
大三寒假學習進度(8)
阿新 • • 發佈:2021-01-25
# 1. 神經網路的搭建八股
## 1.1 、 用Tensorflow API: tf.keras 搭建神經網路八股
* **六步法:**
>* **import**
>
> import相關模組,比如 import tensorflow as tf
>
>* **train, test**
>
> 告知要喂入網路的訓練集和測試集是什麼
>
> 也就是要指定訓練集的輸入特徵x_train和訓練集標籤y_train
>
> 測試集的輸入特徵x_test和測試集的標籤y_test
>
>* **model = tf.keras.models.Sequential**
>
> 在Sequential()中搭建網路結構,逐層描述每層網路
>
>* **model.compile**
>
> 在compile()中配置訓練方法,告知訓練時選擇哪種優化器,選擇哪個損失函式,選擇哪種評測指標
>
>* **model.fit**
>
> 在fit()中執行訓練過程,告知訓練集和測試集的輸入特徵和標籤,告知每個batch是多少,告知要迭代多少次資料集
>
>* **model.summary**
>
> 用summary()打印出網路的結構和引數統計
* **model = tf.keras.models.Sequential([網路結構])**
------
Sequential()可以認為是個容器,裡面封裝了一個神經網路結構
在Sequential中要描述從輸入層到輸出層每一層的網路結構
>**網路結構舉例:**
>
>* 拉直層:tf.keras.layers.Flatten()
> * 這一層不含計算,只是形狀轉換,把輸入特徵拉直變成一維陣列
>* 全連線層:tf,keras.layers.Dense(神經元個數,activation=“啟用函式”,kernel_regularizer=哪種正則化)
> * activation(字串給出)可選:relu、softmax、sigmoid、tanh
> * kernel_regularizer可選:tf.keras.regularizer.l1()、tf.keras.regularizers.l2()
>* 卷積層:tf.keras.layres.Conv2D(filters= 卷積核個數,kernel_size=卷積核尺寸。strides=卷積步長,padding="valid" or "same")
>* LSTM層:tf.keras.layers.LSTM()
* **Model.compile( optimizer = 優化器, loss = 損失函式, metrics = [“準確率”])**
------
>* optimizer 可以是字串形式給出的優化器名字,也可以是函式形式,使用函式 形式可以設定學習率、動量和超引數。
> * 可選項包括:
> 1. ‘sgd’or tf.optimizers.SGD( lr=學習率, decay=學習率衰減率, momentum=動量引數)
> 2. ‘adagrad’or tf.keras.optimizers.Adagrad(lr=學習率, decay=學習率衰減率)
> 3. ‘adadelta’or tf.keras.optimizers.Adadelta(lr=學習率, decay=學習率衰減率)
> 4. ‘adam’or tf.keras.optimizers.Adam (lr=學習率, decay=學習率衰減率)
>
>* Loss 可以是字串形式給出的損失函式的名字,也可以是函式形式。
>
> * 可選項包括:
>
> 1. ‘mse’or tf.keras.losses.MeanSquaredError()
> 2. ‘sparse_categorical_crossentropy or tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False)
>
> * 損失函式常需要經過 softmax 等函式將輸出轉化為概率分佈的形式。 from_logits 則用來標註該損失函式是否需要轉換為概率的形式,取 False 時表 示轉化為概率分佈,取 True 時表示沒有轉化為概率分佈,直接輸出。
>
>* Metrics 標註網路評測指標。
>
> * 可選項包括:
>
> 1. ‘accuracy’:y_和y都是數值形式給出的
>
> 如:如 y_=[1] y=[1]
>
> 2. ‘categorical_accuracy’:y_和y都是以獨熱碼或概率分佈形式給出
>
> 如:y_=[0, 1, 0], y=[0.256, 0.695, 0.048]
>
> 3. ‘sparse_ categorical_accuracy’:y_是以數值形式給出,y 是以獨熱碼形式 給出。
>
> 如: y_=[1],y=[0.256, 0.695, 0.048]
* **model.fit(訓練集的輸入特徵, 訓練集的標籤, batch_size=, epochs=, validation_data = (測試集的輸入特徵,測試集的標籤), validataion_split = 從測試集劃分多少比例給訓練集, validation_freq = 測試的 epoch 間隔次數)**
------
* **model.summary()**
------
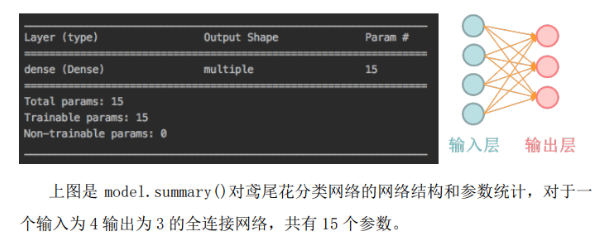
>* **summary 函式用於列印網路結構和引數統計**
>
>
* **用六步法實現鳶尾花資料集分類**
```py
# impor相關模組
import tensorflow as tf
from sklearn import datasets
import numpy as np
# 交代訓練集的輸入特徵x_train和訓練集的標籤y_train
x_train = datasets.load_iris().data
y_train = datasets.load_iris().target
# 測試集的輸入特徵x_test和測試集標籤y_test可以直接給定,也可以在fit中按比例從訓練集中劃分
#實現了資料集的亂序
np.random.seed(116)
np.random.shuffle(x_train)
np.random.seed(116)
np.random.shuffle(y_train)
tf.random.set_seed(116)
#在Sequential()搭建網路結構
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(3, activation='softmax', kernel_regularizer=tf.keras.regularizers.l2())
])
# 在compile中配置訓練方法
model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.1),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
#在fit()中執行訓練過程
model.fit(x_train, y_train, batch_size=32, epochs=500, validation_split=0.2, validation_freq=20)
# 列印網路結構和引數統計
model.summary()
```
* 結果
![](https://img2020.cnblogs.com/blog/1717301/202101/1717301-20210125204756270-10174533