`
`《 PCI/PCI-X Family of Gigabit Ethernet Controllers Software Developer's Manual》`
歡迎關注個人公眾號,不定期更新Linux相關技術文章。
![](https://img2020.cnblogs.com/blog/1771657/202101/1771657-20210124225217681-8082585