
P95、P99.9百分位數值——服務響應時間的重要衡量指標
阿新 • • 發佈:2021-02-01
前段時間,在對系統進行改版後,經常會有使用者投訴說頁面響應較慢,我們看了看監控資料,發現從介面響應時間的平均值來看在500ms左右,也算符合要求,不至於像使用者說的那麼慢,歲很費解,後來觀察其它的一些指標發現確實是有問題,這個指標就是P95,P99.9,我們發現雖然平均響應時間並不高,但P95和P99.9卻達到了2s以上,說明我們的介面確實存在慢查詢。於是撈取了一些慢查詢的請求日誌終於發現問題。那麼P95、P99又代表什麼意思呢?
通常,我們對服務響應時間的衡量指標有Min(最小響應時間)、Max(最大響應時間)、Avg(平均響應時間)等。
### 1 平均值Avg
其中比較常用的值就是平均值,例如平均耗時為100ms,表示伺服器當前`請求的總耗時/請求總數量`,通過該值,我們大體能知道服務執行情況。
但是使用平均值來衡量響應時間有個非常大的問題,舉個例子:眾所周知,我和Jack馬和tony馬的財富加起來足以撼動整個亞洲,我和姚明的平均身高有兩米多......
平均值同樣有這種問題,這個衡量指標的計算方式會把一些異常的值平均掉,進而會掩蓋一些問題,我們只知道所有請求的平均響應時間是100ms,但是具體有多少個請求比100ms要大,又有多少個請求比100ms要小,大多少,是200ms,還是500ms,又或是1000ms,我們無從得知。
### 2 百分位數值
平均值並不能反映資料分佈及極端異常值的問題,這時我們可以使用百分位數值。
百分位數值是一個統計學中的術語。
> 如果將一組資料從小到大排序,並計算相應的累計百分位,則某一百分位所對應資料的值就稱為這一百分位的百分位數。可表示為:一組n個觀測值按數值大小排列。如,處於p%位置的值稱第p百分位數
用我們軟體開發行業的例子通俗來講就是,假設有100個請求,按照響應時間從小到大排列,位置為X的值,即為PX值。
P1就是響應時間最小的請求,P10就是排名第十的請求,P100就是響應時間最長的請求。
在真正使用過程中,最常用的主要有P50(中位數)、P95、P99。
**P50:** 即中位數值。100個請求按照響應時間從小到大排列,位置為50的值,即為P50值。如果響應時間的P50值為200ms,代表我們有半數的使用者響應耗時在200ms之內,有半數的使用者響應耗時大於200ms。如果你覺得中位數值不夠精確,那麼可以使用P95和P99.9
**P95:**響應耗時從小到大排列,順序處於95%位置的值即為P95值。
還是採用上面那個例子,100個請求按照響應時間從小到大排列,位置為95的值,即為P95值。 我們假設該值為200ms,那這個值又表示什麼意思呢?
意思是說,我們對95%的使用者的響應耗時在200ms之內,只有5%的使用者的響應耗時大於200ms,據此,我們掌握了更精確的服務響應耗時資訊。
**P99.9:**許多大型的網際網路公司會採用P99.9值,也就是99.9%使用者耗時作為指標,意思就是1000個使用者裡面,999個使用者的耗時上限,通過測量與優化該值,就可保證絕大多數使用者的使用體驗。 至於P99.99值,優化成本過高,而且服務響應由於網路波動、系統抖動等不能解決之情況,因此大多數時候都不考慮該指標。
下圖是我從我們系統中隨便拉的兩個介面的效能監控資料,我們可以看到第一個均值在40ms,P95在82.5ms,看似還可以,但是P99.9卻是1743ms。
而第二個介面均值在710ms,但是P95卻是1592.7ms,這代表我們有將近5%的使用者訪問該介面的時間要大於1592.7ms。P99.9更是達到了2494.2ms。

以上兩個介面如果單純只看均值指標,並沒有什麼問題,但是P95和P99.9卻反映了我們一些慢請求的情況。拿到這個指標資料,我們就知道我們的服務並非沒有問題,就可以去優化這兩個指標的值,以達到更好的使用者體驗。
### 3 如何計算百分位數值
平均值之所以會成為大多數人使用衡量指標,其原因主要在於他的計算非常簡單。`請求的總耗時/請求總數量`就可以得到平均值。而P值的計算則相對麻煩一些。
按照傳統的方式,計算P值需要將響應耗時從小到大排序,然後取得對應百分位之值。
如果服務qps較低,例如:100/秒,我們計算這1s內的P值,就記錄這100請求的耗時資料,然後排序,然後取得P分位值,並非難事。但如果我們要計算1h內的p值呢,就是要對360000的資料進行排序然後取得P分位值。而如果對於一些使用者量更大的系統,例如:QPS 30萬/秒,那麼1h內的p值如果還是採用`記錄+排序`的方式,就是要對十個多億的資料進行排序,可想而知需要消耗多麼大的記憶體與計算資源。
那麼有沒有簡單的計算方式呢?
可以採用分桶計算的方式,即一個耗時範圍一個桶,該計算方式雖不是完全準確值,但精度非常高,誤差較小。
首先需要界定每個桶的跨度,可以採用等分形式,例如對於耗時統計需求,我們可以假定一個耗時上界,然後等分成N個區間,如下圖,如果響應耗時在30ms則落在0-50ms的桶內,如果響應時間在80ms則落在50-100ms的桶內,以此類推。
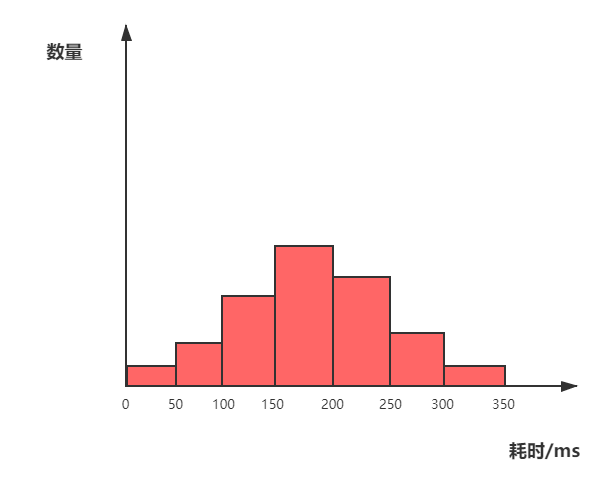
這樣就避免了對全部資料進行排序,只需要根據各個桶中的資料數量,即可計算出95%位置位於哪個桶,例如需要計算95線時,就從最大的桶開始剔除,當數量超過5%的時候,那個桶的值就是95線。然後在桶的內部採用插值方法,也可以通過桶內平均的方式來計算出一個相對精確的P95值。
此外,考慮到資料分佈特點,服務耗時異常資料應該只是少數,但是異常值跨度可能很大,大部分耗時資料均靠近正常值,如果採用桶等分的形式,可能會導致大量資料堆積在一個桶內中,又如何解決這個問題?
其實可以採用非等分的跨度劃分方式,例如採用**指數**形式劃分,耗時越低的區間,跨度越小,精度約高。
此外也可以採用美團點評的實時監控系統cat的桶跨度劃分方式,程式碼如下:
```java
public static int computeDuration(int duration) {
if (duration < 1) {
return 1;
} else if (duration < 20) {
return duration;
} else if (duration < 200) {
return duration - duration % 5;
} else if (duration < 500) {
return duration - duration % 20;
} else if (duration < 2000) {
return duration - duration % 50;
} else if (duration < 20000) {
return duration - duration % 500;
} else if (duration < 1000000) {
return duration - duration % 10000;
} else {
int dk = 524288;
if (duration > 3600 * 1000) {
dk = 3600 * 1000;
} else {
while (dk < duration) {
dk <<= 1;
}
}
return dk;
}
}
```
即:小於20ms的時候1ms一個桶,大於20ms小於200ms的時候5ms一個桶,大於200ms小於500ms的時候20ms一個桶,以此類推!而桶的值也可以作為百分位數的近似值,而無需進行排序計算,這個時候約耗時越小的時候,精度越準確!
### 小結
百分位數值在網際網路系統中有很大的意義。**通過對百分位數值的監控與優化,我們可以將更多的使用者納入我們的監控體系中,讓我們的服務能夠對絕對大多數的使用者提供更好的體驗!**在一些錯誤率、異常率上面我們也可以使用百分位數來進行系統可用性是否達到要求,甚至在一些新的產品特性或者AB測試上也可以用來統計分析使用者對其的反響,以此來衡量該特性是否真正對使用者有幫