
Java Object類 和 String類 常見問答 6k字+總結
阿新 • • 發佈:2021-01-30
# 寫在最前面
這個專案是從20年末就立好的 flag,經過幾年的學習,回過頭再去看很多知識點又有新的理解。所以趁著找實習的準備,結合以前的學習儲備,建立一個主要針對應屆生和初學者的 Java 開源知識專案,專注 Java 後端面試題 + 解析 + 重點知識詳解 + 精選文章的開源專案,希望它能伴隨你我一直進步!
說明:此專案我確實有很用心在做,內容全部是我參考了諸多博主(已註明出處),資料,N本書籍,以及結合自己理解,重新繪圖,重新組織語言等等所制。個人之力綿薄,或有不足之處,在所難免,但更新/完善會一直進行。大家的每一個 Star 都是對我的鼓勵 !希望大家能喜歡。
注:所有涉及圖片未使用網路圖床,文章等均開源提供給大家。
**專案名: Java-Ideal-Interview**
Github 地址: [Java-Ideal-Interview - Github ](https://github.com/ideal-20/Java-Ideal-Interview)
Gitee 地址:[Java-Ideal-Interview - Gitee(碼雲) ](https://gitee.com/ideal-20/java-ideal-interview)
持續更新中,線上閱讀將會在後期提供,若認為 Gitee 或 Github 閱讀不便,可克隆到本地配合 Typora 等編輯器舒適閱讀
若 Github 克隆速度過慢,可選擇使用國內 Gitee 倉庫
- [三 Java 常見物件](#三-java-常見物件)
- [1. 基本歸納](#1-基本歸納)
- [1.1 Object 類](#11-object-類)
- [2.2 String 類](#22-string-類)
- [2. 題目總結](#2-題目總結)
- [2.1 == 和 equals 的區別?](#21-和-equals-的區別)
- [2.2 如何比較兩個物件內容是否相同?(重寫 equals)](#22-如何比較兩個物件內容是否相同重寫-equals)
- [2.3 hashCode() 和 equals()](#23-hashcode-和-equals)
- [2.3.1 什麼是 hashCode() 和 equals()](#231-什麼是-hashcode-和-equals)
- [2.3.2 equals() 已經實現功能了,還需要 hashCode() 做什麼?](#232-equals-已經實現功能了還需要-hashcode-做什麼)
- [2.3.3 為什麼不全部使用高效率的 hashCode(),還要用 equals()?](#233-為什麼不全部使用高效率的-hashcode還要用-equals)
- [2.3.4 hashCode() 和 equals() 是如何一起判斷保證高效又可靠的?](#234-hashcode-和-equals-是如何一起判斷保證高效又可靠的)
- [2.3.5 為什麼重寫 equals 時必須重寫 hashCode 方法?](#235-為什麼重寫-equals-時必須重寫-hashcode-方法)
- [2.4 深拷貝和淺拷貝的區別?](#24-深拷貝和淺拷貝的區別)
- [2.5 為什麼重寫 toString() 方法?](#25-為什麼重寫-tostring-方法)
- [2.6 字串使用 += 賦值後,原始的String物件中的內容會改變嗎?](#26-字串使用-賦值後原始的string物件中的內容會改變嗎)
- [2.7 字串建構函式賦值和直接賦值的區別?](#27-字串建構函式賦值和直接賦值的區別)
- [2.8 String、StringBuffer、StringBuilder的區別](#28-string-stringbuffer-stringbuilder的區別)
- [2.9 字串 “+” 和 StringBuilder 選擇用哪個?](#29-字串-和-stringbuilder-選擇用哪個)
# 三 Java 常見物件
**說明**:本章主要涉及到了:Object類、Scanner類、String類、StringBuffer和StringBuilder、Arrays工具類、基本型別包裝類、正則表示式、System類、Math、Random類、BigInteger和BigDecimal類、Date、DateFormat和Calendar類
**補充**:由於 Object 以及 String 類屬於高頻內容,所以總結題目以及小點知識之前,會對其做一個基本的歸納複習。
## 1. 基本歸納
在講解這些常見類之前,我們不得不簡單的提一下什麼是API,先貼一組百度百科的解釋:
> API(Application Programming Interface,應用程式程式設計介面)是一些預先定義的函式,目的是提供應用程式與開發人員基於某軟體或硬體得以訪問一組例程的能力,而又無需訪問原始碼,或理解內部工作機制的細節。
簡單的說:就是 Java 中有好多現成的類庫,其中封裝了許多函式,只提供函式名和引數,但隱藏了函式的具體實現,這些可見的部分作為與外界聯絡的橋樑,也就是我們所稱的 API ,不過由於Java是開源的,所以這些隱藏的實現我們也是可以看到的。
### 1.1 Object 類
- Object 是類層次結構的**根類**,所有的類都隱式的(不用寫extends)繼承自Object類。
- Java 所有的物件都擁有Object預設方法
- Object 類的構造方法有一個,並且是**無參構造**
這就對應了前面學習中的一句話,子類構造方法預設訪問父類的構造是無參構造
我們需要**瞭解的方法**又有哪些呢?
A:hashCode() B:getClass() C: finalize() D:clone() E:wait() F:notify() G:notifyAll()
我們需要**掌握的方法**又有哪些呢?
A:toString() B:equals()
**方法總結:**
```java
// 1. 返回此Object的執行時類,是一個 native方法,同時因為使用了final關鍵字修飾,故不允許子類重寫。
public final native Class getClass()
// 2. 用於返回物件的雜湊碼,是一個native方法,例如主要涉及在 HashMap 中。
public native int hashCode()
// 3. 比較兩個物件是否相同,預設比較的是地址值是否相同。而比較地址值是沒有意義的,所以,一般子類也會重寫該方法。
public boolean equals(Object obj)
// 4. 實現物件的克隆,包括成員變數的資料複製,分為深淺克隆兩種。是一個native方法。
protected native Object clone() throws CloneNotSupportedException
// 5. 返回類的名字@該例項16進位制的雜湊碼字串。因此建議Object 所有的子類都重寫此方法。
public String toString()
// 6. 喚醒一個在此物件監視器上等待的執行緒(監視器理解為鎖)。若有多個執行緒在等待只會任意喚醒一個。是一個 native方法,且不能重寫。
public final native void notify()
// 7. 同 notify(),區別是會喚醒在此物件監視器上等待的所有執行緒。
public final native void notifyAll()
// 8. 意為暫停執行緒的執行.是一個native方法。注意:釋放了鎖,而sleep方法不釋放鎖。timeout是等待時間。
public final native void wait(long timeout) throws InterruptedException
// 9. 多了一個nanos引數,代表額外時間(以毫微秒為單位,範圍是 0-999999)。 所以時間最後要計算總和。
public final void wait(long timeout, int nanos) throws InterruptedException
// 10同前兩個 wait() 只不過該方法一直等待
public final void wait() throws InterruptedException
// 11. 在物件將被垃圾回收器清除前呼叫,但不確定時間
protected void finalize() throws Throwable { }
```
### 2.2 String 類
String 是一個很常用的類,簡單歸納一下常見的方法
**構造方法**
```java
// 1. 空構造
public String()
// 2. 把位元組陣列轉換成字串
public String(byte[] bytes)
// 3. 把位元組陣列的一部分轉換成字串
public String(byte[] bytes,int offset,int length)
// 4. 把字元陣列轉換成字串
public String(char[] value)
// 5. 把字元陣列的一部分轉換成字串
public String(char[] value,int offset,int count)
// 6. 把字串常量值轉換成字串
public String(String original)
// 7. 下面的這一個雖然不是構造方法,但是結果也是一個字串物件
String s = "hello";
```
簡單總結:String類的構造方法可以將 **位元組、字元陣列、字串常量**(全部或者部分)轉換為字串型別
**判斷方法**
```java
// 1. 比較字串的內容是否相同,區分大小寫
boolean equals(Object obj)
// 2. 比較字串的內容是否相同,不區分大小寫
boolean equalsIgnoreCase(String str)
// 3. 判斷大字串中是否包含小字串
boolean contains(String str)
// 4. 判斷某個字串是否以某個指定的字串開頭
boolean startsWith(String str)
// 5. 判斷某個字串是否以某個指定的字串結尾
boolean endsWith(String str)
// 6. 判斷字串是否為空
boolean isEmpty()
注意:
String s = “”; // 字串內容為空
String s = null; // 字串物件為空
```
**獲取方法**
```java
// 1. 獲取字串的長度
int length()
// 2. 獲取指定索引的字元
char charAt(int index)
// 3. 返回指定字元在此字串中第一次出現的索引
int indexOf(int ch)
// 為什麼這裡是int而不是char?
// 原因是:‘a’和‘97’其實都能代表‘a’ int方便
// 4. 返回指定字串在此字串中第一次出現的索引
int indexOf(String str)
// 5. 返回指定字元在此字串中從指定位置後第一次出現的索引
int indexOf(int ch,int fromIndex)
// 6. 返回指定字串在此字串中從指定位置後第一次出現的索引
int indexOf(String str, int fromIndex)
// 7. 從指定位置開始擷取字串,預設到末尾
String substring(int start)
// 8. 從指定位置開始指定位置結束擷取字串
String substring(int start, int end)
```
**轉換方法**
```java
// 1. 把字串轉換為位元組陣列
byte[] getBytes()
// 2. 把字串轉換成字元陣列
char[] toCharArray()
// 3. 把字元陣列轉換成字串
static String valueOf(char[] chs)
// 3. 把int型別的資料轉換成字串
static String valueOf(int i)
// 注意:String類的valueOf方法可以把任何型別的資料轉換成字串!
// 4. 把字串轉換成小寫
String toLowerCase()
// 5. 把字串轉換成大寫
String toUpperCase()
// 7. 把字串拼接
String concat(String str)
```
**其他方法**
```java
// 1. 替換功能
String replace(char old,char new)
String replace(String old,String new)
// 2. 去除字串兩端空格
String trim()
// 3. 按字典比較功能
int compareTo(String str)
int compareToIgnoreCase(String str)
```
## 2. 題目總結
### 2.1 == 和 equals 的區別?
`==` :如果比較的物件是基本資料型別,則比較的是數值是否相等;如果比較的是引用資料型別,則比較的是物件
的地址值是否相等。
`equals()`:equals 方法不能用於基本資料型別的變數,如果沒有對 equals 方法進行重寫,則比較的是引用型別的變數所指向的物件的地址。一般會選擇重寫此方法,來比較兩個物件的內容是否相等,相等則返回 true。
### 2.2 如何比較兩個物件內容是否相同?(重寫 equals)
例如一個 Student 類,new 兩個物件出來,單純的想比較內容是否相同如何做呢。
```java
public class Student {
private String name;
public int age;
// get set ...
}
```
通過 equals() 比較兩個物件是否相同,預設情況下,比較的是地址值是否相同。而比較地址值是沒有意義的,所以,一般子類也會重寫該方法。在諸多子類,如String、Integer、Date 等均重寫了 equals() 方法
改進思路:我們可以將比較地址值轉變為比較成員變數
- 因為 name 為 String 型別,而 String 型別為引用型別,所以不能夠用 == 比較,應該用 equal()
- String 中預設重寫過的 equal() 方法是用來比較字串內容是否相同
- 我們要使用的是學生類的成員變數,所以父類 Object不能呼叫子類Student的特有功能,所以使用向下轉型
```java
//重寫v1.0
public boolean equals(Object o) {
Student s = (Student) o;
if (this.name.equals(s.name) && this.age == s.age) {
return true;
} else {
return false;
}
}
```
```java
//重寫v2.0 (可作為最終版)
public boolean equals(Object o) {
if (this.name == o) {
return true;
}
//測試它左邊的物件是否是它右邊的類的例項,返回 boolean 的資料型別。
if (!(o instanceof Student)) {
return false;
}
Student s = (Student) o;
return this.name.equals(s.name) && this.age == s.age;
}
```
```java
// IDEA自動生成版
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age &&
Objects.equals(name, student.name);
}
```
### 2.3 hashCode() 和 equals()
#### 2.3.1 什麼是 hashCode() 和 equals()
`hashCode()` 方法是 Object 類中的一個本地方法(用 c 語言或 c++ 實現的),會返回該物件的雜湊碼,也稱為雜湊碼;其本質是返回一個 int 整數。雜湊碼的作用是確定該物件在雜湊表中的索引位置。可以通過雜湊碼,在散列表中根據“鍵”快速的檢索出對應的“值”。從而快速找到需要的物件,然後進行判斷是不是同一個物件。
```java
public native int hashCode();
```
`equals()` 方法是Object 類中的一個方法,如果沒有對 equals 方法進行重寫,則比較的是引用型別的變數所指向的物件的地址。一般會選擇重寫此方法,來比較兩個物件的內容是否相等,相等則返回 true。
總結:單考慮目的兩者是差不多的,都是用來對比兩個物件是否相等一致。
#### 2.3.2 equals() 已經實現功能了,還需要 hashCode() 做什麼?
重寫 equals() 裡面的內容一般比較全面周詳,但是效率就比較低,例如:如果集合中現在已經有2000個元素,那麼第2001個元素加入集合時,它就要呼叫 2000次 equals方法。
而使用 hashCode() ,其使用的雜湊演算法也稱為雜湊演算法,是將資料依特定演算法直接指定到一個地址上,所以 hashCode() 這種形成 hash 碼的方式比較是比較高效的。
#### 2.3.3 為什麼不全部使用高效率的 hashCode(),還要用 equals()?
hashCode() 方法不是一個 100% 可靠的方法,個別情況下,不同的物件生成的 hashcode 也可能會相同。
#### 2.3.4 hashCode() 和 equals() 是如何一起判斷保證高效又可靠的?
如果大量內容都是用 equals() 去比對,效率顯然是比較低的,所以每次比對之前都去使用 hashCode() 去對比,如果返回的 hashCode 不同,代表兩個物件肯定不相同,就可以直接返回結果了。如果 hashCode 相同,又為了保證其絕對可靠,所以使用 equals() 再次進行比對,同樣是相同,就保證了這兩個物件絕對相同。
#### 2.3.5 為什麼重寫 equals 時必須重寫 hashCode 方法?
如果重寫了 equals() 而未重寫 hashcode() 方法,可能就會出現兩個字面資料相同的物件(例如下面 stu1 和 stu2) equals 相同(因為 equals 都是根據物件的特徵進行重寫的),但 hashcode 不相同的情況。
```java
public class Student {
private String name;
public int age;
// get set ...
// 重寫 equals() 不重寫 hashcode()
}
--------------------------------------------
Student stu1 = new Student("BWH_Steven",22);
Student stu2 = new Student("BWH_Steven",22);
--------------------------------------------
stu1.equals(stu2); // true
stu1.hashCode(); // 和 stu2.hashCode(); 結果不一致
stu2.hashCode();
```
如果把物件儲存到 HashTable、HashMap、HashSet 等中(不允許重複),這種情況下,去查詢的時候,由於都是先使用 hashCode() 去對比,如果返回的 hashCode 不同,則會認為物件不同。可以儲存,從內容上看,明顯就重複了。
> 所以一般的地方不需要重寫 hashcode() ,只有當類需要放在 HashTable、HashMap、HashSet 等hash 結構的集合時才會去重寫。
> **補充:阿里巴巴 Java 開發手冊關於 hashCode 和 equals 的處理遵循規則:**
>
> - 只要重寫 equals,就必須重寫 hashCode。
> - 因為 Set 儲存的是不重複的物件,依據 hashCode 和 equals 進行判斷,所以 Set 儲存的物件必須重寫這兩個方法。
> - 如果自定義物件做為 Map 的鍵,那麼必須重寫 hashCode 和 equals。
> - String 重寫了 hashCode 和 equals 方法,所以我們可以非常愉快地使用 String 物件作為 key 來使用。
### 2.4 深拷貝和淺拷貝的區別?
**淺拷貝(淺克隆)**:基本資料型別為值傳遞,物件型別為引用傳遞(兩者同生共死)
**深拷貝(深克隆)**:對於物件或者數值,所有元素或者屬性均完全複製,與原物件脫離(真正意義上的複製, 兩者獨立無關)
舉例:
```java
public class Book {
private String name; // 姓名
private int price; // 價格
private Partner partner; // 合作伙伴
// 省略建構函式、get set、toString 等
}
```
```java
public class Partner{
private String name;
// 省略建構函式、get set、toString 等
}
```
淺拷貝用到拷貝,首先就對 Book 類進行處理
- 首先實現 Cloneable 介面
- 接著重寫 clone 方法
```java
public class Book implements Cloneable{
private String name; // 姓名
private int price; // 價格
private Partner partner; // 合作伙伴
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
// 省略建構函式、get set、toString 等
}
```
再來測試一下
```java
public class Test {
public static void main(String[] args) throws CloneNotSupportedException {
// 初始化一個合作伙伴型別
Partner partner = new Partner("張三");
// 帶參賦值
Book bookA = new Book("理想二旬不止", 66, partner);
// B 克隆 A
Book bookB = (Book) bookA.clone();
System.out.println("A: " + bookA.toString());
System.out.println("A: " + bookA.hashCode());
System.out.println("B: " + bookB.toString());
System.out.println("B: " + bookB.hashCode());
}
}
```
執行結果
A: Book{name='理想二旬不止', price=66, partner=Partner{name=張三}}
A: 460141958
B: Book{name='理想二旬不止', price=66, partner=Partner{name=張三}}
B: 1163157884
結果非常明顯,書籍資訊是一致的,但是記憶體地址是不一樣的,也就是說確實克隆成功了,列印其 hashCode 發現兩者並不相同,說明不止指向同一個,也是滿足我們要求的
到這裡並沒有結束,你會發現還是有問題,當你刊印的過程中修改一些值的內容的時候,你看看效果
```java
public class Test {
public static void main(String[] args) throws CloneNotSupportedException {
// 初始化一個合作伙伴型別
Partner partner = new Partner("張三");
// 帶參賦值
Book bookA = new Book("理想二旬不止", 66, partner);
// B 克隆 A
Book bookB = (Book) bookA.clone();
// 修改資料
bookB.getPartner().setName("李四");
bookB.setPrice(44);
System.out.println("A: " + bookA.toString());
System.out.println("A: " + bookA.hashCode());
System.out.println("B: " + bookB.toString());
System.out.println("B: " + bookB.hashCode());
}
}
```
執行結果
A: Book{name='理想二旬不止', price=66, partner=Partner{name=李四}}
A: 460141958
B: Book{name='理想二旬不止', price=66, partner=Partner{name=李四}}
B: 1163157884
???這不對啊,B 明明是克隆 A 的,為什麼我在克隆後,修改了 B 中兩個值,但是 A 也變化了啊
這就是典型的淺克隆,在 Book 類,當欄位是引用型別,例如 Partner 這個合作伙伴類,就是我們自定義的類,這種情況不復制引用的物件,因此,原始物件和複製後的這個Partner物件是引用同一個物件的。而作為基本型別的的值就沒事。
如何解決上面的問題呢,我們需要重寫主類的 clone 的內容(改為深拷貝),同時在引用型別中也實現淺拷貝
A:被引用型別實現淺克隆
```java
public class Partner implements Cloneable {
private String name;
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
// 省略建構函式、get set、toString 等
}
```
B:修改引用類 cloen 方法
```java
public class Book implements Cloneable{
private String name; // 姓名
private int price; // 價格
private Partner partner; // 合作伙伴
@Override
protected Object clone() throws CloneNotSupportedException {
Object clone = super.clone();
Book book = (Book) clone;
book.partner =(Partner) this.partner.clone();
return clone;
}
// 省略建構函式、get set、toString 等
}
```
C:測試一下
```java
public class Test {
public static void main(String[] args) throws CloneNotSupportedException {
// 初始化一個合作伙伴型別
Partner partner = new Partner("張三");
// 帶參賦值
Book bookA = new Book("理想二旬不止", 66, partner);
// B 克隆 A
Book bookB = (Book) bookA.clone();
// 修改資料
partner.setName("李四");
System.out.println("A: " + bookA.toString());
System.out.println("A: " + bookA.hashCode());
System.out.println("B: " + bookB.toString());
System.out.println("B: " + bookB.hashCode());
}
}
```
執行效果
A: Book{name='理想二旬不止', price=66, partner=Partner{name=李四}}
A: 460141958
B: Book{name='理想二旬不止', price=66, partner=Partner{name=張三}}
B: 1163157884
可以看到,B 克隆 A 後,修改 A 中 合作伙伴 的值,沒有受到影響,這也就是我們通常意義上想要實現的效果了。
### 2.5 為什麼重寫 toString() 方法?
主要目的還是為了簡化輸出
1. 在類中重寫toString()後,輸出類物件就變得有了意義(輸出s 和 s.toString()是一樣的 ,不寫也會預設呼叫),變成了我們實實在在的資訊 ,例如 Student{name='admin', age=20},而不是上面的 cn.ideal.pojo.Student@1b6d3586
2. 如果我們想要多次輸出 類中的成員資訊,就需要多次書寫 ge t方法(每用一次就得寫)
> toString() 方法,返回該物件的字串表示。
>
> `Object` 類的 `toString` 方法返回一個字串,該字串由類名(物件是該類的一個例項)at 標記符 `@` 和此物件雜湊碼的無符號十六進位制表示組成。換句話說,該方法返回一個字串,它的值等於:
>
> 程式碼:`getClass().getName()+ '@' + Integer.toHexString(hashCode())`
>
> 通常我們希望, `toString` 方法會返回一個“以文字方式表示” 此物件的字串。結果應是一個簡明但易於讀懂的資訊表示式。因此建議所有子類都重寫此方法。
### 2.6 字串使用 += 賦值後,原始的String物件中的內容會改變嗎?
答案:不會
```java
/*
* 字串特點:一旦被賦值,就不能改變
*/
public class StringDemo {
public static void main(String[] args) {
String s = "Hello";
s += "World";
System.out.println("s:" + s);
}
}
//執行結果:
s:HelloWorld
```
**解釋:**不能改變是指字串物件本身不能改變,而不是指物件的引用不能改變,上述過程中,字串本身的內容是沒有任何變化的,而是分別建立了三塊記憶體空間,(Hello) (World) (HelloWorld) Hello + World 拼接成 HelloWorld 這時,s 不指向原來那個 “Hello” 物件了,而指向了另一個String物件,內容為 “HelloWorld ” ,原來那個物件還存在記憶體中,只是 s 這個引用變數不再指向它了。
**總結**:開發中,儘量少使用 + 進行字串的拼接,尤其是迴圈內,我們更加推薦使用StringBuild、StringBuffer。
### 2.7 字串建構函式賦值和直接賦值的區別?
通過 new 建構函式建立字串物件。String s = new String("Hello"); 系統會先建立一個匿名物件 "Hello" 存入堆記憶體,而後 new 關鍵字會在堆記憶體中又開闢一塊新的空間,然後把"Hello"存進去,並且把地址返回給棧記憶體中的 s, 剛才的匿名物件 "Hello" 就變成了一個垃圾物件,因為它沒有被任何棧中的變數指向,會被GC自動回收。
直接賦值。如String str = "Hello"; 首先會去字串常量池中找有沒有一個"Hello"物件,如果沒有,則新建一個,並且入池,所以此種賦值有一個好處,下次如果還有 String 物件也用直接賦值方式定義為“Hello”, 則不需要開闢新的堆空間,而仍然指向這個池中的"Hello"。
```java
//兩者的區別
String s = new String("Hello");
String s = "Hello";
```
**總結**:前者new一個物件,“hello”隱式建立一個物件,後者只有“Hello”建立一個物件,在開發中,儘量使用 String s = "Hello" 的方式,效率比另一種高。
### 2.8 String、StringBuffer、StringBuilder的區別
> 前面我們用字串做拼接,比較耗時並且也耗記憶體(每次都會構造一個新的string物件),而這種拼接操作又是比較常見的,為了解決這個問題,Java就提供了兩個字串緩衝區類。StringBuffer和StringBuilder供我們使用。
**簡單比較**:
String:長度大小不可變
StringBuffer:長度可變、執行緒安全、速度較慢
StringBuilder:長度可變、執行緒不安全、速度最快
**解釋:**
1. 在執行速度方面的比較:StringBuilder > StringBuffer
2. StringBuffer與StringBuilder,他們是字串變數,是可改變的物件,每當我們用它們對字串做操作時,實際上是在一個物件上操作的,不像String一樣建立一些物件進行操作,所以速度就快了。
3. StringBuilder:執行緒非安全的
StringBuffer:執行緒是安全的(synchronized關鍵字進行修飾)
當我們在字串緩衝區被多個執行緒使用時,JVM 不能保證 StringBuilder 的操作是安全的,雖然他的速度最快,但是可以保證 StringBuffer 是可以正確操作的。當然大多數情況下就是我們是在單執行緒下進行的操作,所以大多數情況下是建議用StringBuilder而不用StringBuffer的,就是速度的原因。
**對於三者使用的總結:**
1. 如果要操作少量的資料用 String
2. 單執行緒操作字串緩衝區 下操作大量資料 StringBuilder
3. 多執行緒操作字串緩衝區 下操作大量資料 StringBuffer
### 2.9 字串 “+” 和 StringBuilder 選擇用哪個?
首先java並不支援運算子過載(String類中的 “+” 和 “+=” 是 Java 中僅有的兩個過載過的運算子),所以我們可以通過 “+” 符號 將多個字串進行拼接
將圖中程式碼(使用了 “+” 符號)利用 `javap -c filename` 反編譯
我們可以看到程式碼被編譯器自動優化成使用StringBuilder方式拼接,執行效率得到了保證
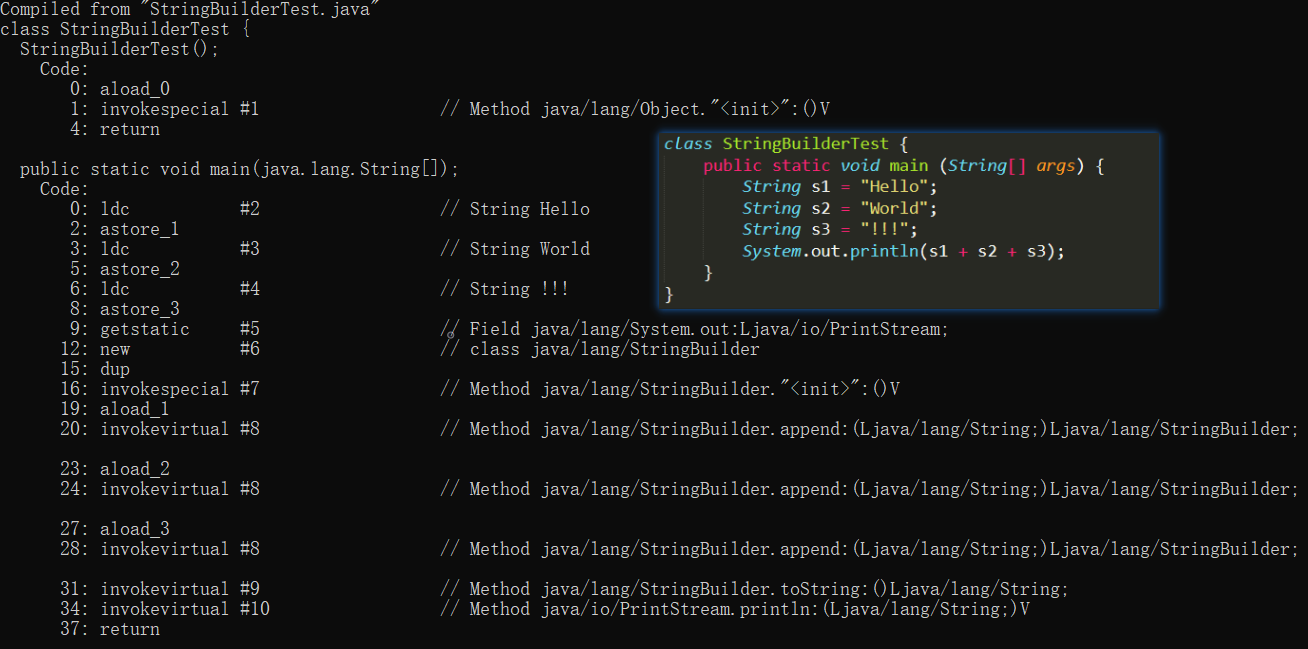
下面一個案例 **陣列拼接成指定格式的字串** 程式碼中使用了迴圈語句
```java
// 在迴圈中通過String拼接字串
public class StringBuilderDemo {
public static void main(String[] args) {
String[] arr = {"Hello", "World", "!!!"};
String s1 = arrayToString(arr);
System.out.println(s1);
}
public static String arrayToString(String[] arr) {
String s = "";
s += "[";
for (int x = 0; x < arr.length; x++) {
if (x == arr.length - 1) {
s += arr[x];
} else {
s += arr[x];
s += ", ";
}
}
s += "]";
return s;
}
}
//執行結果
[Hello, World, !!!]
```
使用String方式進行拼接,我們反編譯可以看到,StringBuilder被建立在迴圈的內部,這意味著每迴圈一次就會建立一次StringBuilder物件,這可是一個糟糕的事情。
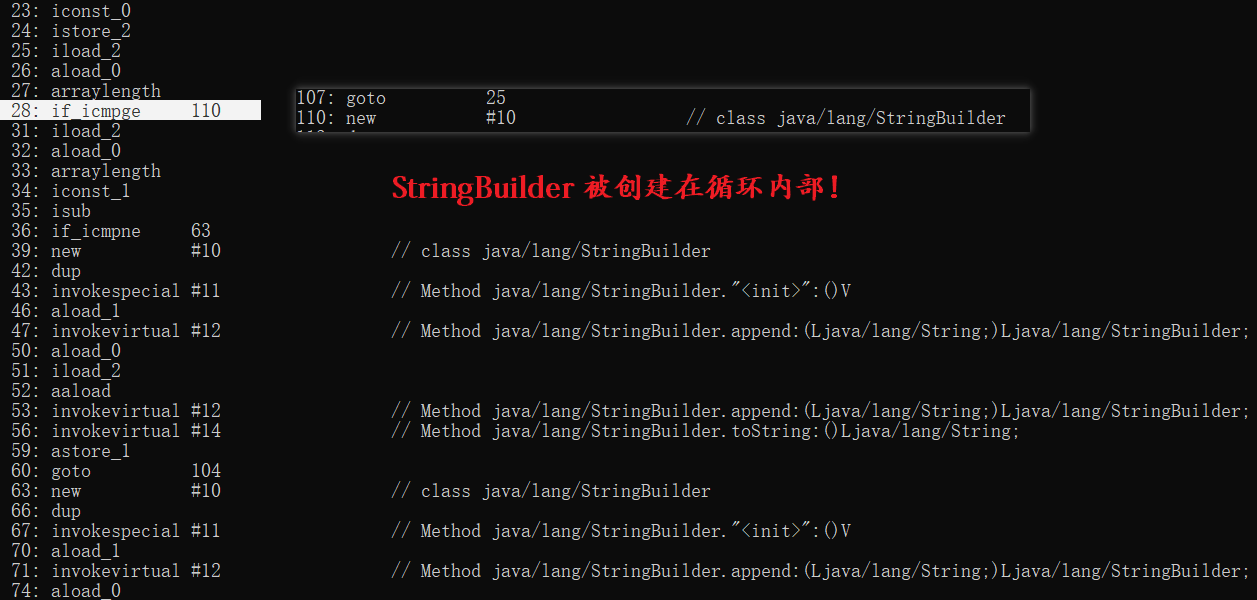
```java
// 在迴圈中使用StringBuilder拼接字串
public class StringBuilderDemo2 {
public static void main(String[] args) {
String[] arr = {"Hello", "World", "!!!"};
String s1 = arrayToString(arr);
System.out.println(s1);
}
public static String arrayToString(String[] arr) {
StringBuilder s = new StringBuilder();
s.append("[");
for (int x = 0; x < arr.length; x++) {
if (x == arr.length - 1) {
s.append(arr[x]);
} else {
s.append(arr[x]);
s.append(", ");
}
}
s.append("]");
return s.toString();
}
}
//執行結果
[Hello, World, !!!]
```
使用StringBuilder方式進行拼接,自行去看一下彙編程式碼中,不僅迴圈部分的程式碼更為簡潔,而且它只生成了一個StringBuilder物件。顯式的建立StringBuilder物件還允許你預先為其指定大小。可以避免多次重新分配緩衝。
**總結:**
如果字串操作比較簡單,就可以使用 “+” 運算子操作,編譯器會為你合理的構造出最終的字串結果
如果使用迴圈語句 最好自己手動建立一個StringBuilder物件,用它來構最