
ES入門及安裝軟體
阿新 • • 發佈:2021-01-28
## es介紹
Elasticsearch,簡稱es,是一款高擴充套件的分散式全文檢索引擎。它可以近乎實時的儲存,檢索資料。es是面向文件型的資料庫,一條資料就是一個文件,用json做為文件序列化的格式。es是基於java開發的並使用lucene作為核心來實現所有的索引和搜尋功能,將對搜尋引擎的操作都封裝成restful的api,使用http請求就能對其進行操作。
es的優點:
- 分散式實時檔案儲存,並將每一個欄位都編入索引,使其可以被搜尋
- 實時分析的分散式搜尋引擎
- 可以擴充套件到上百臺伺服器,處理PB級別的結構化或非結構化資料
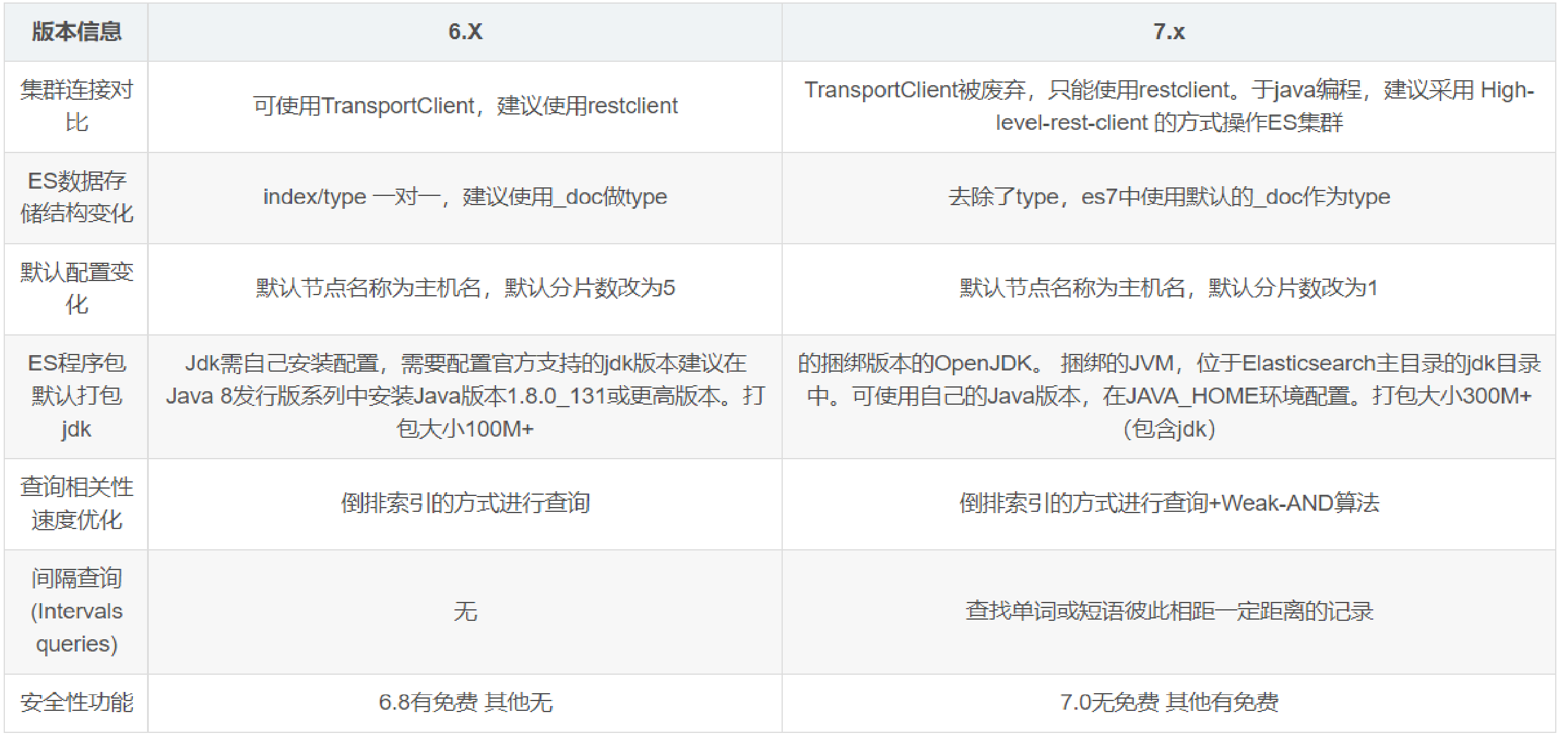
這裡筆者使用的是es7.X,es6和es7的差別還是挺大的,如下:
## 2.es安裝
要求:jdk1.8以上,最低要求1.8。
我這裡是安裝的windows版本的,es的安裝非常簡單,開箱即用。如果需要檔案,請留言郵箱。

1.如果電腦效能不是很好,可以修改config下的jvm.options中的22行~23行:
```yaml
-Xms1g
-Xmx1g
```
因為我的電腦效能不是很好,所以我就改成了256M。
2.解決跨域,用於後面視覺化介面和後臺的連線。
config下的elasticsearch.yml檔案末尾新增:
```yaml
http.cors.enabled: true
http.cors.allow-origin: "*"
```
3.啟動,bin目錄下的elasticsearch.bat,雙擊即可啟動。
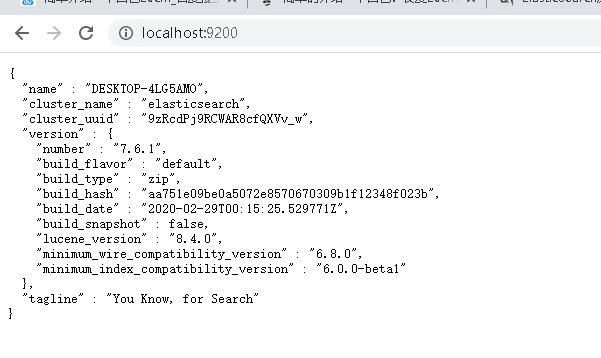
4.訪問:
5.安裝視覺化介面(head)
head外掛依賴於node.js。所以必須要安裝node.js。
head外掛基於grunt和http通訊。
安裝依賴:
```
# 在elasticsearch-head-master目錄下安裝淘寶映象
npm install -g cnpm --registry=https://registry.npm.taobao.org
# 安裝完cnpm之後執行
cnpm install
# 啟動head外掛命令
npm run start
```
訪問:localhsot:9100
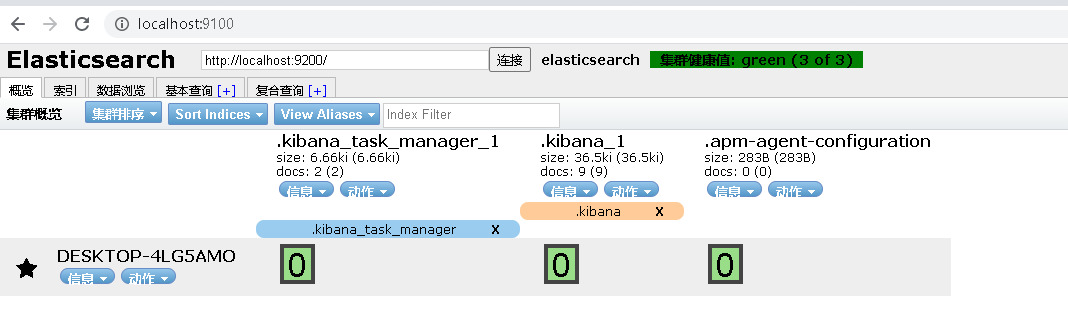
圖中綠色的表示資料塊。
6.安裝kibana
kibana也是基於node的。
啟動:kibana-7.6.1-windows-x86_64\bin目錄下的kibana.bat的檔案雙擊啟動。
訪問:localhost:5601
從上圖中可以看到,kibana是英文版的,漢化:
kibana-7.6.1-windows-x86_64\config下最後一行新增:
```yaml
i18n.locale: "zh-CN"
```
重啟之後再此訪問,就全是中文版的了。
## 3.es核心概念
**索引(index)**:索引是組織資料的邏輯名稱空間,是存放資料的地方,可以理解為資料庫。
**型別(type)**:定義資料結構的,可以理解為資料庫的一張表。
**文件(document)**:資料(一個文件就是一條資料),可以理解為資料庫的行資料。
**倒排索引**:一個倒排索引有文件中所有不重複詞的列表構成,使用與快速的全文檢索。可以理解為資料庫通過增加一個索引(比如一個 B樹(B-tree))索引 到指定的列上,以便提升資料檢索速度。在es中,每個欄位的所有資料都是預設被索引的,即每個欄位都有為了快速檢索設定的專門的倒排索引。同時能在同一個查詢中使用所有的倒排索引。
1.物理設計:
es在後臺把每個索引劃分成多個分片,每個分片可以在叢集中的不同伺服器間遷移,因為es一般情況下都會搭建叢集,當然單機也是叢集。
2.邏輯設計:
一個索引型別中,包含多個文件。有多個文件的話,就可以去查詢對應得資訊,當索引一篇文件時,可以通過這樣得一個順序找到它:索引>型別>文件ID(對應資料庫位:資料庫>表>行),通過這個組合就能找到對應得某個具體的文件。
## 4.ik分詞器
將elasticsearch-analysis-ik-7.6.1這個檔案解壓縮,然後放到es的elasticsearch-7.6.1\plugins下,如圖:

然後重啟es,可以看到ik分詞器的外掛。

IK分詞器提供了兩個分詞演算法:ik_smart(最少切分) ik_max_word(最細粒度劃分);
測試:
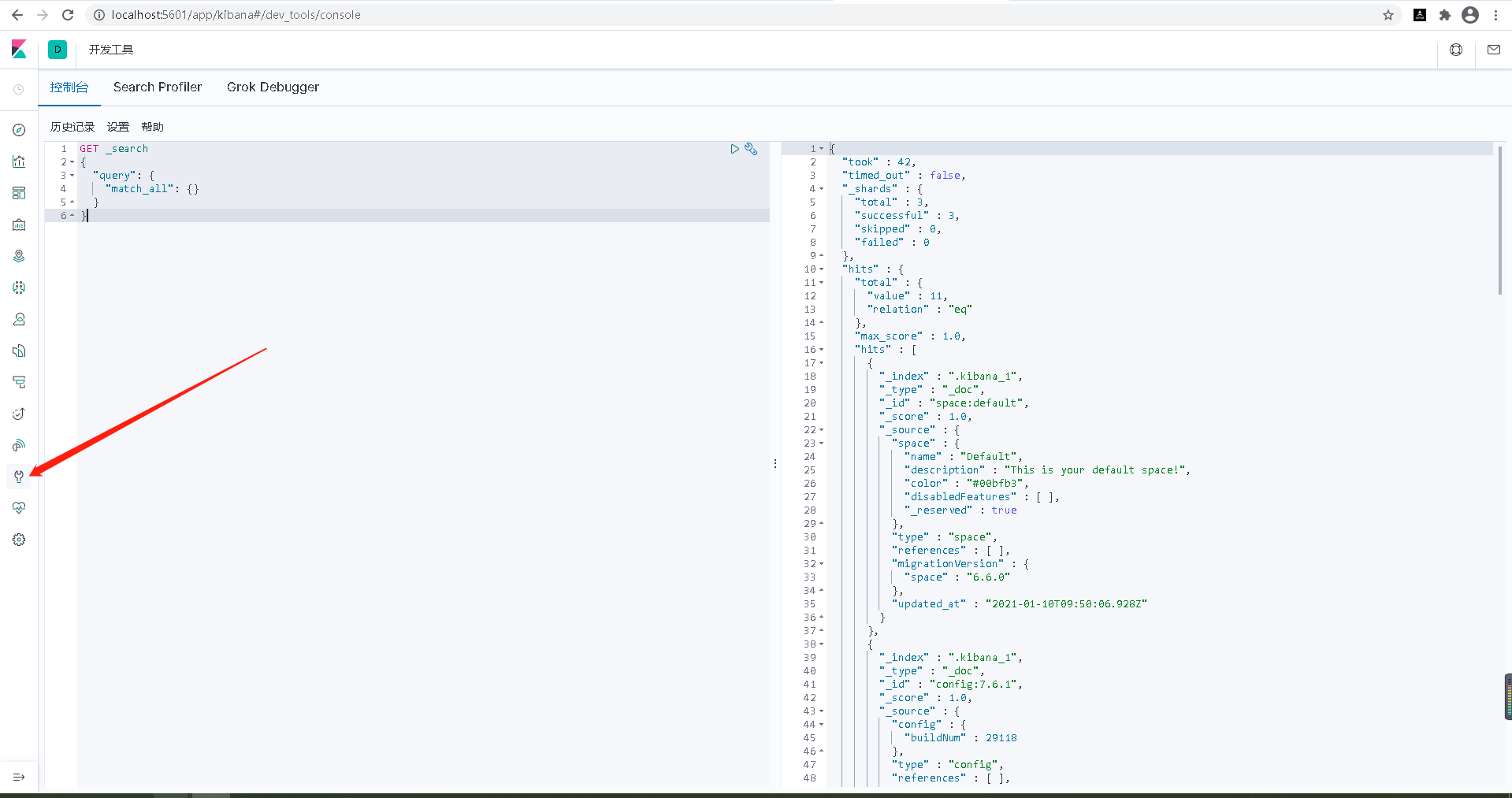
我在這裡使用“塘朗變電站”測試,可以看到,ik分詞器將“塘”,“朗”當作一個詞,將“變電站”當作一個詞。如果我們想將塘朗當作一個詞,那麼就需要自定義配置片語。
在elasticsearch-7.6.1\plugins\ik\config目錄下,有一個IKAnalyzer.cfg.xml檔案:
```xml
IK Analyzer 擴充套件配置
charon.dic
```
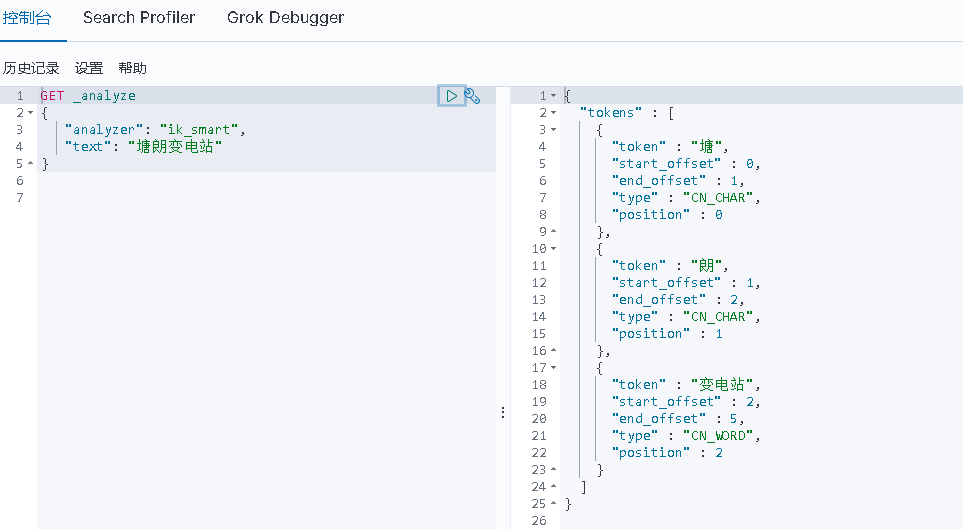
在config目錄下新建一個charon.dic檔案,然後在裡面新增塘朗。然後就可以看到,配置之後就將“塘朗”變成一個詞了。
## 5.文件操作
最初打算自己做一些關於文件操作的案例的,但是發現在官網文件上有很詳細的說明,那就貼出官網的地址吧:
https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
## 6.使用java程式碼操作es
這裡我就不貼出自己的程式碼了,下面這位老哥的程式碼,親測有效:
https://blog.csdn.net/b15735105314/article/details/1